Genetic Algorithm改进策略全【编码/适应度/选择/交叉/变异/参数选择/终止条件】
文章目录
- @[toc]
- 写在前面
- 并行遗传算法Parallel Genetic Algorithm
- 一、编码方法
- 1.1 编码的重要性
- 1.2 编码原则
- 1.3 编码方法
- 1.3.1 二进制编码
- 汉明悬崖问题:
- Grey Code:
- 1.3.2 浮点数编码
- 1.3.3 符号编码及其他编码
- 多参数级联编码
- 多参数交叉编码
- 二、适应度函数
- 2.1 函数重要性
- 2.2 适应度函数设计原则
- 2.3 适应度种类
- 2.4 尺度变换
- 2.4.1 尺度变换的原因
- 2.4.2 尺度变换方法
- 1. 线性尺度变换
- (1) 正常情况放缩
- (2) 后期为负值
- 2.乘幂尺度变换
- 3.指数尺度变换
- 三、约束条件处理
- 3.1 搜索空间限制
- 3.2 罚函数
- 难点:
- 3.3 可行解变换法
- 缺点:
- 四、选择算子
- 4.1 比例选择
- 4.2分级/排序选择
- 1.原因:( f f f悬殊)
- 2.方法:
- 优缺点:
- 4.3 竞技选择
- 操作:
- 特点:
- 优势:
- 4.4 最优保存策略
- 操作:
- 特点:
- 使⽤⽅法:
- 4.5 截断选择
- 4.6 (μ+λ)选择
- 4.7 对比总结
- 五、交叉算子
- 5.1 单点交叉
- 特点:
- 5.2 多点交叉
- 两点操作:
- 多点交叉:
- 5.3 均匀交叉
- 操作:
- 举例:
- 5.4 算术交叉
- 操作过程:
- 5.5 平坦交叉和线性交叉
- 平坦交叉
- 线性交叉
- 六、变异算子
- 6.1 基本位变异
- 具体操作过程:
- 举例:
- 6.2 均匀变异
- 具体操作过程:
- 举例:
- 适用范围:
- 6.3 边界变异
- 均匀变异缺点:
- 6.4 非均匀变异
- 6.5 高斯变异
- 举例:
- 七、控制参数选择
- 八、终止条件
- 九、种群多样性
- 9.1 小生境技术
- 9.2 早熟
- 原因:
- 防止:
- 9.3 多种群遗传算法MPGA
文章目录
- @[toc]
- 写在前面
- 并行遗传算法Parallel Genetic Algorithm
- 一、编码方法
- 1.1 编码的重要性
- 1.2 编码原则
- 1.3 编码方法
- 1.3.1 二进制编码
- 汉明悬崖问题:
- Grey Code:
- 1.3.2 浮点数编码
- 1.3.3 符号编码及其他编码
- 多参数级联编码
- 多参数交叉编码
- 二、适应度函数
- 2.1 函数重要性
- 2.2 适应度函数设计原则
- 2.3 适应度种类
- 2.4 尺度变换
- 2.4.1 尺度变换的原因
- 2.4.2 尺度变换方法
- 1. 线性尺度变换
- (1) 正常情况放缩
- (2) 后期为负值
- 2.乘幂尺度变换
- 3.指数尺度变换
- 三、约束条件处理
- 3.1 搜索空间限制
- 3.2 罚函数
- 难点:
- 3.3 可行解变换法
- 缺点:
- 四、选择算子
- 4.1 比例选择
- 4.2分级/排序选择
- 1.原因:( f f f悬殊)
- 2.方法:
- 优缺点:
- 4.3 竞技选择
- 操作:
- 特点:
- 优势:
- 4.4 最优保存策略
- 操作:
- 特点:
- 使⽤⽅法:
- 4.5 截断选择
- 4.6 (μ+λ)选择
- 4.7 对比总结
- 五、交叉算子
- 5.1 单点交叉
- 特点:
- 5.2 多点交叉
- 两点操作:
- 多点交叉:
- 5.3 均匀交叉
- 操作:
- 举例:
- 5.4 算术交叉
- 操作过程:
- 5.5 平坦交叉和线性交叉
- 平坦交叉
- 线性交叉
- 六、变异算子
- 6.1 基本位变异
- 具体操作过程:
- 举例:
- 6.2 均匀变异
- 具体操作过程:
- 举例:
- 适用范围:
- 6.3 边界变异
- 均匀变异缺点:
- 6.4 非均匀变异
- 6.5 高斯变异
- 举例:
- 七、控制参数选择
- 八、终止条件
- 九、种群多样性
- 9.1 小生境技术
- 9.2 早熟
- 原因:
- 防止:
- 9.3 多种群遗传算法MPGA
SGA面临的问题其中主要包含:
- 交叉变异会破坏优良基因,使得普通遗传算法陷入早熟(考定义)(所有个体都收敛到同一极值无法进化,陷入局部最优解;2. 接近最优解的个体总被淘汰,进化过程不收敛)
- 轮盘赌的方式使得适应值高的个体占据种群,种群多样性下降,导致种群停止进化
- 没有一个简洁通用得到适应度值标定方法
写在前面
我们可以在多方面进行遗传算法的改进,包括:
-
分层遗传算法(Hierarchic Genetic Algorithm);
-
CHC算法;
-
Messy 遗传算法;
-
⾃适应遗传算法(Adaptive Genetic Algorithm);
-
基于⼩⽣境技术的遗传算法(Niched Genetic Algorithm,NGA);
-
并⾏遗传算法(Parallel Genetic Algorithm);
-
混合遗传算法:
①遗传算法与最速下降法相结合的混合遗传算法。
②遗传算法与模拟退⽕法(Simulated Annealing)相结合的混合遗传算法
并行遗传算法Parallel Genetic Algorithm
- 多种群并行进化的遗传算法
- 克服标准遗传算法的早熟收敛问题,有较强的全局搜索能力
- 将并行计算机的高速并行性和GA天然的并行性相结合,增加种群多样性,减少了未成熟收敛的可能
- 包括两种方法:标准型并行、分解型并行
- 标准型(主从式模型):主节点机将选择的群体部分个体发送给从节点机;从节点机把适应度评价发给主节点
- 分解型:只依照节点机个数分成若干子群体,各个子群体在各自节点机上并发独自运行遗传算法;经过一定的进化代,各子群体间将交换若干个体(引入优良个体,丰富了种群的多样性,防止未成熟早收敛)
接下来我们从这几个方面进行阐述:
一、编码方法
1.1 编码的重要性
遗传算法是对问题变量的编码集进⾏操作,⽽不是变量本身,有效地避免了对变量的微分操作运算。编码的重要性体现在:
- 决定染色体排列形式
- 决定个体从搜索空间的基因型变换到解空间的表现型的解码方式
- 影响复制、交叉、变异等遗传算子运算方法和效率
1.2 编码原则
- 编码原则⼀(有意义积⽊块编码原则):应使⽤能易于产⽣与所求问题相关的且具有低阶、短定义⻓度模式的编码⽅案。
- 编码原则⼆(最⼩字符集编码原则):应使⽤能使问题得到⾃然表示或描述的具有最⼩编码字符集的编码⽅案。
1.3 编码方法
1.3.1 二进制编码
汉明悬崖问题:
某些相邻整数的二进制代码之间有很大的汉明距离,使得遗传算法的交叉和突变都难以跨越
- 31的二进制:
011111 - 32的二进制:
100000
Grey Code:
循环二进制码或反射二进制码
-
特点:
连续的两个整数所对应的编码值直接仅仅只有一个码位不相同,其余码位都完全相同
-
优点:
便于提高局部搜索能力;交叉、变异等遗传操作便于实现;符合最小字符集编码原则;便于利用模式定理对算法进行理论分析;相邻的两个码组之间只有⼀位不同,因⽽在模数转换中,当模拟量发⽣微⼩变化⽽可能引起数字量发⽣变化时,格雷码仅改变⼀位,可减少出错的可能性
-
原理:
假设格雷码为 G = g m g m − 1 . . . g 2 g 1 G=g_mg_{m-1}...g_2g_1 G=gmgm−1...g2g1
二进制编码为 B = b m b m − 1 . . . b 2 b 1 B=b_mb_{m-1}...b_2b_1 B=bmbm−1...b2b1
二进制编码到格雷码转换公式为:
g m = b m g i = b i + 1 ⊕ b i , i = m − 1 , m − 2 , m − 3 , . . . , 1 g_m=b_m\\ g_i=b_{i+1}\oplus b_i~~,i=m-1,m-2,m-3,...,1 gm=bmgi=bi+1⊕bi ,i=m−1,m−2,m−3,...,1
也就是从最右边一位起,依次将每一位与左边一位异或,作为对应格雷码该位的值,最左边一位不变 -
举例:
二进制
10011000;Gray码11010100
1.3.2 浮点数编码
个体的每个基因值⽤某⼀范围内的⼀个浮点数来表示;个体的编码⻓度等于其决策变量的个数。因为这种编码⽅法使⽤的是决策变量的真实值,浮点数编码⽅法也叫做真值编码⽅法。
特点(区间范围内)、优(精度高、表示范围较大、搜索空间大、便于混合)缺点详见上一篇blog,不再继续赘述。
1.3.3 符号编码及其他编码
主要优点:
- 符合有意义积⽊块编码原则
- 便于在遗传算法中利⽤所求解问题(TSP)的专⻔知识
- 便于遗传算法与相关近似算法之间的混合使⽤
但是需要认真设计运算操作,满足约束要求。
多参数级联编码
多个决策变量编码,将各个参数分别以某种编码方法进行编码,再将他们的编码按照一定顺序连接在一起。(不同参数不同上下界、不同编码长度或精度)
多参数交叉编码
- 可先对各个参数进⾏分组编码;然后取各个参数编码串中的最⾼位连接在⼀起, 以它们作为个体编码串的前N位编码。
- 长度为M×N(N个参数,每个参数有M位)
- 相当于是将M×N的数组
flatten展平1-n是各个参数第一位编码;n+1到2n是各个参数的第2位编码
二、适应度函数
2.1 函数重要性
- 进化的初期, 通常会产⽣⼀些超常的个体, 若按照⽐例选择法, 这些超常个体会因竞争⼒突出而控制选择过程,影响算法全局优化性能
- 进化的后期:算法接近收敛,适应度差异小,优化潜能降低,可能获得局部最优解
2.2 适应度函数设计原则
- 单值连续非负
- 合理、一致性:适应度值反映解的优劣程度----->难以衡量
- 计算量小:尽可能简单一些,降低计算成本
- 通用性强
2.3 适应度种类
- 求最大值:
fit(x) = { F ( x ) + C m i n if F ( x ) + C m i n ≥ 0 0 otherwise \text{fit(x)}= \begin{cases} F(x)+C_{min}\quad \text{if }\ F(x)+C_{min}\geq0\\ 0\quad \text{otherwise} \end{cases} fit(x)={F(x)+Cminif F(x)+Cmin≥00otherwise
另外也可以:
fit(x) = { 1 1 + C − F ( x ) if C ≥ 0 , C − F ( x ) ≥ 0 0 otherwise \text{fit(x)}= \begin{cases} \frac{1}{1+C-F(x)}\quad \text{if }\ C\geq 0 ~,C-F(x)\geq0\\ 0\quad \text{otherwise} \end{cases} fit(x)={1+C−F(x)1if C≥0 ,C−F(x)≥00otherwise
- 求最小值:
fit(x) = { C m a x − F ( x ) if C m a x − F ( x ) ≥ 0 0 otherwise \text{fit(x)}= \begin{cases} C_{max}-F(x)\quad \text{if }\ C_{max}-F(x)\geq0\\ 0\quad \text{otherwise} \end{cases} fit(x)={Cmax−F(x)if Cmax−F(x)≥00otherwise
另外也可以:
fit(x) = { 1 1 + C + F ( x ) if C ≥ 0 , C + F ( x ) ≥ 0 0 otherwise \text{fit(x)}= \begin{cases} \frac{1}{1+C+F(x)}\quad \text{if }\ C\geq 0 ~,C+F(x)\geq0\\ 0\quad \text{otherwise} \end{cases} fit(x)={1+C+F(x)1if C≥0 ,C+F(x)≥00otherwise
2.4 尺度变换
2.4.1 尺度变换的原因
遗传概率完全由适应度来决定,进使用界限构造法计算个体适应度时,收敛效果并不好。
- 我们希望初期不要有太多超长个体影响整个种群的多样性,要对其进行控制(降低差异度,限制复制数量)
- 后期能对个体适应度进行放大、扩大最佳适应度和其他适应度的差异,提高竞争性
2.4.2 尺度变换方法
1. 线性尺度变换
F ′ = a F + b F a v g ′ = F a v g ( 1 ) F m a x ′ = c F a v g c ∈ [ 1.2 , 2 ] ( 2 ) F'=aF+b\\ F'_{avg}=F_{avg}~~~~(1)\\ F'_{max}=cF_{avg}~~c∈[1.2,2]~~~~(2) F′=aF+bFavg′=Favg (1)Fmax′=cFavg c∈[1.2,2] (2)
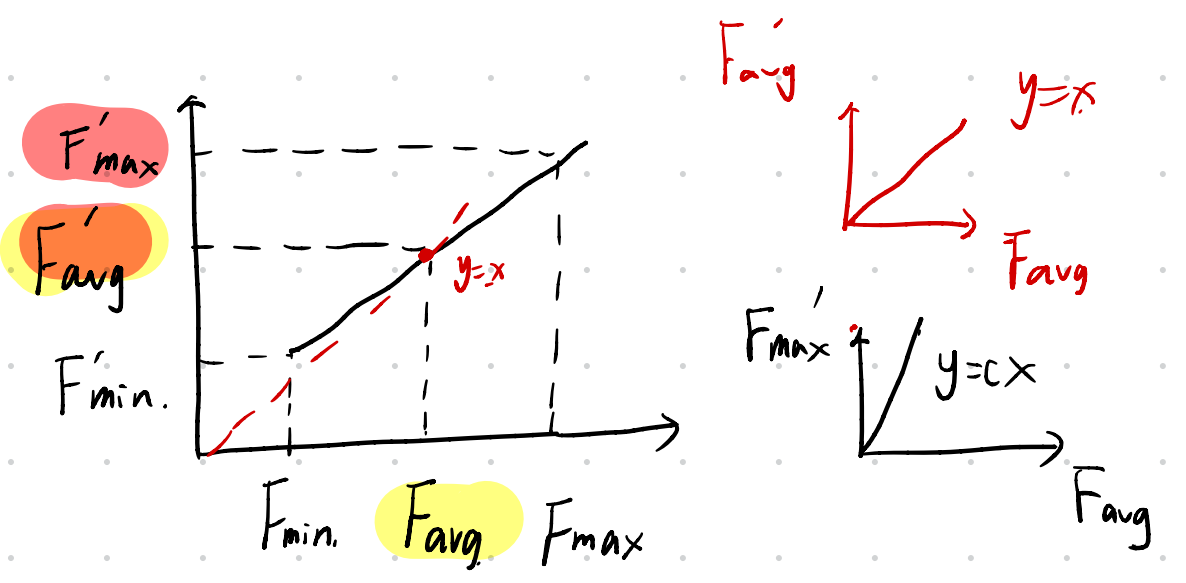
(1) 正常情况放缩
a.适应度非负判别式:
F ’ m i n > 0 a F m i n + b > 0 F’_{min} > 0\\ a F_{min} + b > 0 F’min>0aFmin+b>0
则可得到 F m i n > c F a v g − F m a x c − 1 F_{min}>\frac{cF_{avg}-F_{max}}{c-1} Fmin>c−1cFavg−Fmax
b.求解a,b:
a = c − 1 F m a x − F a v g F a v g b = F m a x − c F a v g F m a x − F a v g F a v g a=\frac{c-1}{F_{max}-F_{avg}}F_{avg}\\ b=\frac{F_{max}-cF_{avg}}{F_{max}-F_{avg}}F_{avg} a=Fmax−Favgc−1Favgb=Fmax−FavgFmax−cFavgFavg
推导也很简单,带入即可,如下图:

(2) 后期为负值
满足 F m i n ′ = 0 F'_{min}=0 Fmin′=0还有变换前后均值相同
推导和结果为
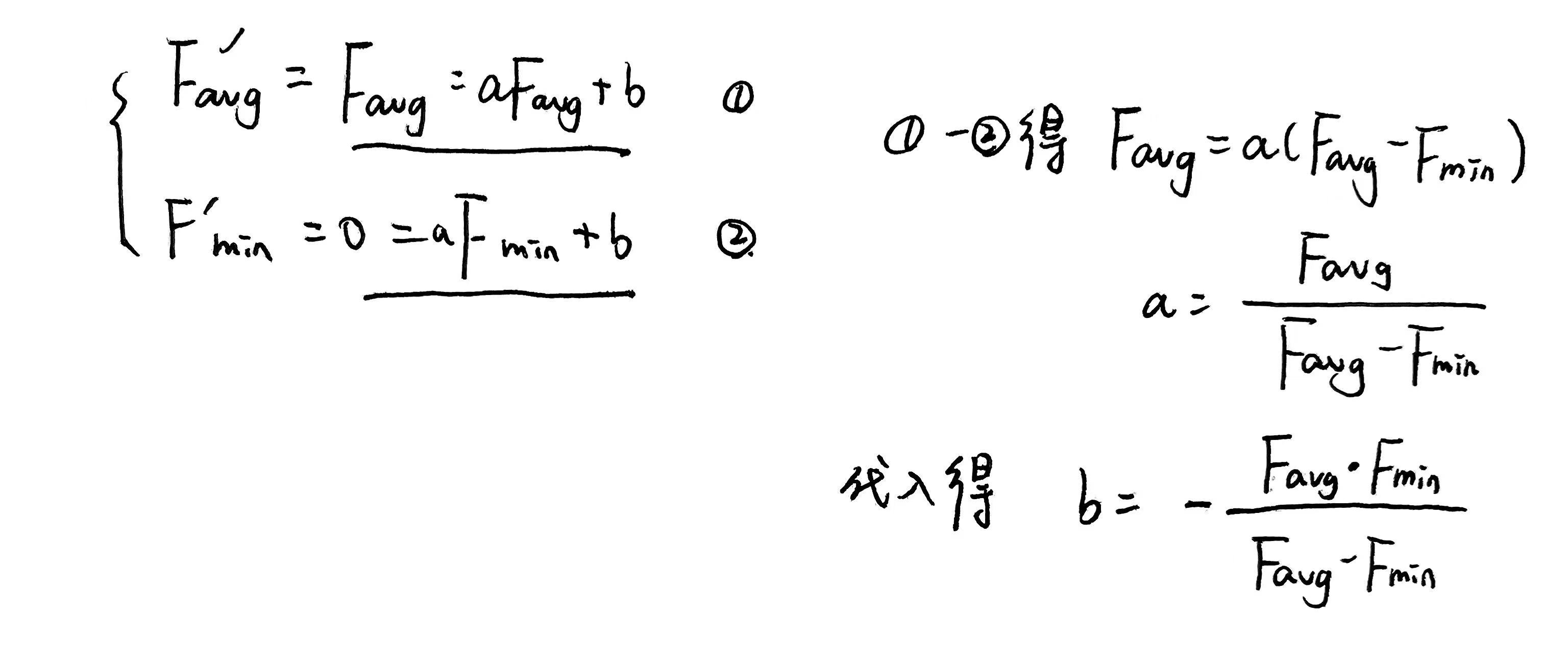
2.乘幂尺度变换
F ′ = F k F'=F^k F′=Fk
3.指数尺度变换
F ′ = e − β F = 1 e β F F'=e^{-βF}=\frac{1}{e^{βF}} F′=e−βF=eβF1
其中, β β β越小,放缩越大,F进化前后期差异越大
三、约束条件处理
3.1 搜索空间限制
对GA的搜索空间的大小加以限制,使得搜索空间中表示一个个体与解空间中表示一个可行解的点有一一对应的关系。->编码上着手(搜索空间=解空间)
- 设置最小的搜索空间,能够提高遗传算法的搜索效率
- 遗传算子之后产生的新个体在解空间也要有对应解而不是无效解
3.2 罚函数
防止出现无效解(搜索空间的个体解码之后的没有对应的可行解),我们可以计算适应度时增加一个罚函数,从而降低该个体适应度
F’(x) = { F ( x ) if x 满足约束条件 F ( x ) − P ( x ) otherwise \text{F'(x)}= \begin{cases} F(x)\quad \text{if x 满足约束条件} \\ F(x)-P(x) \quad \text{otherwise} \end{cases} F’(x)={F(x)if x 满足约束条件F(x)−P(x)otherwise
惩罚项包括:
-
平方法
F = f ( x 1 , x 2 , . . . , x n ) + ∑ i = 1 m [ h i ( x 1 , x 2 , . . . x n ) ] 2 F=f(x_1,x_2,...,x_n)+\sum^m_{i=1}[h_i(x_1,x_2,...x_n)]^2 F=f(x1,x2,...,xn)+i=1∑m[hi(x1,x2,...xn)]2 -
松紧法
F = f ( x 1 , x 2 , . . . , x n ) + K ⋅ ( t T ) p ⋅ f ˉ ∑ i = 1 m d i F=f(x_1,x_2,...,x_n)+K \cdot(\frac{t}{T}) ^p\cdot \bar f\sum^m_{i=1}d_i F=f(x1,x2,...,xn)+K⋅(Tt)p⋅fˉi=1∑mdi
先松后紧
难点:
若罚函数的强度太⼩,部分个体仍有可能破坏约束条件,所以保证不了遗传运算所得到的个体⼀定是满⾜约束条件的⼀个可⾏解;
若罚函数的强度太大,又有可能个体的适应度差异不大,降低了个体间的竞争力,影响算法运行效率
3.3 可行解变换法
基因型到表现型变换中增加使其满⾜约束条件的处理过程。即寻找出⼀种个体基因型和个体表现型之间的多对⼀的变换关系,使进化过程中所产⽣的个体(基因型?)总能够通过这个变换⽽转化成解空间中满⾜约束条件的⼀个可⾏解(表现型?)
缺点:
以扩大搜索空间为代价,运行效率有所下降
四、选择算子
4.1 比例选择
就是我们普通的根据适应度大小来确定的概率选择,但是是随机操作,有时候选择误差较大,不多讲了
4.2分级/排序选择
1.原因:( f f f悬殊)
个别特优个体会多次被选中进⾏复制,经过⼏代后它们在群体中数⽬愈来愈多,冲淡了群体的多样性。因此提出分级的概念,用连续渐变的分级代替数值悬殊的适应度。
2.方法:
-
设群体中有m个个体,降序排序,个体优劣的等级依次为:1,2,3,…,i,…,M
-
等差线性分级 p ( i ) = q − ( i − 1 ) d p(i)=q-(i-1)d p(i)=q−(i−1)d,为什么是这个公式?考虑极端情况即可 i = 1 或 q i=1或q i=1或q
-
等差求和
∑ i = 1 M p ( i ) = M ⋅ q + q − ( M − 1 ) d 2 = 1 解得 q = ( M − 1 ) d 2 + 1 M \sum^M_{i=1}p(i)=M\cdot\frac{q+q-(M-1)d}{2}=1\\解得 q=\frac{(M-1)d}{2}+\frac{1}{M} i=1∑Mp(i)=M⋅2q+q−(M−1)d=1解得q=2(M−1)d+M1d=0: q = 1 M q=\frac{1}{M} q=M1q-(M-1)d=0: q = 2 M q=\frac{2}{M} q=M2
所以q的选择范围是:
1 M ≤ q ≤ 2 M \frac{1}{M}\leq q\leq\frac{2}{M} M1≤q≤M2
优缺点:
优点:消除个体适应度差别悬殊的影响,代替适应度缩放
缺点:抹杀个体适应度实际差别,不能重复运用遗传信息
4.3 竞技选择
操作:
Boostrap不放回抽样M次
t代随机选择k个个体- 比较
k个个体适应度,最大者进入t+1代 - 重复1.2.
M次,直到产生和t代相同数目的个体数
特点:
- 选择的⼒度取决于 k值的⼤⼩。k值愈⼤,每次选出的优胜者具有很⾼的适应度。反之,k值愈⼩,优胜者的适应度或⾼或低,随机性很强。
- 参数k就是tournament size,即参加锦标赛的个体个数,通常当k=2是最常使⽤的⼤⼩ ,也称 Binary Tournament Selection
优势:
- 并行能力强 【不需要对所有适应度值进行排序】
- 复杂度
O(n) - 不易陷入局部最优点
4.4 最优保存策略
保留每⼀代中最优的个体到下⼀代,不参与交叉、变异运算,直接替换掉交叉变异遗传操作后所产生的适应度最低的个体。
操作:
- 找出当前群体中适应度最⾼的个体和适应度最低的个体。
- 更新并记录迄今为止最好的个体~~(若当前群体中最佳个体的适应度⽐总的迄今为⽌的最好个体的适应度还要⾼,则以当前群体中的最佳个体作为新的迄今为⽌的最好个体。)~~
- ⽤迄今为⽌的最好个体替换掉当前群体中的最差个体。
特点:
- (是答案)可保证迄今为⽌所得到的最优个体不会被交叉、变异等遗传运算所破坏,它是遗传算法收敛性的⼀个重要保证条件。
- (不是答案)缺点是它容易使得某个局部最优个体不易被淘汰掉反⽽快速扩散,从⽽使得算法的全局搜索能⼒不强。
使⽤⽅法:
⼀般要与其他选择操作⽅法配合使⽤,才有良好的效果。另外,最优保存策略还可以推⼴,即在每⼀代的进化过程中保留多个最优个体不参加交叉、变异等遗传运算,⽽直接将它们复制到下⼀代群体中。这种选择⽅法也称为稳态复制。
4.5 截断选择
只从种群中选择⼀定⽐例的最好个体作为⽗体,然后均匀随机的对这些⽗体进⾏交叉配对直⾄⼦代个体个数等于种群⼤⼩。
注意:⼀些选择算⼦的步骤或者策略中,涉及交叉或者变异算⼦
4.6 (μ+λ)选择
父代种群的μ个个体使⽤交叉(重组)或变异操作产⽣ λ 个⼦代个体,然后将这 μ+λ 个个体进⾏⽐较再选择 μ (父)个最优者。
4.7 对比总结
| 序号 | 名称 | 特点 | 备注 |
|---|---|---|---|
| 1 | ✅轮盘赌选择 | 选择误差较大 | GA成员 |
| 2 | 随机竞争选择 | 比轮盘赌选择较好 | |
| 3 | ✅最佳保留选择 | 保证迭代终止结果为历代最高适应度个体 | |
| 4 | 无回放随机选择 | 降低选择误差,复制数小于 f/(f+1),操作不方便 | |
| 5 | ✅确定性选择 | 选择误差更小,操作简易 | |
| 6 | 柔性分段复制 | 有效防止基因缺失,但需要选择参数 | |
| 7 | 自适应柔性分段式动态群体选择 | 群体自适应变化,提高搜索效率 | |
| 8 | 无回放式余数随机选择 | 误差最小 | 应用较广 |
| 9 | 均匀排序 | 与适应度大小差异程度正负无关 | |
| 10 | ✔ 稳态复制 | 保留父代中一些高适应度的串 | |
| 11 | 随机联赛选择 | ||
| 12 | 复制评价 | ||
| 13 | ✔ 最优保存策略 | 全局收敛,提高搜索效率,但不宜于非线性强的问题 | |
| 14 | 排挤选择 | 提高群体的多样性 | |
| 15 | ✔ 最优保存策略 | 保证全局收敛 |
五、交叉算子
5.1 单点交叉
⼜称为简单交叉,它是指在个体编码串中只随机设置⼀个交叉点,然后在该点互相交换两个配对个体的部分染色体。
特点:
若邻接基因座之间的关系能提供较好的个体性状和较⾼的个体适应度的话,则这种单点交叉操作破坏这种个体性状和降低个体适应度的可能性最⼩。
5.2 多点交叉
指在个体编码串中随机设置了⼆/多个交叉点,然后再进⾏部分基因交换。
两点操作:
- 在相互配对的两个个体编码串中随机设置两个交叉点。
- 交换两个个体在所设定的两个交叉点之间的部分染⾊体。

多点交叉:

⼀般不⼤使⽤多点交叉算⼦,因为它有可能破坏⼀些好的模式。事实上,随着交叉点数的增多,个体的结构被破坏的可能性也逐渐增⼤。
5.3 均匀交叉
指两个配对个体的每⼀个基因座上的基因都以相同的交叉概率进⾏交换,从⽽形成两个新的个体。均匀交叉实际上可归属于多点交叉的范围
操作:
-
随机产生⼀个与个体编码串⻓度等⻓的由0、1组成的编码串$W = w_1 w_2 … w_i … w_n $, 其中n为个体编码串⻓度。
-
由下述规则从A、B两个⽗代个体中产⽣出新的⼦代个体A’ 、B’ :
-
若 w i = 0 w_i = 0 wi=0,则A’ 在第i个基因座上的基因值继承A的对应基因值,B’ 在第i个基因座上的基因值继承B的对应基因值,即不交换;
-
若 w i = l w_i=l wi=l,则A’ 在第i个基因座上的基因值继承B的对应基因值,B’ 在第i个基因座上的基因值继承A的对应基因值,即交换。
神神叨叨说了这么一长串,举个例子贼简单
举例:

-
5.4 算术交叉
指两个个体的线性组合产生出两个新的个体,为了能够进行线性组合运算,算数交叉的操作对象一般是由浮点数编码所表示的个体。
交叉后的两个新个体为:
{ X A t + 1 = α X B t + ( 1 − ) X A t X B t + 1 = α X A t + ( 1 − α ) X B t \begin{cases} \begin{split} X_A^{t+1}=αX_B^{t}+(1-)X_A^{t}\\ X_B^{t+1}=αX_A^{t}+(1-α)X_B^{t} \end{split} \end{cases} {XAt+1=αXBt+(1−)XAtXBt+1=αXAt+(1−α)XBt
式中,α为常数时,此时进行的交叉运算称为均匀算术交叉;当α为由进化代数所决定的变量时,此时称为非均匀算术交叉。
操作过程:
(1)确定两个个体进行线性组合时的系数α 。
(2)依据上式进行交叉操作产生新个体。
5.5 平坦交叉和线性交叉
平坦交叉
P 1 = ( p 1 1 , p 2 1 , . . . p n 1 ) P 2 = ( p 1 2 , p 2 2 , . . . p n 2 ) C 1 = ( c 1 2 , c 2 2 , . . . c n 2 ) 其中 c i ∈ [ p i 1 , p i 1 ] P_1=(p_1^1,p_2^1,...p_n^1) \\P_2=(p_1^2,p_2^2,...p_n^2)\\ C_1=(c_1^2,c_2^2,...c_n^2)\\其中c_i∈[p_i^1,p_i^1] P1=(p11,p21,...pn1)P2=(p12,p22,...pn2)C1=(c12,c22,...cn2)其中ci∈[pi1,pi1]
线性交叉
c i ′ = 1 2 P i 1 + 1 2 P i 2 c_i'=\frac{1}{2}P_i^1+\frac{1}{2}P_i^2 ci′=21Pi1+21Pi2
六、变异算子
目的:提高局部搜索能力;保持多样性,防止早熟
6.1 基本位变异
对个体编码串中以变异概率 P m P_m Pm随机指定的一个或几个基因座上的基因值做变异
具体操作过程:
- 对个体的每一个基因座,以概率 P m P_m Pm指定为变异点
- 对指定变异点进行变异操作
举例:
在第五个点变异
1010 1 ′ 1 − > 1010 0 ′ 1 10101'1->10100'1 10101′1−>10100′1
6.2 均匀变异
用符合某一范围内均匀分布的随机数,以某一个较小的概率替换个体编码中各个基因座上的原有基因值
具体操作过程:
-
依次指定个体编码串中的每个基因座为变异点。
-
对每一个变异点,以变异概率 P m P_m Pm 从对应基因的取值范围内取一随机数来代替原有基因值。
举例:
设个体为 X = x 1 x 2 x 3 . . . x k . . . x l X = x_ 1 x_2 x_ 3 . . . x_k . . . x_ l X=x1x2x3...xk...xl,若 x k x_k xk为变异点,其取值范围为 [ U m i n k , U m a x k ] [ U _{m i n}^ k , U_{ m a x}^ k ] [Umink,Umaxk] ,在该点对个体 X X X进行均匀变异操作后,可得到一个新的个体 X = x 1 x 2 x 3 . . . x k ′ . . . x l X = x_ 1 x_2 x_ 3 . . . x_k' . . . x_ l X=x1x2x3...xk′...xl,其中变异点的新基因值为:
x ′ k = U min k + r ⋅ ( U max k − U min k ) x^{\prime}{ }_{k}=U_{\min }^{k}+r \cdot\left(U_{\max }^{k}-U_{\min }^{k}\right) x′k=Umink+r⋅(Umaxk−Umink)
式中r为[ 0 , 1 ]范围内符合均匀概率分布的一个随机数。
适用范围:
均匀变异操作特别适合应用于遗传算法的初期运行阶段,它使得搜索点可以在整个搜索空间内自由移动,从而可以增加群体的多样性,使算法处理更多的模式。
6.3 边界变异
咱们直接沿用均匀变异的假设,只是采用了边界值替代:
x k ′ = { U min k if random(0,1)=0 U max k if random(0,1)=1 x_k'= \begin{cases} U_{\min }^{k}\quad \text{if random(0,1)=0} \\ U_{\max }^{k}\quad \text{if random(0,1)=1} \end{cases} xk′={Uminkif random(0,1)=0Umaxkif random(0,1)=1
当变量的取值范围特别宽,并且无其他约束条件时,边界变异会带来不好的影响,但它特别适用于最优点位于或接近于可行解的边界时的一类问题。
均匀变异缺点:
取某一范围内均匀分布的随机数来替换原有基因值,可能使得个体在搜索空间内自由移动;另一方面它却不便于对某一重点区域进行局部搜索。
6.4 非均匀变异
采用对原有基因值作一随机扰动,以扰动后的结果作为变异后的新基因值。对每个基因座都以相同的概率进行运算后,相当于整个解向量在解空间中作了一个轻微的变动。
x k ′ = { x k + Δ ( t , U max k − ν k ) if random(0,1)=0 x k + Δ ( t , ν k − U min k ) if random(0,1)=1 x_k'= \begin{cases} x_{k}+\Delta(t,U_{\max }^{k}-\nu_k)\quad \text{if random(0,1)=0} \\ x_{k}+\Delta(t,\nu_k-U_{\min }^{k})\quad \text{if random(0,1)=1} \end{cases} xk′={xk+Δ(t,Umaxk−νk)if random(0,1)=0xk+Δ(t,νk−Umink)if random(0,1)=1
6.5 高斯变异
是改进遗传算法对重点搜索区域的局部搜索性能的⼀种⽅法。⾼斯变异是指进⾏变异操作时,⽤符合均值为 μ \mu μ、⽅差为 2 的正态分布的⼀个随机数来替换原有基因值。
举例:
假定有12个在[0,1]范围内均匀分布的随机数 r i 其中 ( i = 1 , 2 , … , 12 ) r_i ~其中(i=1,2,…,12) ri 其中(i=1,2,…,12),则符合N( μ \mu μ,2)正态分布的⼀个随机数Q可由下式求得:
Q = μ + σ ( ∑ i = 1 12 r i − 6 ) Q=\mu+\sigma(\sum^{12}_{i=1}r_i-6) Q=μ+σ(i=1∑12ri−6)
这块了解即可:

七、控制参数选择
- 产生新个体方法:交叉,决定全局搜索能力;辅助方法是变异,决定局部搜索能力
- 交叉和变异相互配合,共同完成对搜索空间的全局搜索和局部搜索
八、终止条件
-
最大迭代次数T∈[200,500]
tips:最后一代不一定有最优个体,所以要经常记录每袋的最优个体以便查询比较
-
控制运行时间T
-
规定最小偏差 ∣ f m a x − f ∗ ∣ < ε |f_{max}-f^*|<\varepsilon ∣fmax−f∗∣<ε
只是对于适应度目标已知的遗传算法(比如方差作为适应度计算的曲线拟合问题)
-
观察适应度变化趋势 ∣ f t − f t − 1 ∣ < ε |f_{t}-f_{t-1}|<\varepsilon ∣ft−ft−1∣<ε
初期最优个体的适应度以及群体平均适应度都比较小,随之交叉变异等操作,适应度增大,但是这种增加会趋于缓和或停止。
九、种群多样性
9.1 小生境技术
- 基于预选择:看看父子谁的适应度高,就保留谁到下一代
- 基于排挤:定义排挤因子,取CF=2或3,随机选 1 C F \frac{1}{CF} CF1个个头组成排挤成员,使成员分类
- 基于共享:定义个体间亲密程度 d i , j d_{i,j} di,j,定义个体共享度 S i = ∑ i = 1 n s h ( d i , j ) S_i=\sum^n_{i=1}sh(d_{i,j}) Si=∑i=1nsh(di,j),加入个体适应度 f s ( i ) = f ( i ) s i f_s(i)=\frac{f(i)}{s_i} fs(i)=sif(i)
9.2 早熟
原因:
- 超长个体限制选择算子作用,进化停滞不前
- N过小,交叉操作无法发挥作用,群体很快进入正则化
- 迭代次数不够
- 进化搜索的最终结果对交叉概率和变异概率的取值⾮常敏感,取值不合理就会导致⽆法继续进化⽽早熟。
防止:
- 重启
- 有目的的选择配对个体进行配对策略,拆开相似个体
- 增加交叉操作频率、使用动态适应度函数、使用破坏性的交叉算子
- 排挤模式用新产生的个体去替换父辈中类似的个体。
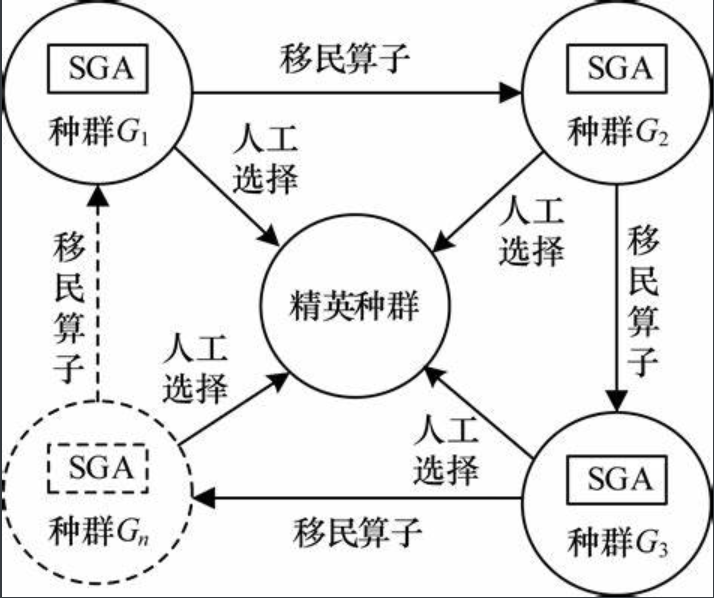
9.3 多种群遗传算法MPGA
- 突破SGA仅靠单个群体进⾏遗传进化的框架,引⼊多个种群同时进⾏优化搜索;不同的种群赋以不同的控制参数,实现不同的搜索⽬的。
- 各个种群之间通过迁移算⼦进⾏联系,实现多种群的协同进化;最优解的获取是多个种群(不同控制参数)协同进化的结果
- 通过⼈⼯选择算⼦保存各种群每个进化代中的最优个体,并作为判断算法收敛的依据。
精华种群:
- 不进⾏选择、交叉、变异等遗传操作,保证进化过程中各种群产⽣的最优个体不被破坏和丢失。
- 是判断算法终⽌的依据,可以采⽤最优个体最少保持代数(超过这个代数最优个体不变就停⽌进化)作为终⽌依据。
太不容易了,主包终于写完了!!!!