常见的图像生成模型
一、评价指标
1. LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
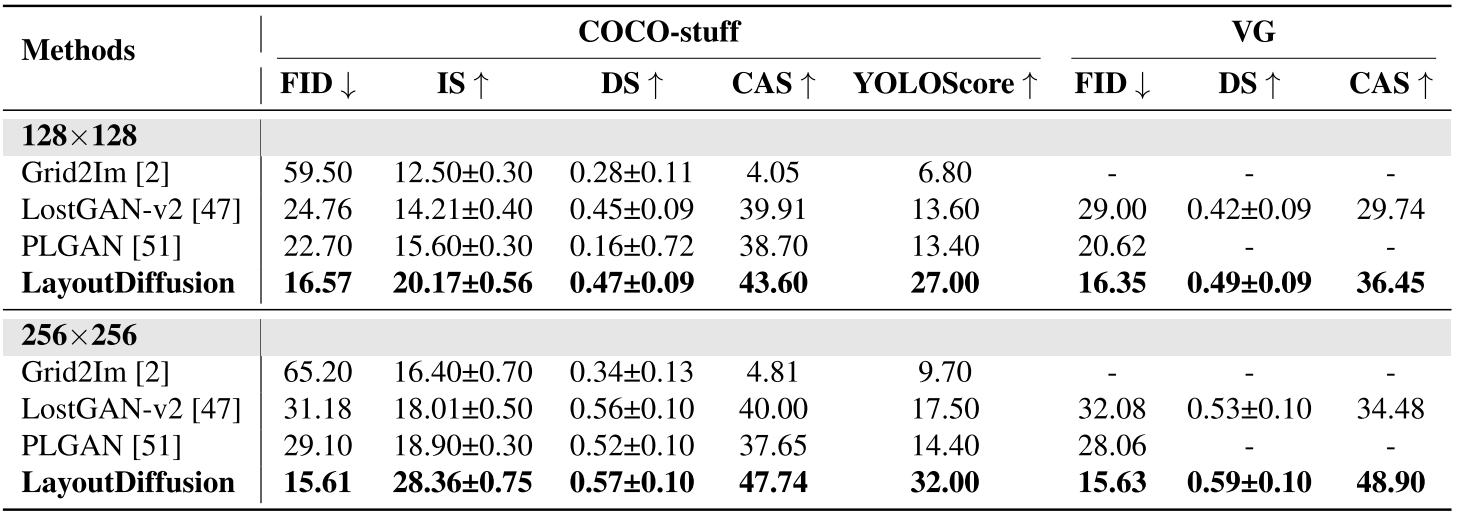
(1)Frechet Inception Distance(FID)[10]通过测量真实的图像和ImageNet预训练的Inception-V3 [48]网络上生成的图像之间的特征分布差异来显示生成图像的整体视觉质量。
(2)Inception Score(IS)[38]使用在ImageNet网络上预训练的Inception-V3 [48]来计算生成图像输出的统计分数。
(3)多样性得分(DS)通过比较DNN特征空间中的LPIPS [55]度量来计算相同布局的两个生成图像之间的多样性。
(4)分类评分(CAS)[32]首先裁剪图像的地面真值框区域,并以32×32的分辨率将其分类。使用生成的图像训练ResNet-101 [9]分类器,并在真实的图像上进行测试。
(5)YOLOScore [23]使用预训练的YOLOv 4 [4]模型在生成的图像上评估了80个事物类别bbox mAP,并显示了一个生成的模型中的控制精度。
2. Blended Diffusion for Text-driven Editing of Natural Images
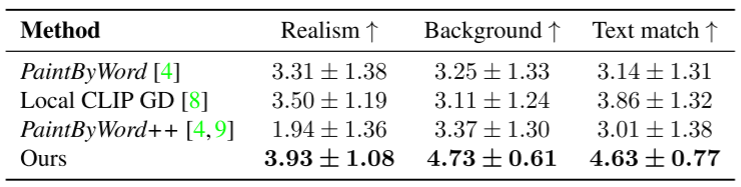
(1)Realism
(2)Background
(3)Text match
3. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
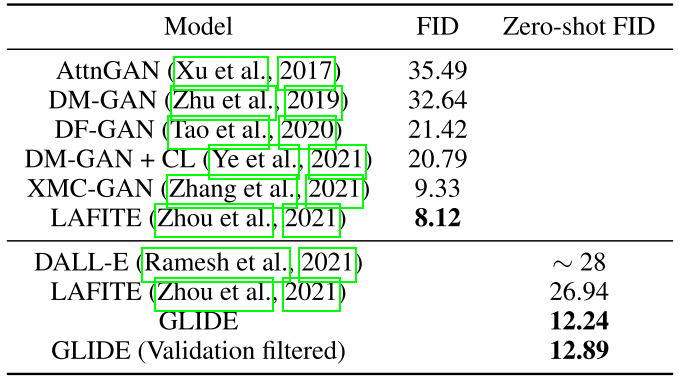
(1)FID
(2)Zero-shot FID
4. RePaint: Inpainting using Denoising Diffusion Probabilistic Models
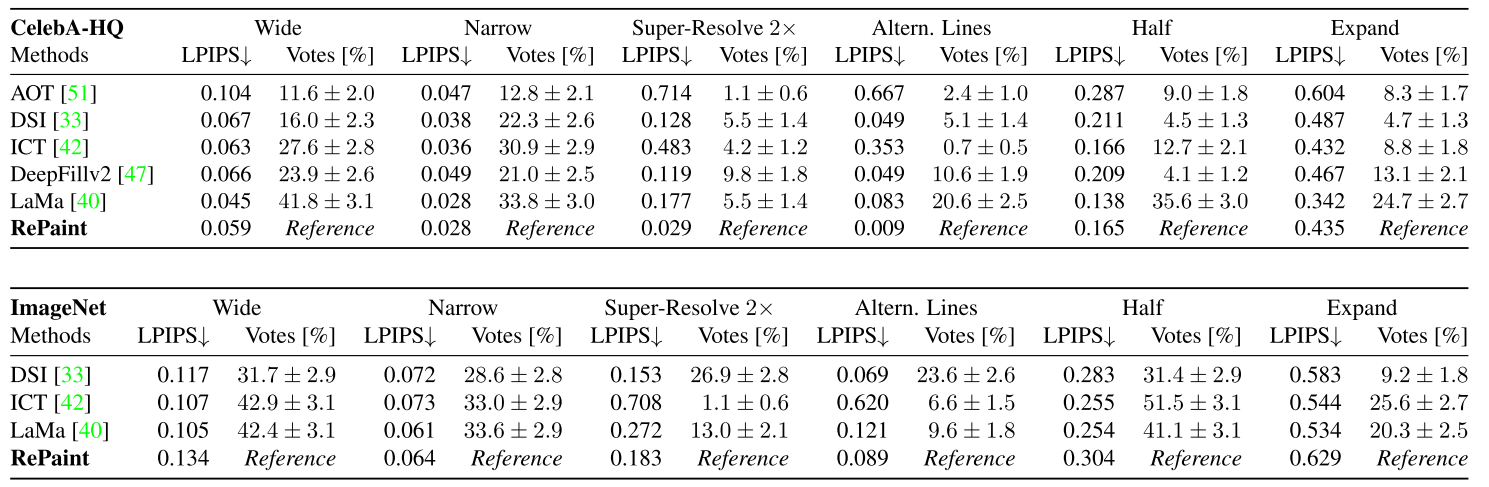
(1)votes:在每个数据集和掩码设置中每个方法对方法的比较中产生1000票,并在平均投票旁边显示95%置信区间。除了用户研究之外,
(2)感知度量LPIPS:这是一种基于AlexNet深层特征空间的学习距离度量。我们在用户研究中使用的相同的100个测试图像上计算LPIPS。
5. Null-text Inversion for Editing Real Images using Guided Diffusion Models
6. Paint by Example: Exemplar-based Image Editing with Diffusion Models
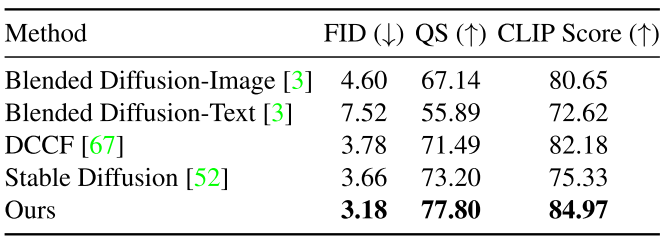
(1)FID [23]评分,广泛用于评估生成的结果。我们遵循[33]并使用CLIP模型提取特征,计算3,500个生成图像和COCO测试集的所有图像之间的FID得分。
(2)质量分数(QS)[17],旨在评估每张图像的真实性。我们取其平均值来衡量生成图像的整体质量。
(3)CLIP评分[45],评估编辑区域与参考图像之间的相似性。具体来说,我们将这两幅图像的尺寸调整为224 × 224,通过CLIP图像编码器提取特征并计算它们的余弦相似度较高的CLIP分数表明编辑区域与参考图像更相似。
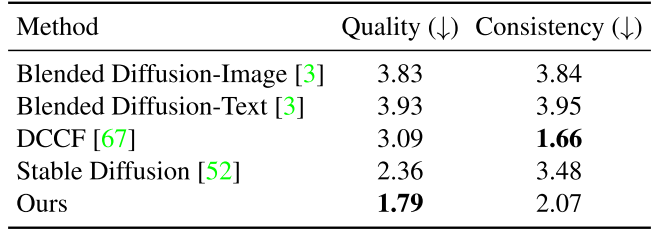
(4)Quality、Consistency:为了获得用户对生成图像的主观评价,我们对50名参与者进行了用户研究。在研究中,我们使用了30组图像,每组包含两个输入和五个输出。每组的所有这些结果都以随机顺序并排呈现给参与者。参与者有无限的时间从1到5(1是最好的,5是最差的)独立地在两个视角上:图像质量和与参考图像的相似性。我们在表2中报告了平均排名分数。总的来说,图像协调方法DCCF是最相似的参考图像,因为它是直接从它复制。尽管如此,用户更喜欢我们的结果比别人给我们的现实质量。
7. T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
(1)FID
(2)CLIP Score
8. TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
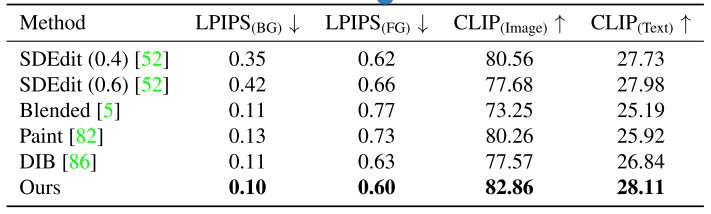
(1) LPIPS(BG) [87] measures the backgroundconsistency
(2) LPIPS(FG) [87] evaluates the low-level similarity between the edited region and the reference foreground,。
(3) CLIP(Image) [59] evaluates the semantic similarity between the edited region and the reference in the CLIP embedding space。
(4) CLIP(Text) [59] measures the semantic alignment between the text prompt and the resultant image.
9. Uni-paint: A Unified Framework for Multimodal Image Inpainting with Pretrained Diffusion Model
(1)T2I(反映对文本的忠实度)
(2)NIMA(关注技术质量但对美学不可知)
(3)人类投票(反映个人主观偏好,作为NIMA的补充)。
10. Adding Conditional Control to Text-to-Image Diffusion Models
(1)Result Quality
(2)Condition Fidelity
(3)IoU
(4)FID
(5)CLIP-score
(6)CLIP-aes.
11. Shape-Guided Diffusion with Inside-Outside Attention
(1)联合平均交叉点(mIoU)作为指标。具体来说,我们计算正确合成为所需对象类的掩蔽区域内的像素比例,如在COCO-Stuff [3]上训练的分割模型[4]所确定的。由于动物对象掩码是特别细粒度的,并且mIoU不能捕获退化情况的全貌(例如,如果编辑将猫的整个身体替换为猫的头),
(2)我们还计算动物类的关键点加权mIoU(KW-mIoU)。具体来说,我们通过比较源图像与编辑图像时正确关键点的百分比对每个样本的mIoU进行加权,如动物关键点检测模型所确定的[39]。
(3)我们还报告了FID分数作为图像真实性的度量,它使用Inception网络的特征来衡量真实的和合成图像的分布相似性[21,34]。
(4)我们报告了CLIP [23]分数作为图像-文本对齐的度量,它使用大型预训练图像-文本模型的特征来衡量文本提示和合成图像的相似性。
12. ZONE: Zero-Shot Instruction-Guided Local Editing
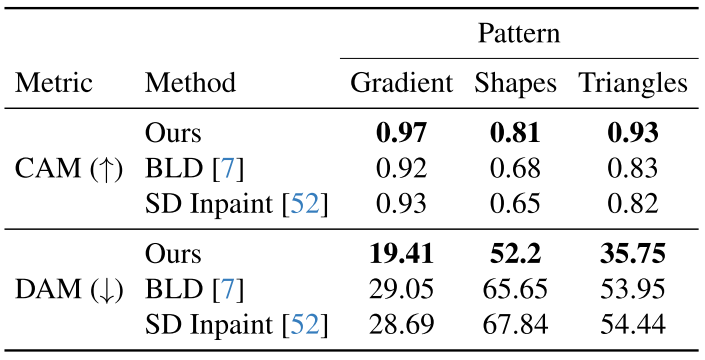
(1)学习感知图像块相似性(LPIPS)[61]用于量化原始图像和编辑图像之间的感知相似性。
(2)CLIP文本图像相似性(CLIP-T)[12]用于评估编辑图像与其相应字幕之间的对齐度,
(3)CLIP图像相似性(CLIP-I)用于评估编辑图像与原始图像之间的布局相似性和语义相关性,作为编辑图像质量的可靠指标。
(4)L1和L2距离进行像素级差异比较。
13. HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models
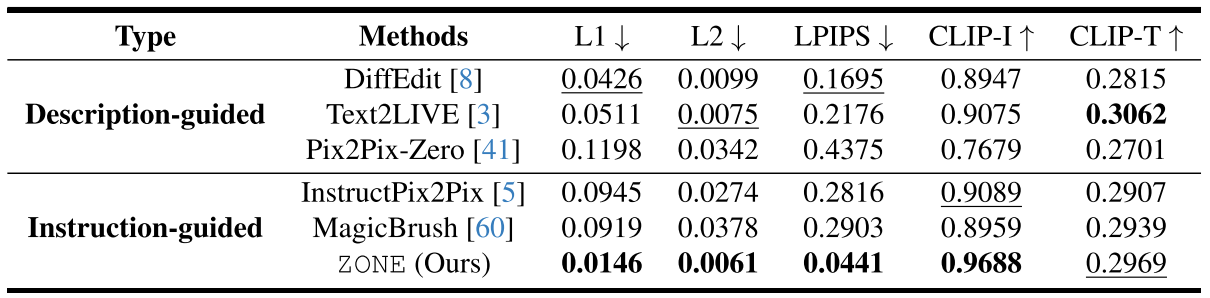
(1)我们使用输入掩模的边界框来评估图像裁剪区域的CLIP分数。由于CLIP评分仍然可以为对抗性示例分配高分,因此我们还计算了生成类的准确性。
(2)Accuracy:使用MSCOCO的预训练实例检测模型:MMDetection [5]。我们在生成的图像的裁剪区域上运行它,并且,由于裁剪中可能包含多个对象,如果提示标签在检测到的对象列表中,则将示例视为肯定。
(3)为了衡量结果的视觉保真度,我们采用了LAION Aesthetic score。Aesthetic score是由来自Simulacra Aesthetic Captions数据集[24]的5000个图像评级对训练的MLP计算的,并且可以用于根据图像的美学吸引力将[0,10]范围内的值分配给图像。最后,
(4)PickScore [14]作为文本对齐和视觉保真度的组合度量。通过对真实的用户反馈进行训练,PickScore不仅能够评估修复方法的真实性,而且能够评估生成质量,同时反映用户的复杂需求。在我们的设置中,我们在我们与其他方法的结果之间应用PickScore,并在它为我们提供优势时计算百分比。
14. Differential Diffusion: Giving Each Pixel Its Strength
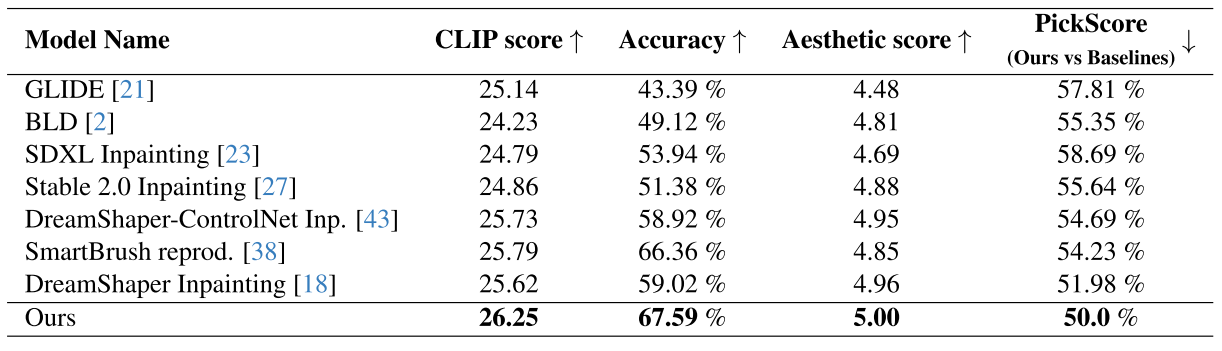
(1)相关性遵守度量(CAM):CAM倾向于关注高级要素;例如,在比较不同形状的地图时,CAM通常会分配较差的相似性评分。另一方面,DAM关注的是较低级别的特征。
(2)和距离遵守度量(DAM):DAM通常会为亮度发生变化的区域不同的地图分配较低的相似性分数。因此,每个指标都提供了一个独特的遵守质量视图。请参考补充材料中的差异示例。
二、模型效果
1. LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
2. Blended Diffusion for Text-driven Editing of Natural Images
3. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
4. RePaint: Inpainting using Denoising Diffusion Probabilistic Models
5. Null-text Inversion for Editing Real Images using Guided Diffusion Models

6. Paint by Example: Exemplar-based Image Editing with Diffusion Models
7. T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models

8. TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
9. Uni-paint: A Unified Framework for Multimodal Image Inpainting with Pretrained Diffusion Model
文本驱动和无条件(括号内)修复的定量比较
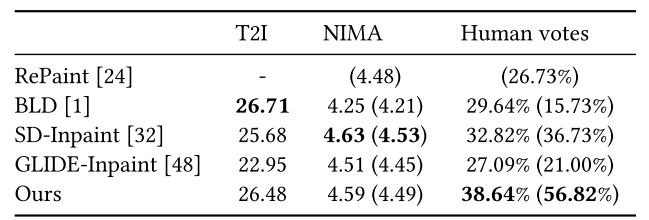
样本驱动修复的定量结果
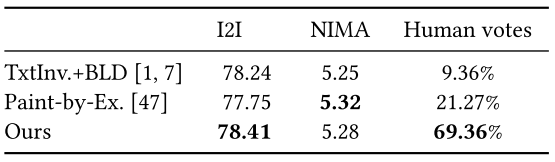
10. Adding Conditional Control to Text-to-Image Diffusion Models
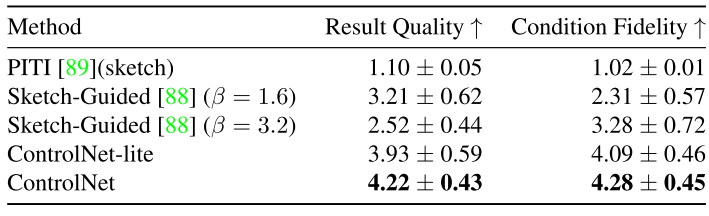

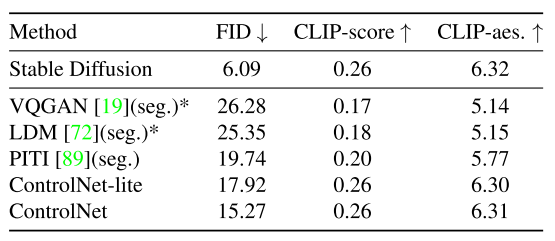
11. Shape-Guided Diffusion with Inside-Outside Attention
自动评估MS-COCO Shapetrams(测试集)。MS-COCO Shape使用MS-COCO提供的对象蒙版,而Inferred Shape使用从文本推断的对象蒙版。我们的w/o IOA表示我们的方法没有内外注意力。
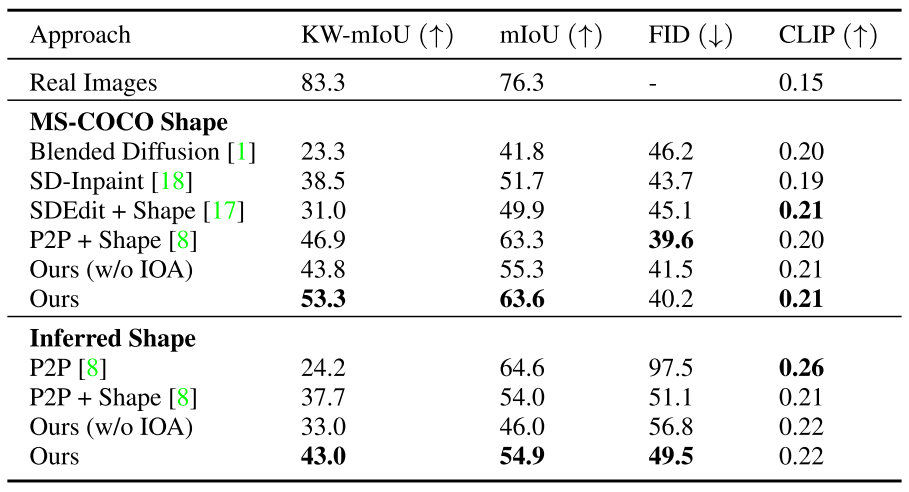
12. ZONE: Zero-Shot Instruction-Guided Local Editing
13. HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models
14. Differential Diffusion: Giving Each Pixel Its Strength
三、模型架构及输入条件
1. LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
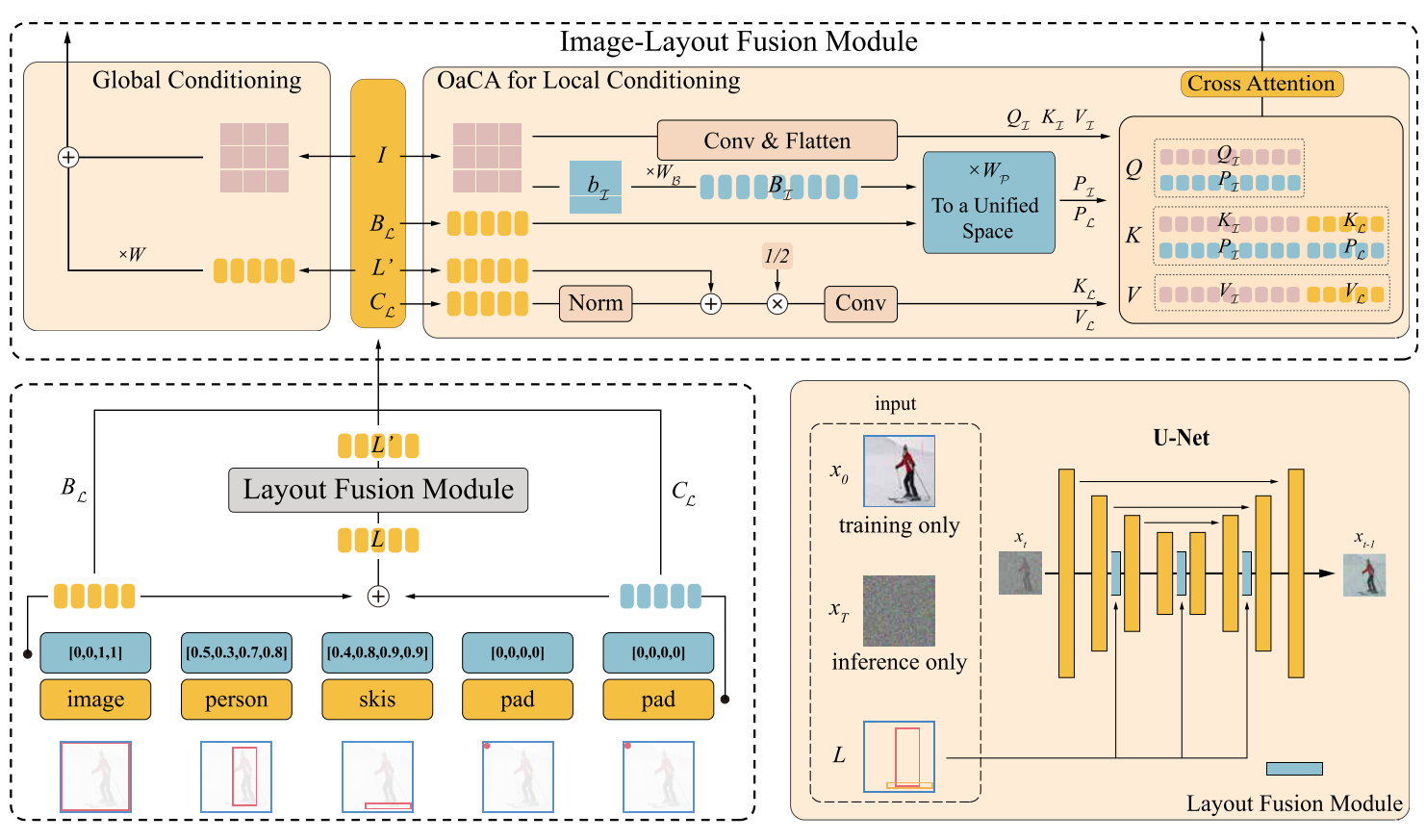
LayoutDiffusion 是一个用于布局到图像生成(layout-to-image generation)的可控扩散模型。该模型的核心架构包括四个主要部分:布局嵌入(Layout Embedding)、布局融合模块(Layout Fusion Module, LFM)、图像-布局融合模块(Image-Layout Fusion Module)以及布局条件扩散模型(Layout-conditional Diffusion Model)。模型的输入条件包括一个布局(包含边界框和类别信息的对象集合)、一个与布局相关的文本提示(可选),以及一个图像分辨率(用于控制生成图像的大小)。通过这些输入,LayoutDiffusion 能够生成与布局和文本提示一致的高质量图像,同时保持对多个对象位置和大小的精确控制。
2. Blended Diffusion for Text-driven Editing of Natural Images
Blended Diffusion 是一种基于文本引导的自然图像编辑方法,旨在通过自然语言描述和感兴趣区域掩码(ROI mask)对图像进行局部编辑。该方法结合了预训练的语言-图像模型 CLIP 和去噪扩散概率模型(DDPM),以生成自然外观的结果。模型的输入条件包括一张自然图像、一个二值掩码(标记需要编辑的区域)和一个文本提示(描述编辑内容)。为了实现编辑区域与未编辑区域的无缝融合,Blended Diffusion 在扩散过程中将输入图像的噪声版本与局部文本引导的扩散潜在表示进行空间混合。此外,该方法通过在扩散过程中引入扩展增强(extending augmentations)来减少对抗性结果的出现。Blended Diffusion 不需要额外训练,能够生成多个结果以满足任务的多对一性质。
3. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
GLIDE(Guided Language to Image Diffusion for Generation and Editing)是一种基于扩散模型的文本引导图像生成和编辑系统。它结合了预训练的文本编码器和扩散模型,通过分类器自由引导(classifier-free guidance)技术来生成高质量的图像。模型的输入条件包括一个文本提示(描述目标图像的内容)、一个初始噪声图像(用于扩散模型的起始点),以及可选的掩码(用于图像编辑任务,如修复或局部编辑)。GLIDE通过在扩散过程中逐步减少噪声,同时利用文本提示引导生成过程,能够生成与文本描述高度一致的图像。此外,GLIDE还支持图像修复功能,允许用户通过文本提示对现有图像进行局部编辑,生成的结果能够与周围环境自然融合。
4. RePaint: Inpainting using Denoising Diffusion Probabilistic Models
RePaint 是一种基于去噪扩散概率模型(DDPM)的图像修复方法,专门用于自由形式的图像修复任务。该方法的核心在于利用预训练的无条件 DDPM 作为生成先验,通过在逆扩散过程中对已知区域进行采样来条件化生成过程。模型的输入条件包括一张带有缺失区域的图像和一个二值掩码,掩码标记了需要修复的区域。RePaint 在逆扩散的每一步中,对已知区域使用输入图像的信息进行采样,而对未知区域则依赖 DDPM 的生成能力。为了提高生成图像的语义一致性和与已知区域的和谐性,RePaint 引入了一种改进的重采样策略,通过在扩散时间上进行跳跃和多次采样,使得生成的图像在语义上更加合理。该方法无需针对特定掩码分布进行训练,因此能够泛化到各种掩码类型,生成高质量且多样化的修复结果。
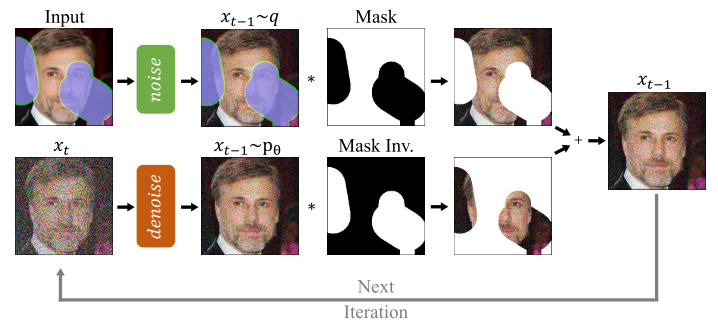
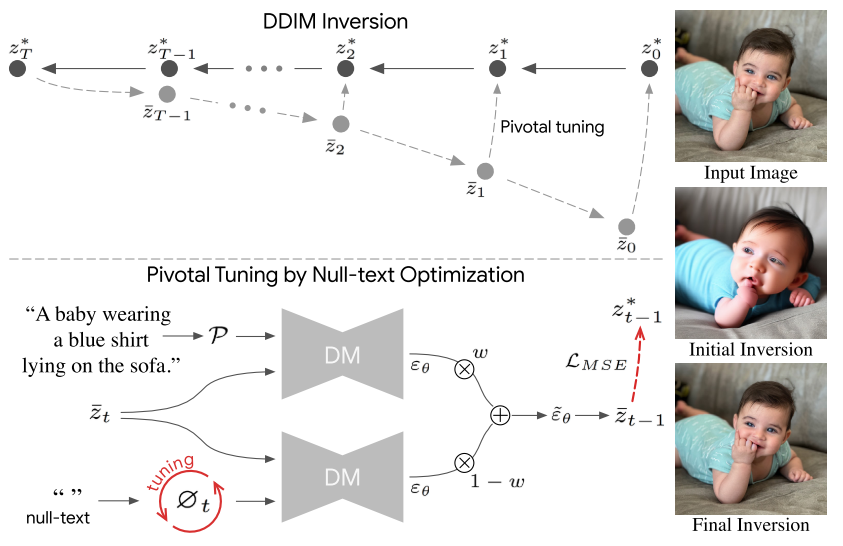
5. Null-text Inversion for Editing Real Images using Guided Diffusion Models
Null-text Inversion 是一种用于真实图像编辑的技术,基于引导扩散模型(Guided Diffusion Models)。该方法的核心在于将真实图像及其对应的文本描述准确地嵌入到预训练的文本引导扩散模型的潜在空间中,同时保留模型强大的编辑能力。模型的输入条件包括一张真实图像和一个与图像内容相关的文本描述(caption)。该方法首先使用 DDIM(Denoising Diffusion Implicit Models)逆向采样技术生成一个近似的噪声轨迹,作为优化的起点(pivot)。然后,通过优化无条件文本嵌入(null-text embedding)来提高重建质量,而不是直接调整模型权重或条件文本嵌入。这种方法不仅能够实现高保真度的图像重建,还能在不改变模型权重的情况下,通过 Prompt-to-Prompt 编辑技术对图像进行直观的文本引导编辑。
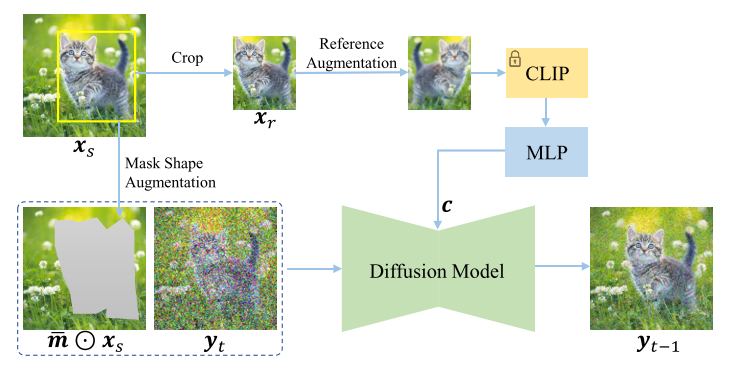
6. Paint by Example: Exemplar-based Image Editing with Diffusion Models
本文提出了一种基于扩散模型的示例引导图像编辑方法(Paint by Example),用于根据用户提供的示例图像精确地修改图像内容。模型的输入条件包括一个源图像(source image)、一个示例图像(exemplar image)以及一个二值掩码(binary mask),掩码用于指定需要编辑的区域。模型架构基于扩散模型,通过自监督训练实现源图像和示例图像的解耦与重组。为避免直接复制粘贴示例图像导致的融合伪影,模型采用了信息瓶颈(information bottleneck)和强数据增强(strong augmentations)技术。信息瓶颈通过仅使用预训练CLIP图像编码器的类别令牌(class token)作为条件,迫使网络理解示例图像的语义信息,而不是简单地记忆图像内容。强数据增强包括对示例图像进行翻转、旋转、模糊和弹性变换等操作,以减少训练与测试之间的域差距。此外,模型还设计了任意形状的掩码以模拟实际编辑中用户可能使用的不规则笔刷形状,并利用分类器自由引导(classifier-free guidance)来提高生成图像与示例图像的相似度。整个框架仅需一次扩散模型的前向传播,无需针对每张图像进行迭代优化,从而实现了对真实世界图像的可控编辑,具有高保真度和语义一致性。
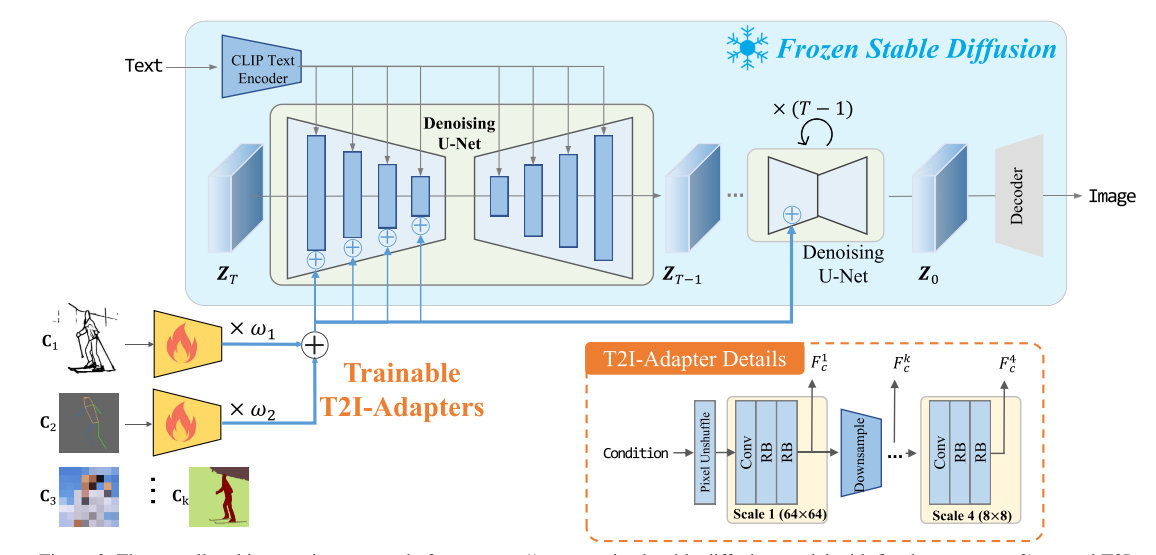
7. T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
本文提出了 T2I-Adapter,这是一个简单且轻量级的模型,旨在为预训练的文本到图像(T2I)模型(如 Stable Diffusion)提供额外的控制信号,以实现更精确的图像生成,而无需改变原始模型的网络拓扑结构或生成能力。模型的输入条件包括文本提示、参考图像(如草图、语义分割图、深度图、关键点图等)以及一个二值掩码(用于指定需要编辑的区域)。T2I-Adapter 通过学习将外部控制信号与 T2I 模型内部的知识对齐,从而实现对生成结果的颜色和结构的灵活控制。具体来说,T2I-Adapter 提取多尺度的条件特征,并将这些特征注入到 T2I 模型的 UNet 编码器中,以增强生成过程。该方法具有以下优势:1) 即插即用,不影响原始 T2I 模型的结构和生成能力;2) 轻量级,仅需约 77M 参数和 300M 存储空间;3) 灵活,可针对不同条件训练多种适配器;4) 可组合,多个适配器可以组合使用以实现多条件控制;5) 可泛化,训练后的适配器可以直接应用于基于同一 T2I 模型的自定义模型。通过大量实验,T2I-Adapter 在生成质量和控制能力上均表现出色,能够实现丰富的图像编辑效果。
8. TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
TF-ICON 是一个新颖的训练自由的图像引导合成框架,它利用基于注意力机制的文本驱动扩散模型来实现跨域图像合成。该框架的核心在于无需额外训练、微调或优化即可完成图像合成任务,能够在 20 步采样内完成合成,并且能够利用丰富的语义知识在不同视觉领域(如照片写实、油画、素描和卡通动画)中实现图像引导合成。模型的输入条件包括主图像(背景图像)、参考图像(前景图像)、用户指定的掩码区域以及文本提示。主图像提供了合成的背景环境,参考图像中的对象将被合成到主图像中,用户掩码指定了参考图像中需要合成到主图像的区域,文本提示则用于指导合成过程,确保合成结果符合用户期望的视觉风格和内容。此外,TF-ICON 引入了一种特殊的“异常提示”(exceptional prompt),用于在预训练的文本到图像模型中准确地将真实图像反转为潜在代码,为后续的合成生成奠定了基础。
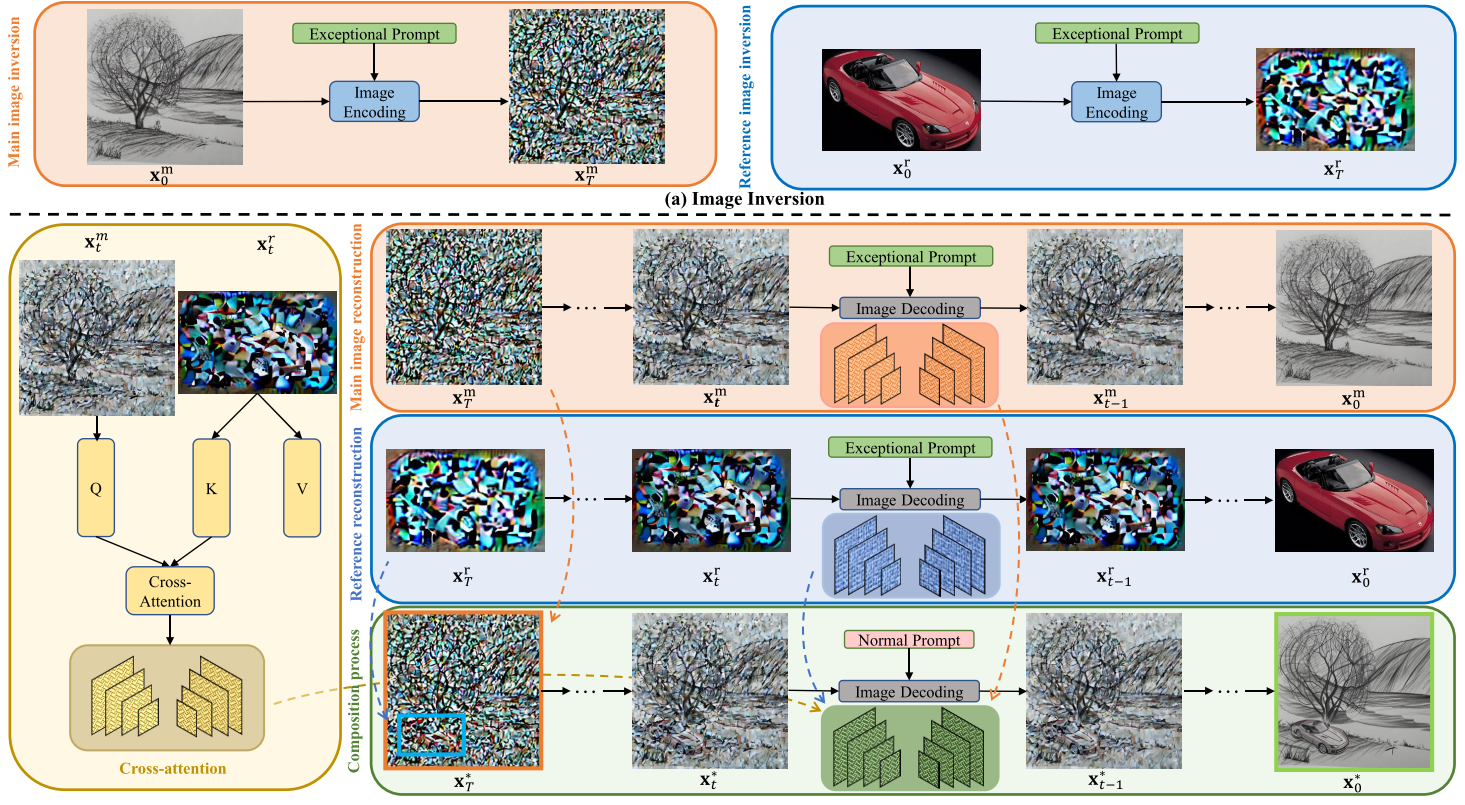
9. Uni-paint: A Unified Framework for Multimodal Image Inpainting with Pretrained Diffusion Model
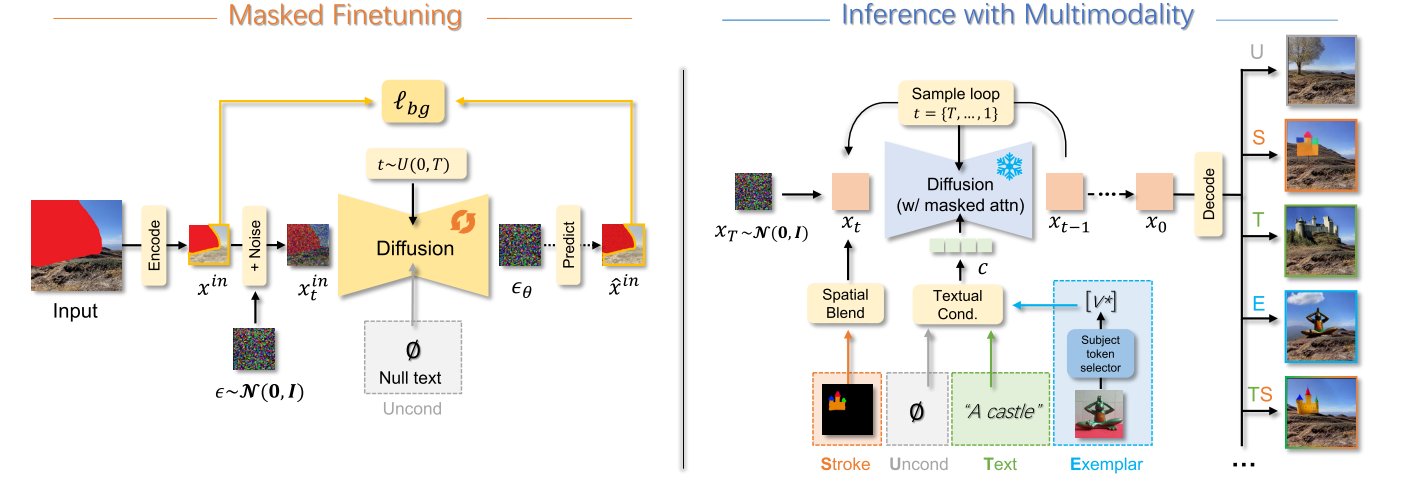
Uni-paint 是一个基于预训练扩散模型的多模态图像修复框架,支持无条件、文本引导、笔触引导、示例引导以及混合引导的修复模式。该框架的核心在于通过掩码微调(masked finetuning)和掩码注意力控制(masked attention control)机制,使模型能够根据不同的输入条件生成高质量的修复结果。具体来说,掩码微调使模型能够基于已知图像区域进行无条件修复,而掩码注意力控制则限制了修复内容的范围,避免修复内容溢出到已知区域。此外,Uni-paint 利用预训练的 Stable Diffusion 模型的条件接口,通过文本嵌入和图像嵌入实现语义引导和空间引导的修复。模型的输入条件包括一张不完整的输入图像、一个指示已知区域的二值掩码、可选的文本提示、示例图像或笔触图。通过这些输入,Uni-paint 能够在保持与现有单模态方法相当的修复质量的同时,提供多模态修复能力,从而在不同的修复任务中实现更好的灵活性和可扩展性。
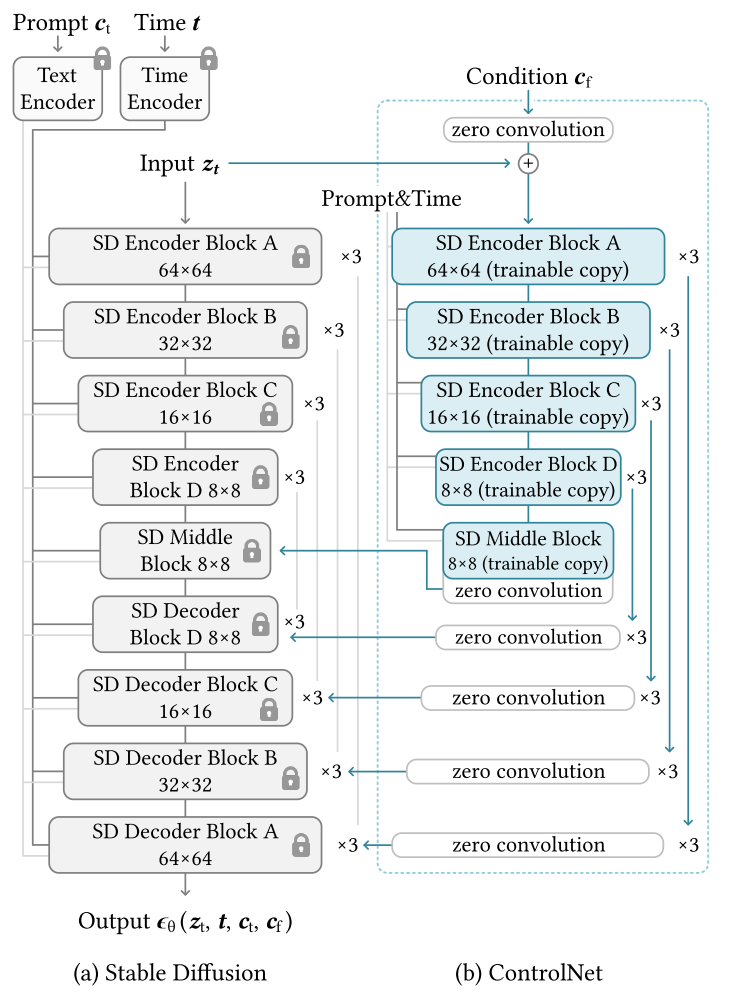
10. Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet 是一种神经网络架构,旨在为大型预训练文本到图像扩散模型(如 Stable Diffusion)添加空间条件控制。模型输入包括文本提示、条件图像(如边缘图、姿态图、分割图等)以及可选的二值掩码(用于指定编辑区域)。ControlNet 的核心结构是通过“零卷积”(权重和偏置均初始化为零的卷积层)将原始模型的编码层锁定并复制为可训练副本,从而在训练初期避免有害噪声干扰预训练模型的深层特征。在训练过程中,ControlNet 逐渐学习将条件图像的语义信息与预训练模型的特征对齐,从而实现对生成图像的精确控制。该架构不仅保留了原始模型的高质量生成能力,还通过条件图像提供了更细粒度的空间控制,支持单条件或多条件组合使用,且训练过程对小数据集(<50k)和大数据集(>1M)均具有鲁棒性。
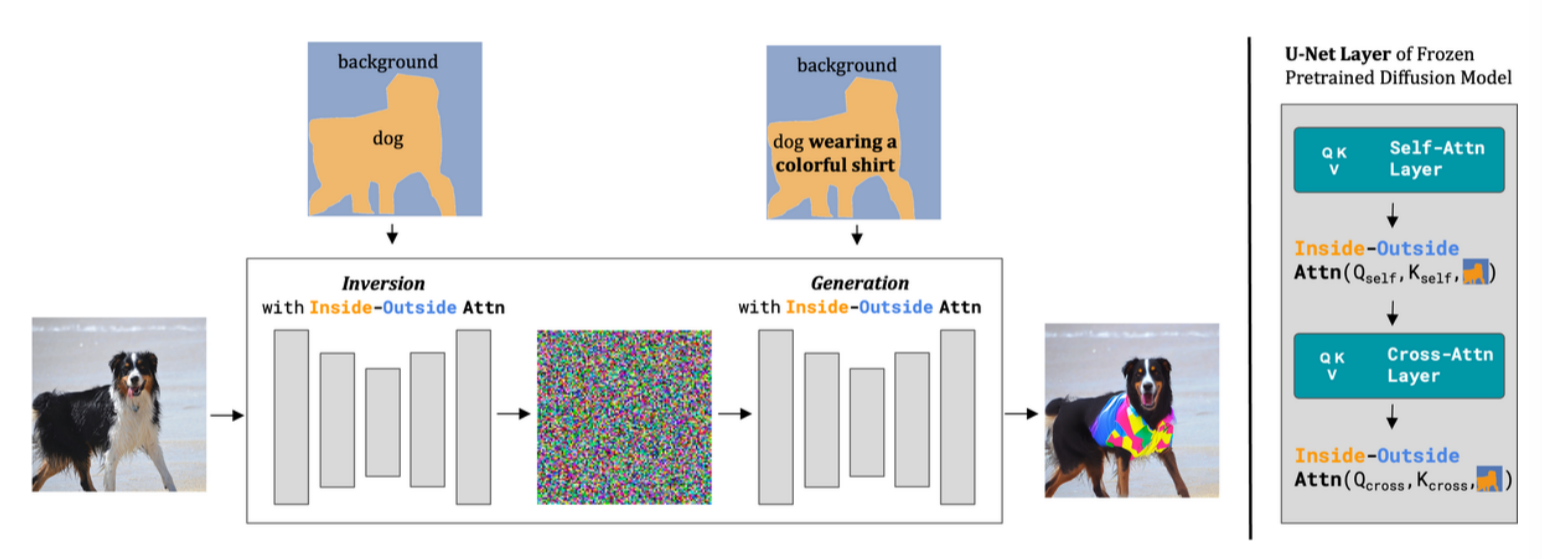
11. Shape-Guided Diffusion with Inside-Outside Attention
Shape-Guided Diffusion 是一种训练自由的文本到图像扩散模型,专门用于局部图像编辑任务,能够根据文本提示和对象掩码精确地替换图像中的对象,同时保留对象的形状。该模型的核心是 Inside-Outside Attention 机制,它在扩散模型的逆向(图像到噪声)和生成(噪声到图像)过程中对交叉注意力和自注意力图进行约束,确保对象(内部)与背景(外部)的编辑被正确地定位到相应的空间区域。模型的输入条件包括:一张真实图像、一个描述原始对象的源文本提示、一个描述编辑后对象的编辑文本提示,以及一个可选的对象掩码(如果未提供,模型将使用形状推断函数从源文本提示中推断掩码)。通过这些输入,Shape-Guided Diffusion 能够生成与文本提示和掩码形状都保持一致的编辑图像,同时在自动评估指标(如 mIoU、FID 和 CLIP 分数)和人工评估中均优于现有方法。
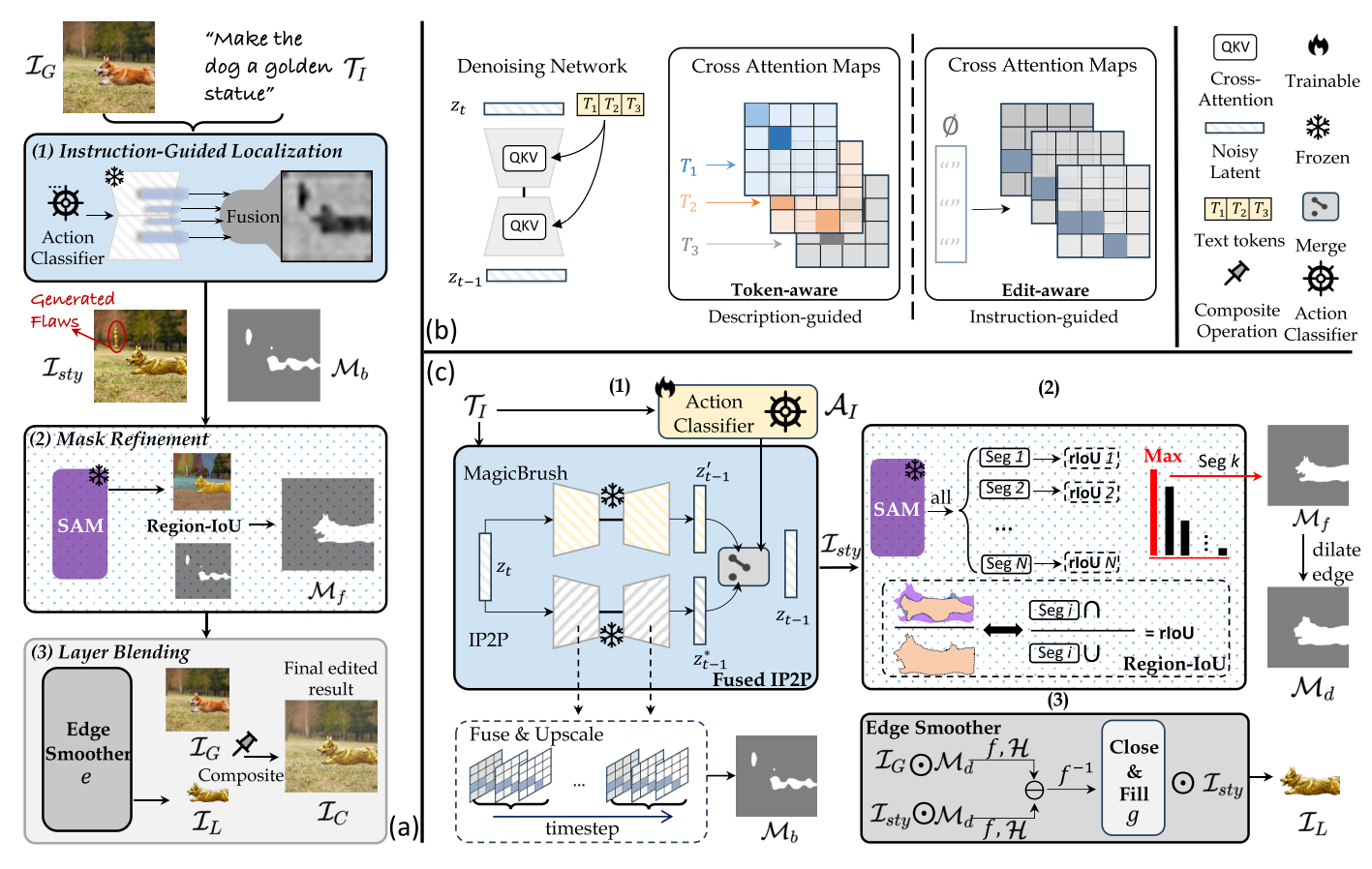
 12. ZONE: Zero-Shot Instruction-Guided Local Editing
12. ZONE: Zero-Shot Instruction-Guided Local Editing
ZONE(Zero-Shot Instruction-Guided Local Editing)是一种零样本指令引导的局部图像编辑方法,其核心架构包括三个主要模块:指令引导定位模块、掩码细化模块和边缘平滑模块。模型的输入条件包括一张RGB图像和一条文本指令。具体来说,首先通过指令引导定位模块利用InstructPix2Pix模型的注意力机制,将用户提供的文本指令(如“让他的领带变成蓝色”)转化为具体的图像编辑区域,并生成一个粗略的编辑区域掩码。然后,通过掩码细化模块结合Segment Anything Model(SAM)和提出的Region-IoU方案,对编辑区域掩码进行精细化处理,以获得更精确的编辑区域。最后,利用基于快速傅里叶变换(FFT)的边缘平滑模块,将编辑后的图像层与原始图像无缝融合,生成最终的编辑结果。整个模型无需额外训练或微调,能够实现高保真度的局部图像编辑,同时保留未编辑区域的原始细节。
 13. HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models
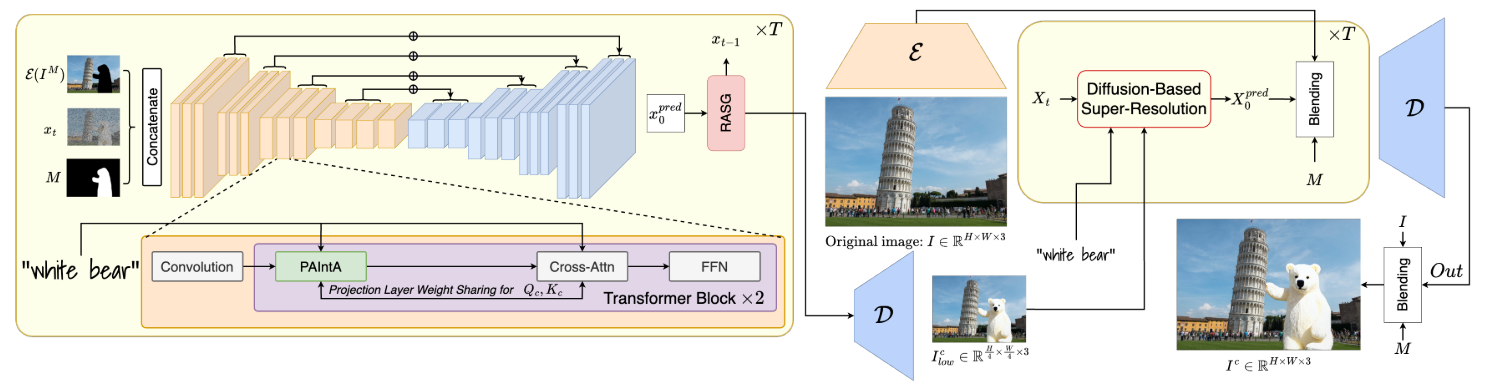
13. HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models
HD-Painter 是一种无需训练的高分辨率文本引导图像修复方法,旨在解决现有模型在文本对齐和高分辨率修复方面的不足。其输入条件包括一张图像、一个二值掩码(指示需要修复的区域)和一个文本提示。模型架构分为两个阶段:首先,使用预训练的修复扩散模型(如 Stable Inpainting)进行文本引导的图像修复,将自注意力层替换为 Prompt-Aware Introverted Attention(PAIntA)层,以增强文本对齐能力;然后,通过 Reweighting Attention Score Guidance(RASG)机制进一步提升文本对齐效果。其次,利用专门的超分辨率技术对修复后的低分辨率图像进行上采样,以实现高达 2K 分辨率的图像修复。PAIntA 通过调整自注意力分数,减少已知区域对未知区域的影响,同时增加与文本提示对齐的已知像素的贡献。RASG 则通过在 DDIM 过程中无缝集成梯度重加权机制,防止潜在空间的分布偏移,从而生成更符合文本提示的修复结果。此外,HD-Painter 的超分辨率技术利用已知区域的细节信息,无缝地扩展生成区域,确保高分辨率图像的修复效果。
14. Differential Diffusion: Giving Each Pixel Its Strength
Differential Diffusion 是一种新型框架,能够在扩散模型的推理过程中对图像的每个像素或每个区域的编辑强度进行精细控制。该框架的核心在于通过改变不同区域在不同时间步的编辑强度,实现对原始图像保真度的空间控制。具体来说,它引入了一个“变化图”(change map)的概念,该图与输入图像具有相同的维度,描述了每个位置的编辑强度。在推理过程中,该框架将变化图分解为一系列嵌套的掩码,并迭代应用这些掩码,使得每个区域根据掩码在不同的时间步开始推理过程,从而控制每个区域的编辑强度。该框架无需任何优化过程,如微调或训练,即可实现对现有扩散模型的增强,为图像编辑提供了更灵活的控制能力。