GraphRAG使用
GraphRAG是什么
是一种结构化的、分层的检索增强生成(RAG)方法,而不是使用纯文本片段的语义搜索方法。
GraphRAG 过程如下:
- 原始文本中提取出知识图谱
- 构建社区层级,这种结构通常用来描述个体、群体及它们之间的关系,帮助理解信 息如何在社区内部传播、知识如何共享以及权力和影响力如何分布
- 为这些社区层级生成摘要,然后在执行基于 RAG 的任务时,会利用这些结构
GraphRAG与基线RAG
大多数 RAG 使用矢量相似性作为搜索技术,称之为基线 RAG,GraphRAG 使用知识图谱来在处理复杂信息时提供问题和回答性能的显著改进。
在某些情况下,基线 RAG 的性能非常差:
- 基线 RAG 难以连接各个要点。这种情况发生在回答问题需要通过共享属性遍历不同的信息片段,以提供新的综合见解。
- 基线 RAG 在被要求全面理解大量的数据(跨文档)或甚至单个大文档的的语义概念时表现不佳。
GraphRAG方法:
- 使用 LLMs 来创建基于输入语料库的知识图谱。这个知识图谱、社区层级摘要、以及知识图谱机器学习输出会在用户查询时用于增强提示。
- GraphRAG 在回答上述两类问题时可以显著改进回答能力,远超基线RAG。
RAG 在帮助 LLM 推理“私有数据集”方面有很大的潜力。这些数据集是 LLM 从未见过的,例如企业的专有研究、商业文件。
看一下下面例子
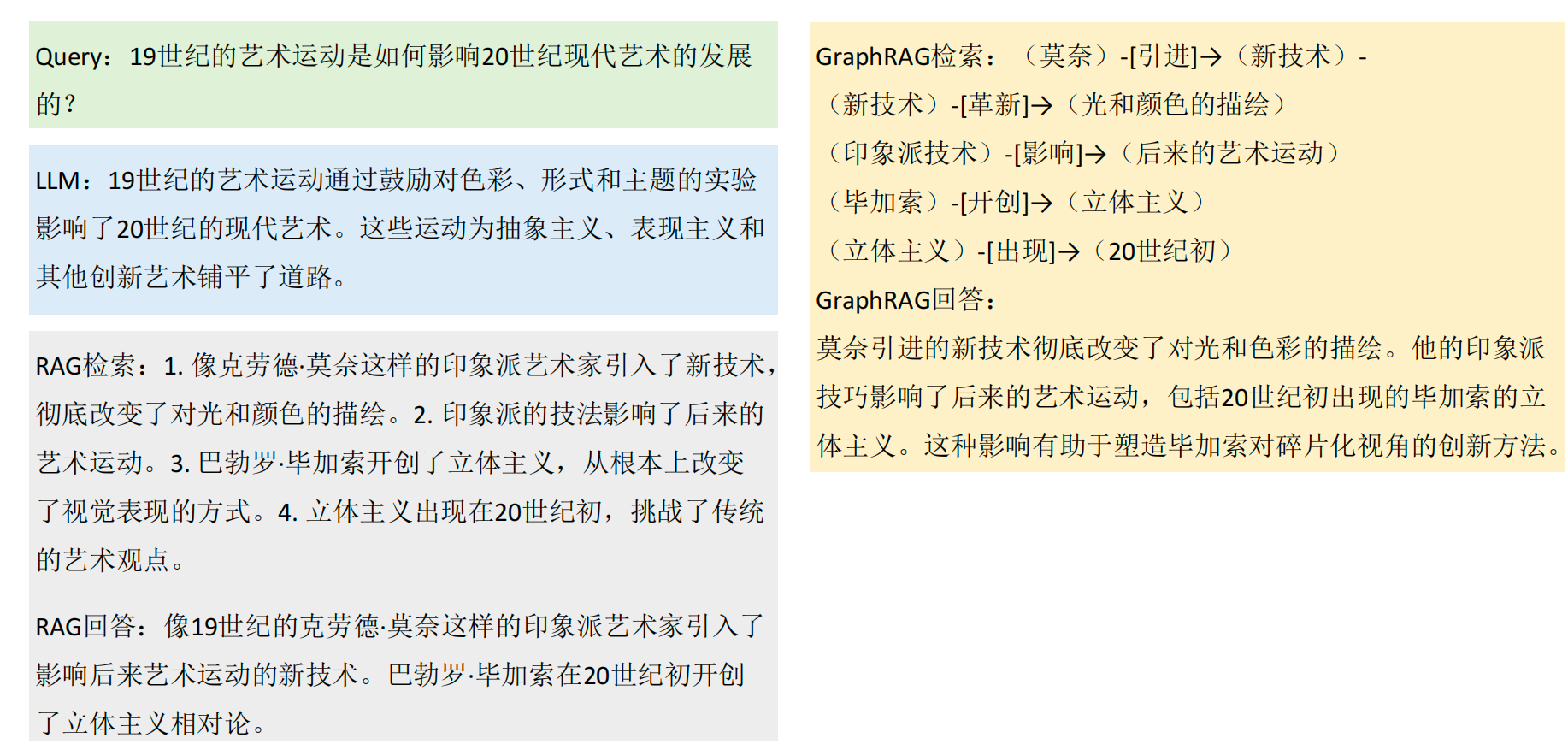
- 左图
流程:直接将问题输入大语言模型(LLMs),由其生成回答。
回答示例:指出 19 世纪艺术运动通过鼓励在色彩、形式和题材上进行实验影响 20 世纪现代艺术,为抽象主义、表现主义等创新形式铺平道路。回答存在不足。 - 中间
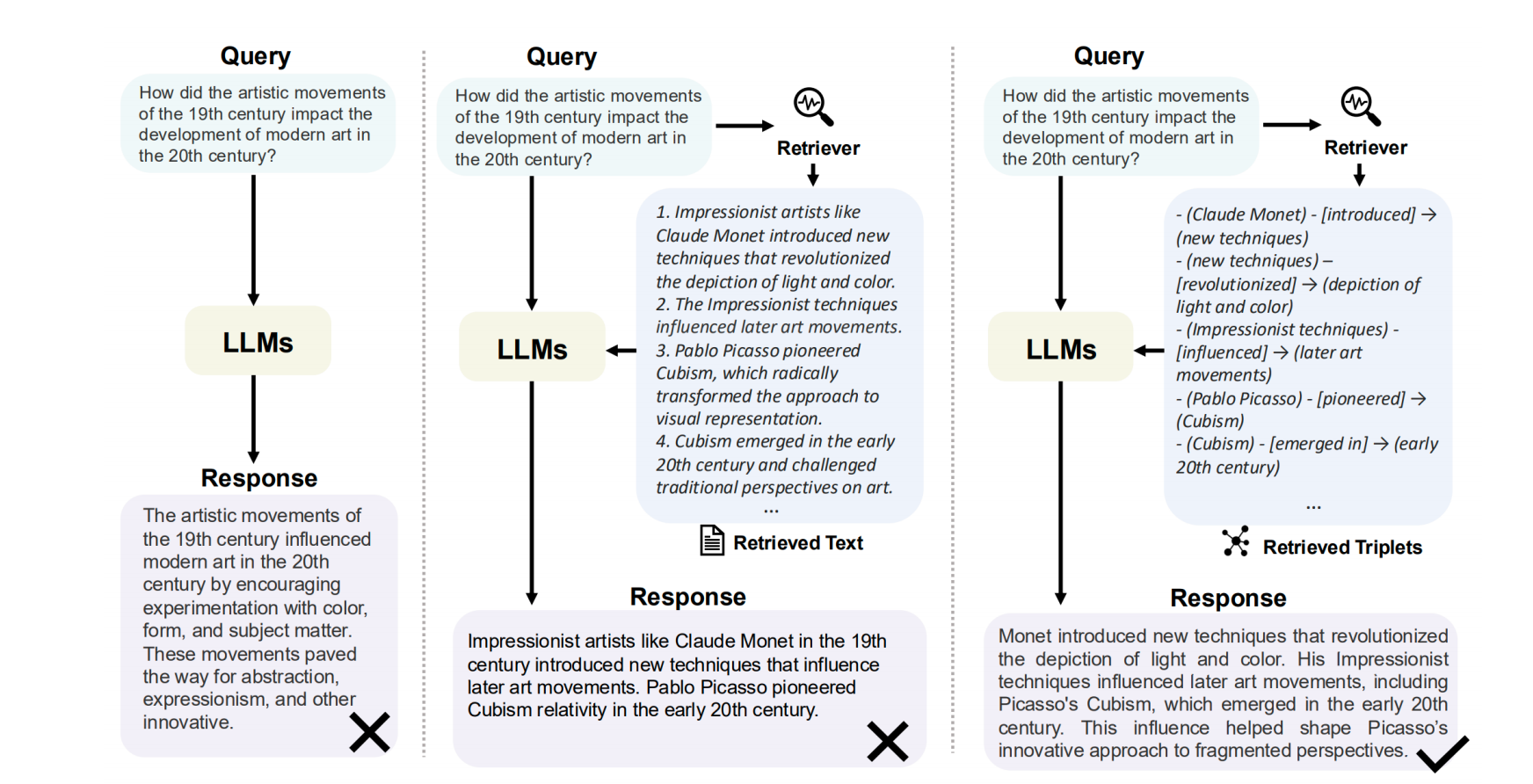
流程:先将问题输入检索器(Retriever),检索相关文本(Retrieved Text),再输入大语言模型(LLMs)生成回答。
回答示例:提到像克劳德・莫奈等印象派画家引入新技法影响后来艺术运动,巴勃罗・毕加索开创立体主义等。回答不理想。 - 右图
流程:问题经检索器(Retriever),检索出三元组信息(Retrieved Triplets ,如人物 - 行为 - 事件等关系信息 ),再由大语言模型(LLMs)生成回答。
回答示例:阐述莫奈新技法革新光影描绘并影响后续艺术运动,包括毕加索的立体主义,立体主义在 20 世纪初兴起并塑造毕加索对碎片化视角的创新处理方式。回答效果较好。
GraphRAG 的基本步骤
1. 索引
-
将输入语料库分割为一系列的文本单元(TextUnits),这些单元作为处理以下步骤的可分析单元,并在我们的输出中提供细粒度的引用。
-
使用 LLM 从文本单元中提取所有实体、关系和关键声明。
-
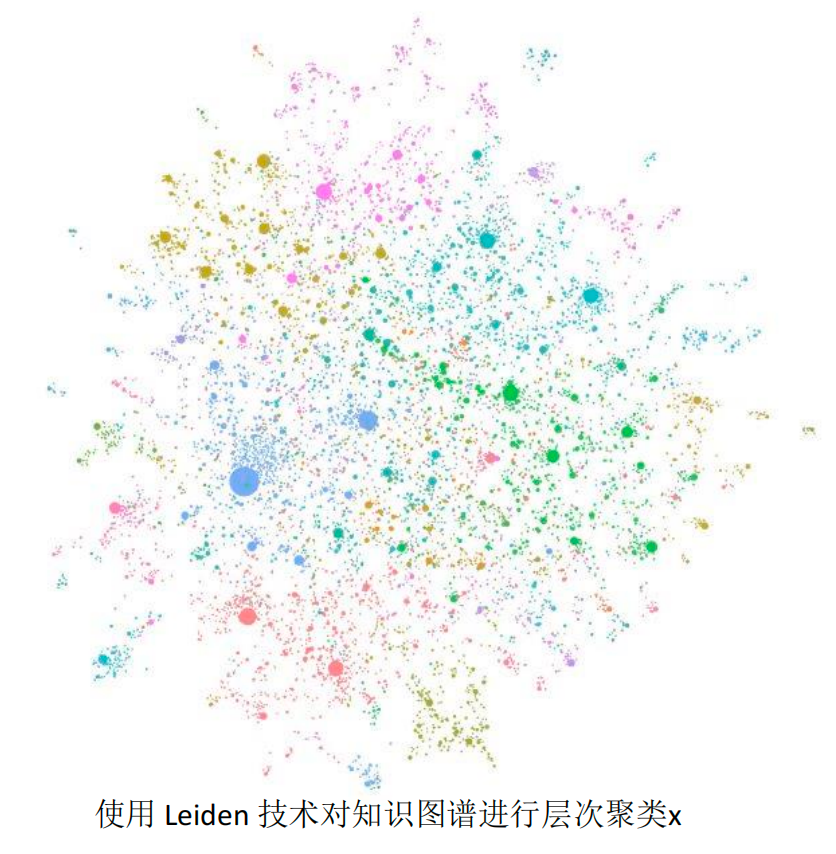
使用 Leiden 技术对知识图谱进行层次聚类。每个圆圈都是一个实体(例如人、地点或组织),大小表示实体的度,颜色表示其社区层级。
-
自下而上地生成每个社区层级及其组成部分的摘要。这有助于对数据集的整体理解。
2. 查询
-
在查询时,使用这些结构为 LLM 上下文窗口提供材料来回答问
题。主要查询模式有:- 全局搜索,通过社区层级摘要来推理有关语料库的整体问题。
- 局部搜索,通过扩展到其邻居和相关概念来推理特定实体的情况。
GraphRAG方法是使用LLM构建基于图的文本索引,分两个阶段:
首先从源文档中派生出实体知识图谱
然后为所有密切相关的实体组预生成社区摘要。

GraphRAG索引数据流
知识模型:
在GraphRAG的存储库中,包括实体类型如Document、TextUnit、Entity、Relationship、Covariate、Community Report和Node。
默认配置工作流程:将文本文档转换为知识图谱模型,主要步骤包括:
- 组合 TextUnits
将输入文档转换为TextUnits,用于知识图谱提取的文本块。用户可以配置块大小和分组方式。 - 知识图谱提取
分析每个TextUnit,用来提取实体、关系和主张。实体和关系在entity_extract动词中提取,而主张在claim_extract动词中提取。- 实体和关系提取:
使用LLM从原始文本中提取实体和关系。合并具有相同名称和类型的实体,以及具有相同源和目标的关系。 - 实体和关系概述:
通过询问LLM获取每个实体和关系的简要概述。 - 实体解析(默认未启用):
解析表示相同现实世界实体,但具有不同名称的实体。 - 主张提取和发射:
从源TextUnits中提取主张,这些主张是正面事实陈述,并作为Covariates发射。
- 实体和关系提取:
- 知识图谱增强
了解实体的社区结构,并增强知识图谱。使用层次Leiden算法进行社区检测,使用Node2Vec算法进行知识图谱嵌入。 - 社区总结
生成社区报告,了解知识图谱在各个粒度级别上的高层次情况。使用LLM生成每个社区的摘要。 - 文档处理
为知识模型创建“文档”表。如果工作流在CSV数据上运行,可以配置工作流,用于向文档输出添加其他字段。 - 网络可视化
执行UMAP降维,用于在2D空间中可视化知识图谱。UMAP嵌入作为“节点”表格发出。
GraphRAG工作流程是将文本数据转换为结构化的知识图谱,以便理解和分析数据。通过这个流程,用户可以提取关键信息,如实体、关系和主张,并在知识图谱中进行进一步的分析和可视化。
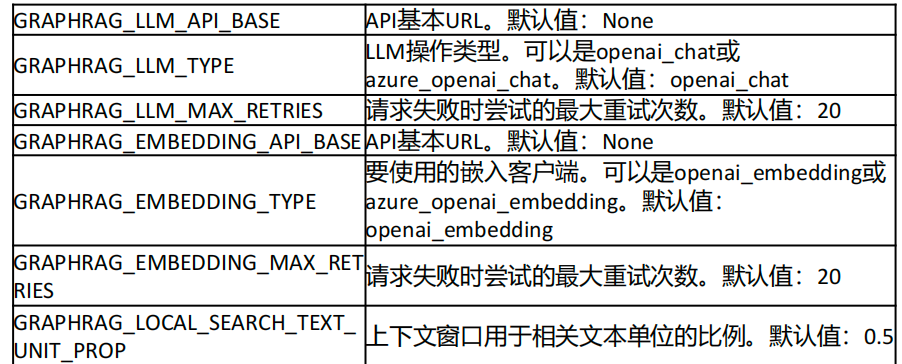
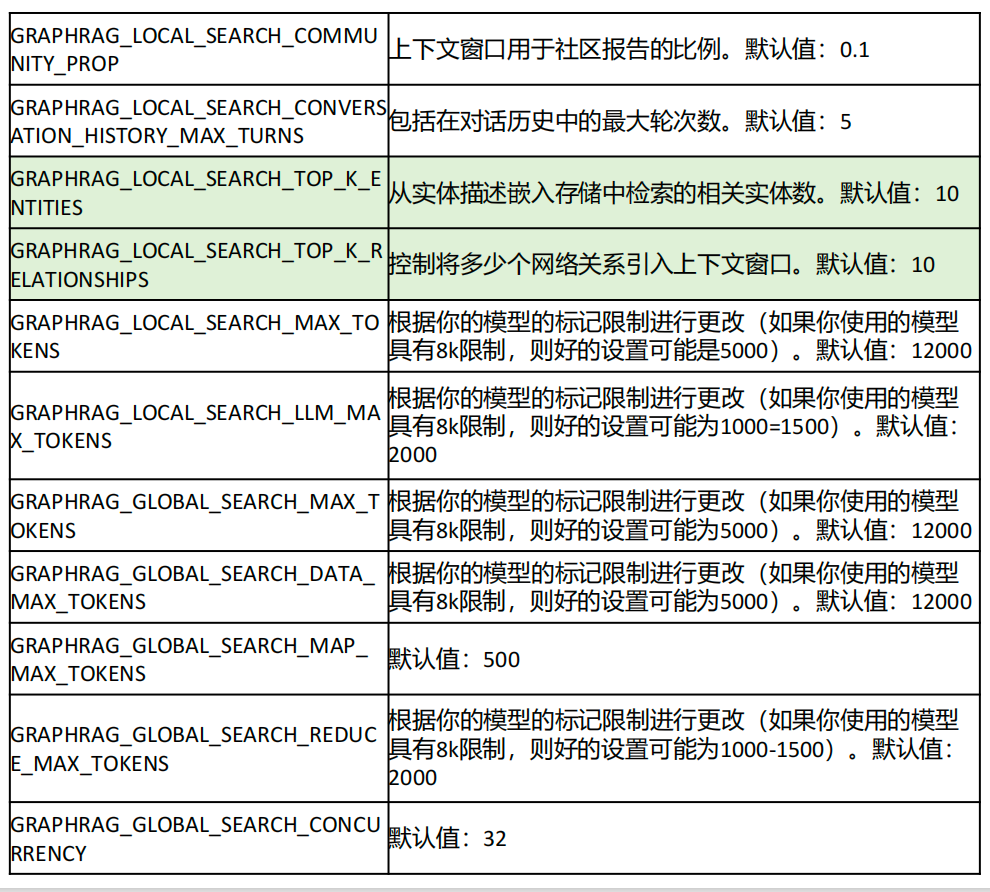
GraphRAG 使用
https://github.com/microsoft/graphrag
-
下载源码
git clone https://github.com/microsoft/graphragcd graphrag -
下载依赖并初始化项目
pip install poetry poetry install初始化
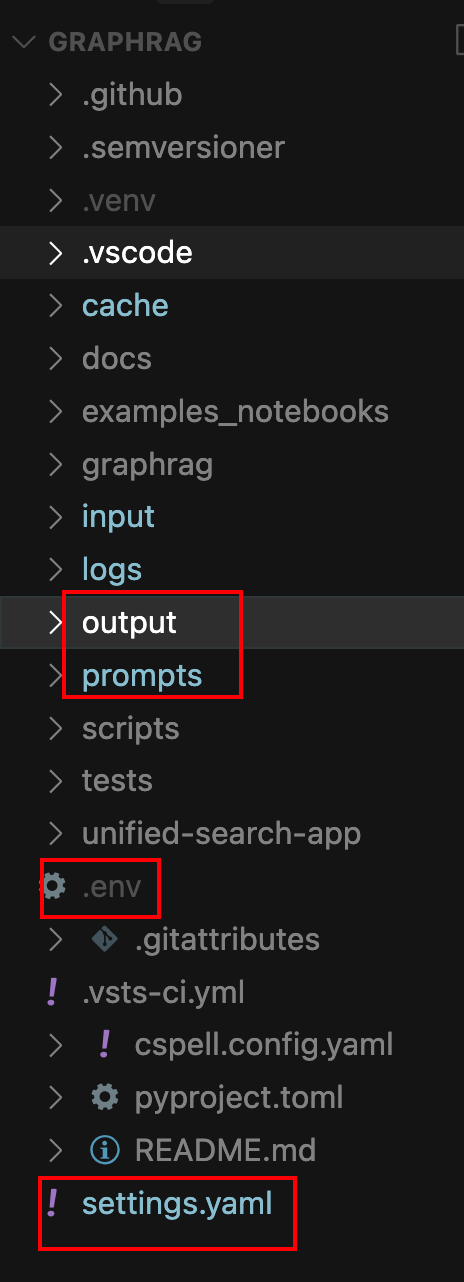
poetry run poe index --init --root .正确运行后,此处会在graphrag目录下生成output、prompts、.env、settings.yaml文件
-
将待检索的文档放到 ./cases/input 目录下
-
修改配置文件
对 .env文件配置 api_key,并修改 settings.yaml,设置 model为 gpt-4o-mini 减少成本 -
创建GraphRAG索引(耗时较长,取决于文本的大小)
本例耗时较长,比较花费tokenpoetry run poe index --init --root .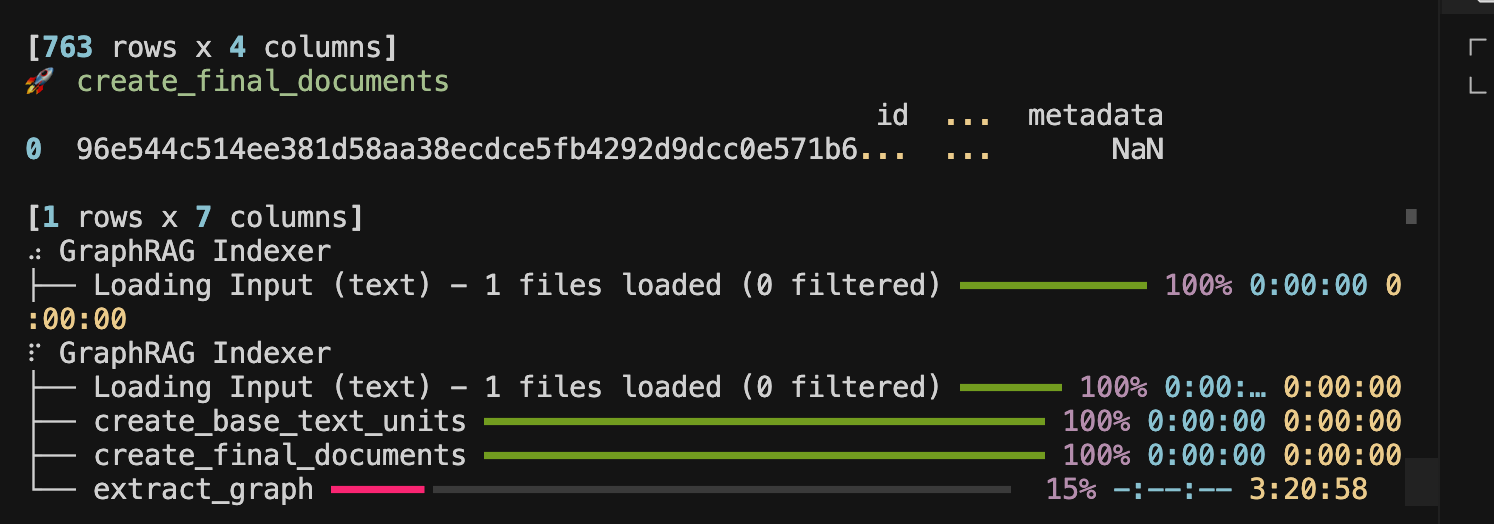
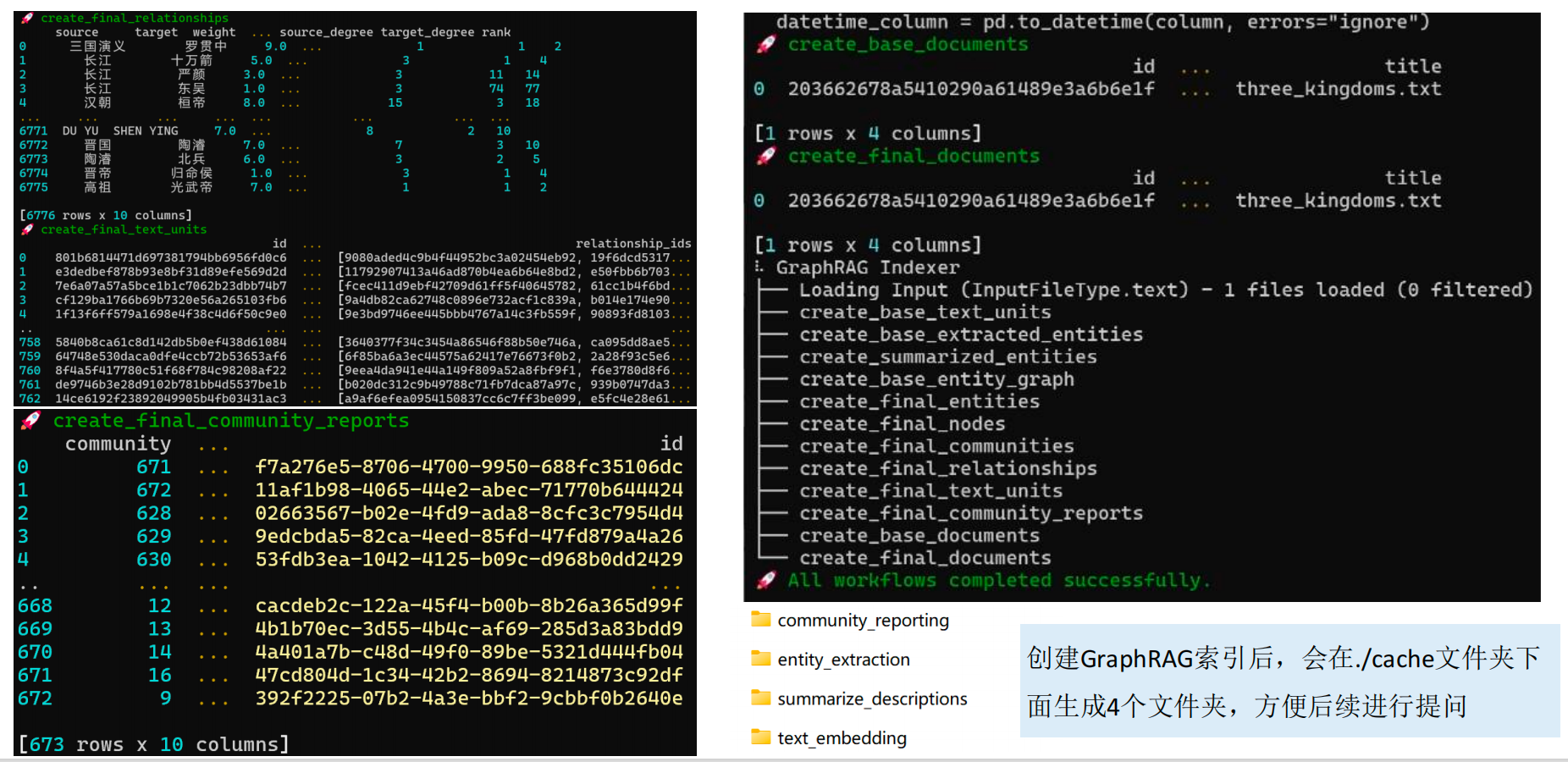
-
进行查询
下面有全局查询和本地查询的解释Global Query(全局查询)
python -m graphrag.query --root ./cases --method global "和曹操 相关的人物都有哪些?"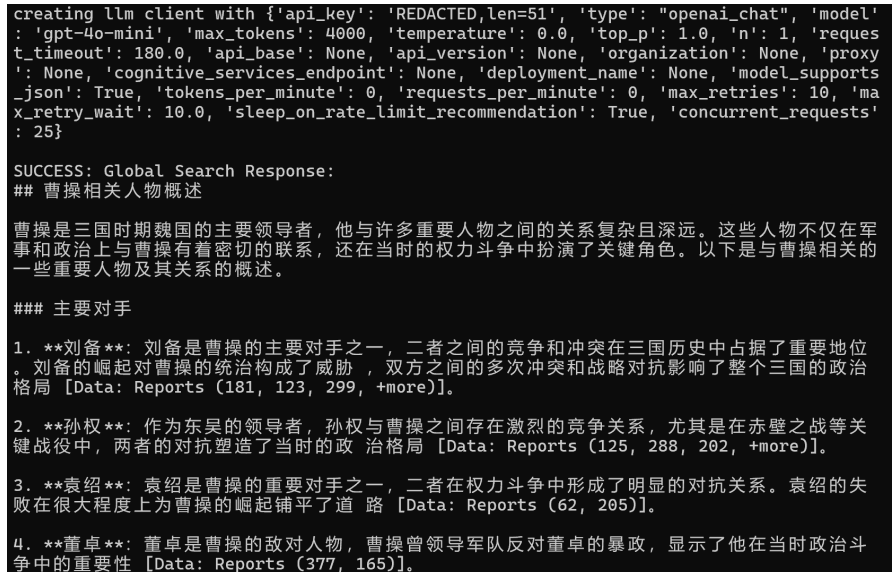

Local Query(本地查询)python -m graphrag.query --root ./cases --method local "和曹操相 关的人物都有哪些?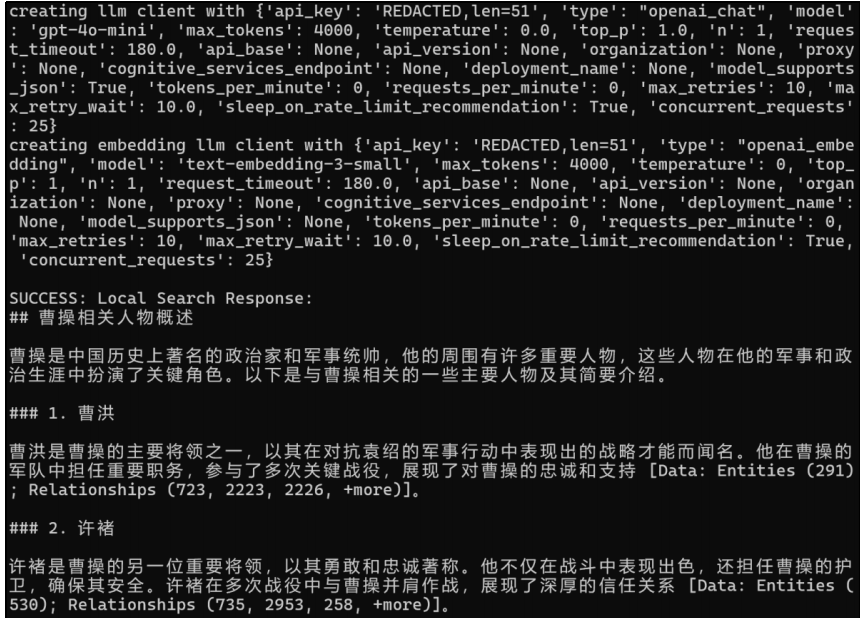
GraphRAG查询模式
Global Query 适合处理需要跨数据集汇总信息的宏观问题,而Local Query 适合处理需要理解文档中特定实体的微观问题。
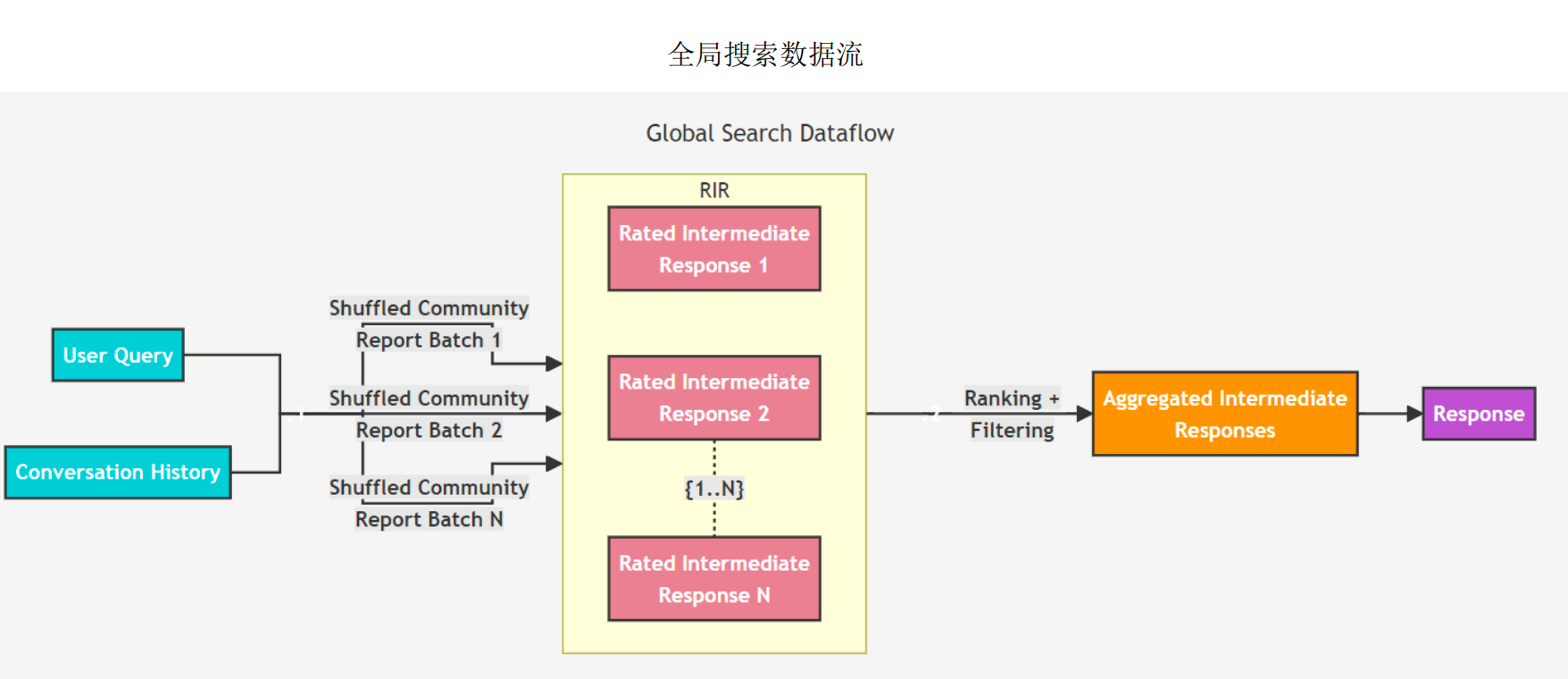
Global Query(全局查询)
用于回答全局性的问题,例如“《三国演义》的主题是什么”。
它通过利用社区摘要,对整个语料库进行整体问题的推理,利用LLM生成的知识图谱来组织和聚合信息。
在具体实现上,Global Query 方法使用从社区层次结构指定层级中收集的报告作为上下文数据,以类似Map-Reduce的方式生成响应。
在Map步骤中,社区报告被分割成文本块,每个文本块用于生成中间响应,其中每个点都有一个数值评级。
在Reduce步骤中,从中间响应中挑选出最重要的点并进行聚合,最终形成用于生成最终响应的上下文。这种方法的直观理解是:越宏观的问题需要越宏观的视角和信息来回答。
这种查询方式是资源密集型的,但通常能够很好地回答那些需要对数据集整体有全面理解的问题。
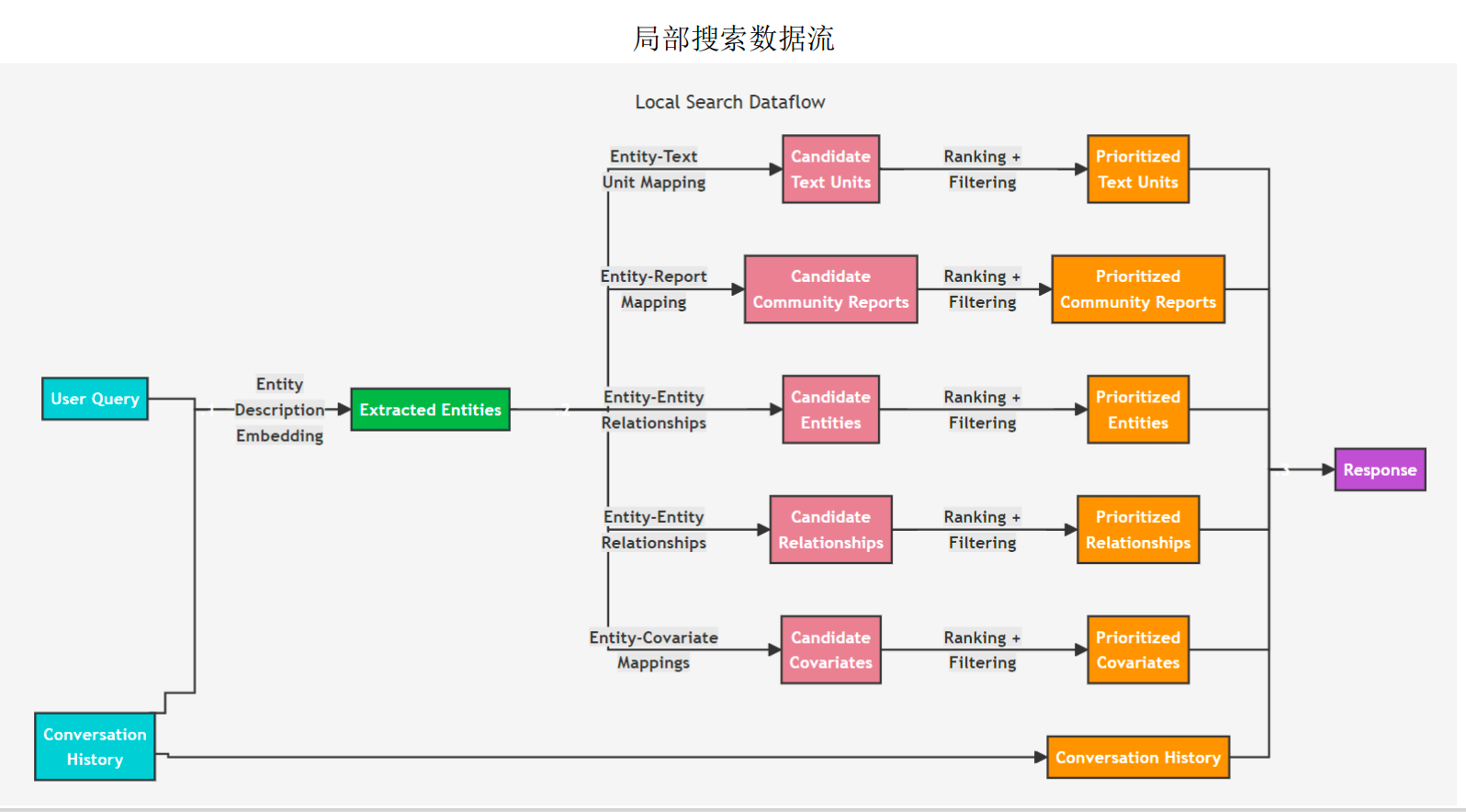
Local Query(本地查询)
用于回答更加具体的问题,例如询问 “洋甘菊有哪些治疗特性?”。
本地查询则基于更加微观的视角,结合知识图谱中的结构化数据与原始文档中的非结构化数据,来增强检索和生成过程中的上下文。
在具体实现上,系统将依据原始提问,从知识图谱中识别出一组与用户输入语义相关的实体。然后,利用这些实体作为查询条件,在知识图谱或相关数据库中进行检索,找到与这些实体直接相关的内容,包含:TextUnit、社区报告、实体、关系或
协变量(如主张)。检索的结果经过过滤和重排序后,选择高质量的数据源,并将其整合进一个预定义大小的上下文窗口。
这种方法适用于需要理解输入文档中特定实体的问题,通过结合AI提取的知识图谱和原始文档的文本块生成答案。
示例:

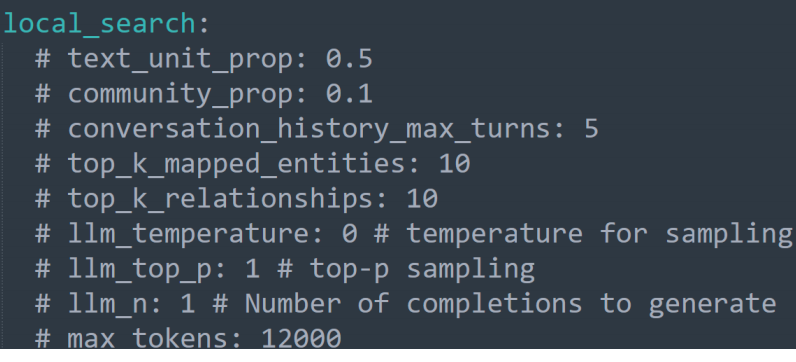
如何让匹配上的entities和关系更多一些?
对比
