MRVG-Net论文精读
Basic Information
- 标题:Multimodal Reference Visual Grounding
- 作者:Yangxiao Lu¹, Ruosen Li¹, Liqiang Jing¹, Jikai Wang¹, Xinya Du¹, Yunhui Guo¹, Nicholas Ruozzi¹, Yu Xiang¹
- 机构:¹ Department of Computer Science, University of Texas at Dallas, Richardson, TX 75080, USA
- 会议:COLM2025 under review
- 项目主页 (含代码和数据集):https://irvlutd.github.io/MultiGrounding
Abstract
Visual grounding focuses on detecting objects from images based on language expressions. Recent Large Vision-Language Models (LVLMs) have significantly advanced visual grounding performance by training large models with large-scale datasets. However, the problem remains challenging, especially when similar objects appear in the input image. For example, an LVLM may not be able to differentiate Diet Coke and regular Coke in an image. In this case, if additional reference images of Diet Coke and regular Coke are available, it can help the visual grounding of similar objects.
In this work, we introduce a new task named Multimodal Reference Visual Grounding (MRVG). In this task, a model has access to a set of reference images of objects in a database. Based on these reference images and a language expression, the model is required to detect a target object from a query image. We first introduce a new dataset to study the MRVG problem. Then we introduce a novel method, named MRVG-Net, to solve this visual grounding problem. We show that by efficiently using reference images with few-shot object detection and using Large Language Models (LLMs) for object matching, our method achieves superior visual grounding performance compared to the state-of-the-art LVLMs such as Qwen2.5-VL-7B. Our approach bridges the gap between few-shot detection and visual grounding, unlocking new capabilities for visual understanding.
视觉定位(Visual grounding)专注于根据语言表达从图像中检测物体。近期的视觉-语言大模型(LVLMs)通过在大型数据集上训练大模型,显著提升了视觉定位的性能。然而,当输入图像中出现相似物体时,这个问题仍然具有挑战性。例如,一个视觉-语言大模型可能无法区分图像中的健怡可乐(Diet Coke)和普通可乐(regular Coke)。在这种情况下,如果能提供健怡可乐和普通可乐的额外参考图像,将有助于相似物体的视觉定位。在这项工作中,我们引入了一项名为多模态参考视觉定位(Multimodal Reference Visual Grounding, MRVG)的新任务。在这项任务中,模型可以访问数据库中的一组物体参考图像。基于这些参考图像和语言表达,模型需要在查询图像中检测目标物体。我们首先引入了一个新的数据集来研究MRVG问题。然后我们引入了一种名为MRVG-Net 的新方法来解决这个视觉定位问题。我们表明,通过有效地利用 少量样本物体检测的参考图像 ,并使用大型语言模型(LLMs)进行物体匹配,我们的方法在视觉定位性能上优于现有的先进视觉-语言大模型,例如Qwen2.5-VL-7B。我们的方法弥合了少量样本检测和视觉定位之间的差距,为视觉理解开启了新的能力。
Current Issues, Challenges, Author’s Motivation, and Proposed Solution
核心动机:让模型在面对难以用语言精确描述的相似物体时,通过参考额外的图片来更精细的区分和定位目标(区分图像中高度相似物体)。
这张图展示了从简单到复杂的视觉定位任务演进,并定位了本文提出的MRVG任务的创新之处在于其对参考图像集的利用方式和对目标唯一性的要求,旨在解决相似物体带来的定位挑战。

图1:三种视觉定位任务的比较:( a ) 视觉定位根据文本表达在查询图像中识别物体。( b ) 上下文视觉定位除了语言表达外,还利用参考图像(一个或多个)来帮助指代文本表达去定位图像中的目标物体,其中参考图像必须包含目标物体。( c ) 多模态参考视觉定位使用一组参考图像和指示性表达来识别目标,其中目标在参考图像中仅代表一个物体。
这张图清晰地展示了三种不同的视觉定位(Visual Grounding)任务,并突出了本文研究工作(( c )部分)的特点。所有任务的最终目标(Output)都是在右侧的“查询图像”(query image,图中包含一个蓝色瓶子和两个白色瓶子的场景)中,用绿色框标出文本指令所指的目标物体。
核心思想(本文创新点):
- 多模态参考: 同时使用文本表达和一组参考图像集。
- 消除歧义/精确定位: 当查询图像或文本描述本身可能存在歧义时(例如,查询图像中有多个洗发水瓶,或者“二合一标签”描述不够独特时),参考图像集可以帮助模型更精确地理解目标物体到底长什么样。
- 唯一性约束: 目标在参考图像中仅代表一个物体 (the target only represents one object in the reference images)。这意味着在给定的参考图像集中,符合文本描述的目标物体应该是唯一的,这有助于模型学习更具辨别性的特征。
| 方法 | 输入 | 描述 |
|---|---|---|
| ( a ) 传统视觉定位 | 纯文本描述 | 仅依赖文本描述进行查询图像定位。 |
| ( b ) 上下文视觉定位 | 文本描述 + 一个或少数几个必须包含目标的参考图像 | 利用少量示例参考图像来辅助定位,通过示例中的目标物体来指代待定位对象。 |
| ( c ) 多模态参考视觉定位(本文) | 文本描述 + 包含多种物体(目标唯一)的参考图像数据库 | 针对目标类别有多个相似实例且文本描述不足以消除歧义的场景,通过与多样化参考图像库结合,实现更精准的定位;参考库可视作“原型”或“候选原型”集合,增强辨识能力。 |
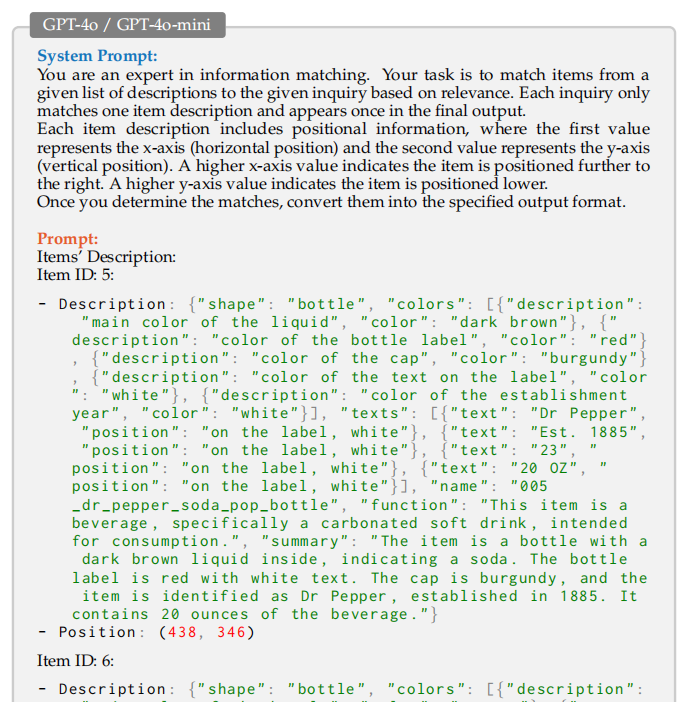
我们提出了一种名为 MRVG-Net 的新方法,用于解决多模态参考视觉定位任务。在我们的方法中,给定目标物体的参考图像,我们会使用一个像GPT-4o-mini 这样的视觉-语言大模型(LVLM)来提取这些物体的文本描述,例如颜色、形状和用途。这一步只需要运行一次。然后,我们获得了参考图像 中 所有物体的文本描述。在推理过程中,当给定一个查询图像时,首先会使用一个少样本检测器,例如NIDS-Net ,来从查询图像中检测目标物体。NIDS-Net 使用参考图像作为少样本物体检测的支持集 。因此,它只检测那些存在于参考图像中的物体。利用NIDS-Net预测的物体实例ID,我们可以检索到检测到的物体对应的描述。最后,一个像GPT-4o 这样的大型语言模型(LLM)执行推理,将物体描述与输入的文本查询进行匹配,以生成最终的物体定位结果。我们的方法不像上下文视觉定位那样依赖LVLM来处理参考图像,而是利用一个少样本物体检测器根据参考图像来检测物体。因此,我们的方法能够处理大量的参考图像。此外,物体匹配仅使用文本来完成,这样我们可以利用最先进的LLM进行鲁棒的匹配。
具体来说,在多模态参考视觉定位中,我们获得一组 N N N 个目标实例,其中每个实例由 K K K 个参考图像表示。我们将所有参考图像表示为 I T ∈ R N × K × 3 × W × H I_T \in \mathbb{R}^{N \times K \times 3 \times W \times H} IT∈RN×K×3×W×H,其中 W W W 和 H H H 分别表示图像的宽度和高度。每个参考图像仅包含一个物体以及该物体的分割掩码。我们将参考图像的所有分割掩码表示为 M T ∈ R N × K × W × H M_T \in \mathbb{R}^{N \times K \times W \times H} MT∈RN×K×W×H。目标是在查询图像 I Q ∈ R 3 × W × H I_Q \in \mathbb{R}^{3 \times W \times H} IQ∈R3×W×H 中定位并分割由指示性表达 r r r 描述的特定目标物体。指示性表达 r r r 提供了一种自然语言描述,该描述能够明确识别出查询图像中出现的 N N N 个目标物体之一。与目标物体相关联的 K K K 个模板图像中的每一个都作为视觉参考,模型利用它来匹配查询图像中所指的物体。输出包含一个边界框 b b b 和一个可选的实例分割掩码 m ∈ R W × H m \in \mathbb{R}^{W \times H} m∈RW×H,该掩码精确地描绘了物体的边界。
Dataset
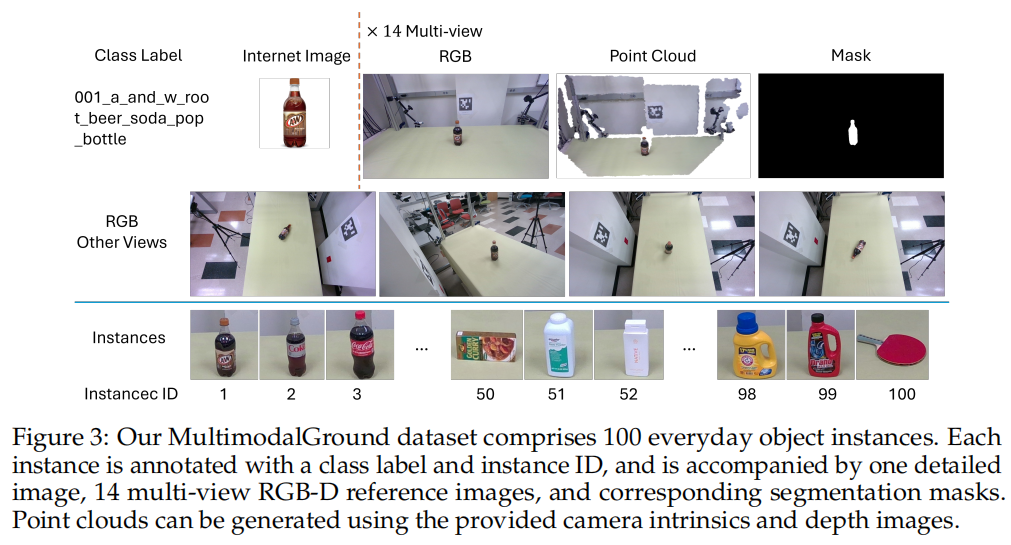
我们引入了一个名为 MultimodalGround 的新数据集,该数据集可用于评估模型在两项任务上的表现:标准视觉定位和多模态参考视觉定位。该数据集包含四种类型的场景,其中含有250张RGB-D查询图像和855个由人工手动标记的物体标注。这些图像是使用一台英特尔实感D455相机拍摄的。如图2所示,每个标注包括一个边界框、一个分割掩码和一个指示性表达。

查询图像中的物体代表了100种可以在超市中找到的常见日常用品。对于每个物体实例,数据集提供了使用七台英特尔实感D455相机从七个不同视角拍摄的14张真实世界RGB-D模板图像,此外还有一张来源于互联网的RGB图像,用于支持生成详细的物体描述。对于每张RGB-D参考图像,我们为每个物体提供了一个对应的掩码,如图3所示。这些参考图像用于为语言定位提供视觉参考。为了促进未来在RGB-D视觉定位、新实例检测和分割方面的研究,我们在数据集中同时提供了相机的内参和深度图像。
Method
我们的框架 MRVG-Net 采用了一种“检测与匹配”范式,如图 4 所示。对于 N 个对象中的每一个,使用一个 代表性图像 I i I_i Ii 来生成一个详细的对象描述文件 D i D_i Di,这里使用了一个大型视觉语言模型 (LVLM),其中 i = 1 , . . . , N i = 1, ..., N i=1,...,N。这些描述文件 { D i D_i Di} i = 1 N _{i=1}^N i=1N 作为对象匹配的基础。给定一个 查询图像 I Q I_Q IQ,少样本检测器 NIDS-Net (Lu et al., 2024) 通过生成一组 实例 ID { c j c_j cj} 及其对应的边界框 { b j b_j bj} 来识别相关对象,其中 j = 1 , . . . , M j = 1, ..., M j=1,...,M 表示 M M M 个检测,基于参考图像。利用预测的对象实例 ID,我们检索相应的对象描述 { D c j D_{c_j} Dcj} 和空间位置 { b j b_j bj},以形成一组候选对象 C = { ( D c j , b j ) } j = 1 M C = \{ (D_{c_j}, b_j) \}_{j=1}^M C={(Dcj,bj)}j=1M。最后,一个大型语言模型 (LLM) 在候选对象 C C C 和指代表达式 R R R 之间执行匹配,以识别目标对象。
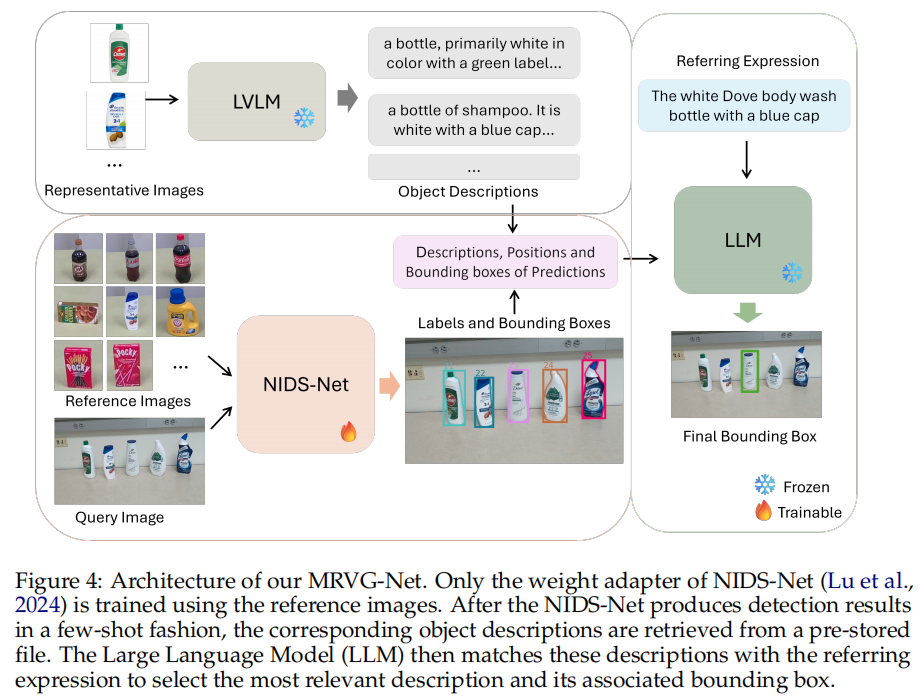
- 首先,利用 LVLM 为可能的对象建立一个视觉和文本描述的知识库。
- 然后,利用 NIDS-Net 在给定的查询图像中初步检测出一些候选对象。
- 最后,利用 LLM 理解用户的自然语言指令(指代表达式),并将这个指令与 NIDS-Net 的检测结果以及 LVLM 生成的描述进行智能匹配,从而精确地定位用户想要找的目标对象。
Object Descriptions
为了支持精确的对象定位(object grounding),我们采用一个大型视觉语言模型(LVLM)来为 N = 100 N = 100 N=100 个日常对象生成详细的自然语言描述,每个对象都由一张高质量的 互联网图像 I i I_i Ii(其中 i = 1 , . . . , N i = 1, ..., N i=1,...,N)表示。对于每个对象,LVLM 会生成一个描述性文件 D i D_i Di,该文件捕捉了细粒度的视觉属性,如形状、颜色、材质和功能。这些描述 { D i D_i Di} i = 1 N _{i=1}^N i=1N 具有上下文感知能力,能够很好地与自然指代表达式对齐,并增强跨模态检索性能。对象描述可以使用 LVLM 预先计算并存储在一个文件中,这样在推理过程中就不再使用 LVLM。
Novel Instance Detection
给定目标实例的参考图像 I T I_T IT,NIDS-Net (Lu et al., 2024) 通过以下步骤在查询图像 I Q I_Q IQ 中检测相应的对象。首先,它对 I Q I_Q IQ 应用 Grounding DINO ,使用一个通用的文本提示(例如,“Object”)来获得一组前景对象的初始边界框 { b j b_j bj} j = 1 M _{j=1}^M j=1M。对于每个边界框 b j b_j bj,使用 SAM 来生成一个精确的分割掩码 m j m_j mj,从而得到以 ( b j , m j b_j, m_j bj,mj) 表示的对象proposals。然后,每个参考图像和提议都被编码成一个实例嵌入。具体来说,NIDS-Net 从 DINOv2 ViT 的块嵌入 (patch embeddings) 中提取平均前景特征,分别表示为参考实例的 e i e_i ei 和提议的 e j e_j ej。一个权重适配器被应用于通过鼓励相似实例间的聚类和不相似实例间的分离来优化这些嵌入。最后,该方法将提议嵌入 { e j e_j ej} 与目标嵌入 { e i e_i ei} 进行匹配,预测标签以及它们对应的边界框 { b j b_j bj} 和掩码 { m j m_j mj}。在 NIDS-Net 中,只有权重适配器使用这些参考图像进行训练,而所有其他组件保持冻结状态。
LLM Reasoning for Matching
为了在查询图像 I Q I_Q IQ 中识别出自然语言表达 r r r 所指的目标对象,我们构建了一个候选集 C = { ( D c j , p j , b j , m j ) } j = 1 M C = \{ (D_{c_j}, p_j, b_j, m_j) \}_{j=1}^M C={(Dcj,pj,bj,mj)}j=1M。其中,每个元素包含一个检索到的对象描述 D c j D_{c_j} Dcj、预测边界框 b j b_j bj 的左上角位置 p j = ( x j , y j ) p_j = (x_j, y_j) pj=(xj,yj),以及其可选的相应分割掩码 m j m_j mj。对象描述 D c j D_{c_j} Dcj 是通过将预测的实例 ID c j c_j cj 映射到参考集中由 LVLM 生成的描述配置文件而获得的。
为了执行匹配,我们向大型语言模型 (LLM) 输入指代表达 r r r 和候选集 C C C,并要求它根据相对空间位置、语义相似性和上下文线索来选择最可能的匹配项。为简单起见,匹配过程仅考虑对象描述 D c j D_{c_j} Dcj 和位置 p j p_j pj,而省略了边界框 b j b_j bj 和掩码 m j m_j mj。
这种方法利用了 LLM 在细致入微的语言理解和推理方面的能力,即使在存在视觉上相似的对象或模糊措辞的情况下,也能够准确解析指代表达。我们的方法具有可解释性,并且与人类的理解方式相一致,从而提高了在复杂场景下的定位(grounding)准确性。
Experiments
Settings
在我们的框架中,我们仅使用参考图像来训练 NIDS-Net 的 权重适配器(weight adapter)。该适配器包含两个线性层,在几分钟内训练了 640 个周期 (epochs)。继 NIDS-Net 之后,训练过程采用 Adam 优化器,学习率为 1 × 10 − 3 1 \times 10^{-3} 1×10−3,批处理大小为 1024,并使用 InfoNCE 损失函数。所有实验均在配备 4 × NVIDIA A100 GPUs 4 \times \text{NVIDIA A100 GPUs} 4×NVIDIA A100 GPUs 的服务器上运行。
Evaluation metric: 给定一个查询图像、一个指代表达式和一组参考图像,模型会预测一个由该表达式描述的边界框。为了评估定位(grounding)性能,我们计算预测边界框与真实边界框之间的交并比(Intersection over Union, IoU)。IoU 大于 0.5 的预测被分类为真正例(true positives),低于该阈值的则为假正例(false positives)。准确率(Acc@0.5)计算为所有真正例的数量除以所有测试样本的总数。为了全面评估模型的定位能力,我们根据 Ref-L4 的建议,计算不同 IoU 阈值下的准确率:Acc@0.75、Acc@0.9,以及 mAcc,后者计算的是 IoU 阈值在 0.5 和 0.9 之间,以 0.05 为增量的平均准确率。
Experimental Results
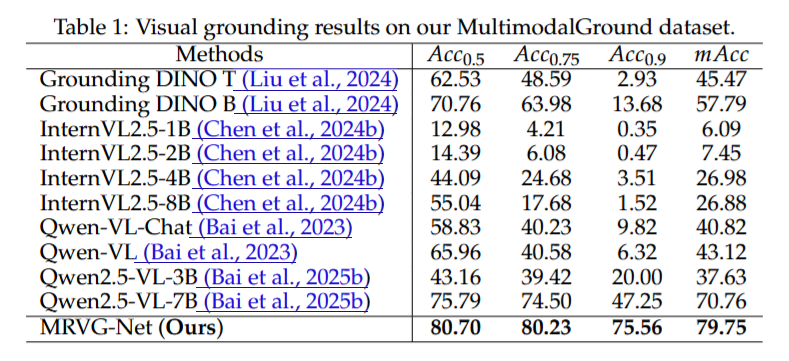
与其他方法的比较: 我们在表1中展示了不同模型在 MultimodalGround 数据集上的评估结果。尽管其他模型以零样本(zero-shot)的方式执行视觉定位,但我们的方法是唯一一个通过利用参考图像以少样本(few-shot)方式处理多模态参考视觉定位任务的模型。我们的方法在所有指标上均优于其他所有模型,展示了其在处理视觉定位任务中一系列挑战性场景时的卓越能力。此外,高 Acc@0.9 值表明我们方法的边界框能够准确地定位目标对象。
定性结果: 我们在图5中展示了我们数据集上的视觉结果。虽然其他模型可能会因为缺乏视觉线索而检测失败,但我们的方法利用参考图像来实现准确检测。

Ablation Study
物体描述模型: 我们评估了不同的多模态大语言模型 (LVLM),使用相同的提示词来生成物体描述。如表2所示,当匹配策略和匹配模型相同时,GPT-4o 的表现优于 GPT-4o-mini,这表明其在描述生成任务中具有强大的能力。此外,在审查了两个模型生成的描述后,GPT-4o 通常比 GPT-4o-mini 提供更详细、信息更丰富的描述。
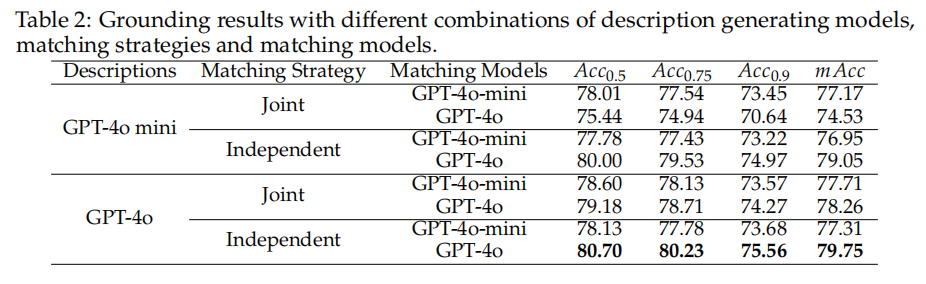
匹配策略和匹配模型: 采用了两种匹配策略来关联一组物体描述和一组指代表达。联合匹配是指同时匹配两组,其中每个指代表达都与集体语境中整组物体描述进行比较。因此,联合匹配并行处理图像查询中的所有指代表达。相比之下,独立匹配是独立地将每个指代表达与物体描述集进行匹配,将每个表达视为独立个体,而不考虑指代表达之间的相互作用。表2表明,独立匹配产生了卓越的性能,因为不正确的匹配不会影响其他匹配的准确性。表2还显示,在 MultimodalGround 数据集上,GPT-4o 在大多数情况下都优于 GPT-4o-mini,这得益于其卓越的能力。
假设你有一堆玩具,每种玩具都有一个名字(比如“小熊”、“小汽车”、“积木”)。同时,你还有一些描述这些玩具的纸条(比如“毛茸茸的玩具”、“会跑的玩具”、“可以搭起来的玩具”)。现在,你的任务是把纸条和对应的玩具配对起来。这里有两种不同的匹配策略。
-
联合匹配 (Joint Matching):
- 想象:你把所有的玩具都摆在桌子上,然后把所有的纸条都拿在手里。
- 怎么做:你看着一张纸条(比如“毛茸茸的玩具”),然后环顾桌子上所有的玩具,找出那个最符合描述的玩具(小熊)。同时,你心里还想着其他的纸条和玩具,确保你做的每个配对都是最合理的,这样才能让所有的纸条都和最合适的玩具配对上。
- 特点:这种方法考虑的是整体。你在配对的时候,会同时考虑所有的玩具和所有的描述,让它们“组队”达到最佳效果。如果一个描述和玩具配错了,可能会影响到其他描述和玩具的配对。
-
独立匹配 (Independent Matching):
- 想象:你一次只拿一个玩具出来,然后一次只拿一张纸条出来。
- 怎么做:你拿起一张纸条(比如“毛茸茸的玩具”),然后只盯着一个玩具(比如小熊),看看它们是不是一对。如果是,就配对。如果不是,就放下这个玩具,再拿另一个玩具来试。你不会去管其他的纸条和玩具,只专注于当前这一对。
- 特点:这种方法考虑的是个体。每个纸条和玩具的配对都是独立的,一个配错了不会影响到其他的配对。因为它们是“单打独斗”的。
在原文的语境中,这个“匹配”是关于“物体描述”和“指代表达”(比如一句话描述一个物体)的配对。这两种策略决定了模型在进行这种配对时,是全局考量(联合匹配)还是局部独立考量(独立匹配)。文章中说,“独立匹配”表现更好,可能是因为它避免了“一个错误影响一串”的问题,当一个配对出现错误时,不会“牵连”到其他配对,从而整体的准确率更高。
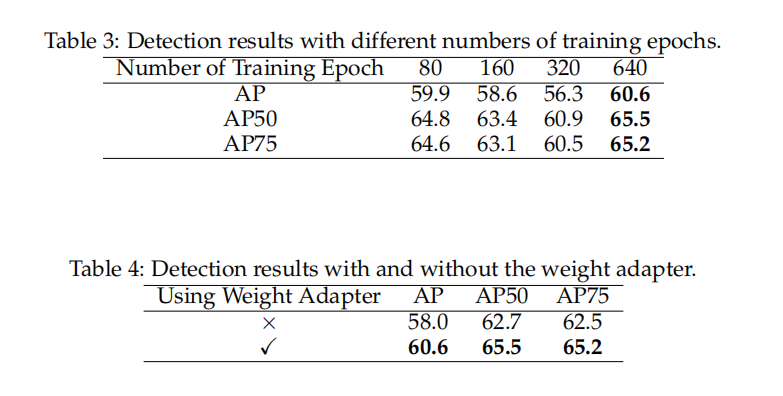
NIDS-Net 权重适配器在不同训练周期数下的结果呈现在表3中。我们选择640个周期,因为它能提供稳定且鲁棒的性能。AP、AP50 和 AP75 是用于评估物体检测模型的指标,其中 AP 是平均精度,AP50 是在 IoU 阈值为0.5时的精度,AP75 是在 IoU 阈值为0.75时的精度。NIDS-Net 中未使用权重适配器的物体检测结果呈现在表4中。
Prompts
Visual Grounding Prompts

Object Description Generation

LLM Matching
Joint Matching



Independent Matching
Failure Cases
我们方法的失败案例主要归因于 NIDS-Net 中的检测错误,如图6所示。NIDS-Net 在 IoU 阈值为0.50时达到了65.5的平均精度(AP),在 IoU 阈值为0.75时达到了65.2的平均精度。不正确的类别标签预测导致物体描述和指代表达之间的不匹配。预计使用比 NIDS-Net 更先进的少样本检测器将改善我们框架的性能。

失败分析: NIDS-Net 在855次预测中存在318次错误分类,而 MRVG 仅有165次失败。这种差异的产生是因为 NIDS-Net 的错误分类并不总是导致定位失败。例如,像“最左边的瓶子”这样的短语依赖于相对空间关系,这可以从预测的边界框中推断出来。此外,NIDS-Net 可能会将一个实例错误分类为另一个相似的实例,但描述足够接近,大型语言模型(LLMs)仍然可以正确地定位目标物体。
核心原因是:物体检测器 NIDS-Net 不够准。NIDS-Net 经常误判物体类别,但有些错误不影响最终结果,因为:
- 描述依赖的是物体相对位置,而非精确识别。即使 NIDS-Net 对瓶子的具体类别有点误差,但只要它能准确识别出瓶子的边界框(bounding box),LLM依然能根据边界框推断出“最左边”的位置,从而正确理解描述。
- 语言模型(LLM)够“聪明”,有时 NIDS-Net 可能把一个物体错认为另一个“相似”的物体(比如把一个类型的杯子认成另一个类型的杯子),但LLM能容忍一些检测小误差。
- 解决方法:换个更先进的检测器。
Conclusion
在这项工作中,我们引入了多模态指代视觉定位(MRVG)任务,该任务结合了文本查询和多张参考图像以增强视觉定位。鉴于来自LVLM的物体描述,我们提出的MRVG-Net方法利用了一个少样本物体检测器来处理参考图像,然后利用一个LLM来匹配物体描述和指代表达。MRVG-Net在我们引入的MultimodalGround数据集上优于现有模型,展示了其在实际应用中的潜力。这项工作为开发更鲁棒和上下文感知的视觉定位系统开辟了新的途径。
局限性: 像 NIDS-Net 这样的少样本检测器在物体检测中可能存在误差。在推理过程中,顺序处理指代表达可能需要大量的计算资源并耗费时间。因此,当查询图像包含大量项目时,我们的方法可能会产生高计算成本和较长的处理时间。
Directions for improvement
- 更先进的少样本检测器: 论文明确指出 NIDS-Net 在物体检测上存在误差,并提到使用更先进的少样本检测器有望提升性能 。可以探索最新的少样本目标检测模型,例如基于Transformer的检测器、或者结合了更强预训练模型(如更大规模的 CLIP 或 DINOv2)的检测器,来提高检测精度和召回率。
- 更紧密的模态融合: 目前 MRVG-Net 是“检测-匹配”两阶段范式 。未来可以探索更紧密的端到端多模态融合模型,直接将参考图像、查询图像和文本查询输入一个统一的网络,实现特征级别的融合,从而避免中间阶段的误差累积,并可能捕获更复杂的跨模态交互。
- 动态物体描述生成: 论文中物体描述是预先生成的 。可以尝试在推理阶段根据查询图像的上下文信息,动态生成或精炼物体描述,使其更具语境相关性,从而提升匹配精度。例如,当查询图像中的物体受光照、遮挡影响时,动态描述可以更好地适应这些变化。
- 强化 LLM 的空间推理能力: 论文指出 LLM 在匹配时使用了空间位置信息 。可以进一步优化 LLM 的提示词工程,或通过专门的微调,使其在处理“最左边”、“上方”、“靠近”等相对空间关系时更准确、更鲁棒。可以引入更复杂的几何或拓扑关系表示,而不只是简单的 (x, y) 坐标 。
- 多参考图像选择策略: 论文中提到了“大量参考图像” 。可以研究更智能的参考图像选择机制,例如通过相似性度量或基于查询的图像检索,从海量参考库中自动选择最相关、最具辨识度的参考图像,以减少噪声和计算负担。
- 交互式视觉定位: 允许用户通过多轮对话或交互式点击来修正模型的定位结果,使系统更加用户友好和灵活。
Appendix
附1:虚拟现实(Virtual Reality, VR)和增强现实(Augmented Reality, AR)
-
VR (Virtual Reality - 虚拟现实):
- VR技术旨在创造一个完全沉浸式的计算机生成的环境,用户戴上特制的头戴显示设备(VR头盔)后,会感觉自己仿佛置身于一个全新的、虚拟的世界中。这个虚拟世界可以与真实世界完全不同,用户的视觉和听觉会被虚拟环境所主导。
- VR应用包括游戏、模拟训练(如飞行、手术模拟)、虚拟旅游、虚拟社交、教育体验等。
-
AR (Augmented Reality - 增强现实):
- AR技术是将计算机生成的虚拟信息或图像叠加到用户所看到的真实世界之上,从而“增强”用户对现实世界的感知。用户通常通过智能手机、平板电脑的摄像头,或者特制的AR眼镜来体验。AR不会取代真实环境,而是在真实环境的基础上添加数字内容。
- AR应用包括手机上的AR游戏(如Pokémon GO)、AR导航(在真实街道上显示方向箭头)、产品虚拟试穿/试戴、工业维护指导(在真实设备上显示维修步骤)、教育(如展示三维恐龙模型在教室里)等。
在引用的文本中,提到“视觉定位这些物体(visual grounding of these objects)可能在各种机器人技术和VR/AR应用中非常有用”,这意味着:
在VR或AR环境中,如果系统能够准确地根据语言指令(比如用户说的话或程序指令)识别并定位环境中的特定物体(无论是虚拟物体还是AR叠加在真实物体上的标签),这将非常关键。
- 例如,在VR应用中: 用户可能会说“拿起桌子上的那个红色杯子”,VR系统就需要通过“视觉定位”来准确识别指令中的“红色杯子”是虚拟场景中的哪一个。
- 例如,在AR应用中: 用户可能会通过AR眼镜看着一个真实的机器并说“告诉我这个部件的名称”,AR系统需要定位用户视线关注的“这个部件”,并显示相关信息。或者,在AR导航中,指令可能是“在那个便利店右转”,系统需要定位到用户视野中的“那个便利店”。
“VR/AR applications”指的是利用虚拟现实和增强现实技术开发的各种程序或系统,而论文中研究的视觉定位技术能够帮助这些应用更智能、更准确地理解和响应与环境中物体相关的指令。
附2:MRVG-Net训练细节
MRVG-Net旨在解决多模态指代视觉定位 (MRVG) 任务,该任务的目标是根据文本查询和多张参考图像,从查询图像中定位目标物体。
MRVG-Net的训练主要集中在NIDS-Net的权重适配器(weight adapter)上。NIDS-Net是MRVG-Net框架中用于少样本物体检测的组件。权重适配器由两个线性层组成。
- 训练目标: 训练NIDS-Net的权重适配器,使其能够根据参考图像有效地检测查询图像中的物体。
- 训练时长/周期: 权重适配器被训练了640个周期 (epochs),作者指出这在几分钟内即可完成,并能提供稳定且鲁棒的性能。
- 优化器: 使用Adam优化器。
- 学习率: 1 × 10 − 3 1 \times 10^{-3} 1×10−3。
- 批次大小 (Batch Size): 1024。
- 损失函数: 使用InfoNCE损失函数。
- 硬件: 所有实验均在配备4块NVIDIA A100 GPU的服务器上运行。
- NIDS-Net其他组件: 除了权重适配器,NIDS-Net的其他组件在训练过程中保持冻结 (frozen) 状态。
文中明确指出训练的是NIDS-Net的“权重适配器(weight adapter)”,这是一个由两个线性层组成的组件,其目的是在保持大部分模型冻结的情况下,高效地适应新任务。这种“适配器”的概念与LoRA在参数高效微调中的思路相似。
- 数据集: 引入了一个新的数据集,名为MultimodalGround。
- 数据集组成: 包含1400张参考图像、250张查询图像,以及855个与100个日常物体相关的指代表达。
- 场景类型: 包含四种不同类型的室内外场景。
- 查询图像标签: 每个查询图像中的目标物体都由人工标注,包括边界框 (bounding box)、分割掩码 (segmentation mask) 和指代表达 (referring expression)。
- 参考图像: 对于每个物体实例,数据集提供了14张真实世界的RGB-D模板图像(从七个视角捕获)和一张来自互联网的RGB图像,用于生成详细的物体描述。每张RGB-D参考图像也提供了对应的物体掩码。
- 物体描述的生成: 使用大型视觉-语言模型 (LVLM),如GPT-4o-mini或GPT-4o,根据物体的代表性图像生成详细的自然语言描述(包括形状、颜色、文本、功能等)。这些描述是预先计算并存储的,推理时LVLM不再参与此过程。
训练流程总结
- 离线准备: 使用LVLM (GPT-4o/GPT-4o-mini) 为数据库中的每个参考物体生成详细的文本描述,并存储起来。
- 核心训练: 训练NIDS-Net的一个小型权重适配器。NIDS-Net在训练时利用参考图像作为支持集,以学习如何识别查询图像中那些在参考图像中出现的物体。
- 推理阶段:
- 给定查询图像,NIDS-Net首先检测物体,并输出检测到的物体实例ID及其边界框。
- 根据这些实例ID,检索预先生成的物体描述。
- 最后,一个大型语言模型 (LLM),如GPT-4o,根据文本查询和检测到的物体描述(包含位置信息)进行匹配,从而找到最终的目标物体并提供其边界框。
关键创新点: 这种“检测-匹配”范式,将少样本物体检测与LLM的文本推理能力结合起来,使得模型能够有效处理大量参考图像,并通过纯文本匹配实现鲁棒的物体定位。
附3:主实验表格1解释
“T”代表 Tiny,指的是 Swin-T(Swin Transformer Tiny) 骨干网络。它的参数量和浮点运算(FLOPs)最小,推理速度最快,但特征表达能力相对有限。
“B”代表 Base,通常指 Swin-B(Swin Transformer Base) 骨干网络。相较于 Tiny 版本,它的参数和计算量大约增加一倍,能够提供更丰富的特征表达和更精确的定位能力,但推理开销也相应更大。
为什么骨干网络越大收益越明显?
- 更丰富的特征表达: Swin-B在各层的通道数和Transformer block数量上都比Swin-T更多,这使其能够捕捉到更细粒度的视觉线索。
- 更深的上下文融合: 更多的层数意味着模型能够在多尺度上汇聚更多上下文信息,这对于处理复杂场景(例如小物体、遮挡)时,模型的鲁棒性更强。
- 更强的预训练基础: 通常情况下,Swin-B在进行大规模图像分类和检测的预训练时就表现出更好的性能,这使得它在微调到下游的grounding任务时具有先天优势。
拓展思考:
- 跨模态重排序模块: MRVG-Net在生成候选框基础上,可引入语言引导的重排序(re-ranking)机制。
- 多骨干并行: 未来的研究可以考虑同时使用Swin-T/B/L等不同规模的骨干网络,并通过多尺度集成(ensemble)的方式来提升性能。
- 更大规模预训练: 可以加入COCO、RefCOCO等专门用于grounding任务的语料库进行更大规模的预训练,以进一步提升模型性能。利用更强大的语言模型或图文对齐损失函数,可以进一步提升性能。