spark
在Spark SQL中完成“统计有效数据条数及用户数量最多的前二十个地址”任务
1. 数据读取.
2. 格式转换:使用get_json_object函数从JSON格式数据中提取uid、phone、addr字段,形成新的DataFrame
3. 数据过滤:依据有效数据的定义(uid、phone、addr字段均无空值),使用dropna函数过滤数据
4. 统计有效数据条数:调用count函数获取有效数据的数量。
5. 统计地址用户数量并排序:按地址分组,使用count函数统计每个地址的用户数量,再按数量降序排序。
6. 获取前二十个地址:使用show函数展示地址用户数量最多的前二十个地址。
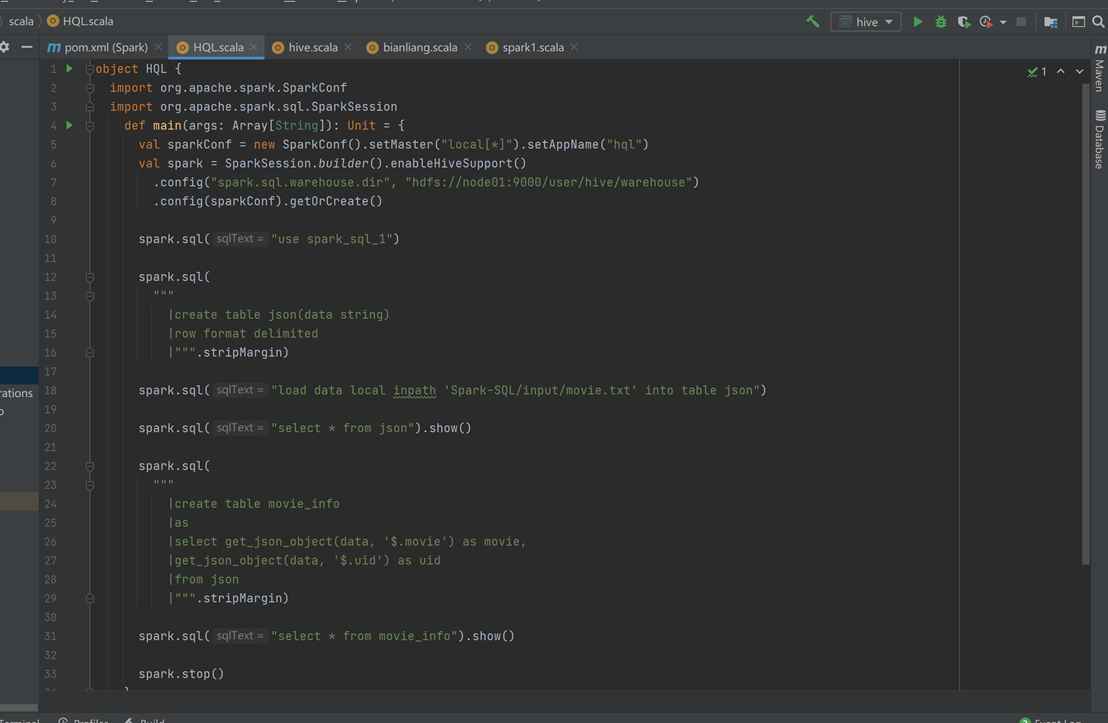
. 代码操作Hive:先导入spark-hive_2.12和hive-exec依赖,把hive-site.xml文件拷贝到项目resources目录,通过代码设置SparkSession并启用Hive支持。若报错,可设置HADOOP_USER_NAME解决;还可通过配置spark.sql.warehouse.dir指定数据库仓库地址。