【文献阅读】Mixture of Lookup Experts
ICML2025

摘要
专家混合模型(MoE)在推理过程中仅激活部分专家,使得模型即使在参数规模扩大时仍能保持较低的推理 FLOPs 和延迟。然而,由于 MoE 动态选择专家,所有专家均需加载到 VRAM 中。其庞大的参数规模仍限制了部署,而仅在需要时将专家加载到 VRAM 的卸载策略会显著增加推理延迟。为解决这一问题,我们提出 Lookup 专家混合模型(MoLE),这是一种在通信和 VRAM 使用方面均高效的新型 MoE 架构。在 MoLE 中,专家在训练期间为前馈网络(FFNs),以嵌入层的输出作为输入。推理前,这些专家可重新参数化为基于输入 id 检索专家输出的查找表(LUTs),并卸载到存储设备。因此,推理期间无需执行专家计算,而是直接根据输入 id 检索专家计算结果并加载到 VRAM,从而通信开销可忽略不计。实验表明,在相同 FLOPs 和 VRAM 使用情况下,MoLE 的推理速度与稠密模型相当,显著快于采用专家卸载的 MoE,同时性能与 MoE 持平。代码:GitHub - JieShibo/MoLE: [ICML 2025 Spotlight] Mixture of Lookup Experts
1. 引言
缩放定律表明,在有足够训练数据的情况下,大语言模型(LLMs)的性能随模型规模增大而提升(Kaplan 等人,2020)。然而,更大的 LLM 也会导致推理速度变慢,从而降低用户体验。因此,LLM 的架构越来越关注专家混合模型(MoE)(Jiang 等人,2024;Dai 等人,2024)。MoE 模型使用多个前馈网络(FFNs)作为专家,并采用路由器确定需要激活的专家子集,而非激活整个模型。这使得模型能够在保持大量参数的同时保持较低的计算成本。
尽管 MoE 降低了计算成本,但参数数量并未减少。这意味着推理期间的 VRAM 需求仍然过高。例如,尽管 Mixtral-8×7B(Jiang 等人,2024)模型一次仅激活 130 亿参数,但其总参数数达 460 亿,无法以 FP16 精度加载到单个 80GB 的 A100 GPU 中。现有方法(Eliseev & Mazur,2023;Xue 等人,2024;Shen 等人,2022)通过将专家卸载到更大的存储设备(如 CPU 内存、磁盘或云存储)并在每个推理步骤按需加载所选专家来减少 VRAM 使用。然而,这种方法存在两个缺点:
i)由于专家选择由路由器动态决定,每个推理步骤必须将不同的专家加载到 VRAM 中。大量参数的频繁传输会显著增加推理延迟,如图 1 所示。
ii)由于单个步骤内不同样本选择不同专家,仅加载部分专家可能无法满足批量生成的需求。
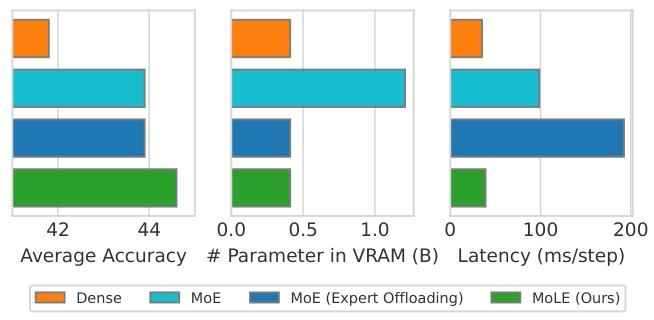
图1. 在相同4.1亿激活参数的情况下,MoE在性能上优于稠密模型,但会带来显著的VRAM使用量。如果卸载专家,推理延迟将会增加。我们的MoLE在不增加模型VRAM使用量或解码延迟的情况下,保持了具有竞争力的性能。
为解决上述问题,我们提出 Lookup 专家混合模型(MoLE),一种新型 LLM 架构。MoLE 在训练和推理阶段具有不同的结构。训练期间,MoLE 与 MoE 类似,包含路由器和多个专家。但与 MoE 中专家以中间特征为输入不同,MoLE 的专家以嵌入标记(即嵌入层的输出)为输入。此外,MoLE 允许所有专家同时激活。训练后,MoLE 不直接用于推理,而是经历一系列重参数化。由于嵌入层的输出对于特定输入 id 是固定的,专家的输入仅有有限选择,等于模型的词汇量大小。因此,对于嵌入层中的每个标记,我们预计算所有专家对应的输出,创建替换原始专家的查找表(LUTs)。
推理期间,MoLE 展现出以下优势:
- 免计算专家:专家从前馈网络重参数化为查找表,无需任何计算。每个专家仅需一次查找操作。
- 低 VRAM 开销和通信延迟:尽管查找表的大小远大于模型本身,但其可完全卸载到存储设备。推理期间,由于每个专家的输出与输入标记数量相同,将查找结果加载到 VRAM 所需的通信量可忽略不计,从而避免推理延迟增加。
- 批量生成友好:传统专家卸载方法在批量生成期间会引入额外的 VRAM 使用和通信延迟,因为批次中的不同样本可能选择不同专家。MoLE 仅传输预计算的专家输出,使其通信开销即使在批量生成时仍可忽略不计。
通过大量实验,我们在 1.6 亿、4.1 亿和 10 亿参数规模下验证了 MoLE 的有效性。如图 1 所示,在计算成本和 VRAM 使用相当的情况下,MoLE 显著优于稠密模型,同时保持相同的推理速度。与采用专家卸载的 MoE 相比,MoLE 实现了更好的性能和显著更快的推理速度。
2. 相关工作
2.1 专家混合模型
MoE 的概念最初由 Jacobs 等人(1991);Jordan & Jacobs(1994)提出,并通过后续研究(Collobert 等人,2002;Rasmussen & Ghahramani,2001;Shahbaba & Neal,2009;Eigen 等人,2014;Theis & Bethge,2015;Deisenroth & Ng,2015;Aljundi 等人,2017;Shazeer 等人,2017)得到广泛探索和发展。
MoE 假设模型的不同部分(即专家)专注于不同任务或封装不同类型的知识。在此范式中,仅激活与给定输入相关的专家,使模型能够扩展容量,同时保持计算成本可控,并充分利用多个专家的专业知识。
随着 LLM 规模的扩大,降低计算开销成为关键焦点,这导致其在基于 Transformer 的 LLM 中的应用(Lepikhin 等人,2021),使 MoE 成为广泛使用的架构。最近,一系列工业规模的大语言模型已发布,包括 Mixtral(Jiang 等人,2024)和 DeepSeek-MoE(Dai 等人,2024)。
2.2 专家卸载
卸载技术通常在 GPU 内存不足时将部分模型参数转移到 CPU 内存或磁盘。然而,当前主流卸载框架(如 Zero-Infinity(Rajbhandari 等人,2021))专为稠密 LLM 设计,按需逐层加载模型参数。这种方法忽略了 MoE 模型的稀疏激活特性,导致不必要地加载未激活的专家。
在此基础上,一些研究提出了专家卸载,这是一种专为 MoE 模型稀疏激活特性设计的参数卸载形式(Eliseev & Mazur,2023;Xue 等人,2024)。这些方法将非专家权重和部分专家缓存存储在 VRAM 中,而将其余专家卸载到 CPU 内存或磁盘并按需加载。
尽管有效,现有专家卸载技术仍存在高延迟问题。后续研究包括优化预取技术和缓存替换策略以加速推理速度(Shen 等人,2022),设计更适合预取的 MoE 架构(Hwang 等人,2024),或采用其他模型压缩技术减少预取延迟(Yi 等人,2023)。
3. Lookup 专家混合模型
3.1 预备知识
首先,我们简要介绍 MoE 的结构及其在推理期间面临的挑战。
对于 MoE,每个专家通常为 FFN 模块。如图 2(左)所示,MoE 层包含 N 个经路由的专家,表示为\(\{FFN_j\}_{j=1}^N\),以及一个线性路由器,表示为\(\{r_j\}_{j=1}^N\)。某些模型可能还引入始终激活的共享专家 FFN_shared。
给定输入标记\(h \in \mathbb{R}^d\),MoE 层的输出标记\(h' \in \mathbb{R}^d\)计算如下:\(G = \text{ArgTopK}(\{h \cdot r_j\}_{j=1}^N)\)\(\{g_j\}_{j \in G} = \text{SoftMax}(\{h \cdot r_j\}_{j \in G})\)\(h' = \sum_{j \in G} (g_j \cdot FFN_j(h)) + FFN_{\text{shared}}(h) + h\) 其中,G 表示激活专家的索引,\(g_i\)表示第 i 个专家的门控值。
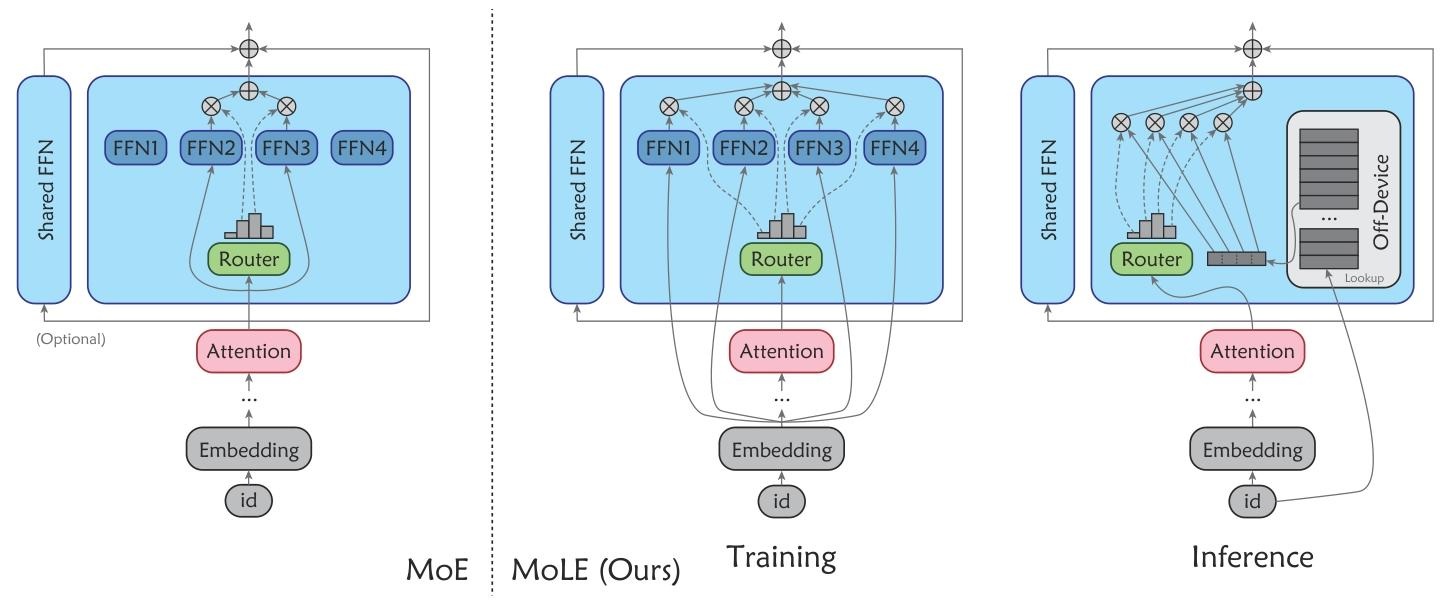
图2. MoLE示意图。在训练阶段,MoLE与MoE在两个关键结构方面存在差异:\(i\) MoLE中的路由专家以嵌入标记作为输入;\(ii\) MoLE中的所有专家均被激活。在推理阶段,MoLE中的路由专家被重参数化为零计算、卸载的查找表(LUTs)。为简化图示,注意力层的归一化层和残差连接已省略。
MoE 的计算效率在于,在公式(3)中仅涉及 k 个经路由的专家。然而,在公式(1)完成前,无法确定需要参与的专家。这意味着要么需要在 VRAM 中存储所有专家,要么在计算完公式(1)后临时将所需的 k 个专家加载到 VRAM 中。
然而,这两种解决方案均存在部署挑战。以 Mixtral-8×7B 为例,其包含 32 个 MoE 层,每层 8 个专家,但每个标记仅激活 2 个专家。尽管每个标记仅激活 130 亿参数,总参数数达 460 亿,以 FP16 精度部署至少需要 92GB VRAM。
若选择临时加载,每个专家大小为 1.76 亿,单个解码步骤加载所需专家需传输高达 113 亿参数。若卸载到 CPU 内存,使用 PCIe 4.0×16 的 A100 GPU 每步仍会产生 0.7 秒的传输延迟。卸载到磁盘则会导致每步超过 10 秒的不可接受延迟。
更重要的是,由于专家选择由路由器动态决定,当批量大小 > 1 时,不同样本选择的专家极可能不同。这需要将所有选定专家(批量大小较大时可能为所有专家)加载到 VRAM 中,不仅增加 VRAM 使用,还进一步加剧通信延迟。
专家需要加载到 VRAM 的原因在于它们参与依赖 GPU 的计算。换言之,若专家无需计算,则无需加载,从而避免显著的通信开销。为解决这一问题,我们引入 MoLE,其专家在推理中可重参数化为免计算的 LUTs。
3.2 训练阶段
如图 2 所示,训练期间,MoLE 与 MoE 结构类似,包含 N 个经路由的专家\(\{FFN_j\}_{j=1}^N\)和线性路由器\(\{r_j\}_{j=1}^N\)。具体而言,MoLE 还包含共享专家 FFN_shared,其对任何输入始终激活,且不接受路由器的加权。
由于专家在训练后将转换为 LUTs,MoLE 与 MoE 的区别如下:首先,LUT 免计算,无需稀疏激活以降低计算成本,因此 MoLE 激活所有专家,而非仅前 k 个专家。路由器的计算为:\(\{g_j\}_{j=1}^N = \text{SoftMax}(\{h \cdot r_i\}_{i=1}^N)\)
其次,由于 LUT 本质上是有限输入-输出对的映射,将专家重参数化为 LUT 的关键在于确保其输入仅有有限可能。为此,MoLE 使用嵌入层的输出(即嵌入标记)作为专家的输入。训练后,嵌入层仅与输入 id 相关,意味着专家的输入限于有限集合。
该层的计算为:\(h' = \sum_{j=1}^N (g_j \cdot FFN_j(e)) + FFN_{\text{shared}}(h) + h\) 其中,\(e = \text{Embedding}(i) \in \mathbb{R}^d\)为嵌入标记,i 表示输入 id。
所有专家在训练期间均被激活并接收梯度,因此无需添加任何辅助损失以防止崩溃或维持训练稳定性。与稠密模型一样,MoLE 仅使用语言建模的交叉熵损失进行训练。
3.3 推理阶段
训练后,MoLE 可像其他 LLM 一样直接用于推理。但为进一步降低 VRAM 开销,可对专家进行重参数化。对于每个可能的输入 id i,预计算专家 FFN_j 的输出:\(v_j^i = FFN_j(\text{Embedding}(i)) \in \mathbb{R}^d\)
实际中,仅需以嵌入层权重作为 FFN_j 的输入进行一次前向传播,即可获得所有 i 的\(v_j^i\)。第 l 层的 LUT 项可表示为:\(\text{LUT}_l = \{\{v_j^i\}_{j=1}^N\}_{i=1}^{|\mathcal{V}|}\) 其中,\(|\mathcal{V}|\)表示词汇量大小。
重参数化后,LUT 卸载到存储设备,MoLE 层的计算可表示为:\(h' = \sum_{j=1}^N (g_j \cdot v_j^i) + FFN_{\text{shared}}(h) + h\)
MoLE 中 LUT 的输入为输入 id,即不包含上下文信息。这是确保专家可重参数化的权衡,但并不意味着专家层不贡献上下文相关知识。
首先,路由器和共享专家仍以中间特征为输入,意味着它们可访问上下文信息。其次,专家层的输出是后续注意力层输入的一部分,使专家能够影响后续注意力的行为。这使专家能够调整模型处理不同上下文中相同单词的方式,从而仍增强模型能力。
3.4 复杂度分析
考虑以基于 MLP 的 FFNs 为专家的 MoE 层。设经路由专家的隐藏层维度为\(D_r\),共享专家的隐藏层维度为\(D_s\)。当单个标记作为输入时,该 MoE 层的 FLOPs 可计算为:\(\text{FLOPs}_{\text{MoE}} = 4d(kD_r + D_s)\) 其中忽略了路由器和归一化层。
为节省 VRAM,假设所有经路由专家均被卸载,则卸载的参数数量为:\(\text{OffParam}_{\text{MoE}} = 2dND_r\)
在最坏情况下,推理期间需要将当前标记路由到的 k 个专家加载到 VRAM 中,每步加载的参数数量为:\(\text{LoadParam}_{\text{MoE}} = 2dkD_r\)
对于 MoLE,由于专家转换为免计算的 LUTs,其 FLOPs 可计算为:\(\text{FLOPs}_{\text{MoLE}} = 4dD_s\)
卸载的 LUT 中包含的参数数量为:\(\text{OffParam}_{\text{MoLE}} = dN|\mathcal{V}|\)
每个推理步骤中,仅需将公式(8)中的所有\(v_j^i\)加载到 VRAM,因此加载的参数数量仅为:\(\text{LoadParam}_{\text{MoLE}} = dN\)

我们在表 1 中总结了所有这些比较。由于\(|\mathcal{V}|\)通常为数万量级(例如,Mixtral 的\(|\mathcal{V}|=3.2万\)(Jiang 等人,2024),Pythia 的\(|\mathcal{V}|=5万\)(Biderman 等人,2023)),且\(D_r\)根据模型规模从数千到数万不等,MoE 和 MoLE 的卸载参数数量不会相差一个数量级。然而,MoLE 中每个标记加载的参数数量仅为 MoE 中每个标记加载参数数量的一小部分 —— 通常小数百甚至数千倍。
4. 实验
4.1 实验设置
模型架构。如表 2 所示,我们实现了激活参数计数为 1.6 亿、4.1 亿和 10 亿的模型。对于稠密模型,我们基本遵循 Pythia(Biderman 等人,2023)的设置。
对于 MoE 模型,我们采用类似 Mixtral 的配置,无共享专家并激活前 2 个经路由专家,因为 Muennighoff 等人(2024)建议共享专家会导致性能下降。
为确保激活参数数量与稠密模型相同,MoE FFNs 的隐藏维度设置为稠密模型 FFNs 隐藏维度的一半。
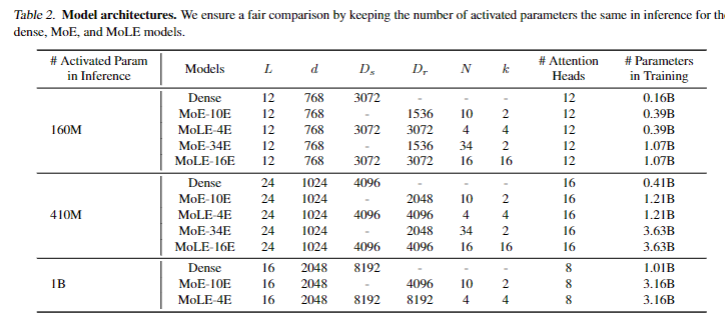
对于 MoLE 模型,由于经路由专家在推理期间无需计算,我们使用与稠密模型 FFNs 相同的 FFNs 作为共享专家,以保持与稠密模型相同的 FLOPs。
对于经路由专家,由于其隐藏维度在推理期间不影响模型架构,为简单起见,将其设置为与共享专家相同。我们实现了具有 10 和 34 个专家的 MoE,以及具有 4 和 16 个专家的 MoLE 进行比较。
数据与分词器。我们在去重后的 Pile 数据集(Gao 等人,2021)的 1000 亿标记子集上训练所有模型,使用 Pythia 采用的 GPT-NeoX 分词器,词汇量为 5 万。
超参数。我们遵循 Pythia 使用的学习率设置,具体而言,激活参数为 1.6 亿的模型使用\(6.0×10^{-4}\),激活参数为 4.1 亿和 10 亿的模型使用\(3.0×10^{-4}\)。对于 MoE 模型,z-loss 和负载平衡损失的系数分别设置为 0.001 和 0.01,如 Muennighoff 等人(2024)所建议。
基准。我们使用 lm-evaluation-harness 包进行评估。使用的基准包括 ARC-C(Clark 等人,2018)、ARC-E(Clark 等人,2018)、BoolQ(Clark 等人,201
我们使用 lm-evaluation-harness 包进行评估。使用的基准包括 ARC-C(Clark 等人,2018)、ARC-E(Clark 等人,2018)、BoolQ(Clark 等人,2019)、HellaSwag(Zellers 等人,2019)、PIQA(Bisk 等人,2020)、RACE(Lai 等人,2017)、SIQA(Sap 等人,2019)和 LAMBADA(Paperno 等人,2016)。对于所有这些基准,我们报告零样本准确率。
卸载设置。为衡量不同模型在 VRAM 受限环境中的部署效率,我们对 MoE 和 MoLE 均应用卸载策略,确保其 VRAM 使用与具有相同激活参数数量的稠密模型一致。对于 MoE 模型,我们采用专家卸载策略,仅在 VRAM 中存储激活专家的参数和所有非专家参数。
在每个推理步骤中,若所需激活专家不在 VRAM 中,则从存储设备加载到 VRAM,替换先前加载的专家。对于 MoLE,我们卸载 LUT,同时将其他参数存储在 VRAM 中。
4.2 主要结果
如表 3 所示,MoE 和 MoLE 均显著优于稠密基线模型。在五组具有相同训练参数数量的 MoLE 和 MoE 模型比较中,MoLE 在五组中的四组平均准确率优于 MoE。值得注意的是,对于激活参数为 1.6 亿、4.1 亿和 10 亿的 MoLE-16E,每个标记加载的参数数量分别仅为 MoE 的约 1/1500、1/2000 和 1/2000。这表明 MoLE 可在显著降低通信开销的同时保持优异性能,使其能够卸载到较低层级的存储设备。
| 模型 | 卸载参数(B) | 每标记加载参数(M) | ARC-C | ARC-E | BoolQ | HellaSwag | PIQA | RACE | SIQA | LAMBADA | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.6 亿激活参数(VRAM 内) | |||||||||||
| 稠密模型 | 0B | 0M | 20.3 | 45.9 | 57.1 | 29.7 | 64.0 | 29.4 | 37.8 | 26.2 | 38.8 |
| MoE-10E | 0.3B | 57M | 21.7 | 49.5 | 51.6 | 32.0 | 66.8 | 30.6 | 39.1 | 31.0 | 40.3 |
| MoLE-4E | 1.8B | 0.037M | 21.9 | 48.5 | 60.7 | 31.2 | 65.1 | 29.4 | 38.4 | 31.1 | 40.8 |
| MoE-34E | 1.0B | 57M | 20.5 | 50.0 | 57.5 | 34.5 | 67.3 | 28.6 | 39.9 | 36.4 | 41.8 |
| MoLE-16E | 7.4B | 0.15M | 22.4 | 48.6 | 60.3 | 32.7 | 68.3 | 30.9 | 38.6 | 33.3 | 41.9 |
| 4.1 亿激活参数(VRAM 内) | |||||||||||
| 稠密模型 | 0B | 0M | 21.8 | 50.8 | 56.8 | 33.8 | 66.5 | 29.6 | 39.2 | 36.2 | 41.8 |
| MoE-10E | 1.0B | 201M | 24.1 | 53.5 | 54.5 | 37.1 | 69.0 | 30.8 | 40.8 | 41.5 | 43.9 |
| MoLE-4E | 4.9B | 0.098M | 22.0 | 54.8 | 61.1 | 35.9 | 69.6 | 30.9 | 40.1 | 42.2 | 44.6 |
| MoE-34E | 3.4B | 201M | 25.0 | 57.0 | 59.7 | 39.9 | 71.5 | 32.3 | 40.4 | 47.1 | 46.6 |
| MoLE-16E | 19.7B | 0.39M | 23.6 | 57.0 | 60.9 | 37.6 | 70.8 | 32.0 | 40.2 | 43.5 | 45.7 |
| 10 亿激活参数(VRAM 内) | |||||||||||
| 稠密模型 | 0B | 0M | 24.1 | 56.9 | 52.8 | 37.6 | 69.5 | 31.6 | 39.1 | 43.1 | 44.3 |
| MoE-10E | 2.7B | 537M | 25.9 | 57.8 | 53.8 | 40.7 | 72.0 | 33.6 | 41.3 | 48.0 | 46.6 |
| MoLE-4E | 6.6B | 0.26M | 25.5 | 58.8 | 61.7 | 39.8 | 71.7 | 32.1 | 40.9 | 48.3 | 47.4 |
我们注意到,MoLE 中 LUT 的大小是 MoE 中卸载专家大小的 2.4 至 7.4 倍。然而,由于这些参数卸载到可扩展的大型存储设备,我们认为 LUT 的存储开销仍在可接受范围内。
具体而言,随着模型规模增大,LUT 的比例也相应降低。在激活参数为 10 亿的模型上,MoLE-4E 的 LUT 大小与 MoE 中的专家大小相当。
4.3 消融实验
训练损失。与 MoE 不同,MoLE 是完全可微的模型,因此在训练期间不会遇到路由器崩溃或不稳定等问题。因此,我们不使用任何额外的辅助损失。
为说明这一点,我们尝试添加 MoE 的负载平衡损失和 z-loss。如表 4 所示,添加这些损失后,模型性能下降。这是因为额外损失导致模型的优化目标与推理需求不一致,产生负面影响。
| 训练损失 | ARC-C | ARC-E | BoolQ | HellaSwag | PIQA | RACE | SIQA | LAMBADA | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| 仅 LM 损失(我们的方法) | 22.4 | 48.6 | 60.3 | 32.7 | 68.3 | 30.9 | 38.6 | 33.3 | 41.9 |
| LM 损失 + 负载平衡损失 | 21.2 | 50.8 | 60.2 | 32.4 | 66.5 | 31.5 | 37.7 | 33.1 | 41.7 |
| LM 损失 + 负载平衡损失 + z-loss | 20.7 | 50.5 | 51.7 | 32.5 | 67.7 | 30.8 | 38.2 | 32.5 | 40.6 |
专家数量和规模。我们实验了不同的专家规模和数量。如表 5 所示,当专家的隐藏维度从 d 增加到 4d 时,模型性能提升。然而,进一步将维度增加到 16d 导致性能饱和。这是因为增加专家规模不影响推理期间重参数化的模型或 LUT 的大小。这表明,固定大小的 LUT 中嵌入的知识随着专家规模的增加达到饱和,即没有 “免费的午餐”—— 专家规模的进一步增加不会带来额外的性能提升。
与规模增加不同,专家数量的增加导致性能持续提升,表明一定程度的可扩展性。同时,LUT 的大小和传输的参数数量也将成比例增加。
| Dr | 训练参数(B) | 卸载参数(B) | 每标记加载参数(M) | ARC-C | ARC-E | BoolQ | HellaSwag | PIQA | RACE | SIQA | LAMBADA | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 768 | 0.4B | 7.4B | 0.15M | 20.6 | 48.1 | 58.7 | 31.4 | 66.9 | 30.3 | 38.7 | 31.9 | 40.8 |
| 3072 | 1.1B | 7.4B | 0.15M | 22.4 | 48.6 | 60.3 | 32.7 | 68.3 | 30.9 | 38.6 | 33.3 | 41.9 |
| 12288 | 3.8B | 7.4B | 0.15M | 21.8 | 52.4 | 58.1 | 33.1 | 67.6 | 29.2 | 38.7 | 32.3 | 41.7 |
| N | 训练参数(B) | 卸载参数(B) | 每标记加载参数(M) | ARC-C | ARC-E | BoolQ | HellaSwag | PIQA | RACE | SIQA | LAMBADA | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 0.3B | 0.9B | 0.02M | 19.5 | 48.2 | 57.7 | 30.2 | 64.7 | 29.5 | 38.1 | 29.4 | 39.7 |
| 4 | 0.4B | 1.8B | 0.04M | 21.9 | 48.5 | 60.7 | 31.2 | 65.1 | 29.4 | 38.4 | 31.1 | 40.8 |
| 8 | 0.6B | 3.7B | 0.07M | 19.4 | 50.5 | 60.2 | 32.0 | 66.4 | 29.9 | 37.4 | 32.6 | 41.1 |
| 16 | 1.1B | 7.4B | 0.15M | 22.4 | 48.6 | 60.3 | 32.7 | 68.3 | 30.9 | 38.6 | 33.3 | 41.9 |
| 32 | 2.0B | 14.7B | 0.29M | 21.8 | 53.1 | 59.0 | 33.5 | 68.4 | 30.7 | 38.8 | 33.0 | 42.3 |
架构设计。为确保经路由专家可重参数化,我们将经路由专家的输入从中间特征改为嵌入标记。直观上,此修改意味着专家仅接收原始词特征,无上下文相关信息,可能导致模型性能下降。但另一方面,由于重参数化的专家在推理阶段无需计算,我们可在保持模型推理 FLOPs 不变的同时激活所有专家,这有助于补偿上述性能损失。为对此进行消融研究,我们训练了以下从 MoE-10E(1.6 亿激活参数)演化而来的模型变体:
- 完全激活:激活 MoE-10E 的所有专家,导致激活参数数量从 0.16B 增加到 0.39B,同时丢弃所有辅助损失。
- 重新配置:基于上述模型,将专家从 10 个经路由专家修改为 1 个共享专家和 4 个经路由专家,此外,专家的隐藏维度增加到原始大小的两倍,总参数数量保持不变。
- 嵌入作为输入:基于上述模型,将经路由专家的输入改为嵌入标记。
- 重参数化:基于上述模型,将经路由专家重参数化为 LUTs,推理期间激活参数数量恢复为 0.16B,该模型称为 MoLE-4E。
如表所示,使用嵌入标记作为经路由专家的输入仅导致 0.7 的性能下降,但带来显著优势,即使专家可重参数化,允许激活所有专家。完全激活的 MoE 相比前 2 个专家的 MoE 性能提升 1.5,导致 MoLE 整体性能优于 MoE。
| 模型 | 训练参数(B) | 推理中激活参数(B) | ARC-C | ARC-E | BoolQ | HellaSwag | PIQA | RACE | SIQA | LAMBADA | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MoE-10E | 0.39B | 0.16B | 21.7 | 49.5 | 51.6 | 32.0 | 66.8 | 30.6 | 39.1 | 31.0 | 40.3 |
| + 完全激活 | 0.39B | 0.39B | 21.6 | 50.2 | 58.6 | 33.3 | 66.8 | 30.5 | 39.6 | 33.5 | 41.8 |
| + 重新配置 | 0.39B | 0.39B | 21.5 | 48.7 | 58.0 | 32.7 | 67.5 | 31.1 | 38.5 | 33.7 | 41.5 |
| + 嵌入作为输入 | 0.39B | 0.39B | 21.9 | 48.5 | 60.7 | 31.2 | 65.1 | 29.4 | 38.4 | 31.1 | 40.8 |
| + 重参数化 = MoLE-4E | 0.39B | 0.16B | 21.9 | 48.5 | 60.7 | 31.2 | 65.1 | 29.4 | 38.4 | 31.1 | 40.8 |
4.4 效率
我们使用 Huggingface 的 transformers 包在 NVIDIA V100 GPU 上测量具有 4.1 亿激活参数的模型的每步解码延迟。由于参数加载的具体速度在很大程度上受底层实现影响,我们基于 V100 的最大 PCIe 带宽 16GB/s 估计加载参数的延迟。对于 MoE 模型,当批量大小为 1 时,前一解码步骤中激活的专家保留在 VRAM 中。当批量大小大于 1 时,每层从前一解码步骤中激活的专家中随机保留两个在 VRAM 中。如果当前步骤中激活的专家与 VRAM 中的专家重叠,则不会重新加载。在此设置下,批量大小为 1、8 和 32 时,MoE-10E 每步加载的专家平均数量分别为 1.6、6.7 和 8.0,MoE-34E 分别为 1.9、12.3 和 27.4。输入长度固定为 512。
如图 3 所示,MoLE 的延迟与稠密模型相当,而 MoE 的延迟显著高于稠密模型。随着批量大小增加,加载的专家数量也增加,进一步增加 MoE 的延迟,但 MoLE 的延迟几乎没有增加。
4.5 减小 LUT 大小
尽管 MoLE 相比 MoE 在卸载场景中显著减少数据传输,但其存储占用较大。虽然存储空间可能不如 VRAM 受限,减小 LUT的大小仍可减轻部署负担。为解决这一问题,我们进行了一项简单的 LUT 压缩实验。我们对 FP16 的 LUT 应用训练后量化,将其量化为 NF4 和 NF3(Dettmers 等人,2023)数据类型,量化的标记块大小分别为 768 和 128。如表 8 所示,模型性能仅有轻微损失,而存储负担和传输数据大小分别减少至原始大小的 25.3% 和 19.5%。这表明 LUT 仍包含显著冗余,具有进一步压缩的潜力。我们将此作为未来工作。
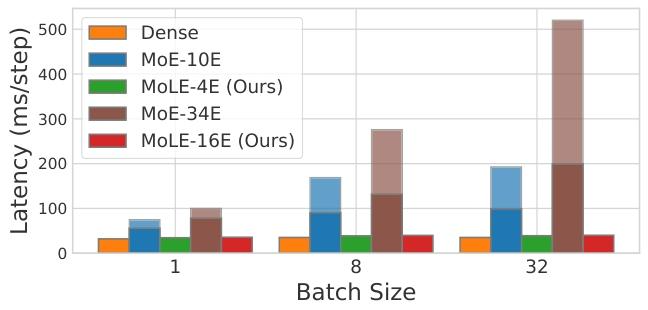
图3. 解码延迟。我们对MoE使用了专家卸载策略。条形图的浅色部分表示由加载操作导致的延迟。
| LUT 精度 | 卸载参数大小 | 每秒加载参数大小 | ARC-C | ARC-E | BoolQ | HellaSwag | PIQA | RACE | SIQA | LAMBADA | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FP16 | 3.5GB | 72KB | 21.9 | 48.5 | 60.7 | 31.2 | 65.1 | 29.4 | 38.4 | 31.1 | 40.8 |
| NF4 | 0.9GB | 18KB | 21.5 | 48.5 | 61.7 | 31.3 | 64.7 | 29.6 | 38.6 | 30.9 | 40.9 |
| NF3 | 0.7GB | 14KB | 22.3 | 48.1 | 59.8 | 31.0 | 65.3 | 28.9 | 38.5 | 30.1 | 40.5 |
5. 结论
在本文中,我们通过提出 MoLE 这一新型语言模型架构,解决了 MoE 的高内存消耗和加载延迟问题。MoLE 将专家的输入限制为有限集合(嵌入标记),使专家可在推理前重参数化为 LUTs,从而避免加载专家参数。MoLE 在下游任务上表现出有竞争力的结果,同时在推理速度上显著优于采用专家卸载的 MoE。这项工作为设计适合边缘设备的语言模型提供了新方向。未来研究可探索更多样化的离散空间和专家架构。
影响声明
本文推动了 LLM 的发展,其具有潜在的社会影响,包括对偏见、错误信息和可及性的担忧。随着该领域的发展,持续的伦理监督和跨学科合作至关重要。