ORPO:让大模型调优更简单高效的新范式
ORPO:让大模型调优更简单高效的新范式
想象一下,你刚认识了一位超级学霸,他博览群书,知识储备惊人(就像一个刚完成“预训练”的大语言模型)。但当你跟他交流时,发现他说话有时不着边际,有时get不到你的点,甚至偶尔会说出一些不那么“中听”的话。这时,你就需要对他进行一番“调教”,让他更好地理解你的意图,更得体地表达——这个过程,在人工智能领域,我们就称之为“对齐(Alignment)”。
ORPO(Odds Ratio Preference Optimization,优势比偏好优化)就是一种新兴的、更简洁高效的“调教”方法,它能让这些聪明的AI更好地为我们服务。
一、为什么AI学霸还需要“补课”?—— “对齐”的重要性
我们先来打个比方。一个刚出厂的AI大模型,就像一个刚学完所有课本知识但还没参加过模拟考、也没学过如何与人有效沟通的学生。它潜力巨大,但行为可能还很“原始”:
- 答非所问:你问东,它答西。
- 事实错误:一本正经地胡说八道。
- 带有偏见:不自觉地输出一些不公平或不恰当的观点。
- “不听话”:无法准确遵循你的具体指令。

为了让AI从“原始学霸”变成“贴心助手”,我们就需要进行“对齐”。目标是让AI的行为和输出更符合人类的价值观和期望,变得 有用(Helpful)、无害(Harmless) 和 诚实(Honest)。
二、传统的“补课”方法:复杂但有效的老路子
在ORPO出现之前,主流的“补课”方法主要有这么几板斧:
-
监督微调 (SFT - Supervised Fine-Tuning):
- 是什么:就像给学生一堆标准答案的练习题,让他照着学。我们准备很多“提问-优质回答”的数据对,让AI模型学习模仿这些优质回答。
- 优点:简单直接,能快速教会AI基础的指令遵循能力。
- 缺点:AI只是在“背答案”,并不真正理解为什么这个答案好,那个答案不好。它缺乏辨别能力。
-
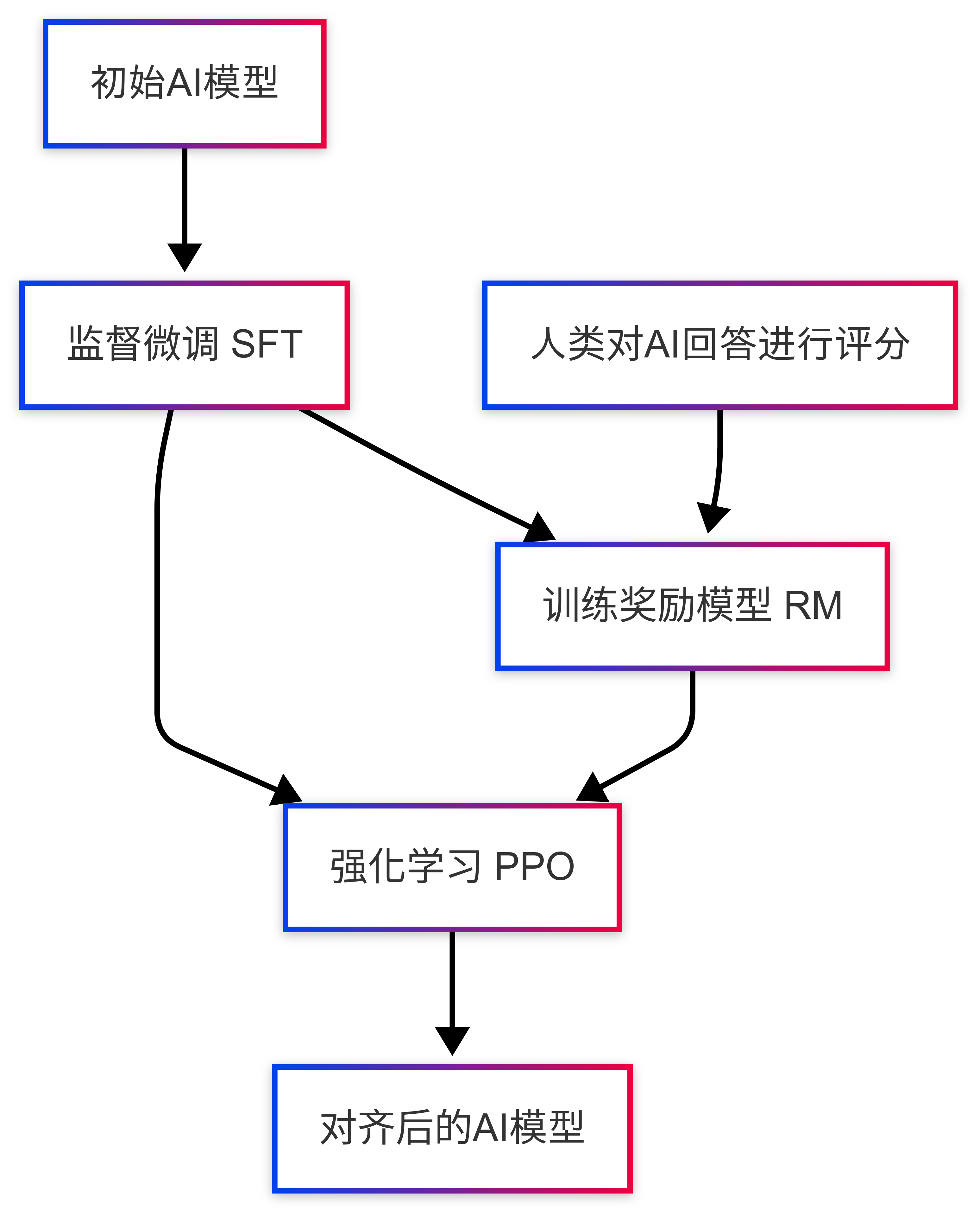
基于人类反馈的强化学习 (RLHF - Reinforcement Learning from Human Feedback):
- 是什么:这套方法更高级,也更复杂。它像是一个多阶段的辅导流程:
- 先SFT打基础:同上,先让模型有个基本概念。
- 训练一个“品味导师”(奖励模型 - Reward Model, RM):找一些人(标注员)来给AI生成的不同答案打分,或者比较哪个答案更好。然后用这些数据训练出一个“品味导师”模型,这个导师能判断AI的回答有多好。
- 强化学习“因材施教”:让AI不断尝试生成回答,然后由“品味导师”给反馈(奖励或惩罚),AI根据这些反馈调整自己,争取获得更高的“导师评分”。常用的强化学习算法是PPO。
- 优点:非常强大,能让AI学会很细致的人类偏好。
- 缺点:流程太长,像发射火箭一样,环节多,调试难,成本高(人力、算力),训练还可能不稳定。
下面是一个RLHF流程的简化图:
- 是什么:这套方法更高级,也更复杂。它像是一个多阶段的辅导流程:
三、能不能简单点?DPO的出现
RLHF虽好,但太麻烦。于是研究者们就在想,能不能绕开训练“品味导师”(奖励模型)和复杂的强化学习步骤呢?
DPO (Direct Preference Optimization - 直接偏好优化) 就应运而生了。
- 核心思想:我们不需要一个独立的“品味导师”。我们可以直接利用人类的偏好数据(比如,对于同一个问题,答案A比答案B好),来直接调整AI模型本身。
- 怎么做(简化版):DPO的目标是让AI模型对于“更好”的答案输出比“更差”的答案更高的概率。但这里有个关键点:它需要一个“参照物”——一个已经SFT过的参考模型 (Reference Model)。DPO在优化时,会确保当前模型相比这个参考模型,更倾向于好的答案。
- 优点:比RLHF简单多了,省去了训练奖励模型和强化学习的步骤。
- 局限:
- 仍然是“两步走”:通常需要先SFT,再DPO。
- 依赖参考模型:训练时需要这个参考模型参与计算,增加了开销。
- 主要关注“相对好坏”:更侧重于让模型知道A比B好,可能对A本身有多好关注不够。
四、ORPO登场:一步到位的“全能教练”
现在,我们的主角ORPO来了!它问了一个更激进的问题:我们能不能把“学习标准答案(SFT)”和“学习偏好(像DPO做的那样)”这两件事合二为一,一步到位,并且还不需要那个额外的参考模型呢?
ORPO说:“可以!”
- 核心思想:ORPO设计了一种新的训练目标,让AI在学习生成“优质回答”的同时,也主动学习“为什么这个回答比另一个要好”,并且明确地拉开与“劣质回答”的差距。这一切都在一个训练阶段完成。
- 打个比方:想象一位健身教练。
- SFT教练:只给你演示标准动作,让你模仿。
- DPO教练:先让你做SFT教练教的动作(参考模型),然后他再告诉你哪个动作比另一个动作更好。
- ORPO教练:他会直接指导你做标准动作,并且如果你做了一个不好的动作,他会立刻指出,并告诉你为什么标准动作更好。一个动作,既学了标准,又辨别了优劣。
五、ORPO的魔法:揭秘“二合一”训练目标
ORPO的精髓在于它那个巧妙的“训练目标”(行话叫损失函数)。对于每一条偏好数据——包含一个提示 (prompt),一个首选回答 (chosen response, y w y_w yw),和一个非首选回答 (rejected response, y l y_l yl)——ORPO会同时关注两件事:
-
目标一:努力生成“首选回答” y w y_w yw (可以理解为SFT的部分)
- 这部分鼓励模型提高生成那个“好答案” y w y_w yw 的概率。模型会因为能更准确、更流畅地生成 y w y_w yw 而受到“奖励”(损失减小)。
- 简单来说,就是:“AI,你要学会说出 y w y_w yw 这个好答案!”
-
目标二:明确区分“首选回答” y w y_w yw 和“非首选回答” y l y_l yl (偏好对齐的部分)
- 这部分的核心是比较模型对 y w y_w yw 和 y l y_l yl 的“喜爱程度”(即生成它们的概率)。
- 如果模型觉得 y w y_w yw 比 y l y_l yl 好得多(即 P ( y w ) ≫ P ( y l ) \text{P}(y_w) \gg \text{P}(y_l) P(yw)≫P(yl)),那么这部分的“惩罚”就很小,接近于0。
- 但如果模型搞反了,觉得 y l y_l yl 比 y w y_w yw 更好,或者对它俩没啥明确态度(比如觉得它俩差不多好),那么模型就会受到一个额外的“惩罚”。这个惩罚会迫使模型调整自己,更明确地“喜欢” y w y_w yw,同时“不喜欢” y l y_l yl。
- 这里的“优势比(Odds Ratio)”概念就体现在如何量化这个“喜欢程度”的差异上。我们希望模型生成 y w y_w yw 的“几率”远大于生成 y l y_l yl 的“几率”。
- 简单来说,就是:“AI,你不仅要会说 y w y_w yw,还要清清楚楚地知道 y w y_w yw 比 y l y_l yl 好得多!”
ORPO的整体训练目标 = (目标一的损失) + λ × \lambda \times λ× (目标二的损失)
这里的 λ \lambda λ (lambda) 是一个调节旋钮,用来平衡这两个目标的重要性。如果 λ \lambda λ 大,模型会更侧重于学习偏好;如果 λ \lambda λ 小,模型会更侧重于把 y w y_w yw 本身学好。通常这个值会设得比较小,比如0.1。
为什么ORPO不需要参考模型了?
因为“目标一”本身就在努力让模型生成好的回答 y w y_w yw,这就像给模型提供了一个内置的“锚点”,防止它在学习偏好(目标二)时跑得太偏,忘记了基本的语言能力和指令遵循能力。
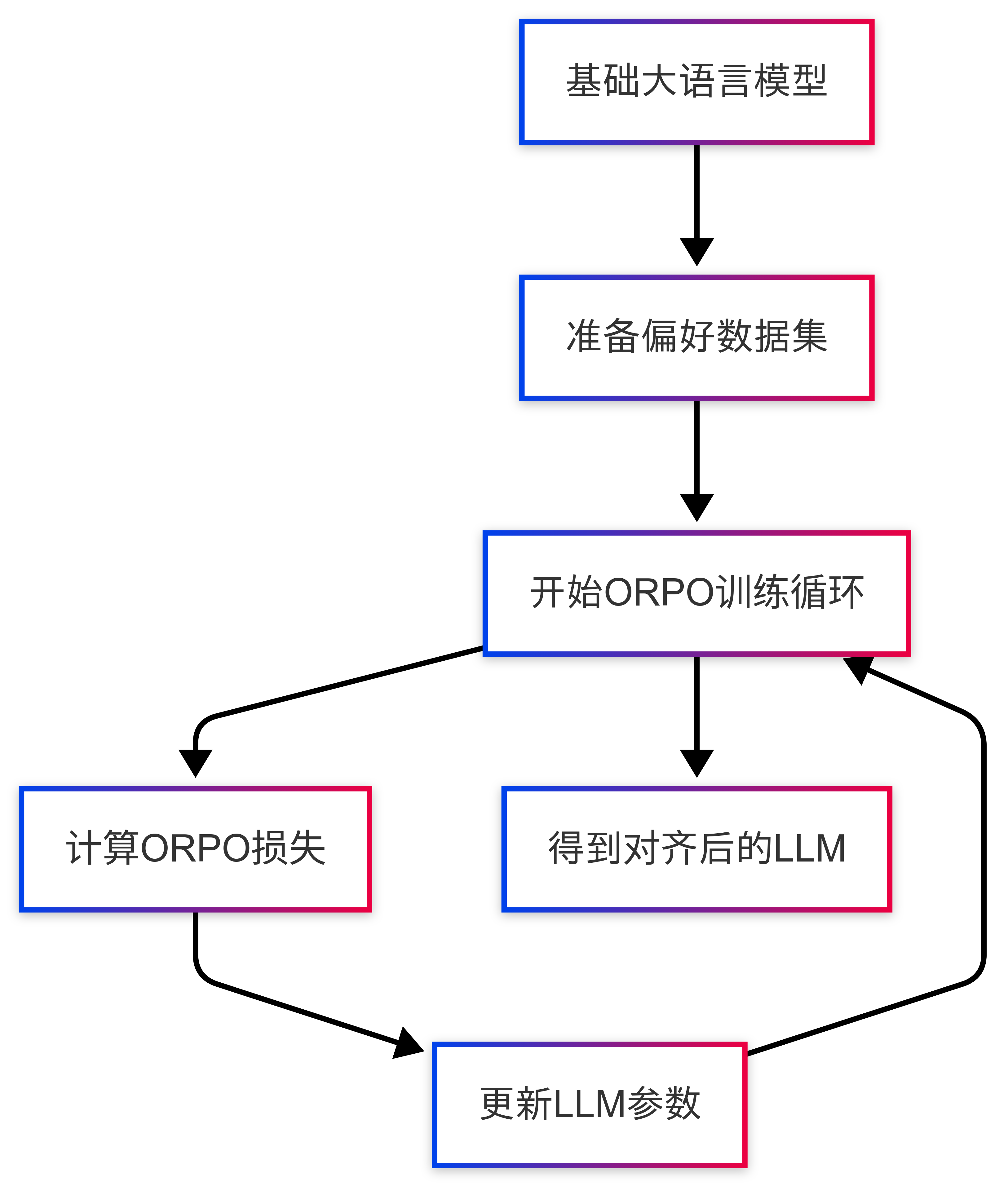
六、ORPO实战演练:从数据到模型
理论听起来不错,那实际操作起来是怎样的呢?
-
准备“教材”:偏好数据集
你需要准备一些数据,每条数据都包含三个部分:prompt: 给AI的指令或问题。chosen: 人类偏好的、较好的回答。rejected: 人类不喜欢的、较差的回答。
数据集格式示例 (JSON格式):
[{"prompt": "请用小学生能听懂的话解释什么是人工智能。","chosen": "想象一下,我们教电脑像人一样思考和学习,比如能和我们聊天、画画、下棋,甚至开车,这就是人工智能,就像给电脑装上了一个聪明的大脑!","rejected": "人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。主要领域包括机器学习、计算机视觉、自然语言处理等。"},{"prompt": "写一首关于春天的短诗。","chosen": "嫩芽初探暖风吹,\n燕语呢喃唤客归。\n桃李芬芳蜂蝶舞,\n春光无限惹人醉。","rejected": "春天来了,花开了,草绿了,天气很好。"} ]这些数据可以来自人工标注(成本高但质量好),也可以利用现有的开源偏好数据集,或者用更强的AI模型来辅助生成。
-
选择“学生”:基础AI模型
你可以选择一个已经预训练好的大语言模型作为起点,比如 Llama、Mistral 等系列的开源模型。有趣的是,ORPO可以直接用这些“原始学霸”开始训练,不一定非要先进行SFT(当然,如果你的起点模型已经SFT过,ORPO也能很好地工作)。 -
开始“上课”:ORPO训练
- 将准备好的 (prompt, chosen, rejected) 数据一批批地喂给AI模型。
- 使用ORPO的“二合一”训练目标(损失函数)来指导模型的学习。
- 模型会不断调整内部参数,努力降低整体损失,也就是同时学会更好地生成
chosen回答,并且显著提高对chosen相对于rejected的偏好程度。
ORPO训练流程图:
七、ORPO vs. DPO:谁更胜一筹?
我们再来清晰地对比一下ORPO和它的前辈DPO:
| 特点 (Feature) | DPO (Direct Preference Optimization) | ORPO (Odds Ratio Preference Optimization) |
|---|---|---|
| 核心思想 | 通过与一个固定的基准AI比较,直接从偏好数据学习策略。 | 将生成优质回答与学习偏好融合在单一训练阶段,无需外部基准。 |
| 训练阶段 | 通常是两阶段:1. 监督微调 (SFT) 得到参考模型;2. DPO微调。 | 单阶段:直接在基础模型上进行ORPO微调,一步到位。 |
| 参考模型 ( π r e f \pi_{ref} πref) | 需要。作为锚点,防止模型在学习偏好时“跑偏”。 | 不需要。其损失函数中对“优质回答”的直接学习部分起到了类似锚点的作用。 |
| 实现复杂度 | 中等。比RLHF简单,但仍需处理参考模型。 | 低。概念和实现都更简洁,组件更少。 |
| 训练开销 (显存/速度) | DPO微调阶段较高,因为需要同时对策略模型和参考模型进行前向计算。 | 较低。因为没有参考模型,训练时计算量和显存占用更少。 |
| SFT的融合方式 | 依赖一个独立的、预先完成的SFT步骤来获得参考模型和初始策略。 | 内置SFT效果。其损失函数的第一部分直接优化了生成“首选回答”的能力,与SFT目标一致。 |
| 优化侧重点 | 更侧重于“相对偏好”(即确保 y w y_w yw 比 y l y_l yl 好),对 y w y_w yw 本身的绝对质量依赖于前置SFT。 | 同时优化 y w y_w yw 的绝对生成质量和相对于 y l y_l yl 的相对偏好。 |
| 数据利用 | 在DPO阶段, y w y_w yw 和 y l y_l yl 主要用于计算偏好差异。 | y w y_w yw 同时用于SFT式的生成学习和偏好学习, y l y_l yl 用于偏好学习。可能更充分地利用了偏好数据中的信息。 |
| 易用性与灵活性 | 步骤略多,对参考模型的选择和管理有一定要求。 | 非常灵活,可以直接从预训练模型开始,简化了整个对齐流程。 |
简单总结一下: ORPO就像是DPO的“青春版”或“威力加强版”,它保留了DPO直接从偏好学习的优点,同时通过巧妙的设计,省去了参考模型,并将SFT的过程融入其中,使得整个对齐流程更加简洁高效。
八、ORPO 为何令人兴奋:优势盘点
-
简单就是美 (Simplicity is King)
- 单刀直入:没有SFT预处理的硬性要求,也没有RLHF里复杂的奖励模型和强化学习算法。整个对齐流程大大简化。
- 容易上手:概念清晰,代码实现也相对直接,对于想要快速尝试模型对齐的开发者非常友好。
-
高效又省钱 (Efficiency Gains)
- 告别参考模型:训练时不需要额外的参考模型参与计算,这意味着更快的训练速度和更低的显存占用。对于计算资源有限的个人开发者或小型团队来说,这简直是福音。
- 一步到位:将SFT和偏好对齐合二为一,减少了整体的训练时间和复杂度。
-
表现不俗 (Strong Performance)
- 研究表明,尽管ORPO设计简洁,但在多个行业标准评测集上(如评估聊天机器人能力的AlpacaEval、MT-Bench,评估模型真实性的TruthfulQA等),它的表现能够与更复杂的DPO甚至RLHF方法相媲美,有时甚至更好。
- 这意味着我们不必总是追求最复杂的方法,简单的设计也能达到很好的效果。
-
“全能型选手”的潜力 (Better All-Rounder from the Start)
- 因为它在学习生成好答案的同时就在学习区分好坏,ORPO训练出来的模型可能从一开始就对“什么是好内容”以及“如何避免坏内容”有更深刻和统一的理解。
九、ORPO虽好,但也要注意几点
没有任何技术是完美的,ORPO也不例外:
-
“教材”质量至上 (Data Quality is Still Crucial)
- ORPO的魔法依赖于高质量的偏好数据 ( p r o m p t , c h o s e n , r e j e c t e d ) (prompt, chosen, rejected) (prompt,chosen,rejected)。如果你的“教材”本身就有问题(比如
chosen的答案其实并不好,或者rejected的答案其实还行),那AI学出来也可能是“歪”的。所谓“垃圾进,垃圾出”。
- ORPO的魔法依赖于高质量的偏好数据 ( p r o m p t , c h o s e n , r e j e c t e d ) (prompt, chosen, rejected) (prompt,chosen,rejected)。如果你的“教材”本身就有问题(比如
-
那个神秘的 λ \lambda λ (The λ \lambda λ Hyperparameter)
- 损失函数中平衡“生成能力”和“偏好能力”的超参数 λ \lambda λ 需要细心调整。设置得不好,可能会导致模型过于偏重一方。这通常需要一些实验来找到最佳值。
-
“新秀”有待考验 (New Kid on the Block)
- 相比于DPO和RLHF,ORPO是一个更新的技术。虽然初期表现惊艳,但它在各种不同类型任务、不同模型规模、不同数据集上的长期表现和鲁棒性,还有待社区进行更广泛和深入的探索与验证。
十、总结:ORPO —— 通往更优AI的“快车道”
ORPO为我们提供了一条更简洁、更高效的路径,来让大型语言模型更好地理解并遵循人类的偏好。它巧妙地将监督学习和偏好学习的目标融合在一个统一的框架内,摆脱了对参考模型的依赖,显著降低了对齐的门槛和成本。
如果你正在寻找一种不那么复杂,但效果依然强大的方法来微调你的AI模型,让它变得更“懂事”、更“有用”,那么ORPO无疑是一个非常值得尝试的新选择。它代表了AI对齐技术向着更实用、更易用的方向迈出的重要一步。