transformer
循环神经网络RNN
专门用于处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有循环连接,能够捕捉序列数据中的时间依赖关系。使RNN能处理自然语音处理、语音识别、时间序列预测等任务。
也叫递归神经网络,具体内容查看前一篇递归神经网络。
transformer
简介
- 2017年谷歌在Attention Is All You Need论文中提出,基于注意力机制的深度学习模型架构,主要用于自然语言处理任务。
- 核心思想:通过自注意力机制来捕捉输入序列中不同位置之间的依赖关系,避免传统RNN的顺序计算瓶颈。
- 优点:通过高速并行矩阵运算来加快训练和解码的速度。
整体架构
Transformer可以堆叠,越高层的Transformer能学习到越高级更抽象的信息。
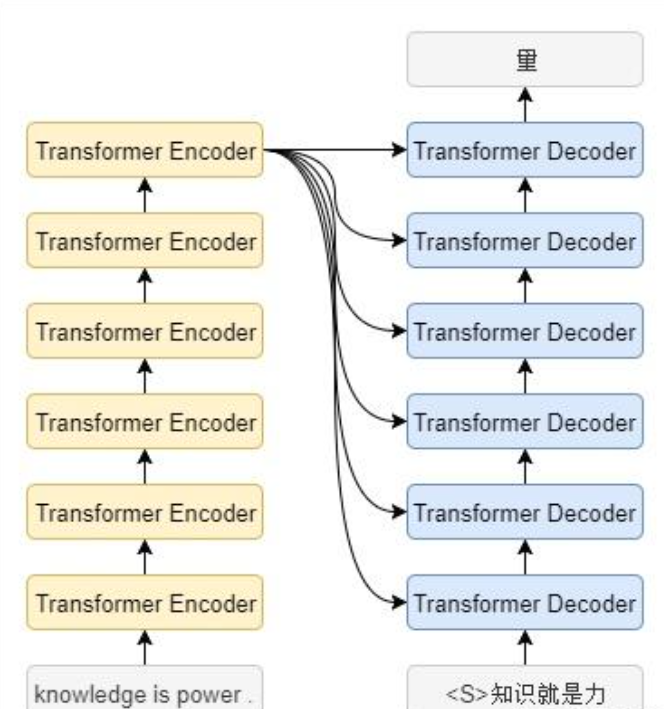
- 编码器
由多个相同层(Encoder Layer)堆叠而成,每一层包含两个子层:多头自注意力机制(multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)。编码器负责将输入序列编码为一个上下文表示。
- 解码器
由多个相同层(Decoder Layer)堆叠而成,每一层包含三个子层:多头自注意力机制、多头编码器-解码器注意力机制(Multi-Head Encoder-Decoder Attention)和前馈神经网络。解码器根据编码器的输出和已生成的部分目标序列生成最终的输出序列。
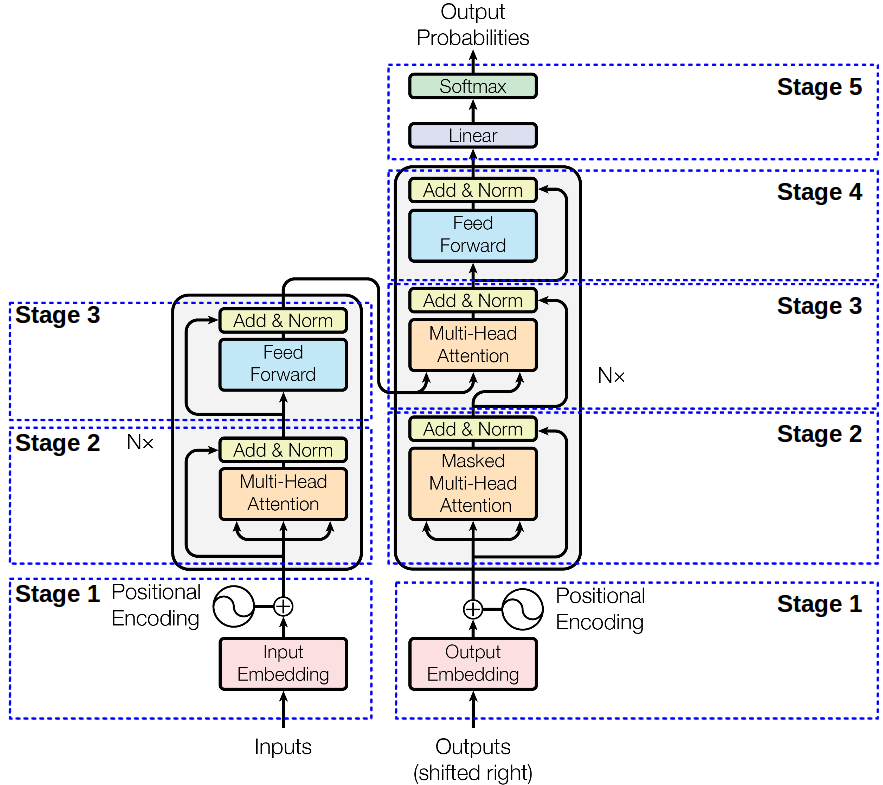
核心组件
编码器
输入部分词向量(Input Embedding)
将离散的单词或字词映射为连续向量表示,每个单词或字词被表示为一个固定维度的向量(如512维)
- 词向量生成方式
- 传统词向量(Word2Vec)
- 静态嵌入:预训练好的词向量(如GloVe)直接作为输入,transformer中较少使用。
- 可学习的嵌入层(Embedding Layer)
- 动态嵌入:Transformer内部通过一个可训练的嵌入层(nn.Embedding)将单词ID映射为向量。模型在训练过程中自动优化这些向量,随着梯度下降不断调整。
- 参数共享:编码器和解码器通常共享同一嵌入层(如BERT),但某些模型(如原始Transformer)可能分开。
- 子词嵌入(Subward Embeddings)
- 解决oov问题:通过Byte Pair Encoding (BPE) 或WordPiece等算法将单词拆分为子词(如"unhappy" → “un” + “happy”),每个子词有自己的向量。
- 词向量特点
- 高维度:通常为模型隐藏层维度(如512或768)。
- 上下文无关:初始词向量是静态的,但经过Transformer的自注意力机制后,会获得上下文相关的表示(如"bank"在不同句子中含义不同)。同一个词在不同上下文中编码也可能不同(训练过程中存在随机操作,词向量可能不同,推理是会一致)。
- 与位置编码结合:词向量会加上位置编码以保留序列顺序信息
模型训练的时候还会更新词向量,为什么?
- 词向量是通过一个可训练的嵌入层(nn.Embedding)生成的,本质是一个查找表(Lookup Table),将每个 token 映射为一个稠密向量
- 这些嵌入参数会通过反向传播(Backpropagation)和梯度下降(如 Adam)进行更新。
- 模型通过调整词向量来捕捉语义和语法信息(例如,“cat” 和 “dog” 的向量会更接近)。
embedding_layer = nn.Embedding(vocab_size, d_model) # 可训练参数
optimizer = torch.optim.Adam(embedding_layer.parameters(), lr=0.001)
位置编码(Positional Encoding)
- 为什么需要位置编码
- Transformer没有递归结构,并行计算无法捕捉序列中的顺序信息。通过位置编码将位置信息显式地注入到输入向量中。
- 位置编码可以是正弦和余弦函数的组合,也可以是可学习的向量。
RNN:输入参数U,隐层参数W,输出参数V。RNN的time step是共享这一套参数。RNN梯度消失有什么不同?RNN的梯度是一个总的梯度和,被近距离梯度主导,远距离梯度忽略不计。
- 位置编码两种主要方式
绝对位置编码(Absolute Positional Encoding)
- P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE(pos, 2i) = sin(pos/10000^{2i/{d_{model}}}) PE(pos,2i)=sin(pos/100002i/dmodel)
- P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE(pos, 2i+1) = cos(pos/10000^{2i/{d_{model}}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
pos:token的位置(0,1,2,…)
0 < = i < d m o d e l / 2 0<=i<d_{model}/2 0<=i<dmodel/2 (维度索引,因为sin和con各对应偶奇位,所以i最大不能超过d/2)
d m o d e l d_{model} dmodel:模型嵌入维度(如512) 也就是词向量维度,必须是偶数比如第一个词向量512维度[0.1415,…,1.926],对应第一个位置向量就是:pos=0,i是从0到255带入公式得到,[0, 1, 0… 1]
多频率位置编码
- 低频维度:当 i 较小时(如 i=0),分母 1000 0 2 i / d 10000^{2i/d} 100002i/d较小,波长较长(低频),用于捕捉长距离位置关系(如句首和句尾的关系)。
- 高频维度:当 i 较大时(如 i=d/2−1),分母 1000 0 2 i / d 10000^{2i/d} 100002i/d较大,波长较短(高频),用于捕捉局部位置关系(如相邻词的位置)。
可学习的位置编码(Learned Positional Encoding)
- 方法:将位置编码作为可训练的参数(类似嵌入层),随机初始化并通过训练更新
- 位置编码的关键性质
- 唯一性:每个位置有唯一编码。
- 距离感知:能够反映位置之间的相对距离(如正弦编码的线性组合性质)。
- 泛化性:正弦编码支持外推到比训练更长的序列。
import mathdef positional_encoding(max_len, d_model):pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度return pe# 示例:生成长度100,维度512的位置编码
pe = positional_encoding(100, 512)
- 注意事项
- 预训练模型的微调:如果使用预训练模型(如 BERT),词向量和位置编码通常已经过训练,但在下游任务微调时仍会更新。
- 共享嵌入层:某些模型(如 Transformer 的编码器-解码器)可能共享词向量层,此时编码器和解码器的词向量会同步更新。
- 冻结嵌入层:在某些场景(如小数据集),可以冻结(requires_grad=False)词向量以防止过拟合。
- 理解
- token向量还没进入Encoder/Decoder就将次序位置信息编码成向量直接加到token向量上了。两个向量都是相同维度。
- T o k e n V e c t o r = W E ( t o k e n ) + P E ( t o k e n ) TokenVector=WE(token) + PE(token) TokenVector=WE(token)+PE(token) = [0.1,0.2,…0.02] + [sin, cos, sin, … , cos]
为什么位置嵌入有用?
正弦位置编码具有线性组合性质。位置编码的每个维度由正弦(偶数维)和余弦(奇数维)交替组成。
(和角公式)
- s i n ( p o s + k ) = s i n ( p o s ) c o s ( k ) + c o s ( p o s ) s i n ( k ) sin(pos+k)=sin(pos)cos(k)+cos(pos)sin(k) sin(pos+k)=sin(pos)cos(k)+cos(pos)sin(k)
- c o s ( p o s + k ) = c o s ( p o s ) c o s ( k ) − s i n ( p o s ) s i n ( k ) cos(pos+k)=cos(pos)cos(k)−sin(pos)sin(k) cos(pos+k)=cos(pos)cos(k)−sin(pos)sin(k)
对于任意偏移量k,存在线性变换使得
- P E ( p o s + k , 2 i ) = P E ( p o s , 2 i ) ⋅ c o s ( k 1000 0 2 i / d ) + P E ( p o s , 2 i + 1 ) ⋅ s i n ( k 1000 0 2 i / d ) PE(pos+k, 2i) = PE(pos, 2i)·cos(\frac{k}{10000^{2i/d}}) + PE(pos, 2i+1)·sin(\frac{k}{10000^{2i/d}}) PE(pos+k,2i)=PE(pos,2i)⋅cos(100002i/dk)+PE(pos,2i+1)⋅sin(100002i/dk)
- P E ( p o s + k , 2 i + 1 ) = P E ( p o s , 2 i + 1 ) ⋅ c o s ( k 1000 0 2 i / d ) − P E ( p o s , 2 i ) ⋅ s i n ( k 1000 0 2 i / d ) PE(pos+k, 2i+1) = PE(pos,2i+1)·cos(\frac{k}{10000^{2i/d}}) - PE(pos,2i)·sin(\frac{k}{10000^{2i/d}}) PE(pos+k,2i+1)=PE(pos,2i+1)⋅cos(100002i/dk)−PE(pos,2i)⋅sin(100002i/dk)
本质上是旋转矩阵乘法,需要正弦/余弦相位偏移性质。
pos = “我” 的位置(如位置 0),
k = “爱” 的位置偏移(如 +1),
pos+k = “你” 的位置(如位置 1)。
模型可以通过注意力机制学习如何组合 PE(pos) 和 PE(k) 来理解相对位置(如“你”在“我”之后 +1)。
自注意力机制(Self-Attention)
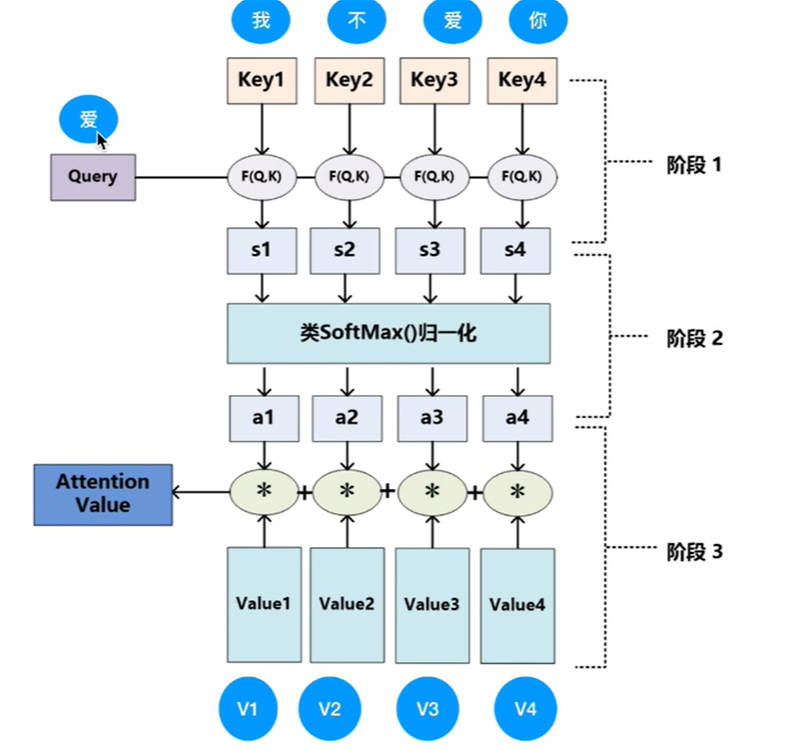
Transformer的核心,用于计算输入序列中每个位置与其他位置之间的相关性。计算过程:
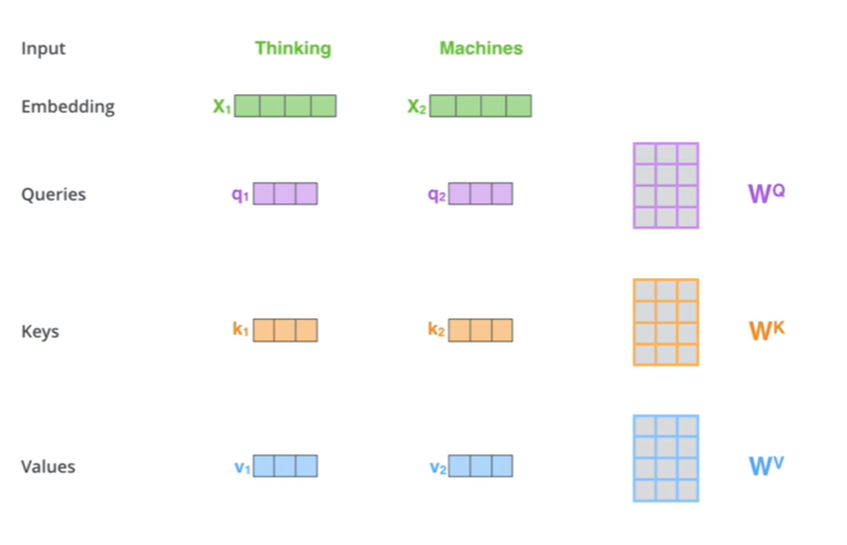
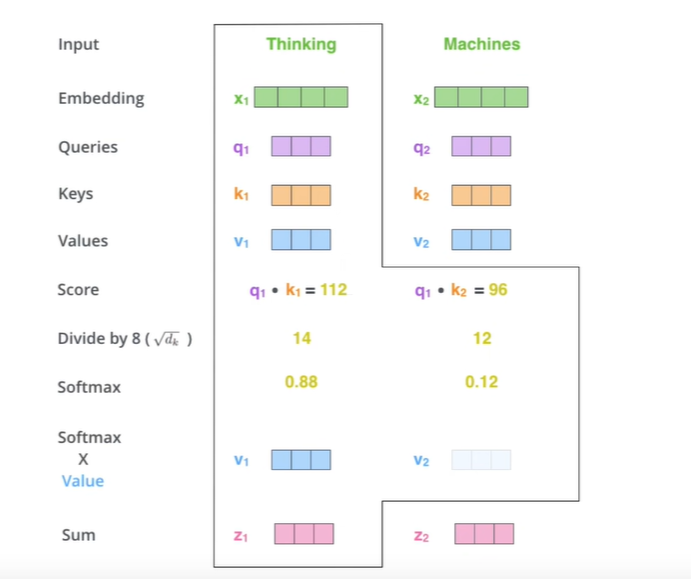
将输入序列通过三个线性变换得到查询向量(Query,Q)、键向量(Key,K)、值向量(Value,V)。
先转换为词向量,在与同一套矩阵参数( W Q 、 W K 、 W v W^Q、W^K、W^v WQ、WK、Wv)相乘得到q、k、v计算注意力分数(对单词和输入句子中的每个单词“语义关联度”进行评分):Attention(Q,K,V)=softmax( Q K T d k \frac{QK^T}{\sqrt{d_k}} dkQKT)V,其中 d k d_k dk是键向量维度,用于缩放,为了控制点乘结果的数值范围,避免梯度消失或梯度爆炸。
- 乘V:保持要关注的单词的值的完整性
Q和K的维度是 d k d_k dk, Q K T QK^T QKT数值范围与 d k d_k dk相关, d k d_k dk较大或较小会使点积结果较大或较小,softmax输入过大或过小,会使梯度爆炸或消失。
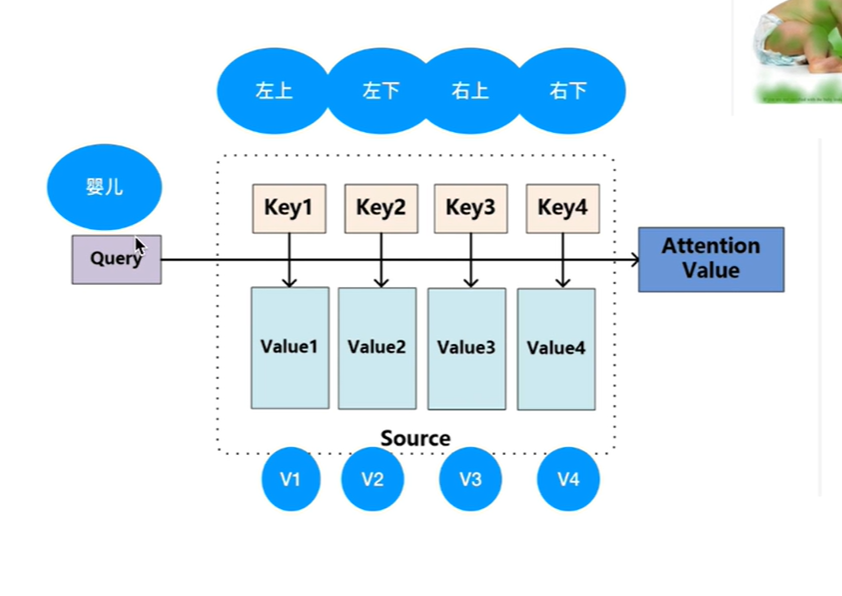
判断婴儿在干嘛?query向量,区域分为左上、左下、右上、右下,四个key向量对应四个v向量
query先跟四个k点乘得到四个值。
点乘:一个向量在另一个向量上投影的长度,是一个标量,可以反应两个向量的相似度,两个向量越相似,点乘结果越大,越关注。最后再和V相乘得到一个加权和,得到第一个单词的自注意力层的输出。
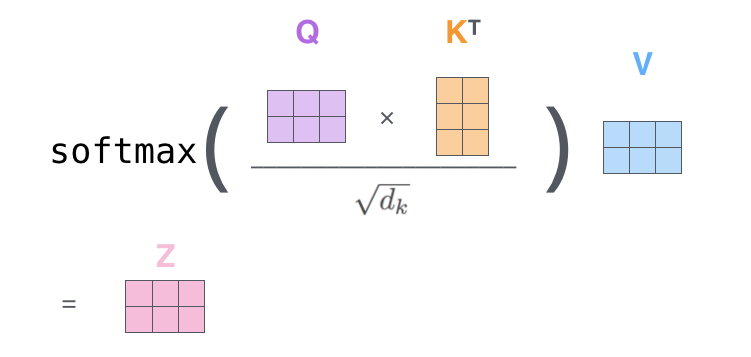

多头自注意力机制(Multi-Head Self-Attention)
增强模型表达能力,将自注意力机制重复多次,每个头学习不同的注意力表示(使用不同的参数w得到不同的Q、K、V),最后将结果拼接并线性变换。
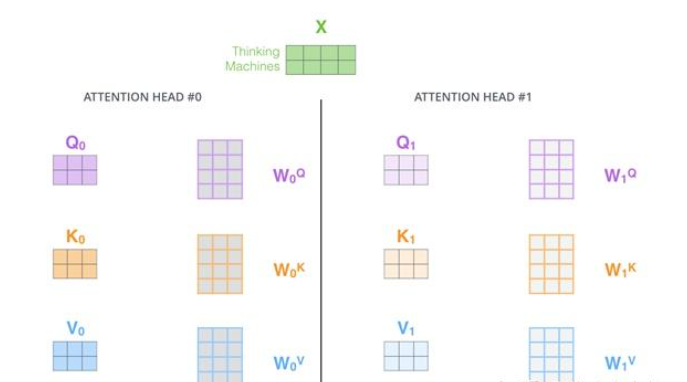
8个23个矩阵Z,线性拼接成224的矩阵,乘权重参数 W o W_o Wo得到合并的Z
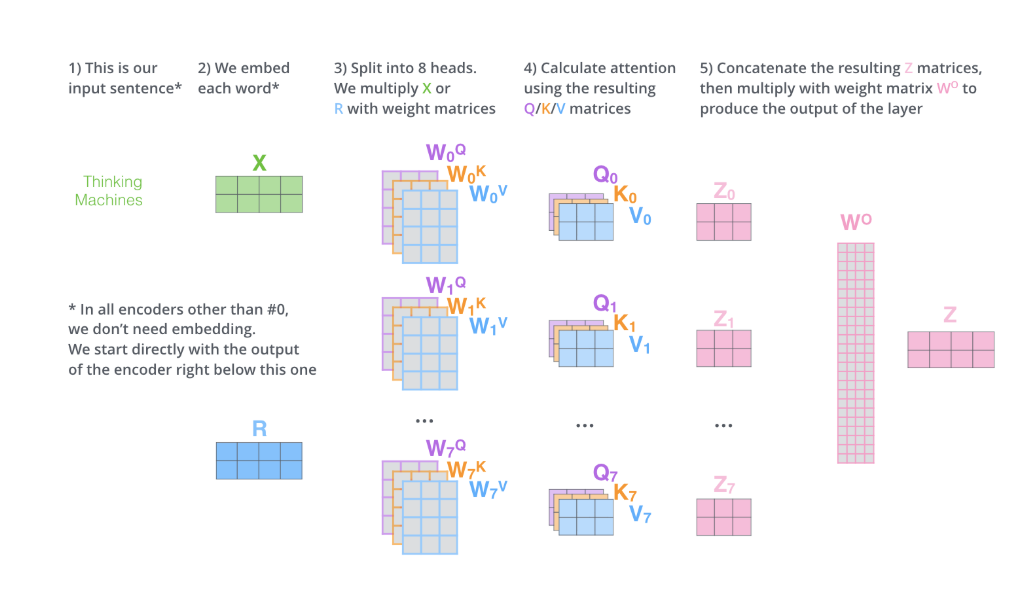
假设有两个词,每个词是1*4向量,则可训练的参数个数?
- 词嵌入矩阵:2*4=8
- W q 0 、 W k 0 、 W v 0 到 W q 7 、 W k 7 、 W v 7 W_{q0}、W_{k0}、W_{v0}到W_{q7}、W_{k7}、W_{v7} Wq0、Wk0、Wv0到Wq7、Wk7、Wv7 共24个矩阵,每个矩阵4*3
- W o W_o Wo 矩阵,24*4
不考虑其它层的情况下,参数为:8 + 24 * 4 * 3 + 24 * 4 = 392
残差连接和层归一化(Residual Connection & Layer Normalization)
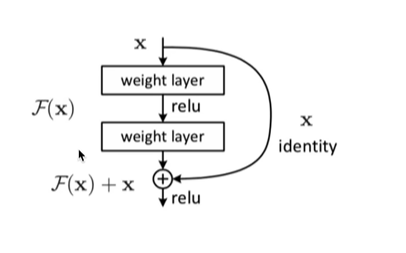
为了缓解梯度消失问题并加速训练,Transformer在每个子层的输出上使用了残差连接,并在其后应用层归一化。
残差连接:用于解决深层神经网络训练中的梯度消失和退化问题。核心思想是通过引入“跳跃连接”,将输入直接加到输出的某个变换上,从而让网络更容易学习到恒等映射,同时缓解梯度消失问题。
- 一般情况下梯度消失是因为连乘
- x经过两层神经网络后得到F(x)然后与x对位相加得到一个输出。
- 在将词转为词向量并加上位置编码后,传入多头自注意力机制得到结果Z
- 然后与加入位置编码的词向量进行连接和归一化。
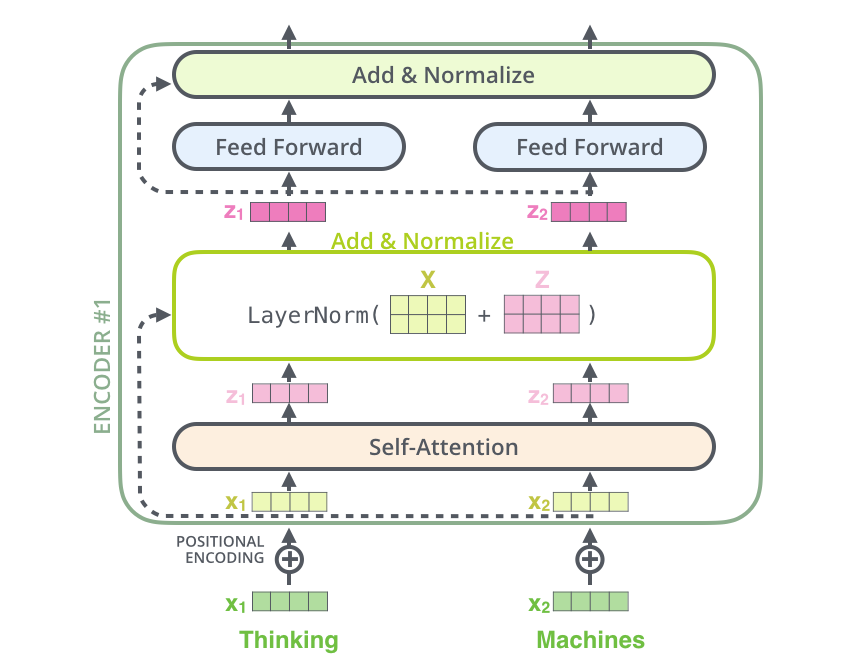
- 层归一化(LN):归一化技术,用于加速模型训练、提高模型性能,可以解决深度神经网络的梯度消失和梯度爆炸。它对每一层的输入进行归一化处理,使每一层的输入分布具有固定的均值和方差。
- 对单个样本的所有特征进行归一化。不依赖批次大小,适用于小批量或单样本。适用于RNN、transformer等序列模型。训练和推理时行为一致。
批归一化(BN):对一个批次中所有样本的同一特征进行归一化。依赖批次大小,批次小可能统计量不准。适用于CNN等需要大批次训练的模型。推理时需要使用移动平均统计量,训练和推理行为不一致。
为什么使用层归一化而不使用批归一化?BN在RNN或transformer中效果差,RNN是动态的,当新加入的数据中有新特征,使用BN计算就会出现问题。
前馈神经网络(Feed-Forward Neural Network)
每个编码器和解码器层中都包含一个两层的前馈神经网络(全连接),激活函数通常为ReLU或GELU,对每个位置的表示进行非线性变换。然后再进行残差连接和层归一化。
- self-attention结果执行完Add&Normalize后,结果发送给feed-forward层进一步操作
- Encoder最后一层输出所有输入序列的编码表示(不仅包含自身信息,还聚合了全局上下文信息),Encoder输出称为“Encoder的Memory”(每个输入词x_i对应一个高维向量d_model维)
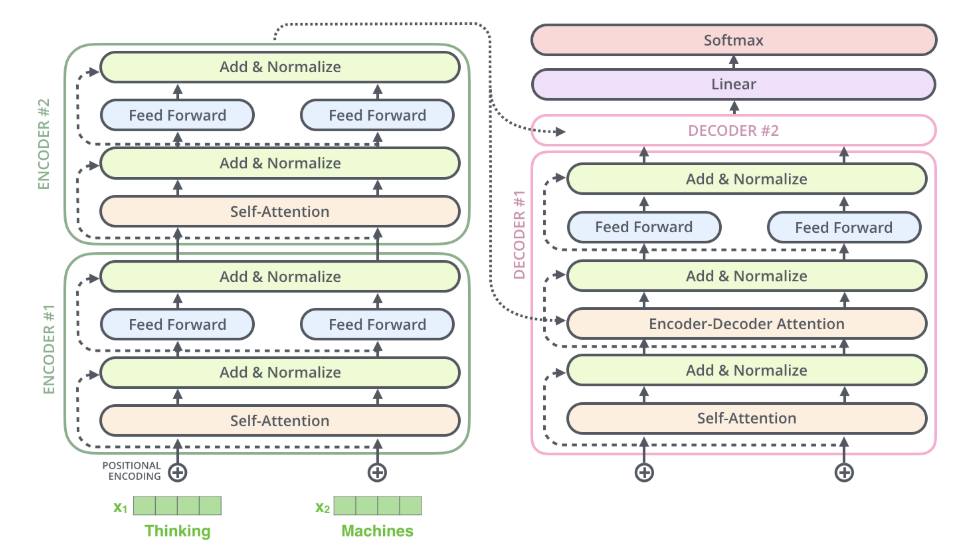
解码器
- Decoder的Query(Q)来自Decoder自身的输入(前一时刻的预测或mask后的目标序列),masked需要对当前词和之后的词盖掉,这样才能进行预测
- Encoder-Decoder Attention层的Kendec和Vendec来自Encoder输出Memory([seq_len, d_model])
- Decoder在解码第t个时刻时,通过self-attention处理目标序列(mask之后)生成当前Decoder的隐状态h_t
- cross-attention中:
- Q=h_t的线性变换(h_t·W_Q)
- K=memory的线性变换(memory·W_K)
- V=memory的线性变换(memory·W_V)

为什么要用Encoder的输出作为K和V?
- K和V的作用:提供输入序列的全局信息,有助于解码器将注意力集中在输入序列中适当位置
- Q的作用:代表Decoder当前需要关注的问题
Decoder像是在做完形填空,去Encoder中(K/V)中找答案
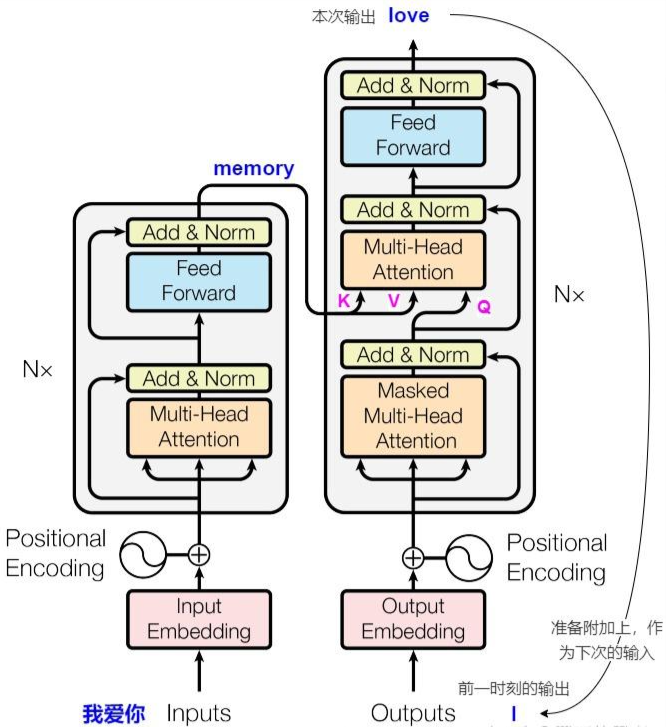
核心结构(解码器由多个相同层堆叠而成)
- 掩蔽自注意力层(Masked Self-Attention)
作用:解码时只能访问当前位置及之前的token,避免未来信息泄露。
实现:通过掩码(上三角矩阵设为负无穷)遮盖后续位置,确保自注意力仅依赖已生成的部分序列。
- 编码器-解码器注意力层(Cross-Attention)
作用:融合编码器的输出(如源语言句子的表示),动态捕捉源序列与目标序列的关联。
机制:Query来自解码器前一层的输出,Key和Value来自编码器的最终输出。
- 前馈神经网络(FFN)
与编码器类似,通过全连接层和非线性变换(如ReLU)对特征进行进一步处理。
每个子层均包含残差连接(Residual Connection)和层归一化(Layer Normalization),以缓解梯度消失问题。
解码过程
- 训练阶段(Teacher Forcing)
- 输入:目标序列整体右移一位(添加起始符),并掩蔽未来位置。
- 并行计算:通过掩蔽自注意力一次性处理整个目标序列,输出每个位置的预测概率
- 损失计算:使用交叉熵损失比较预测与真实标签(如目标语言的下一个token)。
- 推理阶段(自回归生成)
- 逐步生成:从开始,每次预测一个token,并将其作为下一步的输入,直到生成或达到最大长度。
- 关键技术:
- 束搜索(Beam Search):保留多个候选序列,平衡生成质量和多样性。
- 采样策略:如Top-k或Top-p采样,增加输出的随机性。
经典模型
- BERT:基于Transformer编码器,适用于双向上下文建模任务,如文本分类、问答
- GPT:基于Transformer解码器,适用于单向上下文建模任务,如文本生成
- T5:统一自然语言处理任务的输入输出形式,基于完整Transformer架构
BERT:
谷歌2018年提出的基于基于Transformer的预训练语言模型
核心思想
- 双向性
通过Transformer编码器同时学习单词左右两侧的上下文信息(与传统LSTM或GPT的单向性相反)。
- 预训练任务
- Masked Language Model (MLM):随机遮盖输入中的部分单词(如15%),让模型预测被遮盖的词。
- Next Sentence Prediction (NSP):判断两个句子是否为连续的上下文关系。
模型架构
- 基础组件:多层Transformer编码器堆叠(无解码器)。
- Base版:12层,768隐藏维度,12个注意力头(约110M参数)。
- Large版:24层,1024隐藏维度,16个注意力头(约340M参数)。
- 输入表示
- Token Embeddings:将单词或子词(WordPiece)转换为向量。
- Segment Embeddings:区分句子A和句子B(用于NSP任务)。
- Position Embeddings:标记单词的位置信息(与Transformer相同)。
关键特点
- 上下文敏感表示
同一单词在不同语境中具有不同的向量表示(如“bank”在“river bank”和“bank account”中含义不同)。
- 迁移学习友好
通过预训练捕捉通用语言知识,下游任务只需微调少量参数。
- 广泛适用性
支持文本分类、问答、命名实体识别等多种任务,无需任务特定结构调整。
预训练与微调流程
- 预训练阶段(海量无标注数据)
- 输入:从维基百科、图书语料库等采样的大规模文本。
- 目标:通过MLM和NSP任务学习语言通用特征。
- 硬件需求:需TPU/GPU集群训练数天。
- 微调阶段(标注数据)
- 方法:在预训练模型顶部添加任务特定层(如分类层),端到端微调所有参数。
- 示例任务适配:
- 文本分类(如情感分析):添加全连接层输出类别概率。
- 问答任务(如SQuAD):输出答案的起始和结束位置。
应用场景
- 文本分类:如垃圾邮件检测、情感分析。
- 命名实体识别(NER):识别文本中的人名、地点等。
- 问答系统:如SQuAD数据集上的阅读理解。
- 句子相似度计算:判断两句话语义是否相近。
| 特性 | BERT | GPT | 原始Transformer |
|---|---|---|---|
| 架构 | Transformer编码器堆叠 | Transformer解码器堆叠 | 编码器-解码器完整结构 |
| 上下文方向 | 双向 | 单向(从左到右) | 编码器双向,解码器单向 |
| 预训练任务 | MLM + NSP | 语言模型(预测下一个词) | 无(需从头训练) |
| 典型应用 | 理解类任务(分类、抽取) | 生成类任务(文本续写) | 机器翻译等Seq2Seq任务 |