BLIP3-o: 全开源多模态统一模型,先理解后生成,详细解读
BLIP3-o: A Family of Fully Open Unified Multimodal Models—Architecture, Training and Dataset
Paper![]() https://arxiv.org/pdf/2505.09568v1 Code
https://arxiv.org/pdf/2505.09568v1 Code![]() https://github.com/jiuhaichen/blip3o
https://github.com/jiuhaichen/blip3o
采用diffusion transformer (DiT)去生成语义丰富的CLIP图像特征。
证明了统一模型的预训练顺序策略:首先对图像理解进行训练,然后对图像生成进行训练——保留图像理解能力,同时开发强大的图像生成能力。
最后,我们通过向GPT-4o提示涵盖各种场景、对象、人类手势等的各种字幕,精心策划了用于图像生成的高质量指令调优数据集BLIP3o-60k。
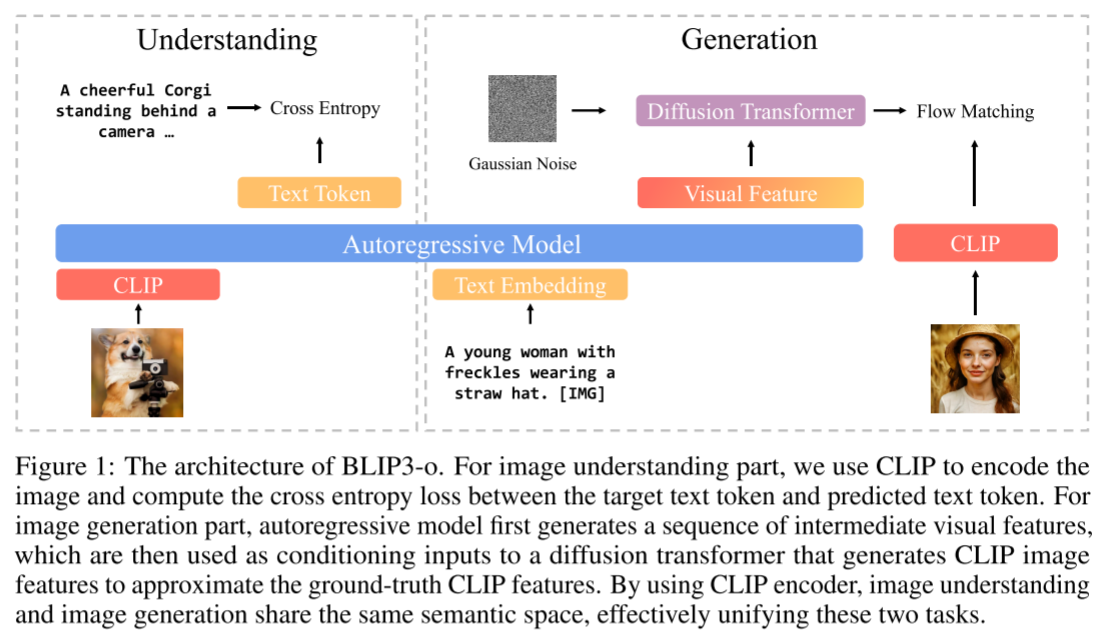
图1:BLIP3-o的架构。对于图像理解部分,我们使用CLIP对图像进行编码,并计算目标文本标记和预测文本标记之间的交叉熵损失。对于图像生成部分,自回归模型首先生成一系列中间视觉特征,然后将其用作Diffusion Transformer的条件输入,该Diffusion transformer生成CLIP图像特征以近似地面实况CLIP特征。通过使用CLIP编码器,图像理解和图像生成共享相同的语义空间,有效地统一了这两个任务。
目录
BLIP3-o: A Family of Fully Open Unified Multimodal Models—Architecture, Training and Dataset
统一的多模态图像生成和理解
动机:
自回归模型与扩散模型的结合
统一多模态图像生成
图像编码与重建
Modeling Latent Image Representation
设计选择
实现细节
统一多模态训练策略
BLIP3-o:
模型结构:
训练策略:
第1阶段:图像生成的预训练
第2阶段:图像生成的指令调整
结果
未来工作
统一的多模态图像生成和理解
动机:
本文旨在系统地研究和推进统一模型的发展,我们开始明确提出了建立统一多模态模型的关键动机。
Reasoning and Instruction Following(推理与遵循指令):将图像生成功能集成到自回归模型(如多模态大型语言模型(MLLM))中,可以继承它们的预训练知识,推理能力和指令遵循能力。例如,我们的模型能够解释提示,如“长鼻子的动物”,而不需要提示重写。这展示了传统图像生成模型难以实现的推理能力和世界知识水平。除了推理之外,MLLM的instruction-following能力预计将在并入统一架构时延续到图像生成过程。
In-context Learning(情境学习):联合支持图像理解和生成的统一模型自然促进了上下文学习能力。在这样的模型中,先前生成的多模态输出可以作为后续生成的上下文,从而无缝支持迭代图像编辑、视觉对话和逐步视觉推理。这消除了模式切换或依赖外部处理管道的需要,允许模型保持一致性和任务连续性。
Towards Multimodal AGI(走向多模态AGI):随着人工智能向通用人工智能(AGI)发展,未来的系统需要超越基于文本的能力,以无缝地感知、解释和生成多模态内容。实现这一目标需要从纯文本架构转变为统一的多模态架构,这种架构可以跨多种模态进行推理和生成。这些模型对于构建能够以整体的、类似人类的方式与世界互动的通用智能至关重要。
自回归模型与扩散模型的结合
GPT-4o的结构pipeline为
![]()
表明自回归和扩散模型可以被联合利用,来组合两个模块的优势。受这种混合设计的启发,我们在研究中采用了自回归+扩散框架。自回归模型产生连续的中间视觉特征,来近似gt图像表示吗,这引起两个关键的问题。(1)gt embedding是什么,应该VAE还是CLIP来将图像编码为连续特征?(2)一旦自回归模型生成视觉特征,我们如何将它们与地面实况图像特征进行最佳对齐?或者更一般地说,我们应该如何对这些连续视觉特征的分布进行建模:通过简单的MSE损失,还是采用基于扩散的方法?
统一多模态图像生成
图像编码与重建
Variational Autoencoders:变分自动编码器(VAEs)是一类生成模型,它学习将图像编码到结构化的连续潜在空间中。编码器在给定输入图像的潜变量上近似后验分布,解码器从从该潜分布提取的样本重建图像。
带扩散解码器的CLIP编码器:CLIP模型已经成为图像理解任务的基本编码器,因为其在大量图文对进行对比训练,具有从图像中提取丰富的高级语义特征的强大能力。然而,利用此功能来生成图像仍然具有挑战,因为CLIP最初不是为重建任务设计的。Emu2通过将基于CLIP的编码器与基于扩散的解码器配对,提出了一种实用的解决方案。CLIP编码器将图像压缩成语义丰富的潜在嵌入,基于扩散的解码器从这些嵌入中重建图像。值得注意的是,虽然解码器是基于扩散架构,但它是用重建损失而不是概率采样目标来训练的。因此,在推理期间,模型执行确定性重构。这个过程有效地将CLIP和扩散模型结合到图像自动编码器中
Discussion:VAE将图像编码为低级像素特征,并提供更好的重建质量。此外,VAE作为现成模型广泛使用,可以直接集成到图像生成训练管道中。相比之下,CLIP-Diffusion需要额外的训练来使扩散模型适应各种CLIP编码器。然而,CLIP扩散架构在图像压缩比方面提供了显著的优势。例如,在Emu2和我们的实验中,每个图像无论其分辨率如何都可以编码为固定长度的64个连续向量,从而提供紧凑且语义丰富的潜在嵌入。相比之下,基于VAE的编码器倾向于为更高分辨率的输入产生更长的潜在嵌入序列,这增加了训练过程中的计算负担。
Modeling Latent Image Representation
将用户提示(例如,“一个戴着草帽的雀斑年轻女性。”)通过自回归模型的输入嵌入层编码为嵌入向量序列 C,并附加可学习的查询向量 Q(训练中随机初始化并优化),形成组合序列 [C;Q]。通过自回归变换器处理 [C;Q],使 Q 学习关注并提取提示 C 中的相关语义信息,生成中间视觉特征(或潜在表示)Q。通过均方误差(MSE)和流匹配两种训练目标,训练 Q 以近似从 VAE 或 CLIP 获得的地面实况图像特征 X,实现 Q 与图像嵌入 X 的对齐。
MSE Loss:给定自回归模型产生的预测视觉特征Q和GT图像特征X,我们首先应用可学习的线性投影来对齐Q和X的维度。W表示可学习投影矩阵。然后将MSE损失表述为:
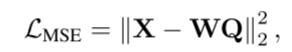
Flow Matching:注意使用MSE损失仅将预测的图像特征Q与目标分布的平均值对齐。一个理想的训练目标是对连续图像表示的概率分布进行建模。我们建议使用flow matching(流匹配),这是一种扩散框架。GT为X1,Q为条件编码,时间步t,噪声X0,通过X0和X1之间的简单线性插值计算Xt:(?这Xt计算公式写的对吗,应该是tX1+(1-t)X0吧)
![]()
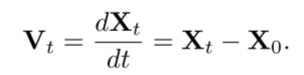
训练目标为:
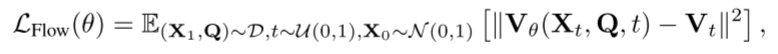
其中θ是扩散变压器的参数,Vθ(Xt, Q,t)表示基于实例(X1,Q)、时间步长t和噪声X0的预测速度。
讨论:
与离散标记不同,离散标记本质上支持基于采样的策略来探索不同的生成路径,连续表示缺乏这一属性。具体来说,在基于MSE的训练目标下,对于给定的提示,预测的视觉特征Q变得几乎是确定性的。因此,无论视觉解码器是基于VAE还是CLIP+扩散架构,输出图像在多次推理运行中几乎保持相同。这种确定性突出了MSE目标的一个关键限制:它限制模型为每个提示产生单一的、固定的输出,从而限制了生成多样性。
相比之下,流匹配框架使模型能够继承扩散过程的随机性。这允许模型以相同的提示为条件生成不同的图像样本,便于更广泛地探索输出空间。然而,这种灵活性是以增加模型复杂性为代价的。与MSE相比,流匹配引入了额外的可学习参数。在我们的实现中,我们使用diffusion transformer(DiT),并根据经验发现扩展其容量会产生显著的性能改进。
设计选择
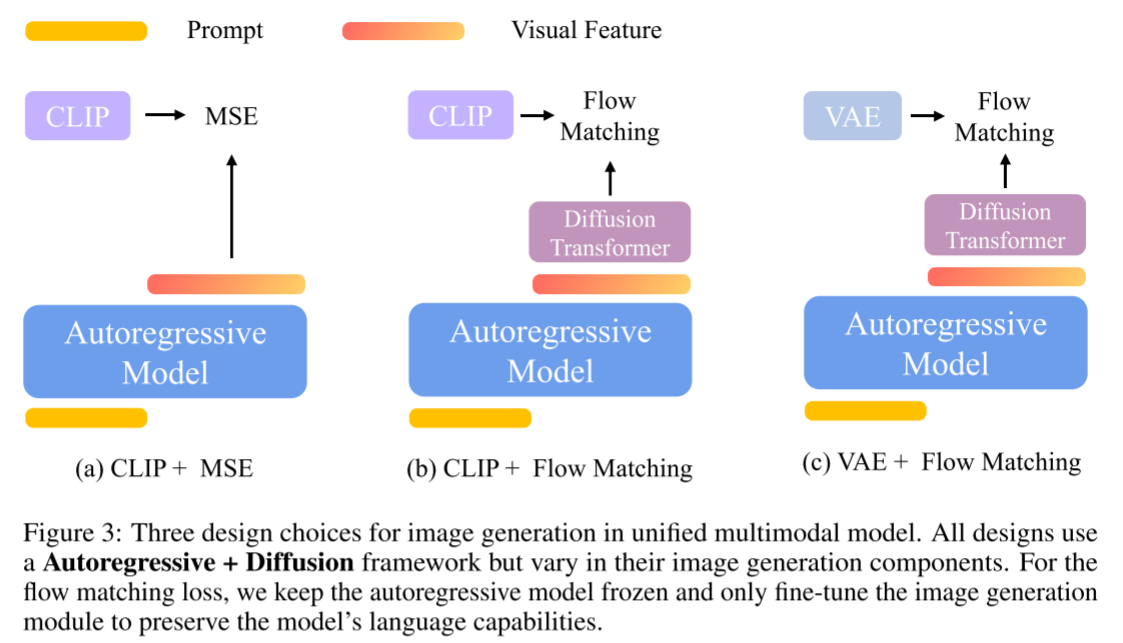
CLIP + MSE:在推理过程中,给定文本提示C,自回归模型预测潜在的视觉特征Q,随后将其传递给基于扩散的视觉解码器以重建真实图像。
CLIP + Flow Matching:本质上,推理管道包括两个扩散阶段:第一个使用条件视觉特征Q迭代去噪为CLIP嵌入。第二个通过基于扩散的视觉解码器将这些CLIP嵌入转换为真实图像。这种方法在第一阶段实现了随机采样,从而允许图像生成的更大多样性。
VAE + Flow Matching:在推理时,给定提示C,自回归模型产生视觉特征Q。然后,调节Q并在每一步迭代去除噪声,真实图像由VAE解码器生成。
VAE + MSE:因为重点是自回归+扩散框架,所以排除了VAE+MSE方法,因为它们不包含任何扩散模块。
实现细节
使用Llama-3.2-1B-Instruct作为自回归模型。训练数据由CC12M、SA-1B和JourneyDB组成,总计约2500万个样本。CC12M和SA-1B使用LLaVA生成的详细字幕,JourneyDB使用原始字幕。
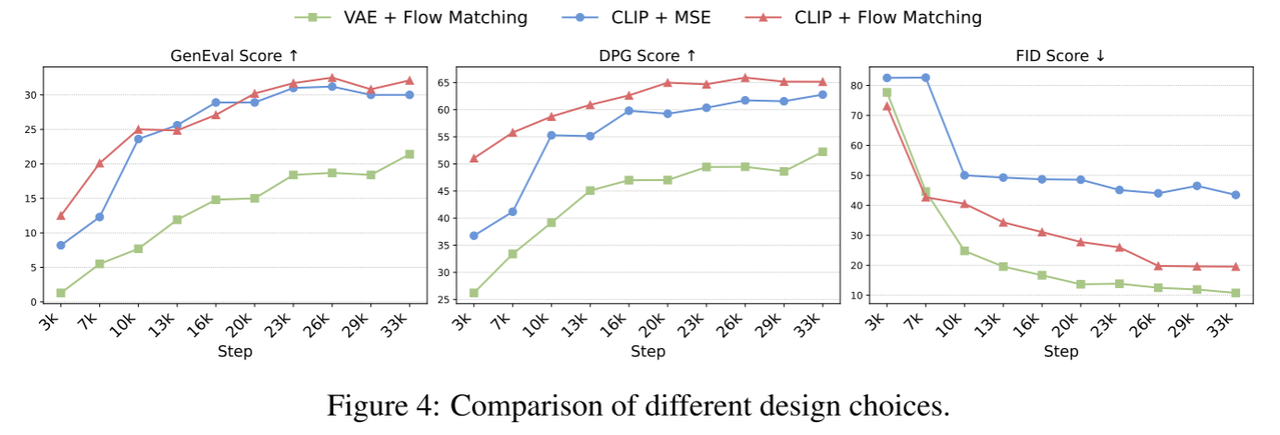
总的来说,实验表明CLIP+Flow Matching是最有效的设计选择。
两个发现:(1)CLIP比VAE学习语义级特征更有效;(2)flow matching作为训练目标更好地捕捉底层图像分布,从而提高样本多样性和视觉质量。
统一多模态训练策略
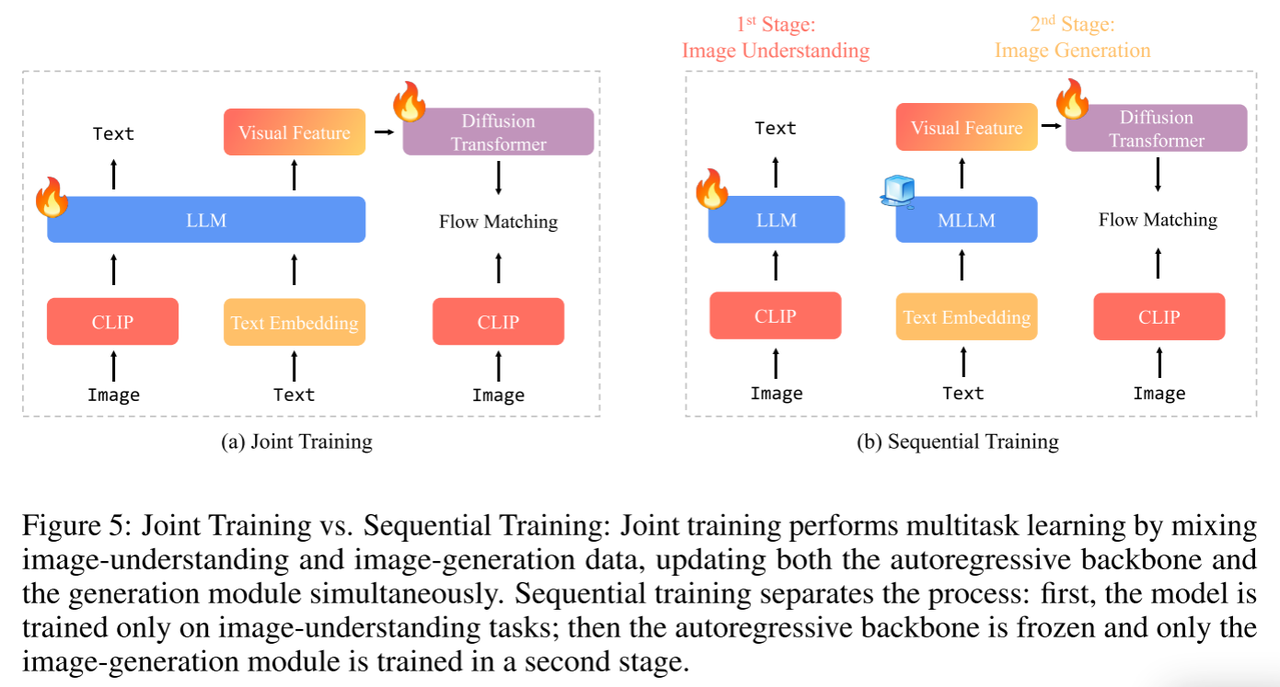
在联合训练设置中,尽管图像理解和生成任务可能会相互受益,但i)总数据大小和(ii)图像理解和生成数据之间的数据比率会影响它们的协同效应。相比之下,顺序训练提供了更大的灵活性:它让我们可以冻结自回归主干并保持图像理解能力。我们可以将所有训练能力用于图像生成,避免联合训练中的任何任务间效应。
我们将选择顺序训练来构建我们统一的多模态模型,并将联合训练推迟到未来的工作中。
BLIP3-o:
基于以上发现,BLIP3-o采用CLIP + Flow Matching,顺序训练开发。
模型结构:
我们开发了两种不同大小的模型:在专有数据上训练的8B参数模型和仅使用开源数据的4B参数模型。鉴于存在强大的开源图像理解模型,例如Qwen2.5VL,我们跳过图像理解训练阶段,直接在Qwen 2.5 VL上构建我们的图像生成模块。在8B模型中,我们冻结Qwen2.5VL-7B-Instruct主干并训练diffusion transformers,总计1.4 B可训练参数。4B模型遵循相同的图像生成架构,但使用Qwen2.5-VL-3B-Instruct作为主干。
Diffusion Transformer Architecture:我们利用Lumina-Next模型的架构。
训练策略:
第1阶段:图像生成的预训练
对于8B模型,我们将2500万开源数据与额外的3000万专有图像相结合。所有图像字幕均由Qwen2.5-VL-7B-Instruct生成,生成平均长度为120个标记的详细描述。为了改进对不同提示长度的泛化,我们还包括大约10%(600万)较短的字幕,其中大约有20个来自CC12M的标记。每个图像-字幕对都使用提示进行格式化:“请根据以下标题生成图像:<标题>”。
对于完全开源的4B模型,我们使用2500万公开可用的图像,每个图像都配有相同的详细字幕。我们还混合了大约10%(300万)来自CC12M的短字幕。
第2阶段:图像生成的指令调整
-
在图像生成预训练阶段之后,我们观察到模型中的几个弱点:
-
生成复杂的人类手势,例如一个人正在射箭;
-
生成常见的对象,例如各种水果和蔬菜;
-
生成地标,例如,金门大桥;
-
生成简单的文本,例如写在街道表面上的“Salesforce”一词。
为了解决这些问题,我们专门针对这些领域进行指令调整(instruction tuning)。对于每个类别,我们提示GPT-4o生成大致10k的提示图像对,创建一个有针对性的数据集,以提高模型处理这些情况的能力。为了提高视觉美学质量,我们还使用来自JourneyDB和DALL·E 3的提示扩展我们的数据。这个过程产生了大约60k高质量提示图像对的精选集合。我们还发布了这个60k的指令调整数据集。
结果
图像理解
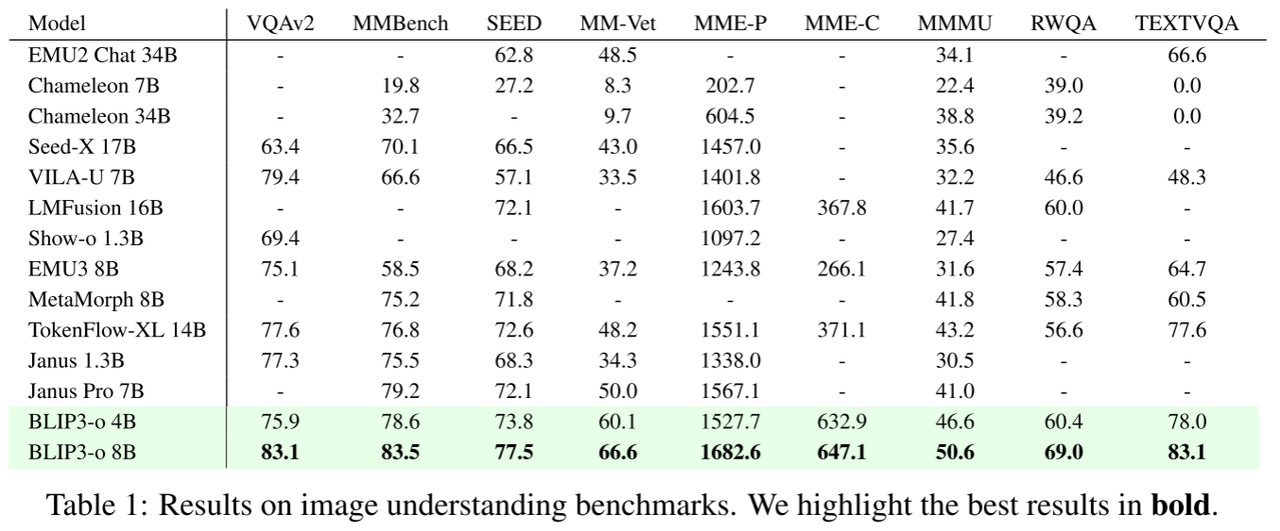
图像生成
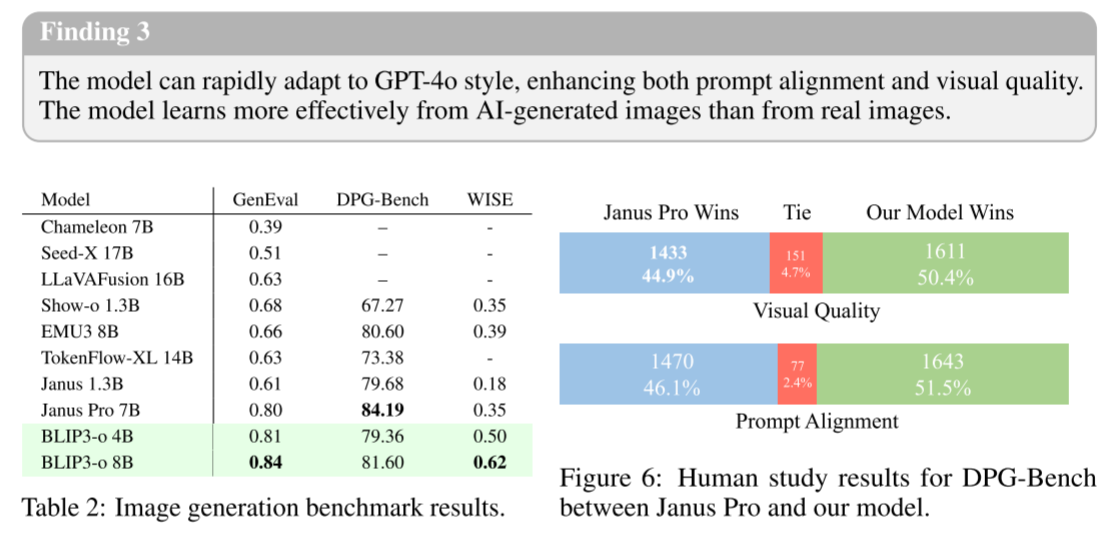
发现3:该模型可以快速适应GPT-4o风格,提高提示对齐和视觉质量。该模型从AI生成的图像中学习比从真实图像中学习更有效。
未来工作
我们目前正在将我们的统一多模态扩展到下游任务,如图像编辑、多轮视觉对话和交错生成。作为第一步,我们将专注于图像重建:将图像输入图像理解视觉编码器,然后通过图像生成模型重建它们,以无缝连接图像理解和生成。在此能力的基础上,我们将收集指令调整数据集,以使模型适应各种下游应用。