深度学习之序列建模的核心技术:LSTM架构深度解析与优化策略
LSTM深度解析
一、引言
在深度学习领域,循环神经网络(RNN)在处理序列数据方面具有独特的优势,例如语音识别、自然语言处理等任务。然而,传统的 RNN 在处理长序列数据时面临着严重的梯度消失问题,这使得网络难以学习到长距离的依赖关系。LSTM 作为一种特殊的 RNN 架构应运而生,有效地解决了这一难题,成为了序列建模领域的重要工具。
二、LSTM 基本原理
(一)细胞状态
LSTM 的核心是细胞状态(Cell State),它类似于一条信息传送带,贯穿整个时间序列。细胞状态能够在序列的各个时间步中保持相对稳定的信息传递,从而使得网络能够记忆长距离的信息。在每个时间步,细胞状态会根据输入门、遗忘门和输出门的控制进行信息的更新与传递。
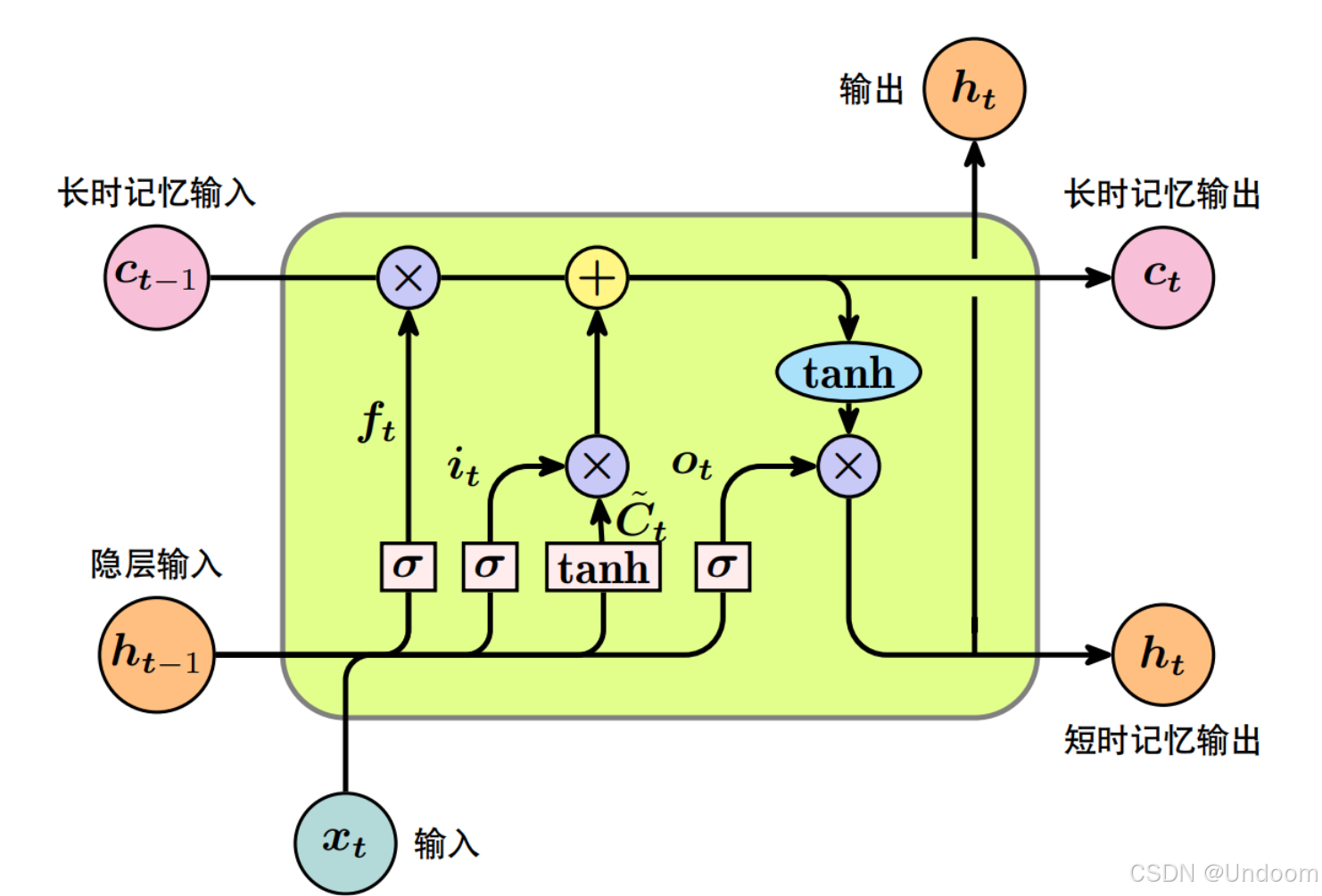
(二)门控机制
遗忘门(Forget Gate)
遗忘门的作用是决定细胞状态中哪些信息需要被保留,哪些信息需要被丢弃。它接收当前输入和上一时刻的隐藏状态作为输入,通过一个 Sigmoid 激活函数将其映射到 0 到 1 之间的值。其中,接近 0 的值表示对应的细胞状态信息将被遗忘,接近 1 的值表示信息将被保留。遗忘门的计算公式如下:

输入门(Input Gate)
输入门负责控制当前输入中有多少信息将被更新到细胞状态中。它同样接收和作为输入,通过 Sigmoid 函数计算出一个更新比例,同时通过一个 Tanh 激活函数对当前输入进行变换,然后将两者相乘得到需要更新到细胞状态中的信息。输入门的计算公式如下:

细胞状态更新
根据遗忘门和输入门的结果,对细胞状态进行更新。具体公式如下:

输出门(Output Gate)
输出门决定了细胞状态中的哪些信息将被输出作为当前时刻的隐藏状态。它接收和作为输入,通过 Sigmoid 函数计算出一个输出比例,然后将其与经过 Tanh 激活函数处理后的细胞状态相乘,得到当前时刻的隐藏状态。输出门的计算公式如下:

三、LSTM 的变体
在LSTM的基础上,研究人员开发了多种变体以解决特定问题或提高性能。以下介绍两种常见的LSTM变体。
(一)双向LSTM(Bidirectional LSTM)
双向LSTM(BiLSTM)通过同时从两个方向(正向和反向)处理序列数据,能够捕捉到更全面的上下文信息。在许多自然语言处理任务中,一个词的含义不仅依赖于它之前的词,也依赖于它之后的词。BiLSTM正是为了解决这一问题而设计的。
import tensorflow as tf# 构建双向LSTM模型
def build_bilstm_model(vocab_size, embedding_dim, lstm_units, output_dim):model = tf.keras.Sequential([tf.keras.layers.Embedding(vocab_size, embedding_dim, mask_zero=True),tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(lstm_units, return_sequences=False)),tf.keras.layers.Dense(output_dim, activation='softmax')])return model# 示例参数
vocab_size = 10000 # 词汇表大小
embedding_dim = 128 # 词嵌入维度
lstm_units = 64 # LSTM单元数量
output_dim = 3 # 输出类别数(如情感分析的积极、消极、中性)# 创建模型
bilstm_model = build_bilstm_model(vocab_size, embedding_dim, lstm_units, output_dim)
bilstm_model.summary()
BiLSTM的工作原理是将输入序列同时送入两个独立的LSTM层,一个按正常顺序处理序列(从左到右),另一个按相反顺序处理序列(从右到左)。然后,将两个LSTM层的输出合并(通常是连接或求和),得到一个能够捕捉双向上下文信息的表示。这种结构使得模型能够同时考虑过去和未来的信息,特别适合需要理解完整上下文的任务,如命名实体识别、词性标注等。
(二)门控循环单元(GRU)
门控循环单元(Gated Recurrent Unit,GRU)是LSTM的一种简化变体,由Cho等人在2014年提出。GRU合并了LSTM的遗忘门和输入门为一个更新门,并将细胞状态和隐藏状态合并,从而减少了参数数量,提高了计算效率。
import tensorflow as tf# 构建GRU模型
def build_gru_model(vocab_size, embedding_dim, gru_units, output_dim):model = tf.keras.Sequential([tf.keras.layers.Embedding(vocab_size, embedding_dim, mask_zero=True),tf.keras.layers.GRU(gru_units, return_sequences=False),tf.keras.layers.Dense(output_dim, activation='softmax')])return model# 示例参数
vocab_size = 10000 # 词汇表大小
embedding_dim = 128 # 词嵌入维度
gru_units = 64 # GRU单元数量
output_dim = 3 # 输出类别数# 创建模型
gru_model = build_gru_model(vocab_size, embedding_dim, gru_units, output_dim)
gru_model.summary()
GRU的主要组成部分:
- 更新门(Update Gate):决定保留多少过去的信息和添加多少新信息
- 重置门(Reset Gate):决定忽略多少过去的信息
GRU的计算公式如下:
z_t = σ(W_z·[h_{t-1}, x_t]) # 更新门
r_t = σ(W_r·[h_{t-1}, x_t]) # 重置门
h̃_t = tanh(W·[r_t * h_{t-1}, x_t]) # 候选隐藏状态
h_t = (1 - z_t) * h_{t-1} + z_t * h̃_t # 当前隐藏状态
与LSTM相比,GRU的优势在于参数更少,训练速度更快,在某些任务上性能相当甚至更好。然而,在处理非常长的序列或需要精细控制记忆机制的任务时,LSTM可能表现更佳。选择使用LSTM还是GRU,通常需要根据具体任务和数据特点进行实验比较。
四、LSTM 的应用领域
(一)自然语言处理
语言模型
LSTM 可以用于构建语言模型,预测下一个单词的概率分布。通过对大量文本数据的学习,LSTM 能够捕捉到单词之间的语义和语法关系,从而生成连贯、合理的文本。例如,在文本生成任务中,给定一个初始的文本片段,LSTM 可以根据学习到的语言模式继续生成后续的文本内容。
机器翻译
在机器翻译任务中,LSTM 可以对源语言句子进行编码,将其转换为一种中间表示形式,然后再解码为目标语言句子。通过对双语平行语料库的学习,LSTM 能够理解源语言和目标语言之间的对应关系,实现较为准确的翻译。
文本分类
对于文本分类任务,如情感分析(判断文本的情感倾向是积极、消极还是中性)、新闻分类(将新闻文章分类到不同的主题类别)等,LSTM 可以对文本序列进行建模,提取文本的特征表示,然后通过一个分类器(如全连接层和 Softmax 函数)对文本进行分类。
(二)时间序列预测
股票价格预测
股票价格受到众多因素的影响,并且具有时间序列的特性。LSTM 可以学习股票价格的历史数据中的模式和趋势,预测未来的股票价格走势。通过分析过去一段时间内的股票价格、成交量、宏观经济指标等数据,LSTM 能够尝试捕捉到股票市场的动态变化规律,为投资者提供决策参考。
气象预测
气象数据如气温、气压、风速等也是时间序列数据。LSTM 可以利用历史气象数据来预测未来的气象变化,例如预测未来几天的气温变化、降水概率等。通过对大量气象观测数据的学习,LSTM 能够挖掘出气象要素之间的复杂关系和时间演变规律,提高气象预测的准确性。
(三)语音识别
在语音识别系统中,LSTM 可以对语音信号的序列特征进行建模。语音信号首先被转换为一系列的特征向量(如梅尔频率倒谱系数 MFCC),然后 LSTM 对这些特征向量序列进行处理,识别出语音中的单词和句子。LSTM 能够处理语音信号中的长时依赖关系,例如语音中的韵律、连读等现象,从而提高语音识别的准确率。
四、LSTM 代码实现
(一)使用 Python 和 TensorFlow 构建 LSTM 模型
以下是一个简单的示例代码,展示了如何使用 TensorFlow 构建一个 LSTM 模型用于时间序列预测任务(以预测正弦波数据为例)。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt# 生成正弦波数据
def generate_sine_wave_data(num_samples, time_steps):x = []y = []for i in range(num_samples):# 生成一个随机的起始点start = np.random.rand() * 2 * np.pi# 生成时间序列数据series = [np.sin(start + i * 0.1) for i in range(time_steps)]# 目标值是下一个时间步的正弦值target = np.sin(start + time_steps * 0.1)x.append(series)y.append(target)return np.array(x), np.array(y)# 超参数
num_samples = 10000
time_steps = 50
input_dim = 1
output_dim = 1
num_units = 64
learning_rate = 0.001
num_epochs = 100# 生成数据
x_train, y_train = generate_sine_wave_data(num_samples, time_steps)# 数据预处理,将数据形状调整为适合 LSTM 输入的格式
x_train = np.reshape(x_train, (num_samples, time_steps, input_dim))
y_train = np.reshape(y_train, (num_samples, output_dim))# 构建 LSTM 模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.LSTM(num_units, input_shape=(time_steps, input_dim)))
model.add(tf.keras.layers.Dense(output_dim))# 定义损失函数和优化器
loss_fn = tf.keras.losses.MeanSquaredError()
optimizer = tf.keras.optimizers.Adam(learning_rate)# 编译模型
model.compile(loss=loss_fn, optimizer=optimizer)# 训练模型
history = model.fit(x_train, y_train, epochs=num_epochs, verbose=2)# 绘制训练损失曲线
plt.plot(history.history['loss'])
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()# 使用训练好的模型进行预测
x_test, y_test = generate_sine_wave_data(100, time_steps)
x_test = np.reshape(x_test, (100, time_steps, input_dim))
y_pred = model.predict(x_test)# 绘制预测结果与真实值对比图
plt.plot(y_test, label='True')
plt.plot(y_pred, label='Predicted')
plt.title('Prediction Results')
plt.xlabel('Sample')
plt.ylabel('Value')
plt.legend()
plt.show()
在上述代码中,首先定义了一个函数 generate_sine_wave_data 用于生成正弦波数据作为时间序列预测的示例数据。然后设置了一系列超参数,如样本数量、时间步长、输入维度、输出维度、LSTM 单元数量、学习率和训练轮数等。接着生成训练数据并进行预处理,将其形状调整为适合 LSTM 模型输入的格式((样本数量, 时间步长, 输入维度))。
构建 LSTM 模型时,使用 tf.keras.Sequential 模型,先添加一个 LSTM 层,指定单元数量和输入形状,然后添加一个全连接层用于输出预测结果。定义了均方误差损失函数和 Adam 优化器,并编译模型。使用 model.fit 方法对模型进行训练,并绘制训练损失曲线以观察训练过程。最后,生成测试数据,使用训练好的模型进行预测,并绘制预测结果与真实值的对比图,以评估模型的性能。
(二)使用 PyTorch 实现 LSTM 模型
除了TensorFlow,PyTorch也是实现LSTM模型的流行框架。以下是使用PyTorch实现相同时间序列预测任务的代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 生成正弦波数据(与TensorFlow示例相同)
def generate_sine_wave_data(num_samples, time_steps):x = []y = []for i in range(num_samples):start = np.random.rand() * 2 * np.piseries = [np.sin(start + i * 0.1) for i in range(time_steps)]target = np.sin(start + time_steps * 0.1)x.append(series)y.append(target)return np.array(x), np.array(y)# 定义LSTM模型类
class LSTMModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_layers=1):super(LSTMModel, self).__init__()self.hidden_dim = hidden_dimself.num_layers = num_layers# LSTM层self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)# 全连接输出层self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):# 初始化隐藏状态和细胞状态h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)# LSTM前向传播out, _ = self.lstm(x, (h0, c0))# 我们只需要最后一个时间步的输出out = self.fc(out[:, -1, :])return out# 超参数
num_samples = 10000
time_steps = 50
input_dim = 1
hidden_dim = 64
output_dim = 1
num_layers = 1
learning_rate = 0.001
num_epochs = 100
batch_size = 128# 生成数据
x_train, y_train = generate_sine_wave_data(num_samples, time_steps)# 转换为PyTorch张量
x_train = torch.FloatTensor(x_train.reshape(num_samples, time_steps, input_dim))
y_train = torch.FloatTensor(y_train.reshape(num_samples, output_dim))# 创建数据加载器
train_dataset = torch.utils.data.TensorDataset(x_train, y_train)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)# 初始化模型
model = LSTMModel(input_dim, hidden_dim, output_dim, num_layers)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 训练模型
loss_history = []
model.train()
for epoch in range(num_epochs):epoch_loss = 0for batch_x, batch_y in train_loader:# 前向传播outputs = model(batch_x)loss = criterion(outputs, batch_y)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()epoch_loss += loss.item()# 记录每个epoch的平均损失avg_loss = epoch_loss / len(train_loader)loss_history.append(avg_loss)if (epoch+1) % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')# 绘制训练损失曲线
plt.figure(figsize=(10, 6))
plt.plot(loss_history)
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.show()# 评估模型
model.eval()
with torch.no_grad():# 生成测试数据x_test, y_test = generate_sine_wave_data(100, time_steps)x_test = torch.FloatTensor(x_test.reshape(100, time_steps, input_dim))# 预测y_pred = model(x_test).numpy()# 绘制预测结果与真实值对比图plt.figure(figsize=(12, 6))plt.plot(y_test, label='True')plt.plot(y_pred, label='Predicted')plt.title('Prediction Results')plt.xlabel('Sample')plt.ylabel('Value')plt.legend()plt.grid(True)plt.show()
(三)PyTorch与TensorFlow实现的比较
PyTorch和TensorFlow是当前深度学习领域最流行的两个框架,它们在实现LSTM模型时有一些关键区别:
-
模型定义方式:
- PyTorch采用面向对象的方式,通过继承
nn.Module类来定义模型 - TensorFlow (Keras API)采用更为函数式的方法,通过Sequential或Functional API构建模型
- PyTorch采用面向对象的方式,通过继承
-
动态计算图与静态计算图:
- PyTorch使用动态计算图,可以在运行时改变网络结构
- TensorFlow 2.x虽然也支持动态图,但其设计理念仍偏向于静态图
-
隐藏状态初始化:
- 在PyTorch中,我们需要显式初始化LSTM的隐藏状态和细胞状态
- 在TensorFlow中,这些状态会自动初始化
-
批处理实现:
- PyTorch通常使用DataLoader进行批处理
- TensorFlow可以直接在fit函数中指定batch_size
-
调试便利性:
- PyTorch的动态图特性使得调试更加直观
- TensorFlow的Eager Execution模式也提供了类似的便利性
两个框架各有优势,选择哪一个通常取决于个人偏好、团队习惯或特定任务的需求。在学术研究中,PyTorch因其灵活性而更受欢迎;而在工业部署中,TensorFlow的生态系统更为完善。
(四)代码解读
TensorFlow实现解读
generate_sine_wave_data 函数通过循环生成多个正弦波序列数据。对于每个序列,随机选择一个起始点,然后根据正弦函数生成指定时间步长的序列数据,并将下一个时间步的正弦值作为目标值。这样生成的数据可以模拟时间序列预测任务中的数据模式,其中输入是一个时间序列,目标是该序列的下一个值。
tf.keras.Sequential 是 TensorFlow 中用于构建序列模型的类。model.add(tf.keras.layers.LSTM(num_units, input_shape=(time_steps, input_dim))) 这一行添加了一个 LSTM 层,num_units 定义了 LSTM 层中的单元数量,它决定了模型能够学习到的特征表示的复杂度。input_shape 则指定了输入数据的形状,即时间步长和输入维度。model.add(tf.keras.layers.Dense(output_dim)) 添加了一个全连接层,用于将 LSTM 层的输出转换为最终的预测结果,输出维度与目标数据的维度相同。
PyTorch实现解读
在PyTorch实现中,我们定义了一个继承自nn.Module的LSTMModel类。在__init__方法中,我们初始化了LSTM层和全连接层。LSTM层的参数包括输入维度、隐藏状态维度和层数,batch_first=True表示输入张量的形状为(batch_size, seq_len, input_dim)。
在forward方法中,我们首先初始化隐藏状态和细胞状态为零张量,然后将输入数据和初始状态传递给LSTM层。LSTM层返回所有时间步的输出和最终状态,我们只取最后一个时间步的输出,并将其传递给全连接层得到最终预测结果。
训练过程中,我们使用DataLoader进行批处理,在每个epoch中遍历所有批次,执行前向传播、计算损失、反向传播和参数更新。这种实现方式更加灵活,允许我们在训练过程中更精细地控制模型行为。
五、LSTM 实际应用案例:情感分析
情感分析是自然语言处理中的一个重要任务,旨在识别和提取文本中表达的情感态度。LSTM因其能够捕捉序列中的长距离依赖关系,特别适合处理这类任务。以下是一个使用LSTM进行电影评论情感分析的完整实现案例。
(一)使用LSTM进行电影评论情感分析
我们将使用IMDB电影评论数据集,这是一个二分类任务,目标是判断评论是正面的还是负面的。
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns# 设置随机种子以确保结果可复现
np.random.seed(42)
tf.random.set_seed(42)# 加载IMDB数据集,只保留最常见的10000个词
max_features = 10000
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)# 打印数据集信息
print(f"训练集样本数: {len(x_train)}")
print(f"测试集样本数: {len(x_test)}")
print(f"样本标签示例: {y_train[:10]}") # 0表示负面评论,1表示正面评论# 查看一个评论示例
print(f"一条评论的词索引: {x_train[0][:20]}...")
print(f"这条评论的长度: {len(x_train[0])}")# 统计评论长度分布
review_lengths = [len(x) for x in x_train]
plt.figure(figsize=(10, 6))
plt.hist(review_lengths, bins=50)
plt.title('评论长度分布')
plt.xlabel('长度')
plt.ylabel('频率')
plt.show()# 设置最大序列长度并进行填充
maxlen = 200 # 截断或填充到200个词
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)print(f"填充后的训练数据形状: {x_train.shape}")
print(f"填充后的测试数据形状: {x_test.shape}")# 构建LSTM模型
embedding_dim = 128model = Sequential()
model.add(Embedding(max_features, embedding_dim, input_length=maxlen))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2, return_sequences=True))
model.add(LSTM(64, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])model.summary()# 设置早停和模型检查点回调
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
model_checkpoint = ModelCheckpoint('best_imdb_model.h5', save_best_only=True, monitor='val_accuracy')# 训练模型
batch_size = 64
epochs = 10history = model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs,validation_split=0.2,callbacks=[early_stopping, model_checkpoint])# 评估模型
score = model.evaluate(x_test, y_test, verbose=1)
print(f"测试集损失: {score[0]:.4f}")
print(f"测试集准确率: {score[1]:.4f}")# 绘制训练历史
plt.figure(figsize=(12, 5))# 绘制准确率
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('模型准确率')
plt.ylabel('准确率')
plt.xlabel('Epoch')
plt.legend(['训练集', '验证集'], loc='lower right')# 绘制损失
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('模型损失')
plt.ylabel('损失')
plt.xlabel('Epoch')
plt.legend(['训练集', '验证集'], loc='upper right')plt.tight_layout()
plt.show()# 进行预测并分析结果
y_pred = (model.predict(x_test) > 0.5).astype("int32")# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['负面', '正面'], yticklabels=['负面', '正面'])
plt.title('混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()# 分类报告
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=['负面', '正面']))# 预测函数:将原始文本转换为模型可接受的输入
def predict_sentiment(text, word_index, model, maxlen=200):# 将文本转换为单词列表words = text.lower().split()# 将单词转换为索引sequence = [word_index.get(word, 0) for word in words]# 填充序列padded_sequence = sequence_pad_sequences([sequence], maxlen=maxlen)# 预测score = model.predict(padded_sequence)[0][0]return {"score": float(score), "sentiment": "正面" if score > 0.5 else "负面"}# 示例预测
# 注意:实际使用时需要获取word_index
# word_index = imdb.get_word_index()
# 示例:predict_sentiment("This movie was fantastic! I really enjoyed it.", word_index, model)
(二)代码解析与关键点
数据预处理
-
词汇表大小限制:我们只保留最常见的10,000个词,这有助于减少模型复杂度并防止过拟合。
-
序列长度标准化:通过统计评论长度分布,我们选择了200作为最大序列长度。对于较短的评论,我们用0进行填充;对于较长的评论,我们进行截断。这确保了输入数据的一致性。
模型架构
-
嵌入层:将词索引转换为密集向量表示,维度为128。这一层学习词的语义表示。
-
堆叠LSTM层:我们使用了两层LSTM,第一层返回完整序列,第二层只返回最终输出。这种堆叠结构能够学习更复杂的特征表示。
-
Dropout正则化:在LSTM层中使用了两种dropout:
- 常规dropout (0.2):随机丢弃LSTM输出中的一部分单元
- 循环dropout (0.2):在时间步之间保持一致的dropout模式
-
全连接层:添加了一个带ReLU激活的全连接层,进一步提取特征。
-
输出层:使用sigmoid激活函数的单个神经元,输出介于0和1之间的概率值,表示评论为正面的概率。
训练策略
-
早停机制:当验证损失连续3个epoch没有改善时停止训练,防止过拟合。
-
模型检查点:保存在验证准确率上表现最佳的模型。
-
验证集划分:从训练数据中划分20%作为验证集,用于监控训练过程。
结果分析
-
混淆矩阵:直观显示模型在正面和负面评论上的表现,帮助识别模型的偏差。
-
分类报告:提供精确率、召回率和F1分数等详细指标,全面评估模型性能。
(三)可视化LSTM内部状态
理解LSTM内部状态的变化对于深入理解其工作机制非常有帮助。以下代码展示了如何可视化LSTM处理序列时的内部状态变化:
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense# 创建一个简单的LSTM模型,返回序列中每个时间步的状态
def create_lstm_visualization_model(input_dim, hidden_dim):inputs = Input(shape=(None, input_dim))lstm_layer = LSTM(hidden_dim, return_sequences=True, return_state=True)lstm_output, final_memory_state, final_carry_state = lstm_layer(inputs)# 创建一个返回所有时间步输出和状态的模型model = Model(inputs=inputs, outputs=[lstm_output, final_memory_state, final_carry_state])return model, lstm_layer# 生成一个简单的序列数据
def generate_simple_sequence(length=20, input_dim=1):# 生成一个正弦波序列x = np.linspace(0, 4*np.pi, length)sequence = np.sin(x).reshape(1, length, input_dim)return sequence# 创建模型
input_dim = 1
hidden_dim = 4
model, lstm_layer = create_lstm_visualization_model(input_dim, hidden_dim)# 生成序列数据
sequence = generate_simple_sequence(length=50, input_dim=input_dim)# 获取LSTM层的权重
lstm_weights = lstm_layer.get_weights()# 创建一个函数来计算每个时间步的内部状态
def compute_lstm_states(model, sequence):# 初始化状态列表h_states = []c_states = []# 初始状态为零h_t = np.zeros((1, hidden_dim))c_t = np.zeros((1, hidden_dim))# 对序列中的每个时间步for t in range(sequence.shape[1]):# 获取当前输入x_t = sequence[:, t:t+1, :]# 使用模型预测_, h_t, c_t = model.predict(x_t, initial_state=[h_t, c_t])# 存储状态h_states.append(h_t[0])c_states.append(c_t[0])return np.array(h_states), np.array(c_states)# 计算内部状态
h_states, c_states = compute_lstm_states(model, sequence)# 可视化内部状态
plt.figure(figsize=(15, 10))# 绘制输入序列
plt.subplot(3, 1, 1)
plt.plot(sequence[0, :, 0])
plt.title('输入序列')
plt.xlabel('时间步')
plt.ylabel('值')# 绘制隐藏状态
plt.subplot(3, 1, 2)
for i in range(hidden_dim):plt.plot(h_states[:, i], label=f'隐藏状态 {i+1}')
plt.title('LSTM隐藏状态')
plt.xlabel('时间步')
plt.ylabel('状态值')
plt.legend()# 绘制细胞状态
plt.subplot(3, 1, 3)
for i in range(hidden_dim):plt.plot(c_states[:, i], label=f'细胞状态 {i+1}')
plt.title('LSTM细胞状态')
plt.xlabel('时间步')
plt.ylabel('状态值')
plt.legend()plt.tight_layout()
plt.show()
这段代码创建了一个简单的LSTM模型,并使用正弦波序列作为输入,计算并可视化了LSTM在处理序列时的隐藏状态和细胞状态的变化。通过观察这些状态的变化,我们可以更好地理解LSTM如何捕捉序列中的模式和长期依赖关系。
六、LSTM 的优势与局限性
(一)优势
长距离依赖学习能力
如前文所述,LSTM 能够有效地解决传统 RNN 中的梯度消失问题,从而可以学习到序列数据中长距离的依赖关系。这使得它在处理诸如长文本、长时间序列等数据时表现出色,能够捕捉到数据中深层次的语义、趋势和模式。
灵活性与适应性
LSTM 可以应用于多种不同类型的序列数据处理任务,无论是自然语言、时间序列还是语音信号等。它的门控机制使得模型能够根据不同的数据特点和任务需求,灵活地调整细胞状态中的信息保留与更新,具有较强的适应性。
(二)局限性
计算复杂度较高
由于 LSTM 的细胞结构和门控机制相对复杂,相比于简单的神经网络模型,其计算复杂度较高。在处理大规模数据或构建深度 LSTM 网络时,训练时间和计算资源的需求可能会成为瓶颈,需要强大的计算硬件支持。
可能存在过拟合
在数据量较小或模型参数过多的情况下,LSTM 模型也可能出现过拟合现象,即模型过于适应训练数据,而对新的数据泛化能力较差。需要采用一些正则化技术,如 L1/L2 正则化、Dropout 等,来缓解过拟合问题。
(三)LSTM调参技巧与最佳实践
在实际应用中,LSTM模型的性能很大程度上取决于超参数的选择和训练策略。以下是一些调参技巧和最佳实践:
1. 网络架构选择
- LSTM单元数量:通常从较小的值开始(如32、64、128),然后根据验证性能逐步增加。单元数量越多,模型容量越大,但也更容易过拟合。
- LSTM层数:对于简单任务,1-2层通常足够;对于复杂任务,可以尝试3-4层。堆叠多层LSTM可以学习更抽象的特征表示。
- 双向vs单向:如果任务需要考虑序列的双向上下文(如命名实体识别),选择双向LSTM;如果是预测任务(如时间序列预测),单向LSTM可能更合适。
2. 正则化策略
# 正则化示例
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(128, dropout=0.2, # 应用于输入的dropoutrecurrent_dropout=0.2, # 应用于循环连接的dropoutkernel_regularizer=tf.keras.regularizers.l2(0.001), # L2正则化return_sequences=True))
model.add(LSTM(64))
model.add(Dense(1, activation='sigmoid'))
- Dropout:在LSTM层中使用dropout可以有效防止过拟合。通常设置在0.2-0.5之间。
- 循环Dropout:特别针对LSTM的循环连接应用dropout,保持时间步之间的一致性。
- L1/L2正则化:对LSTM的权重矩阵应用正则化,限制权重的大小。
- 提前停止:当验证损失不再改善时停止训练,是一种简单有效的正则化方法。
3. 学习率调整
# 学习率调度示例
initial_learning_rate = 0.001
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate,decay_steps=10000,decay_rate=0.9,staircase=True)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
- 初始学习率:通常从较小的值开始(如0.001),这是Adam优化器的默认值。
- 学习率调度:随着训练的进行逐步降低学习率,可以帮助模型收敛到更好的局部最小值。
- 学习率预热:在训练初期使用较小的学习率,然后逐步增加到目标值,有助于稳定训练。
4. 序列处理技巧
- 序列长度:分析数据中序列的长度分布,选择合适的最大长度进行填充或截断。
- 批量大小:对于长序列,可能需要减小批量大小以适应内存限制。
- 梯度裁剪:限制梯度的范数,防止梯度爆炸问题。
# 梯度裁剪示例
optimizer = tf.keras.optimizers.Adam(clipnorm=1.0) # 限制梯度L2范数不超过1.0
5. 初始化策略
- 权重初始化:LSTM对权重初始化敏感,通常使用Glorot均匀初始化(默认)或He初始化。
- 预训练嵌入:在NLP任务中,使用预训练的词嵌入(如Word2Vec、GloVe)可以显著提高性能。
# 使用预训练嵌入示例
embedding_matrix = ... # 加载预训练嵌入
model.add(Embedding(vocab_size, embedding_dim, weights=[embedding_matrix],trainable=False)) # 是否在训练中更新嵌入
6. 训练策略
- 批量归一化:虽然在LSTM中不如在CNN中常用,但在某些情况下可以尝试在LSTM层之间添加批量归一化层。
- 残差连接:对于深层LSTM网络,添加残差连接可以缓解梯度消失问题。
- 注意力机制:结合注意力机制可以帮助模型关注序列中的重要部分。
通过系统地调整这些超参数和应用这些最佳实践,可以显著提高LSTM模型的性能和泛化能力。实践中,建议使用网格搜索或贝叶斯优化等方法进行超参数调优。