C语言之 比特(bit)、字节(Byte)、字(Word)、整数(Int)
在C语言中,经常出现上述的概念,即比特(bit)、字节(Byte)、字(Word)、整数(Int)。查看C语言标准,比特(bit)的定义如下:

即,能存放0或1的存储单元。这是一个抽象的概念。因为,比特(bit)在C语言中并不能直接操作,因为,比特并不是最小的访问(Access)单元,即,没有比特级的寻址(unaddressable)。
而最小的寻址单位是字节(Byte)。其定义如下:

也就是字节(Byte)由特定数量的比特(Bit)所构成,如常见的 8 比特(Bits)构成一个字节(Byte)。 其主要特点是 C语言中的最小寻址单位(addressable)。
整数(Int)在C语言的定义如下:

也就是说其大小由对应的指令集架构(ISA)所定义的。那么,看看 RISCV ISA 对整数的定义如下:
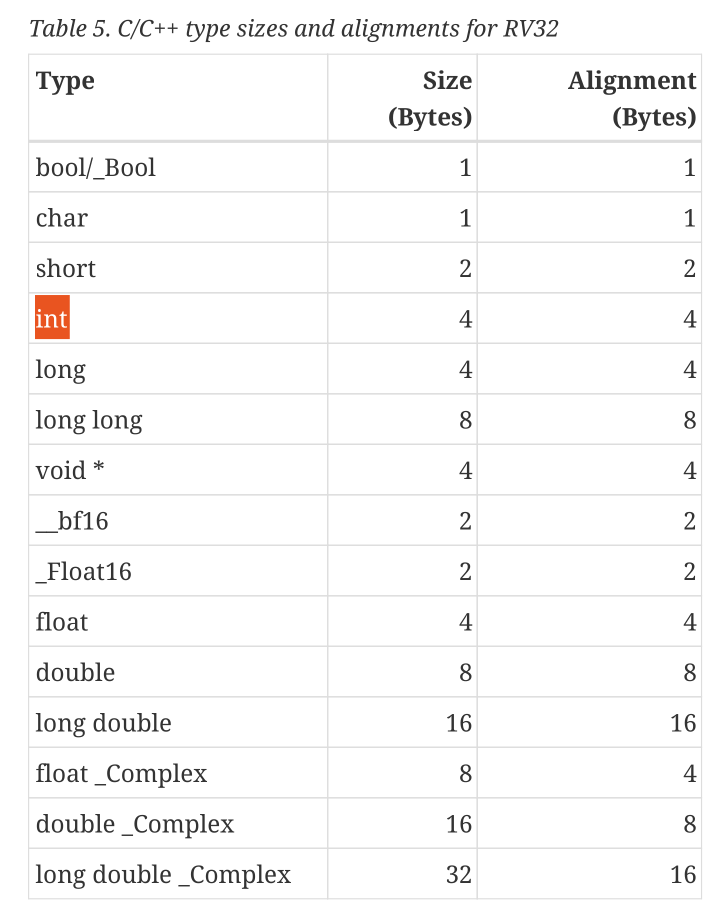
以及:
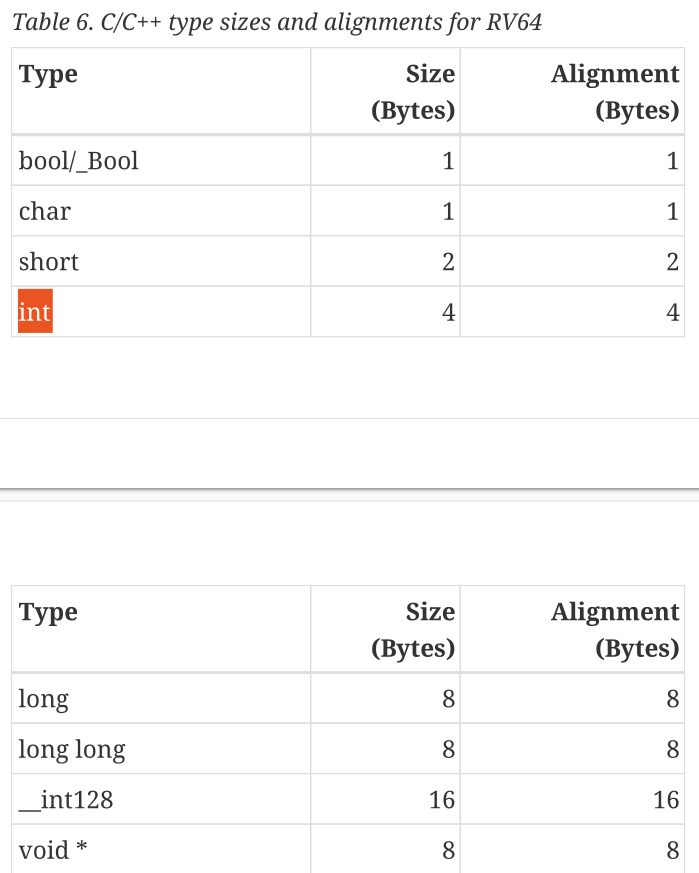
可见,整数(Int)在 RISCV ISA 中,被定义为由 4 字节组成。
那么,字(Word)的概念就在这些原生类型中抽象出来的,是在语义级(Semantics)上的概念,也就是跟业务逻辑(Business Logic)相关的概念。其由字节(Bytes)所组成,具体多少字节形成一个字(Word),也叫单字(Single World),由其业务逻辑所定义,通常一个字(Word)的大小等于一个整数(Int)。那么,一般来说,对应的有 半字(Half-Word)对应短整数(Short-Int),双字(Double-Word)对应长整数(Long-Int),四字(Quad-Word)对应长长整数(Long Long Int)。
这里,可把字节(Byte)看作英文字母(Alphabet),字(Word)看作英文单词(Word in Vocabulary)。