【大模型】TableLLM论文总结
文章目录
- Encoding Spreadsheets for Large Language Models [EMNLP 2024]
- TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models [arXiv 2025.3.6]
- TablePilot: Recommending Human-Preferred Tabular Data Analysis with Large Language [arXiv 2025.3.31]
Encoding Spreadsheets for Large Language Models [EMNLP 2024]
-
背景
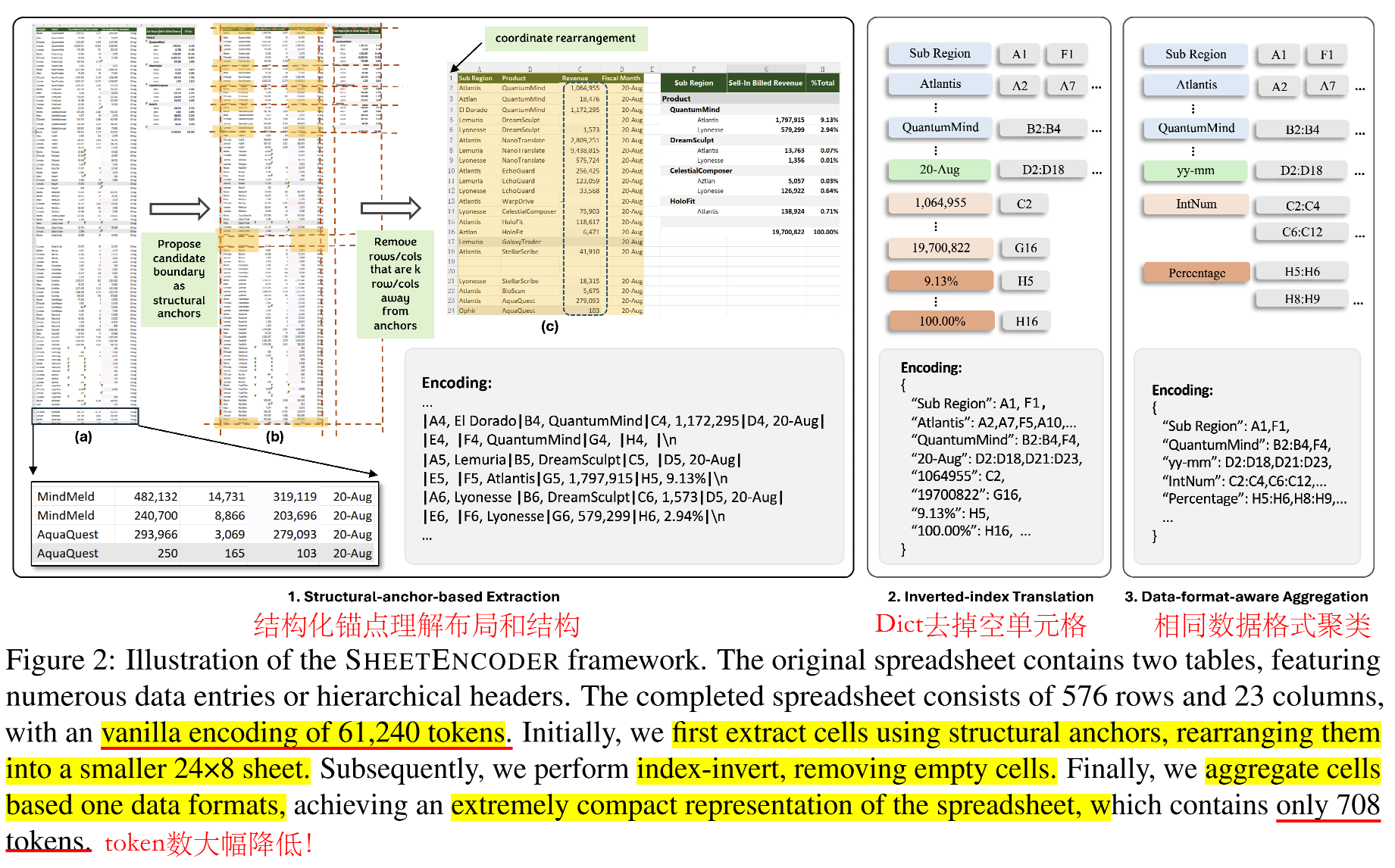
- 电子表格的特点和对LLM的挑战:1)二维表格,缺乏结构和布局的信息;2)布局非常灵活;3)多种格式可以选择
- 传统序列化的编码方式会导致token数量很大,在现在LLM上无法很好应用
-
方法
- 高效布局理解的结构锚点
- 许多均匀的行列对理解布局和结构的贡献很小
- 本文识别结构锚点,在可能的表格边界处的异构的行列,提供了实质性的布局理解
- 移除较远的、同质的行列,得到精简版电子表格
- 此方法可过滤掉75%的电子表格内容,但保留表格边界边缘的97%行列
- 倒排索引,提高效率
- 不同于传统的逐行逐列序列化,本文采用JSON格式的无损倒排索引转换
- 首先将矩阵格式的数据转换成索引字典,将同样值的单元格合并,并去掉空单元格
- 优化token使用,同时保持数据完整性
- 数值单元格的数据格式聚集
- 相邻的数字单元通常具有相似的数字格式,并且精确的数值对于理解电子表格结构不如数据类型重要
- 从单元格中提取数字格式字符串(NFS)和数据类型(用ClosedXML/OpenPyXL工具),具有相同格式/类型的相邻单元格被聚类在一起
- 例子:“2024.2.14"的NFS是"yyyymm-dd”
- 电子表格编码链
- 阶段1:表格标识和边界检测。根据query相关度识别表格,并决定精确的边界,后续分析只针对这部分相关数据
- 阶段2:回复生成。将Query和识别后的表格送给LLM回答问题
- 作用:下游任务被自然地分解成表格理解(表格检测),并且可以兼容后续的CoT推理
- 高效布局理解的结构锚点
TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models [arXiv 2025.3.6]
-
背景
- 直接将参数高效微调(PEFT)应用于表格任务存在显著挑战特别是在更好的表格序列化和在一维序列中表示二维结构化信息方面
- 如何更好地序列化表:不同的序列化方法会影响结果,使用现有的序列化技术, 模型仍然难以准确识别表格结构。检索列可以通过查询中的相同标题名称轻松识别。但是,使用LoRA微调的Llama模型无法识别与标题同列的单元格
- 如何更好地在一维序列中表示二维结构信息:表中行和列的位置信息对于理解表结构、行与列对应关系等至关重要
-
方法
- 特殊标token编码器
- 定义三个特殊标记:[tab]、[row]和[cell]
- 通过纳入专门定义的标记来增强模型对表格数据的理解,这些标记提供了清晰且结构化的表格表示
- 编码器采用的的P-tuning中的编码器
- 2D LoRA
- 能从二维单元位置中可以得到的信息是相对有限的
- 由于这些index的信息密度相对较低,所以选择使用低秩嵌入来表示它们,并且和原始的LoRA并行
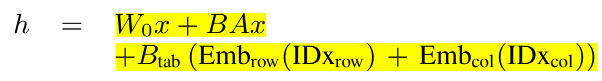
- 特殊标token编码器

TablePilot: Recommending Human-Preferred Tabular Data Analysis with Large Language [arXiv 2025.3.31]
背景
- 有效识别与新表格最相关的数据分析query和结果是一个重大挑战,这个任务称为推荐表格数据分析
- 以前表格数据分析的推荐基于ML,而现在基于LLM
- 数据分析的实际目标:准确、多样、符合人类偏好
- 用LLM推荐表格数据分析的关键挑战:
- 数据量大,LLM处理困难,长上下文产生幻觉
- 以前的工作是考虑单个操作,缺乏多样性,未能提供全面的分析
- 以符合人类认知模式的方式选择和呈现分析结果至关重要
方法
-
本文目标:在没有用户配置文件或先前的交互的前提下(zero-turn场景),用LLM为新表格推荐定制的<query, code, result>三元组,实现自动生成全面和准确的表格分析结果
-
第一步:分析准备(为了提升准确性,采用了采样技术)。采样选择一部分表格数据T’,然后用一个预训练LLM生成表格解释E。此分析准备阶段有助于生成更符合上下文的query和结果。在优化级别,利用post-refinement技术调整输出
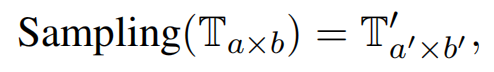
-
第二步:基于模块的分析(为了提高多样性,用模块化的方法来支持各种工作流操作)。将T’和E作为输入,用不同模块生成基础分析、数据可视化、统计建模三方面的<query, code>
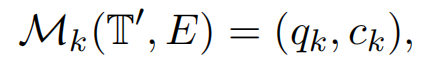
-
第三部:分析优化。首先执行code以获得每个代码的结果r。接下来根据表格采样T和解释E来细化分析三元组,优化过程利用LLM来改善query和code与数据和分析意图的对齐,确保更准确和有意义的结果
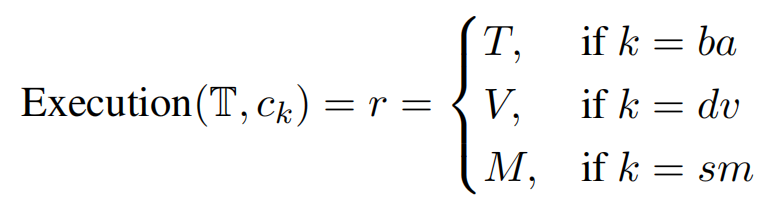
-
第四步:分析排序(为了确保分析与人类的偏好一致)。本文引入了Rec-Align,根据多个维度的指标,比如相关度、多样性,评估并排序所有<q, c, r>,最终选择top-k的操作推荐给用户。确保推荐结果与人类分析倾向一致,并产生更好的结果
-
还贡献一个数据集DART来支持和验证本文的框架
-
训练策略
- 分析SFT:对LLM进行三个分析模块(基础分析、数据可视化、统计建模)的训练,以提高其遵循指令、生成相关query和准确code的能力,从而提高分析的准确性
- 排序SFT:在排序模块中训练的LLM,以更好地遵循指令,根据综合标准评估每个三元组并分配适当的分数。这确保了排序模型在对三元组排序时遵循我们的要求
- 排序DPO:通过DPO实现Rec-Align,以优化排序中三元组的评估,确保评估和评分更贴近人类偏好,进一步提高推荐分析的质量

