【深度学习与大模型基础】第12章-损失函数与梯度下降
1. 什么是损失函数?
想象你在玩一个“蒙眼飞镖”游戏:
-
目标:把飞镖扔到靶心(正确答案)。
-
每次扔飞镖:你会被告知离靶心有多远(比如“偏左10厘米”)。
-
损失函数就是那个告诉你“误差有多大”的规则。它的作用是量化你的错误程度,帮你下一次扔得更准。
在机器学习中:
-
模型(比如一个预测房价的程序)就像“蒙眼玩家”。
-
损失函数是计算“预测值”和“真实答案”差距的数学公式。
-
模型通过不断减少这个“损失值”来学习(就像你调整飞镖方向)。
2. 机器语言的例子
假设我们用最简单的机器语言(二进制)和逻辑,做一个“预测数字”的任务:
任务
-
输入
x=1,模型输出预测值y_pred,真实答案是y_true=3。 -
损失函数用绝对误差:
Loss = |y_true - y_pred|
机器中的表示(简化版)
import matplotlib.pyplot as plt# 定义输入和输出
x = 1
y_true = 3
y_pred = 2 # 假设的预测值# 计算损失(绝对误差)
loss = abs(y_true - y_pred)# 可视化
plt.figure(figsize=(8, 6))
plt.plot([x], [y_true], 'ro', label='真实值 (y_true)')
plt.plot([x], [y_pred], 'bo', label='预测值 (y_pred)')
plt.title('预测值 vs 真实值')
plt.xlabel('输入 (x)')
plt.ylabel('输出 (y)')
plt.legend()
plt.grid(True)# 添加损失值的文本标注
plt.text(x, y_pred - 0.5, f'Loss: {loss}', fontsize=12, color='green', ha='center')plt.show()
3. 为什么需要损失函数?
-
指导学习:模型通过损失值知道“错得多离谱”(比如损失=2比损失=5更好)。
-
自动调整:模型会反向传播这个误差,调整内部参数(比如把
y_pred从1改成2,损失就从2降到1)。 -
通用规则:不同的任务用不同的损失函数(比如预测房价用均方误差,分类用交叉熵)。
4. 现实类比
-
考试评分:损失函数像“错一题扣1分”,总分(损失)越低说明答得越好。
-
导航系统:如果你走错路,GPS会重新规划路线(像模型根据损失调整方向)。
5. 什么是梯度下降?
现实类比:蒙眼下山
想象你被蒙上眼睛,站在一座山上,目标是用最短路径走到山脚。你会怎么做?
-
策略:用脚试探周围,找到最陡峭的下坡方向,迈一小步。
-
重复:不断试探、迈步,直到踩到平地(最低点)。
梯度下降就是数学版的“蒙眼下山”:
-
山:代表模型的损失函数(预测误差)。
-
你:就是模型的参数(比如线性回归中的权重)。
-
目标:找到损失函数的最低点(误差最小)。
6. 机器语言中的梯度下降
简单任务
假设我们要拟合一条直线 y = w * x(w是参数),用均方误差(MSE)作为损失函数:
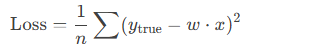
机器指令流程(简化版)
-
初始化参数:
MOV w, 0.0 # 初始权重设为0 -
计算梯度(导数):
梯度公式: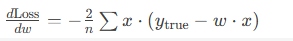
# 假设x=[1,2,3], y_true=[2,4,6], w=0 SUB error1, 2, 0*1 # error1=2 (真实值-预测值) SUB error2, 4, 0*2 # error2=4 SUB error3, 6, 0*3 # error3=6 MUL grad1, error1, 1 # grad1=2*1=2 MUL grad2, error2, 2 # grad2=4*2=8 MUL grad3, error3, 3 # grad3=6*3=18 ADD grad_total, grad1, grad2 ADD grad_total, grad_total, grad3 DIV grad_avg, grad_total, 3 # 梯度平均值= (2+8+18)/3=9.33 -
更新参数(学习率
lr=0.01):MUL delta_w, grad_avg, 0.01 # delta_w=9.33*0.01=0.093 ADD w, w, delta_w # w=0+0.093=0.093 -
重复:用新的
w重新计算梯度和损失,直到梯度接近0。
7. 关键概念
-
梯度(Gradient):
-
就是“最陡的下山方向”(损失函数对参数的导数)。
-
梯度是向量,可以指向多维空间的方向(比如多个参数时)。
-
-
学习率(Learning Rate):
-
每次迈的步长(如
lr=0.01)。 -
太大:可能跨过最低点(发散);太小:下山太慢。
-
-
终止条件:
-
梯度接近0(找到最低点),或达到最大迭代次数。
-
8. 直观图示
复制
下载
损失函数曲线: /\/ \ _________/ \_________ ^| 梯度下降像小球滚下山,最终停在谷底(最优参数w)。
9. 为什么需要梯度下降?
-
自动优化:模型通过梯度下降自动调整参数,无需人工试错。
-
通用性:适用于几乎所有机器学习模型(神经网络、逻辑回归等)。
总结
梯度下降就是:
-
看方向(计算梯度),
-
迈小步(更新参数),
-
反复走(直到最优)。
就像蒙眼下山时,靠脚底感觉坡度找路!