Neo4j(三) - 使用Java操作Neo4j详解
文章目录
- 前言
- 一、创建项目
- 二、导入依赖
- 三、节点和关系数据打印
- 四、创建节点与关系
- 五、查询数据方法
- 六、更新数据方法
- 七、删除节点与关系方法
- 八、合并数据方法
- 九、完整代码
- 1. 完整代码
- 2. 项目下载
前言
本文介绍通过 Java 操作 Neo4j 图数据库的完整流程。主要涵盖开发环境搭建、依赖导入、节点与关系的创建、查询、更新、删除及合并等操作,旨在为读者提供从入门到实践的全流程指导。
一、创建项目
在开始使用 Java 操作 Redis 之前,需先搭建开发环境。本章节以 IDEA 为开发工具,演示如何创建一个基于 Maven 的 Java 项目。通过 IDEA 的项目向导,依次选择 Java 项目类型、配置 Maven 管理依赖、指定 JDK 版本,快速生成标准的项目结构,为后续引入 Neo4j 依赖和编写代码做好准备。
打开IDEA,点击文件-->新建-->项目。
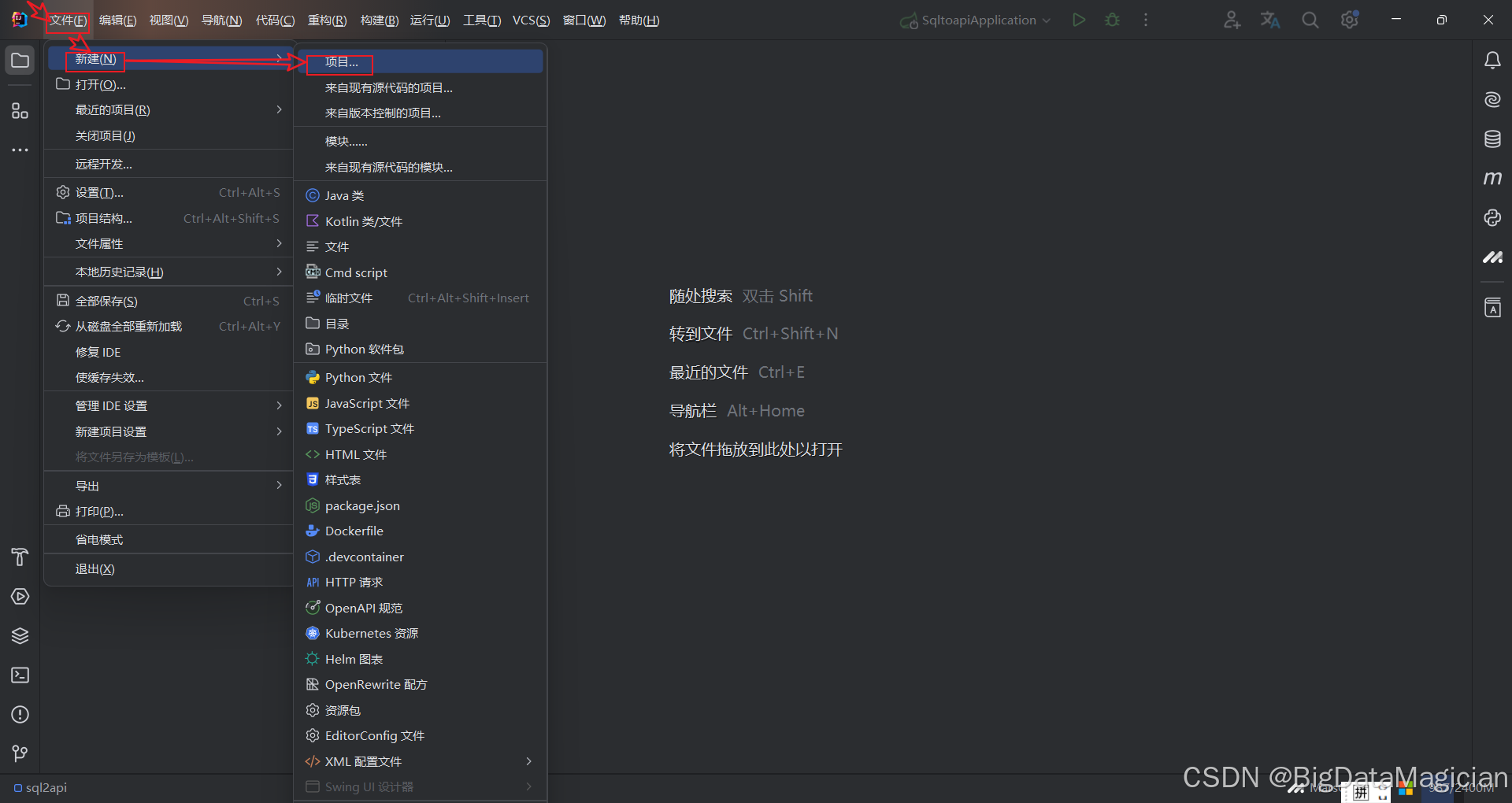
如下图所示,选择Java-->输入项目名-->选择位置-->选择Maven-->选择JDK-->点击创建。
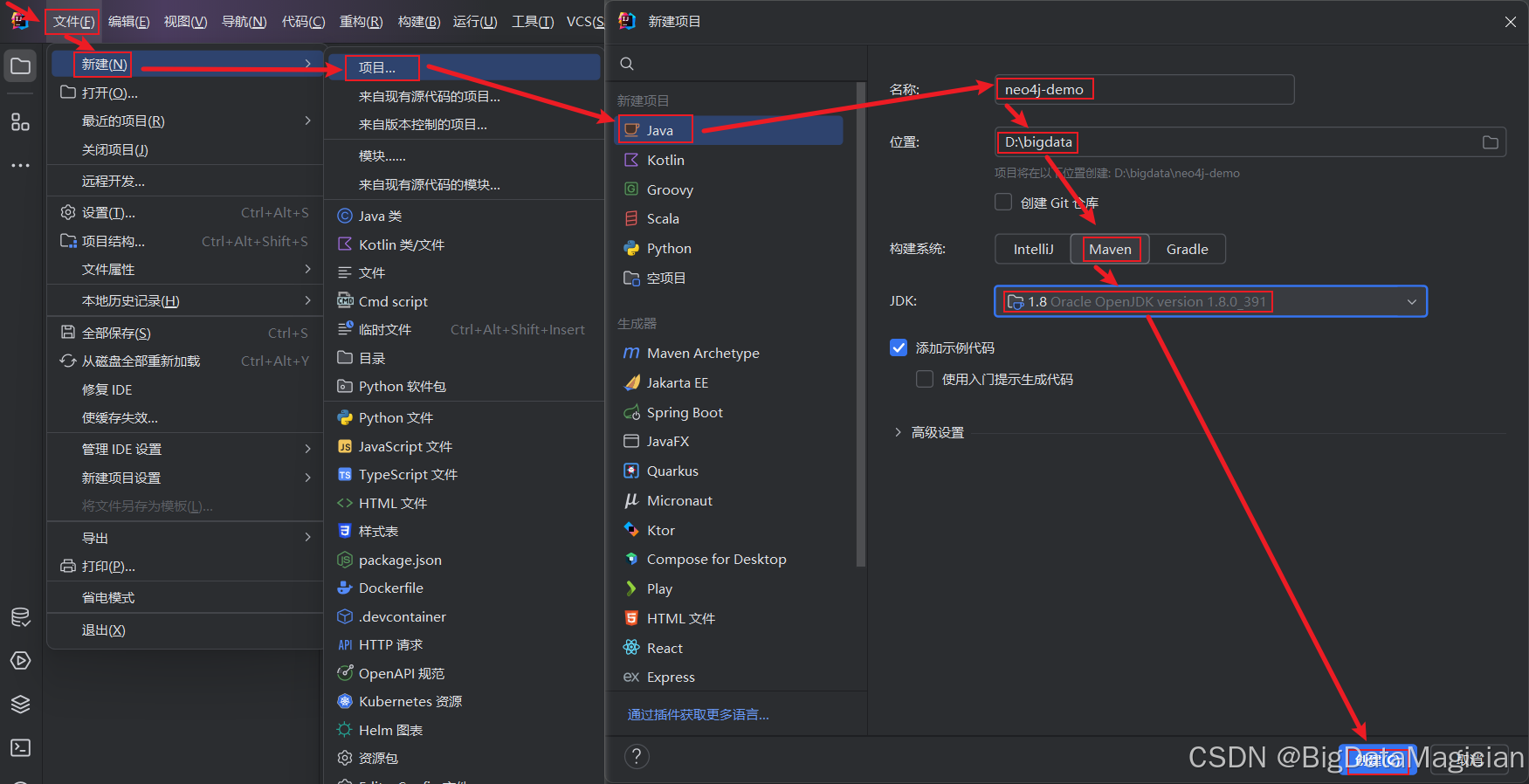
二、导入依赖
介绍 Maven 依赖管理工具的作用,通过在 pom.xml 文件中添加 Neo4j 驱动依赖(neo4j-java-driver),并刷新 Maven 下载相关 Jar 包。此步骤是连接和操作 Neo4j 数据库的必要前提,确保项目能正确调用 Neo4j 的 Java 接口。
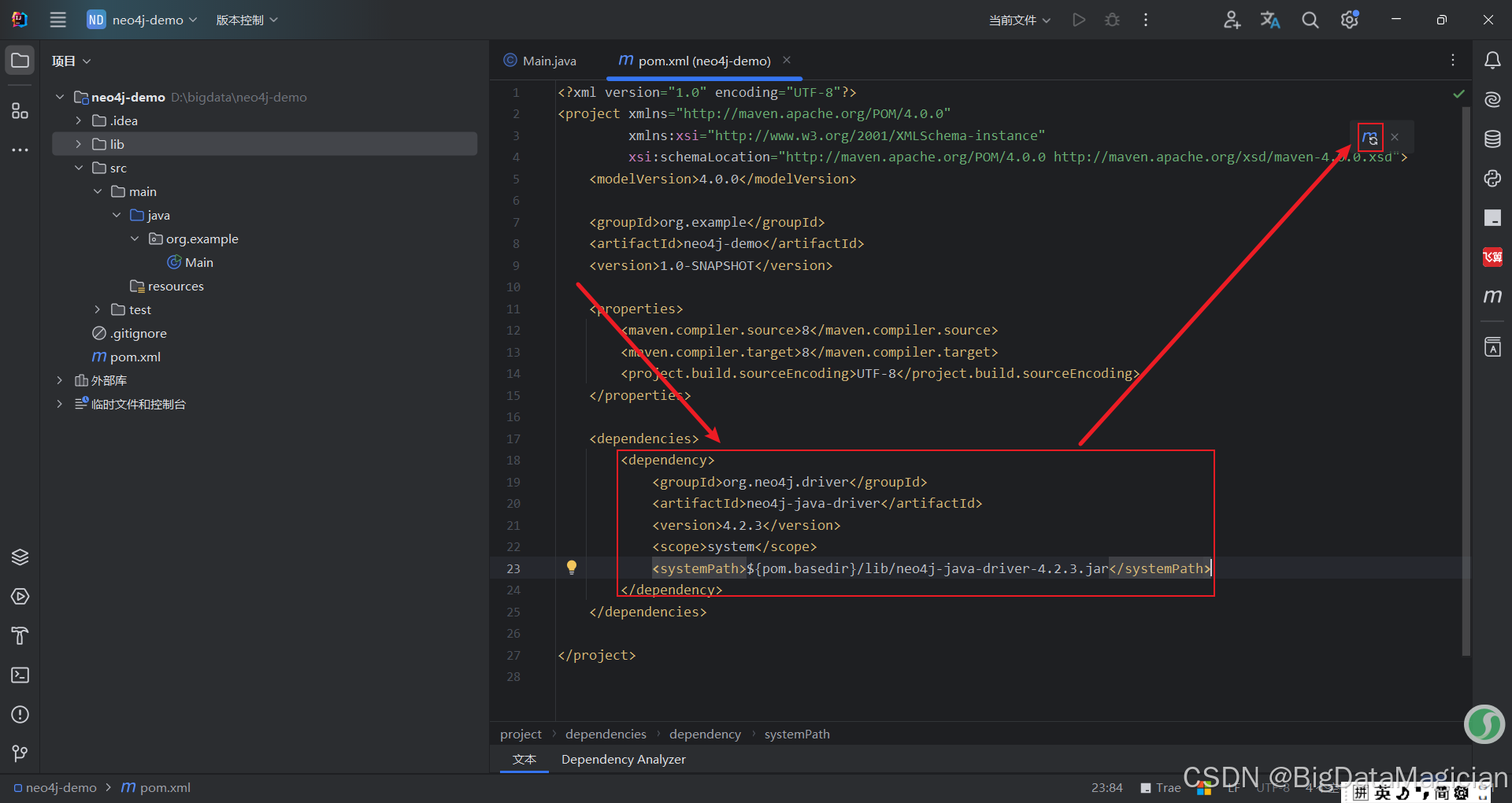
在pom.xml文件中添加如下依赖配置。
<dependencies><dependency><groupId>org.neo4j.driver</groupId><artifactId>neo4j-java-driver</artifactId><version>4.2.3</version></dependency></dependencies>
添加依赖后如下图所示,点击右上角的刷新图标下载配置Neo4j的Java驱动依赖包。
三、节点和关系数据打印
定义两个工具方法 printNodeData 和 printRelationshipData,分别用于打印节点和关系的详细信息(如 ID、标签、属性、起始节点、关系类型等)。这些方法在后续操作中用于验证数据的正确性,帮助开发者直观查看数据库中的节点和关系结构。
public static void printNodeData(String val, Record record) {System.out.println("identity:" + record.get(val).asNode().id());System.out.println("labels:" + record.get(val).asNode().labels());System.out.println("properties:" + record.get(val).asNode().asMap());}public static void printRelationshipData(String val, Record record) {System.out.println("identity:" + record.get(val).asRelationship().id());System.out.println("start:" + record.get(val).asRelationship().startNodeId());System.out.println("end:" + record.get(val).asRelationship().endNodeId());System.out.println("type:" + record.get(val).asRelationship().type());System.out.println("properties:" + record.get(val).asRelationship().asMap());}
四、创建节点与关系
提供多个示例演示如何通过 Cypher 语句创建节点和关系:
- 创建单个节点(含属性);
- 创建多个节点并建立单向 / 双向关系;
- 使用已存在节点创建关系。
- 通过 session.run() 执行 Cypher 语句,并输出操作结果,展示 Neo4j 图数据模型的灵活性。
public static void createOperation(Session session) {// 示例 1:创建一个简单的节点Result run1 = session.run("CREATE (a:Person {name: 'Alice', age: 30})");System.out.println(run1.consume());// 示例 2:创建两个节点并建立关系Result run2 = session.run("CREATE (a:Person {name: 'Alice'}) " + "CREATE (b:Person {name: 'Bob'}) " + "CREATE (a)-[r:FRIENDS_WITH {since: 2020}]->(b)");System.out.println(run2.consume());// 示例 3:在一个命令中创建节点和关系Result run3 = session.run("CREATE (a:Person {name: 'Alice'})-[:WORKS_AT]->(b:Company {name: 'Tech Corp'})");System.out.println(run3.consume());// 示例 4:使用已存在的节点创建关系Result run4 = session.run("MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'}) " + "CREATE (a)-[r:COLLEAGUE_OF {department: 'Engineering'}]->(b)");System.out.println(run4.consume());// 示例 5:创建双向关系Result run5 = session.run("MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'}) " + "CREATE (a)-[:KNOWS]->(b) " + "CREATE (b)-[:KNOWS]->(a)");System.out.println(run5.consume());}
五、查询数据方法
详细列举多种查询场景,涵盖基础查询到复杂过滤:
- 查询所有节点、特定属性节点;
- 关联查询节点及其关系;
- 使用 WHERE 过滤条件、模糊匹配关系类型;
- 限制结果数量(LIMIT)和分页(SKIP)。
- 通过遍历 Result 对象并调用打印方法,展示查询结果的解析和呈现方式。
private static void matchOperation(Session session) {// 示例 1:查询所有 Person 节点System.out.println("查询所有 Person 节点:");Result result1 = session.run("MATCH (p:Person) RETURN p");while (result1.hasNext()) {Record record = result1.next();System.out.println("=========================");printNodeData("p", record);}// 示例 2:查询具有特定属性的节点System.out.println("查询具有特定属性的节点:");Result result2 = session.run("MATCH (p:Person {name: 'Alice'}) RETURN p");while (result2.hasNext()) {Record record = result2.next();System.out.println("=========================");printNodeData("p", record);}// 示例 3:查询节点和其关系System.out.println("查询节点和其关系:");Result result3 = session.run("MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person) RETURN a, r, b");while (result3.hasNext()) {Record record = result3.next();System.out.println("===========a===========");printNodeData("a", record);System.out.println("===========r===========");printRelationshipData("r", record);System.out.println("===========b===========");printNodeData("b", record);}// 示例 4:仅返回某些字段或属性System.out.println("仅返回某些字段或属性:");Result result4 = session.run("MATCH (p:Person) RETURN p.name, p.age");while (result4.hasNext()) {Record record = result4.next();System.out.println(record.get("p.name") + " " + record.get("p.age"));}// 示例 5:使用 WHERE 过滤年龄大于 25 的人System.out.println("使用 WHERE 过滤年龄大于 25 的人:");Result result5 = session.run("MATCH (p:Person) WHERE p.age > 25 RETURN p.name, p.age");while (result5.hasNext()) {Record record = result5.next();System.out.println(record.get("p.name") + " " + record.get("p.age"));}// 示例 6:查找双向关系(比如互为好友)System.out.println("查找双向关系(比如互为好友):");Result result6 = session.run("MATCH (a:Person {name: 'Alice'})-[r1:KNOWS]->(b:Person {name: 'Bob'}) " + "MATCH (b)-[r2:KNOWS]->(a) RETURN a, r1, b, r2");while (result6.hasNext()) {Record record = result6.next();System.out.println("===========a===========");printNodeData("a", record);System.out.println("===========r1===========");printRelationshipData("r1", record);System.out.println("===========b===========");printNodeData("b", record);System.out.println("===========r2===========");printRelationshipData("r2", record);}// 示例 7:模糊匹配多个关系类型System.out.println("模糊匹配多个关系类型:");Result result7 = session.run("MATCH (a:Person {name: 'Alice'})-[:KNOWS|WORKS_WITH]->(b) RETURN b.name");while (result7.hasNext()) {Record record = result7.next();System.out.println(record.get("b.name"));}// 示例 8:限制返回数量System.out.println("限制返回数量:");Result result8 = session.run("MATCH (p:Person) RETURN p.name LIMIT 3");while (result8.hasNext()) {Record record = result8.next();System.out.println(record.get("p.name"));}// 跳过 1 个查询结果并最多返回 3 个 Person 的名字。System.out.println("跳过 1 个查询结果并最多返回 3 个 Person 的名字:");Result result9 = session.run("MATCH (p:Person) RETURN p.name SKIP 1 LIMIT 3");while (result9.hasNext()) {Record record = result9.next();System.out.println(record.get("p.name"));}}
六、更新数据方法
介绍节点和关系的更新操作:
- 修改节点属性、添加新属性、批量设置属性;
- 删除节点属性或标签;
- 更新关系属性(如修改关系的时间戳)。
通过 SET 和 REMOVE 关键字演示数据更新逻辑,确保开发者掌握动态维护图数据的能力。
private static void updateOperation(Session session) {// 示例 1:更新节点的属性System.out.println("更新节点的属性:");Result result1 = session.run("MATCH (n:Person {name: 'Alice'}) SET n.age = 31 RETURN n");while (result1.hasNext()) {Record record = result1.next();System.out.println("=========================");printNodeData("n", record);}// 示例 2:添加新的属性System.out.println("添加新的属性:");Result result2 = session.run("MATCH (n:Person {name: 'Bob'}) SET n.email = 'bob@example.com' RETURN n");while (result2.hasNext()) {Record record = result2.next();System.out.println("=========================");printNodeData("n", record);}// 示例 3:一次性设置多个属性System.out.println("一次性设置多个属性:");Result result3 = session.run("MATCH (n:Person {name: 'Bob'}) SET n.age = 45, n.city = 'Shanghai', n.job = 'Engineer' RETURN n");while (result3.hasNext()) {Record record = result3.next();System.out.println("=========================");printNodeData("n", record);}// 示例 4:删除节点的某个属性System.out.println("删除节点的某个属性:");Result result4 = session.run("MATCH (n:Person {name: 'Alice'}) REMOVE n.age RETURN n");while (result4.hasNext()) {Record record = result4.next();System.out.println("=========================");printNodeData("n", record);}// 示例 5:删除节点的标签System.out.println("删除节点的标签:");Result result5 = session.run("MATCH (n:Person {name: 'Bob'}) REMOVE n:Person SET n:User RETURN n");while (result5.hasNext()) {Record record = result5.next();System.out.println("=========================");printNodeData("n", record);}// 示例 6:更新关系属性System.out.println("更新关系属性:");Result result6 = session.run("MATCH (:Person {name: 'Alice'})-[r:KNOWS]->(:User {name: 'Bob'}) SET r.since = 2021 RETURN r");while (result6.hasNext()) {Record record = result6.next();System.out.println("=========================");printRelationshipData("r", record);}}
七、删除节点与关系方法
演示不同维度的删除操作:
- 删除特定节点间的关系;
- 删除指定类型的所有关系;
- 级联删除节点及其关联关系(DETACH DELETE);
- 清除孤立节点或整个图数据库。
强调删除操作的谨慎性,尤其是清空数据的场景需特别注意。
private static void deleteOperation(Session session) {// 示例 1:删除两个特定节点之间的关系System.out.println("删除两个特定节点之间的关系:");session.run("MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person {name: 'Bob'}) DELETE r");// 示例 2:删除特定类型的关系System.out.println("删除特定类型的关系:");session.run("MATCH ()-[r:KNOWS]->() DELETE r");// 示例 3:删除某个特定节点(先删除关系)System.out.println("删除某个特定节点(先删除关系):");session.run("MATCH (n:Person {name: 'Alice'}) DETACH DELETE n");// 示例 4:删除没有关系的孤立节点System.out.println("删除没有关系的孤立节点:");session.run("MATCH (n) WHERE NOT EXISTS((n)--()) DELETE n");// 示例 5:删除所有节点和关系(清空整个图数据库)System.out.println("删除所有节点和关系(清空整个图数据库):");session.run("MATCH (n) DETACH DELETE n");}
八、合并数据方法
讲解 MERGE 语句的使用场景,确保节点或关系存在(若不存在则创建,存在则匹配):
- 确保单个节点存在并设置属性;
- 区分创建与更新操作(ON CREATE/ON MATCH);
- 合并带属性的关系,避免重复数据。
通过 MERGE 实现数据的幂等性操作,适用于需要保证数据唯一性的场景。
private static void mergeOperation(Session session) {// 示例 1:确保某节点存在(若不存在则创建)System.out.println("确保某节点存在(若不存在则创建):");Result result1 = session.run("MERGE (p:Person {name: 'Alice'}) RETURN p");while (result1.hasNext()) {Record record = result1.next();System.out.println("=========================");printNodeData("p", record);}// 示例 2:确保节点存在,并设置额外属性System.out.println("确保节点存在,并设置额外属性:");Result result2 = session.run("MERGE (p:Person {name: 'Bob'}) SET p.age = 30 RETURN p");while (result2.hasNext()) {Record record = result2.next();System.out.println("=========================");printNodeData("p", record);}// 示例 3:使用 ON CREATE 和 ON MATCH 区分创建与更新操作System.out.println("使用 ON CREATE 和 ON MATCH 区分创建与更新操作:");Result result3 = session.run("MERGE (p:Person {name: 'Charlie'}) " + "ON CREATE SET p.created = datetime() " + "ON MATCH SET p.lastSeen = datetime() " + "RETURN p");while (result3.hasNext()) {Record record = result3.next();System.out.println("=========================");printNodeData("p", record);}// 示例 4:合并关系(确保两个节点之间有某种关系)System.out.println("合并关系(确保两个节点之间有某种关系):");Result result4 = session.run("MERGE (a:Person {name: 'Alice'}) " + "MERGE (b:Person {name: 'Bob'}) " + "MERGE (a)-[r:FRIENDS_WITH]->(b) " + "RETURN a, r, b");while (result4.hasNext()) {Record record = result4.next();System.out.println("===========a===========");printNodeData("a", record);}// 示例 5:合并带属性的关系System.out.println("合并带属性的关系:");Result result5 = session.run("MERGE (a:Person {name: 'Alice'}) " + "MERGE (b:Person {name: 'Bob'}) " + "MERGE (a)-[r:WORKS_WITH {since: 2022}]->(b) " + "RETURN r");while (result5.hasNext()) {Record record = result5.next();System.out.println("=========================");printRelationshipData("r", record);}}
九、完整代码
1. 完整代码
提供包含主函数的完整 Java 代码,整合前文所有操作逻辑。
package org.example;import org.neo4j.driver.*;public class Main {public static void main(String[] args) {// 创建Neo4jDriver实例Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "123456"));// 创建Session实例Session session = driver.session();createOperation(session);matchOperation(session);updateOperation(session);deleteOperation(session);mergeOperation(session);// 关闭Session实例session.close();// 关闭Neo4jDriver实例driver.close();}public static void printNodeData(String val, Record record) {System.out.println("identity:" + record.get(val).asNode().id());System.out.println("labels:" + record.get(val).asNode().labels());System.out.println("properties:" + record.get(val).asNode().asMap());}public static void printRelationshipData(String val, Record record) {System.out.println("identity:" + record.get(val).asRelationship().id());System.out.println("start:" + record.get(val).asRelationship().startNodeId());System.out.println("end:" + record.get(val).asRelationship().endNodeId());System.out.println("type:" + record.get(val).asRelationship().type());System.out.println("properties:" + record.get(val).asRelationship().asMap());}public static void createOperation(Session session) {// 示例 1:创建一个简单的节点Result run1 = session.run("CREATE (a:Person {name: 'Alice', age: 30})");System.out.println(run1.consume());// 示例 2:创建两个节点并建立关系Result run2 = session.run("CREATE (a:Person {name: 'Alice'}) " + "CREATE (b:Person {name: 'Bob'}) " + "CREATE (a)-[r:FRIENDS_WITH {since: 2020}]->(b)");System.out.println(run2.consume());// 示例 3:在一个命令中创建节点和关系Result run3 = session.run("CREATE (a:Person {name: 'Alice'})-[:WORKS_AT]->(b:Company {name: 'Tech Corp'})");System.out.println(run3.consume());// 示例 4:使用已存在的节点创建关系Result run4 = session.run("MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'}) " + "CREATE (a)-[r:COLLEAGUE_OF {department: 'Engineering'}]->(b)");System.out.println(run4.consume());// 示例 5:创建双向关系Result run5 = session.run("MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'}) " + "CREATE (a)-[:KNOWS]->(b) " + "CREATE (b)-[:KNOWS]->(a)");System.out.println(run5.consume());}// 2. 查询数据private static void matchOperation(Session session) {// 示例 1:查询所有 Person 节点System.out.println("查询所有 Person 节点:");Result result1 = session.run("MATCH (p:Person) RETURN p");while (result1.hasNext()) {Record record = result1.next();System.out.println("=========================");printNodeData("p", record);}// 示例 2:查询具有特定属性的节点System.out.println("查询具有特定属性的节点:");Result result2 = session.run("MATCH (p:Person {name: 'Alice'}) RETURN p");while (result2.hasNext()) {Record record = result2.next();System.out.println("=========================");printNodeData("p", record);}// 示例 3:查询节点和其关系System.out.println("查询节点和其关系:");Result result3 = session.run("MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person) RETURN a, r, b");while (result3.hasNext()) {Record record = result3.next();System.out.println("===========a===========");printNodeData("a", record);System.out.println("===========r===========");printRelationshipData("r", record);System.out.println("===========b===========");printNodeData("b", record);}// 示例 4:仅返回某些字段或属性System.out.println("仅返回某些字段或属性:");Result result4 = session.run("MATCH (p:Person) RETURN p.name, p.age");while (result4.hasNext()) {Record record = result4.next();System.out.println(record.get("p.name") + " " + record.get("p.age"));}// 示例 5:使用 WHERE 过滤年龄大于 25 的人System.out.println("使用 WHERE 过滤年龄大于 25 的人:");Result result5 = session.run("MATCH (p:Person) WHERE p.age > 25 RETURN p.name, p.age");while (result5.hasNext()) {Record record = result5.next();System.out.println(record.get("p.name") + " " + record.get("p.age"));}// 示例 6:查找双向关系(比如互为好友)System.out.println("查找双向关系(比如互为好友):");Result result6 = session.run("MATCH (a:Person {name: 'Alice'})-[r1:KNOWS]->(b:Person {name: 'Bob'}) " + "MATCH (b)-[r2:KNOWS]->(a) RETURN a, r1, b, r2");while (result6.hasNext()) {Record record = result6.next();System.out.println("===========a===========");printNodeData("a", record);System.out.println("===========r1===========");printRelationshipData("r1", record);System.out.println("===========b===========");printNodeData("b", record);System.out.println("===========r2===========");printRelationshipData("r2", record);}// 示例 7:模糊匹配多个关系类型System.out.println("模糊匹配多个关系类型:");Result result7 = session.run("MATCH (a:Person {name: 'Alice'})-[:KNOWS|WORKS_WITH]->(b) RETURN b.name");while (result7.hasNext()) {Record record = result7.next();System.out.println(record.get("b.name"));}// 示例 8:限制返回数量System.out.println("限制返回数量:");Result result8 = session.run("MATCH (p:Person) RETURN p.name LIMIT 3");while (result8.hasNext()) {Record record = result8.next();System.out.println(record.get("p.name"));}// 跳过 1 个查询结果并最多返回 3 个 Person 的名字。System.out.println("跳过 1 个查询结果并最多返回 3 个 Person 的名字:");Result result9 = session.run("MATCH (p:Person) RETURN p.name SKIP 1 LIMIT 3");while (result9.hasNext()) {Record record = result9.next();System.out.println(record.get("p.name"));}}// 3. 更新数据private static void updateOperation(Session session) {// 示例 1:更新节点的属性System.out.println("更新节点的属性:");Result result1 = session.run("MATCH (n:Person {name: 'Alice'}) SET n.age = 31 RETURN n");while (result1.hasNext()) {Record record = result1.next();System.out.println("=========================");printNodeData("n", record);}// 示例 2:添加新的属性System.out.println("添加新的属性:");Result result2 = session.run("MATCH (n:Person {name: 'Bob'}) SET n.email = 'bob@example.com' RETURN n");while (result2.hasNext()) {Record record = result2.next();System.out.println("=========================");printNodeData("n", record);}// 示例 3:一次性设置多个属性System.out.println("一次性设置多个属性:");Result result3 = session.run("MATCH (n:Person {name: 'Bob'}) SET n.age = 45, n.city = 'Shanghai', n.job = 'Engineer' RETURN n");while (result3.hasNext()) {Record record = result3.next();System.out.println("=========================");printNodeData("n", record);}// 示例 4:删除节点的某个属性System.out.println("删除节点的某个属性:");Result result4 = session.run("MATCH (n:Person {name: 'Alice'}) REMOVE n.age RETURN n");while (result4.hasNext()) {Record record = result4.next();System.out.println("=========================");printNodeData("n", record);}// 示例 5:删除节点的标签System.out.println("删除节点的标签:");Result result5 = session.run("MATCH (n:Person {name: 'Bob'}) REMOVE n:Person SET n:User RETURN n");while (result5.hasNext()) {Record record = result5.next();System.out.println("=========================");printNodeData("n", record);}// 示例 6:更新关系属性System.out.println("更新关系属性:");Result result6 = session.run("MATCH (:Person {name: 'Alice'})-[r:KNOWS]->(:User {name: 'Bob'}) SET r.since = 2021 RETURN r");while (result6.hasNext()) {Record record = result6.next();System.out.println("=========================");printRelationshipData("r", record);}}// 4. 删除节点与关系private static void deleteOperation(Session session) {// 示例 1:删除两个特定节点之间的关系System.out.println("删除两个特定节点之间的关系:");session.run("MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person {name: 'Bob'}) DELETE r");// 示例 2:删除特定类型的关系System.out.println("删除特定类型的关系:");session.run("MATCH ()-[r:KNOWS]->() DELETE r");// 示例 3:删除某个特定节点(先删除关系)System.out.println("删除某个特定节点(先删除关系):");session.run("MATCH (n:Person {name: 'Alice'}) DETACH DELETE n");// 示例 4:删除没有关系的孤立节点System.out.println("删除没有关系的孤立节点:");session.run("MATCH (n) WHERE NOT EXISTS((n)--()) DELETE n");// 示例 5:删除所有节点和关系(清空整个图数据库)System.out.println("删除所有节点和关系(清空整个图数据库):");session.run("MATCH (n) DETACH DELETE n");}// 5. 合并数据private static void mergeOperation(Session session) {// 示例 1:确保某节点存在(若不存在则创建)System.out.println("确保某节点存在(若不存在则创建):");Result result1 = session.run("MERGE (p:Person {name: 'Alice'}) RETURN p");while (result1.hasNext()) {Record record = result1.next();System.out.println("=========================");printNodeData("p", record);}// 示例 2:确保节点存在,并设置额外属性System.out.println("确保节点存在,并设置额外属性:");Result result2 = session.run("MERGE (p:Person {name: 'Bob'}) SET p.age = 30 RETURN p");while (result2.hasNext()) {Record record = result2.next();System.out.println("=========================");printNodeData("p", record);}// 示例 3:使用 ON CREATE 和 ON MATCH 区分创建与更新操作System.out.println("使用 ON CREATE 和 ON MATCH 区分创建与更新操作:");Result result3 = session.run("MERGE (p:Person {name: 'Charlie'}) " + "ON CREATE SET p.created = datetime() " + "ON MATCH SET p.lastSeen = datetime() " + "RETURN p");while (result3.hasNext()) {Record record = result3.next();System.out.println("=========================");printNodeData("p", record);}// 示例 4:合并关系(确保两个节点之间有某种关系)System.out.println("合并关系(确保两个节点之间有某种关系):");Result result4 = session.run("MERGE (a:Person {name: 'Alice'}) " + "MERGE (b:Person {name: 'Bob'}) " + "MERGE (a)-[r:FRIENDS_WITH]->(b) " + "RETURN a, r, b");while (result4.hasNext()) {Record record = result4.next();System.out.println("===========a===========");printNodeData("a", record);}// 示例 5:合并带属性的关系System.out.println("合并带属性的关系:");Result result5 = session.run("MERGE (a:Person {name: 'Alice'}) " + "MERGE (b:Person {name: 'Bob'}) " + "MERGE (a)-[r:WORKS_WITH {since: 2022}]->(b) " + "RETURN r");while (result5.hasNext()) {Record record = result5.next();System.out.println("=========================");printRelationshipData("r", record);}}
}
2. 项目下载
下载地址:https://download.csdn.net/download/zcs2312852665/90889723?spm=1001.2014.3001.5503