9.PostgreSQL初体验
一.PostgreSQL
1.简介
PostgreSqL,作为一个功能强大且开源的对象关系型数据库管理系统(ORDBMS),自其诞生以来,便以其卓越的性能和丰富的特性赢得了全球开发者和企业的青睐。源自加利福尼亚大学伯克利分校的 PostgreSqL,不仅继承了其前身 Ingres 的精髓,更在不断的发展中推陈出新,成为了现代数据库领域的佼佼者。
2.特点
开源与自由:PostgreSQL完全开源,遵循PostgreSQL许可证,这一特性使得用户可以自由地使用、修改和分发 PostgreSqL,无需担心版权问题,同时也促进了全球开发者的积极参与和贡献。
标准符合性:PostgreSQL高度符合 SQL标准,支持复杂的查询语法、子查询、窗口函数、公共表表达式(CTE)等高级特性,使得开发者可以更加灵活地编写高效、易读的 SQL 代码。
数据类型丰富:PostgreSqL 提供了丰富的数据类型,包括基本类型(如整数、浮点数、字符串等)、日期和时间类型、数组、枚举、范围类型、JSON、地理空间类型等,这些类型极大地扩展了 PostgreSQL的应用范围,使其能够处理各种复杂的数据场景。
事务与并发:PostgreSQL采用多版本并发控制(MVCC)机制,确保了在高并发环境下的数据一致性和隔离性。同时,PostgreSqL还支持复杂的事务处理,包括嵌套事务、保存点等,为开发者提供了强大的事务管理能力。
扩展性:PostgreSQ支持扩展和插件机制,允许用户根据需要定义新的数据类型、函数、操作符、索引方法等。这一特性使得 PostgreSqL 能够不断适应新的业务需求和技术发展。
安全性:PostgreSQL提供了细粒度的访问控制、加密传输、审计日志等安全特性,确保了数据库的安全性和数据的保密性。
3.优势
高性能:PostgreSQL通过优化查询计划、支持并行查询、分区表等特性,提供了卓越的性能表现。即使在处理大规模数据和高并发访问时,也能保持高效的响应速度。
高可用性:PostgreSQ 支持主从复制、流复制和逻辑复制等多种复制方式,使得数据库系统能够轻松实现高可用性和容灾备份。在发生故障时,能够快速恢复服务,确保业务的连续性。
灵活性::PostgreSQL的丰富数据类型和高级特性使得它能够灵活应对各种复杂的业务场景。无论是处理结构化数据还是非结构化数据,PostgreSqL都能提供强大的支持。
社区支持:PostgreSQL拥有一个活跃的开发者社区和丰富的生态系统。社区中不仅有大量的教程、文档和插件可供使用,还有众多经验丰富的开发者愿意分享经验和解答问题。
成本效益:作为开源软件,PostgreSQL降低了企业的成本投入。同时,其卓越的性能和广泛的应用场景也使得 PostgreSQ 成为了许多企业的首选数据库产啪。
4.架构
PostgreSqL 的架构设计体现了其高性能和可扩展性的特点。在逻辑层面上PostgreSqL 包含了数据库集群、表空间、数据库、Schema、表、索引等结构;在物理层面上,则包括数据文件、日志文件、参数文件、控制文件等物理存储方式。其中,数据块(Page)作为数据读写的基本单位,在PostgreSQL中扮演着至关重要的角色。通过优化数据块的读写效率和布局方式,PostgreSqL能够进-步提高其性能表现。
5.应用场景
包括但不限于以下方面:
业务应用:如ERP、CRM、HRM等系统,需要处理复杂的事务和查询操作。PostgreSq 凭借其高性能和事务处理能力,能够为企业应用提供稳定可靠的数据支持。
数据分析:在数据仓库和商业智能领域,PostgreSQL凭借其丰富的数据类型和高级查询特性,能够轻松应对大规模数据分析和挖掘任务。
Web应用:对于需要高并发访问和实时数据处理的 Web 应用来说,PostgreSQL的 MVCC 机制和扩展性特性使得其成为了一个理想的选择。
地理信息系统(GIS):通过PostGIS扩展,PostgreSqL能够支持地理空间数据的存储和分析功能,为 GIS 应用提供了强大的数据支持。
物联网与大数据:随着物联网和大数据技术的不断发展,PostgreSqL凭借其高性能、可扩展性和丰富的数据类型特性,在物联网和大数据领域中也得到了广泛的应用。
6.结论
综上所述,PostgreSqL 作为一款功能强大、开源的数据库管理系统,在现代信息化建设中发挥着越来越重要的作用。其丰富的特性、卓越的性能、灵活的应用场景以及强大的社区支持使得 PostgreSql 成为了众多企业和开发者的首选数据库产品。
二.安装PostgreSQL
1.编译安装(以下是以OpenEuler24版本的操作系统为基础安装16.3版本的postgerSQL)
(1)安装编译安装所需环境
yum -y install gcc gcc-* make libicu libicu-devel readline-devel zlib zlib-devel
(2)编译安装
解压源码包:tar zxvf postgresql-16.3.tar.gz
切换目录:cd postgresql-16.3
--prefix指定安装目录:./configure --prefix=/usr/local/pgsql
编译以及安装:make && make install
配置环境
创建用户:useradd postgres
创建数据存储目录:mkdir /usr/local/pgsql/data
更改数据存储目录的归属用户:chown postgres /usr/local/pgsql/data
(3)配置环境变量
vim /etc/profile
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
source /etc/profile
(4)登录数据库
注意:不要使用root用户登录,切换到postgres这个用户
su - postgres
initdb -D /usr/local/pgsql/data
/usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l logfile start
psql
2.Dnf安装
(1)安装PostgreSQL
dnf install -y postgresql-server
(2)初始化数据库
postgresql -setup --initdb
(3)登录数据库
su - postgres
psql
三.PostgreSQL结构
1.PG的逻辑结构
PG 采用了多层逻辑结构:第一层为实例,第二层为数据库(每个实例下可有多个相互独立的数据库),第三层为 Schema(每个数据库下包含多个 Schema)。每个 Schema 下可以创建表、视图、索引、函数等数据库对象。
Database cluster(数据库集簇):由postgresql server 管理的数据库的集合,下面由多个 database 组成。一个数据库集簇可以包含多个 Database、多个User,每个 Database 以及 Database 中的所有对象都有它们的所有者:User。
Database 数据库: Postgres 默认数据库、Template0 最精简模板、Template1默认模板;数据库本身也是数据库对象,并且在逻辑上彼此分离。存储 schema 的一个逻辑空间,对应在物理层面上也是一个日录。
Schema:一个数据库可以有多个 User 用户,多个 Schema 模式,默认创建一个数据库会存储在默认表空间,它包含一个 Public 名称的 Schema 模式(拷贝自Template1模板)。它可隔离多个用户之间相同名称的对象。一个数据库可以有多个 Schema 模式,他们互不相关互相隔离。实际存储数据库对象的逻辑空间->逻辑上的对象编号,schema 是依附于数据库而存在的。
User 用户:postgres用户是默认创建的超级管理员:每个数据库都有一个OWNER 用户,每个用户可以 OWNER多个数据库。
数据库对象:这里包含了 table,index,view,序列,函数等,数据最终存储在表中。表的组成表由多个page[ block]组成)一个page 包含(页头信息空闲空间 Tuple),实际存储数据的区域->对应到物理层面上就是文件 -->page构成
tablespace:存储数据库的一个逻辑空间,可以存放不同的数据库:-->对应在物理层面上是一个目录
OID:所有数据库对象都有各自的 oid(object identifiers),oid 是一个无符号的四字节整数,相关对象的 oid 都存放在相关的 system catalog 表中,比如数据库的 oid 和表的 oid 分别存放在 pg_database, pg class 表中。
总结:
(1)从大小排列 database cluster-->databases-->schema-->objects
(2)Tablespace 是数据最大的存储空间, Database 是构成表空间的存储单元pages 是 PostgreSQl 数据库中最小的 10 单元
2.PG的物理结构
数据库的文件默认保存在 initdb 时创建的数据目录中。在数据目录中有很多类型、功能不同的目录和文件,除了数据文件之外,还有参数文件、控制文件、数据库运行日志及预写日志等。本质上都是PG 的相关一些文件
(1)软件安装目录
PostgreSQ 数据库的软件目录通常是在/usr 目录下(也可自定义位置),使用 pg_confg 命令可以看到当前数据库的基本情况,也可以在环境变量中可以看到。最直接可以使用 which 命令看到
安装目录里的基本内容如下
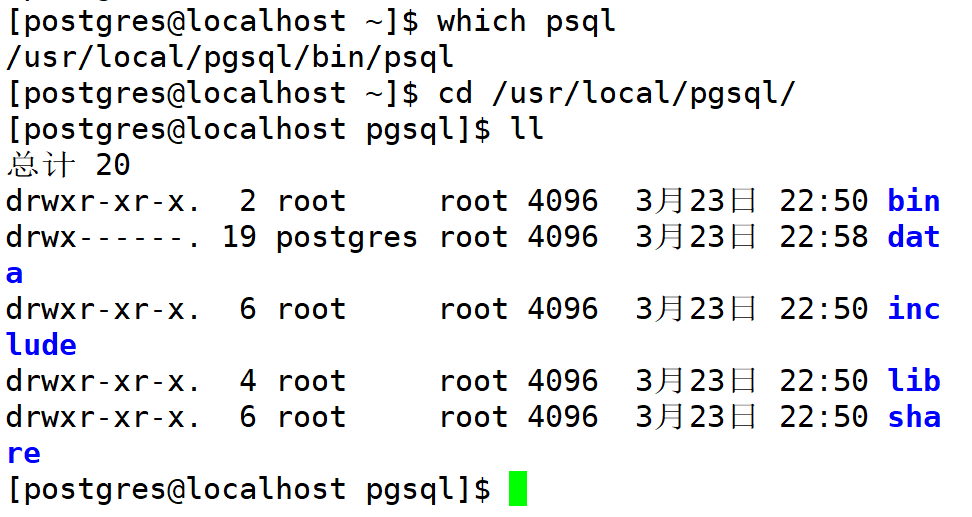
其中各个目录里的内容及用途:
bin:二进制可执行文件,是PG数据库的所有命令所在,为方便使用需设置到环境变量中
lib:动态库目录,PostgreSQL运行所需要的动态库都在此目录下
share:放在文档和配置模板文件,以下拓展插件的SQL文件在此目录下的extension中
data:目录是数据库集群的物理存储核心,包含用户数据、元数据和配置文件
include:目录则提供编译扩展和客户端程序所需的C语言头文件
(2)数据库目录结构
/usr/local/pgsql/data/ --数据目录
base --表和索引文件存放目录
global --影响全局的系统表存放目录
pg_commit_ts --事务提交时间戳数据存放目录
pg_dynshmem --被动态共享所使用的文件存放目录
pg_logical --用于逻辑复制的状态数据
pg_multixact --多事务状态的数据
pg_notify --LISTEN/NOTIFY状态的数据
pg_ replslot --复制槽数据存放目录
pg_serial --已提交的可序列化信息存放目录
pg_snapshots --快照
pg_stat --统计信息
pg_stat_ tmp --统计信息子系统临时文件
pg_subtrans --子事务状态数据
pg_tblspc --表空间
pg_twophase --预备事务状态文件
pg_wal --事务日志(预写日志)
pg xact --日志提交状态的数据存放目录
(3)数据库有两个基础的对象,一个是oid,一个是表空间
OID是数据库对象的唯一标识符
表空间实际上是文件系统中的一个位置链接,即一个目录,它是一个逻辑上的概念,目录是它的物理存在方式。数据库中创建的对象(表、索引、数据库对象)都保存在表空间中。postgresq1初始化完成后,会有两个默认的表空间,一个是 pg_default,如果用户建表时没有指定表空间,所有新建的表都会放在pg_default 中,另一个是 pg_global,存放的是整个实例数据库所共享的系统表。
(4)base的物理布局涉设计
每个数据库都会在$PGDATA/base 下面生成一个子目录,如下图,都会一一对应。
ls /usr/local/pgsql/data/base/
1 4 5
postgres=# select datname,oid from pg database;
(5)表空间跟数据库关系
在Ora数据库中:一个表空间只属于一个数据库使用;而一个数据库可以拥有多个表空间。属于“一对多”的关系
在PostgreSQL集群中:一个表空间可以让多个数据库使用;而一个数据库可以使用多个表空间。属于“多对多”的关系
系统自带表空间:
表空间pg_default是用来存储目录对象、用户表、用户表index、和临时表、临时表index、内部临时表的默认空间。对应存储目标$PADATA/base/
表空间pg_global用来存放系统字典表:对应存储目标$PADATA/global/