定时任务延迟任务
二者的区别:
定时任务:有固定周期的,有明确的触发时间。
延迟任务:没有固定的开始时间,它常常是由一个事件触发的,而在这个事件触发之后的一段时间内触发另一个事件,任务可以立即执行,也可以延迟。
二者的应用场景:
定时任务
Timmer
java自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务。使用这种方式可以让你的程序按照某一个频度执行,但不能在指定时间运行。一般用的较少。
ScheduledExecustorService
jdk自带的一个类;是基于线程池设计的定时任务类,每个调度任务都会分配到线程池中的一个线程去执行,也就是说,任务是并发执行,互不影响。
Spring Task(不支持分布式)
Spring3.0以后自带的task,可以将它看成一个轻量级的Quartz,而且使用起来比Quartz简单许多。
因为自带了,所以只要使用spring,不需要导入依赖直接就能使用。
基本用法
使用示例如下:
- 在启动类中标注
@EnableScheduling注解开启Spring Task功能。
@SpringBootApplication
@EnableScheduling // 开启功能
public class TaskApplication { public static void main(String[] args) {SpringApplication.run(TaskApplication.class, args); }
}
- 在方法上使用
@Scheduled注解来定义一个任务。
@Component // 既然用spring框架自带的东西了,那肯定得注册为bean,要不spring怎么调用
public class ScheduledBean { @Scheduled(cron = "0/5 * * * * ?") // cron表达式用于指定执行时间规则public void printLog(){ System.out.println(Thread.currentThread().getName()+":run..."); }
}
注意事项
作为spring提供的功能,自然需要开启该功能。并且该定时任务还需要被spring所管理。这也就是为什么使用@EnableScheduling注解,还有为什么需要在类上添加@Component注解,在定时方法上加@Scheduled注解。
配置定时规则,我们一般可以直接使用定时规则生成器,网络上有很多在线工具可以提供这个功能:
Cron - 在线Cron表达式生成器
在线Cron表达式生成器 - 码工具
Cron表达式(Crontab/Cron/quartz)在线生成
相关的配置
spring还为spring task提供了自定义配置的选项,如下:
spring: task: scheduling: # 任务调度线程池大小,因为要开线程异步,最多能开几个线程?,默认 1 pool: size: 1 # 调度线程名称前缀 默认 scheduling-,程序线程一多,不好找,加了它可读性高 thread-name-prefix: ssm_ shutdown: # 线程池关闭时,是否等待所有任务完成 await-termination: false # 调度线程关闭前最大等待时间,确保最后一定关闭(如果等待,最多等几秒) await-termination-period: 10s
线程下的阻塞问题
如果存在 定时任务数量 > 执行线程数量 的时候就会引发线程阻塞问题。这是因为线程数量不够执行已经到期的定时任务,这些任务会阻塞在线程中,一旦线程空闲则会立即执行,表现就是本来因该间隔执行的任务,一次性执行了n次,也就是破坏了定时的时效性而且也破坏了间隔周期。
对于解决这个问题有多种解决方式:
- 修改配置,多开几个线程,避免任务执行不过来阻塞在线程中:
- 修改配置文件
- 自定义配置类
- 开启异步调用,避免阻塞,在启动类上加
@EnableAsyn开启异步方法执行,在定时方法上加@Async让定时任务异步执行。
分布式环境解决问题
分布式环境下的话,如果不进行协调,每个环境下可能会去重复执行相同的定时任务,我们可以通过添加分布式锁等方式解决这个问题。
Quartz
一个功能比较强大的调度器,可以让你的程序在指定时间执行,也可以按照某一个频率执行,配置稍显复杂,不支持分片,没有界面。
XXL-JOB
XXL-JOB是一个分布式任务调度平台,以快速开发、简单易用、轻量级和易于扩展为核心设计目标。通过将调度行为抽象为调度中心平台,XXL-JOB实现了调度与任务的相互解耦,提高了整个系统的稳定性和可扩展性。XXL-JOB的核心组件包括调度中心平台和执行器。
源码地址:https:/gitee.com/xuxueli0323/xxl-job
文档地址:https:/www.xuxueli.com/xxl-job/
环境搭建(windows)
XXL-job环境要求:Maven3+、JDK8+、MySQL5.7+,这是因为它依赖这三项实现。
github下载地址:https://github.com/xuxueli/xxl-job
gitee下载地址:http://gitee.com/xuxueli0323/xxl-job
环境搭建步骤如下:
- 确认xxl-job所依赖的环境都ok。
- 去gitee或者github上克隆xxl-job的项目(可以选择最新版本)。
- 直接使用idea打开xxl-job的项目(xxl-job也是使用java开发的,可以直接打开)。打开之后先设置项目maven。下面是包结构的说明:

- 执行“数据库初始化脚本”,该操作会向数据库中创建8张表。
- 在调度中心(xxl-job-admin)的配置文件中编写MySQL的配置信息,调度中心依赖刚刚创建的8张表。
spring:datasource:url: jdbc:mysql://127.0.0.1:3306/xxl_job?ususername: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driver
- 启动xxl-job,访问
/xxl-job-admin登录默认账号admin/123456。即可看到管理界面
环境搭建(docker)
在开发环境中我们一般还是使用docker来安装xxl-job,具体步骤如下:
网上一搜一大堆…
快速入门
- 在执行定时任务的项目中导入依赖:
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>2.3.0</version>
</dependency>
- 编写yaml配置文件:
server:port: 8881
xxl:job:admin:addresses: http://192.168.200.130:8888/xxl-job-admin #调度中心地址# 指定执行器executor:appname: xxl-job-sharding-sample #这里填写的是xxl-job调度中心默认存在的一个执行器port: 9999
- 编写配置类:
@Bean
public XxlJobSpringExecutor xxlJobExecutor(){XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();// 属性值使用@value注解从配置文件中读取xxlJobSpringExecutor.setAdminAddress(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor;.setPort(port);return xxlJobSpringExecutor;
}
- 创建任务:
@Component
public class HelloJob{@XxlJob("demoJobHandler")public void demoJobHandler() throws Exception{sout("定时任务案例执行了");}
}
- 在xxl-job的网页控制台中”任务管理“下的“新建任务”:
绑定执行器为“示例执行器”(默认xxl-job初始化后提供的执行器),调度类型为CRON,填写执行规则Corn,运行模式为BEAN,JobHandler的值与@XxlJob中的属性值对应。
- 重启项目之后,在xxl-job的控制台中启动该任务就能看到定时任务执行效果。
xxl-job概念理解
执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器,实现任务自动发现功能。
执行器的存在另一方面也方便了定时任务的分组。
在创建定时任务的时候,每个任务必须绑定一个执行器。
调度类型:CORN(也就是corn表达式)、固定频率(单位秒,也就每n秒去执行一次)
运行模式:BEAN(在spring中使用时候的运行模式)
JobHandler:指定是哪个任务,也就是 @XxlJob的属性值。
高级配置:集群环境下的配置属性(也就是一个项目启动了不止一个示例的时候就会起作用)
延迟任务
延迟任务一般基于队列实现,下面对比三种不同的技术实现。
DelayQueue(JDK自带)
JDK自带DelayQueue是一个支持延时获取元素的阻塞队列,内部采用优先队列PriorityQueue存储元素,同时元素必须实现Delayed接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素。
优点:JDK自带,不需要别的依赖。
缺点:使用DelayQueue作为延迟任务,消息存在内容中,并不自带持久化机制,容易消息丢失。
RabbitMQ(常用)
RabbitMQ实现延迟任务可以通过RabbitMQ的TTL和死信队列来实现。
TTL:Time To Live(消息存活时间)
死信队列:Dead Letter Exchange(死信交换机),当消息成为Dead message,后,可以重新发送另一个交换机(死信交换机)
主要原理就是消息通过TTL定义了存活时间,当消息过期后会通过死信交换机发送到死信队列中,从而达到延迟消息的目的,再通过延迟消息去触发任务,从而实现延迟任务。
Redis(常用)
Redis实现延迟任务主要依靠于zset数据类型有序和去重的这两个特性实现的。
例如:创建zset使用时间戳的毫秒值作为score进行排序,消费者端进行监听,如果当前时间的毫秒值匹配到了延迟队列中的毫秒值就立即消费。
具体实现:
- 添加需要执行的任务(立即执行 或者 延迟执行)到数据库中。(这里不直接加到队列中是为了预防队列的处理速度满,队列消费速度比不上存入速度导致溢出。同时还能实现持久化,保证任务不会丢失)
- 存入数据库的同时判断任务是否到期,如果到期则存放到
list类型的reids数据中(该list中的任务会按照先后顺序被立即执行)。 - 从数据库中定时同步任务到
zset类型的redis数据中(这里仅仅同步预设时间范围内的任务,超出预设时间的任务短期内不会被执行,所以没有必要放入队列中占用内存)。 - 定时从
zset中刷新到期任务写入到list中去。
具体实现示意图如下:
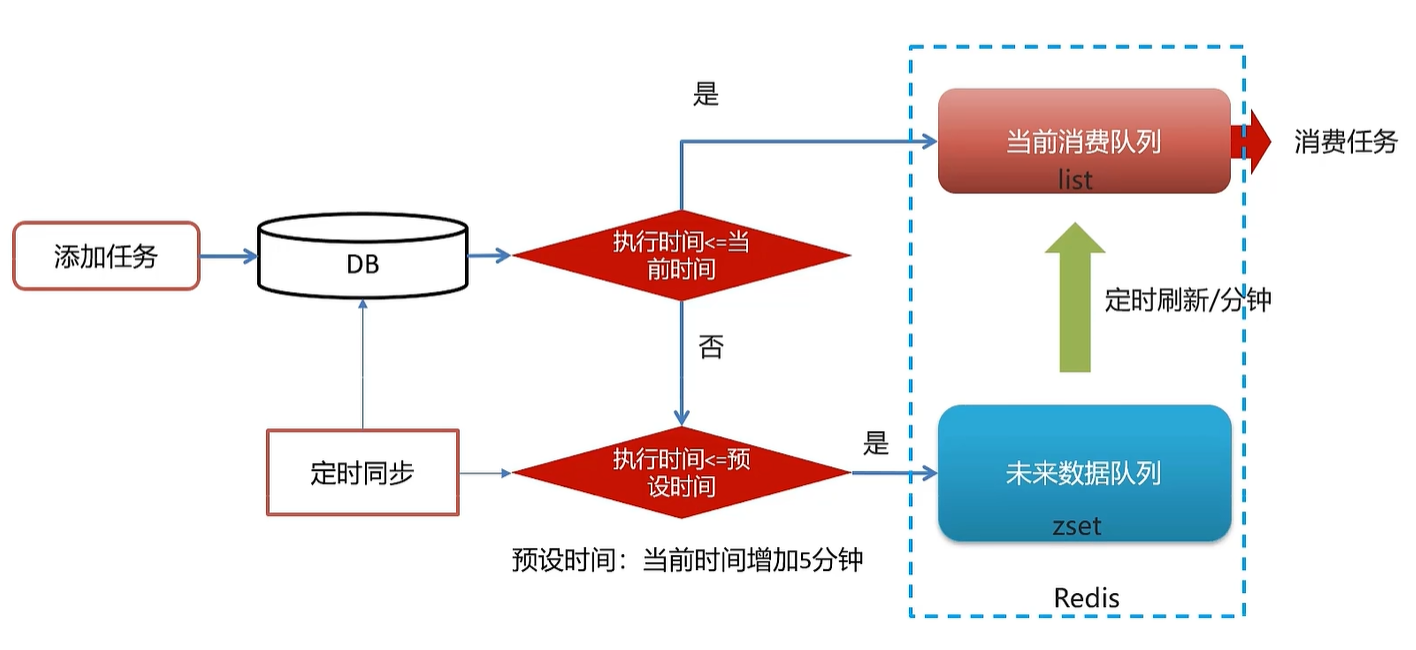
总结:
为什么还要存储到MySQL?
因为redis万一挂掉以后会导致任务丢失,所以任务需要被持久化。
为什么使用redis中的两种数据类型,list和zset?
原因一:list存储立即执行的任务,zset存储未来的数据
原因二:任务量过大以后,zset的性能会下降
为什么还要使用zset作为中间队列?
如果任务数据特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可,是一种优化的形式。