Spring AI 之多模态
人类通过多模态数据输入并行处理知识。我们的学习方式和经验本质上都是多模态的——我们并非孤立地处理视觉、听觉或文本信息。
这与传统机器学习形成鲜明对比:过去的研究往往专注于开发单一模态的专用模型。例如,音频模型专攻文本转语音或语音转文本任务,计算机视觉模型则聚焦物体检测与分类等领域。
但新一代多模态大语言模型正在崛起。以OpenAI的GPT-4o、谷歌Vertex AI Gemini 1.5、Anthropic的Claude3为代表,以及开源界的Llama3.2、LLaVA和BakLLaVA等模型,现已具备接收文本、图像、音频和视频等多模态输入,并能融合这些信息生成文本响应的能力。
多模态大语言模型(LLM)功能使模型能够结合图像、音频或视频等其他模态处理和生成文本。
Spring AI 多模态支持
多模态(Multimodality)指模型能够同时理解并处理来自文本、图像、音频等多种数据源信息的能力。
Spring AI 消息 API 提供了完整的抽象层,全面支持多模态大语言模型。
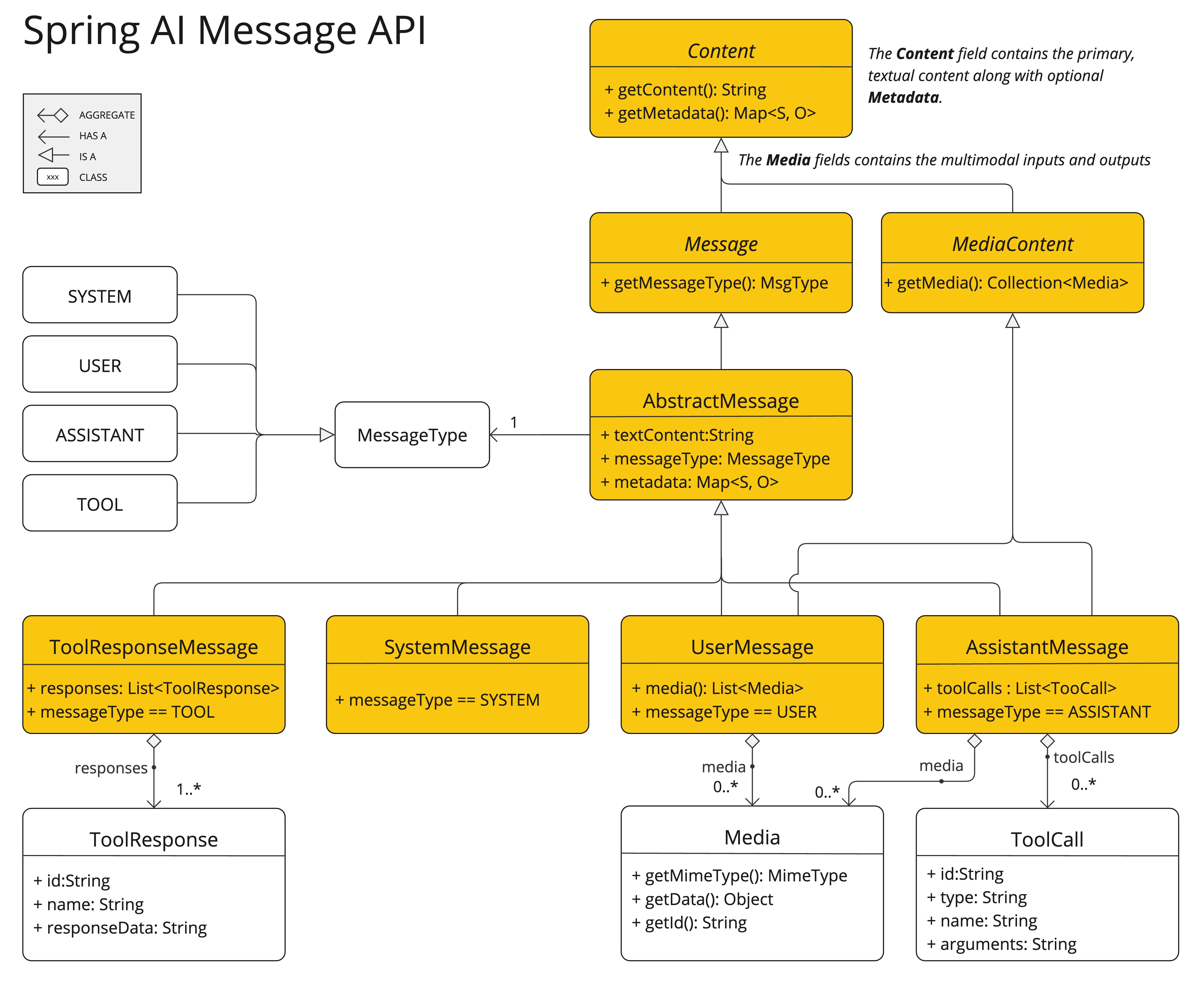
用户消息(UserMessage)的content字段主要用于文本输入,而可选的media字