FPGA为什么快?——从架构到实现的深度解析
FPGA的“快”从何而来?
在处理器家族中,FPGA(现场可编程门阵列)以“硬件级加速”闻名,尤其在高性能计算、图像处理、通信协议处理等领域表现亮眼。它的“快”并非单纯依赖时钟频率(很多FPGA主频仅数百MHz,远低于GHz级的CPU/GPU),而是源于架构设计、并行模式、硬件可编程性三大核心优势。下面我们从底层架构开始,逐层拆解FPGA“快”的秘密。

架构层:天生为并行设计的分布式硬件架构
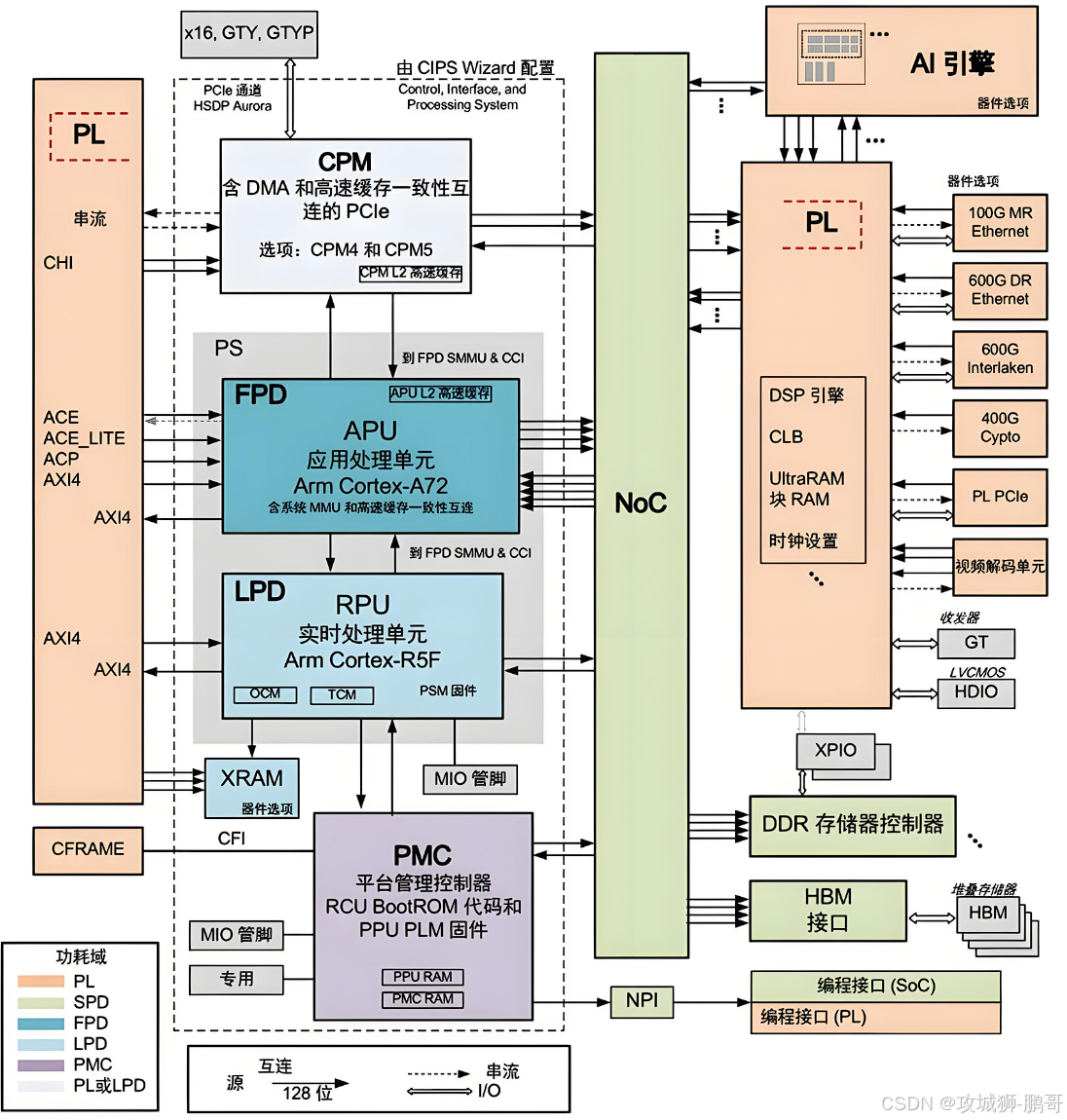
1. 不同于CPU/GPU的“积木式”硬件结构
FPGA的物理结构像一堆可自由组合的“电子积木”,核心由三大模块组成:
- 逻辑单元(LE/CLB):最小计算单元,包含查找表(LUT,实现逻辑运算)、寄存器(存储中间结果)、多路选择器(数据路由)。单个FPGA可集成数百万个LE,相当于数百万个“微型处理器”并行工作。
- 互连资源(Interconnect):可编程布线资源,如导线、开关矩阵,允许任意逻辑单元之间高速互联,延迟可精确控制(纳秒级)。
- I/O单元(IOB):支持高速串行/并行接口(如DDR、PCIe、SerDes),直接对接外部设备,减少数据进出延迟。
这种分布式架构与CPU的“核心+缓存+总线”集中式架构形成鲜明对比:CPU依赖总线调度数据,而FPGA中每个逻辑单元可独立处理数据,通过互连资源直接“点对点”通信,避免了总线拥堵和全局控制器的瓶颈。
2. 硬件级“定制电路”:贴近算法的物理实现
传统CPU执行程序时,需将算法转化为指令流,由控制器逐条解析、调度执行。而FPGA可通过硬件描述语言(Verilog/VHDL)将算法直接映射为专用电路。例如:
- 实现一个乘法器:CPU需调用乘法指令(可能需多个时钟周期),而FPGA可直接例化片上专用乘法器(DSP Block),1个时钟周期完成计算。
- 实现数据流处理:如卷积神经网络中的矩阵运算,FPGA可将权重和数据分配到数千个并行的乘法累加单元(MAC),同时计算不同位置的乘积,无需软件循环调度。
这种“硬件即算法”的特性,让FPGA的计算流程更贴近数学本质,减少了软件层的指令解析、分支预测、缓存失效等开销。
并行计算层:空间并行 vs 时间并行,极致的并行粒度
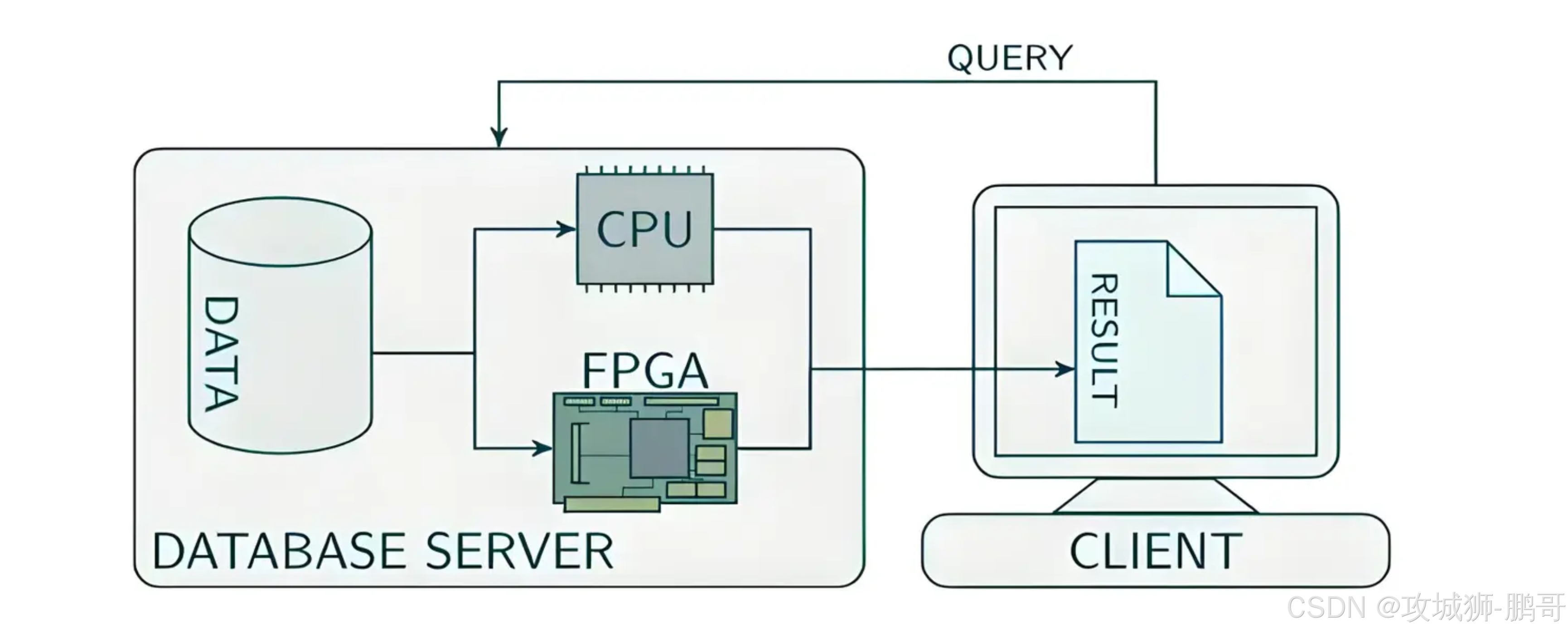
1. 超越CPU/GPU的“空间并行”范式
计算机并行计算有两种基本模式:
- 时间并行&#