VLLM推理可以分配不同显存限制给两张卡吗?
环境:
VLLM 0.8.5
H20 96G
问题描述:
VLLM推理可以分配不同显存限制给两张卡吗?
一张卡90G显存,一张卡还有50多空余显存。
解决方案:
vLLM的gpu-memory-utilization参数是全局设置,不能为每张GPU单独分配不同的显存利用率。你只能设置一个统一的值,例如0.9,vLLM会在每张卡上按剩余可用显存的90%分配。
如何手动调整每张卡的可用显存或运行多个实例?
vLLM不支持为每张GPU单独设置显存利用率。若需手动调整每张卡的可用显存,可通过分别设置CUDA_VISIBLE_DEVICES环境变量,启动多个vLLM实例,每个实例绑定一张GPU,并为每个实例单独设置–gpu-memory-utilization参数。例如:
CUDA_VISIBLE_DEVICES=0 vllm serve ... --gpu-memory-utilization 0.5
CUDA_VISIBLE_DEVICES=1 vllm serve ... --gpu-memory-utilization 0.9
这样每个实例只占用指定GPU,并按需分配显存。
这样模型是不是单独运行两次?
是的,分别用CUDA_VISIBLE_DEVICES和不同–gpu-memory-utilization启动多个vLLM实例时,每个实例会单独加载一份模型,各自独立运行,互不共享显存和KV cache。
如需多卡协同推理,请用–tensor-parallel-size参数实现模型切分并行。
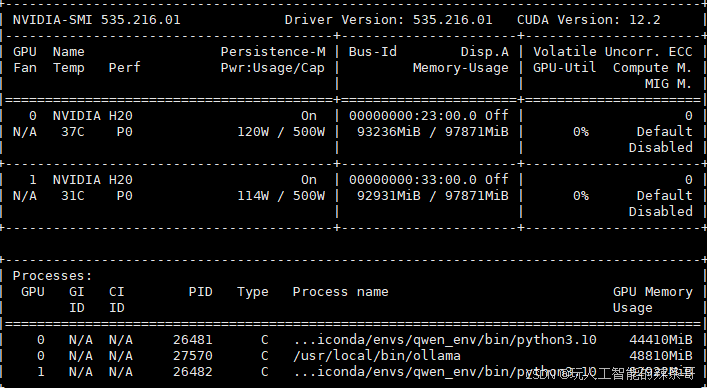
最后可以先启动别的程序,让他先占用显存,然后再启动vllm还是原来的配置
CUDA_VISIBLE_DEVICES=1 vllm serve … --gpu-memory-utilization 0.9
这样vllm这样达到推理可以分配不同显存限制给两张卡。