MySQL 查询执行流程全解析
引言
当你在 MySQL 中执行一条 SQL 查询时,背后隐藏着一套精密的协作机制。从解析器到存储引擎,从优化器到执行计划,每个环节都直接影响查询性能。
本文将通过 Mermaid 流程图 和 时序图,完整还原 SQL 查询的执行流程,并深入解析关键环节的优化策略。
一、整体执行流程概览
1.1 核心阶段划分
1.2 关键组件角色
| 组件 | 职责 |
|---|---|
| 解析器 | 将 SQL 转换为抽象语法树(AST) |
| 优化器 | 选择最优执行计划(基于成本模型) |
| 存储引擎 | 实际读取/写入数据(如 InnoDB、MyISAM) |
| 查询缓存 | 缓存结果集(MySQL 8.0 已移除) |
二、详细执行步骤解析
2.1 语法解析与解析树
示例 SQL:
SELECT u.name, o.amount
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.age > 25
ORDER BY o.create_time DESC;
解析树结构(简化版):
2.2 逻辑优化策略
优化器决策树:
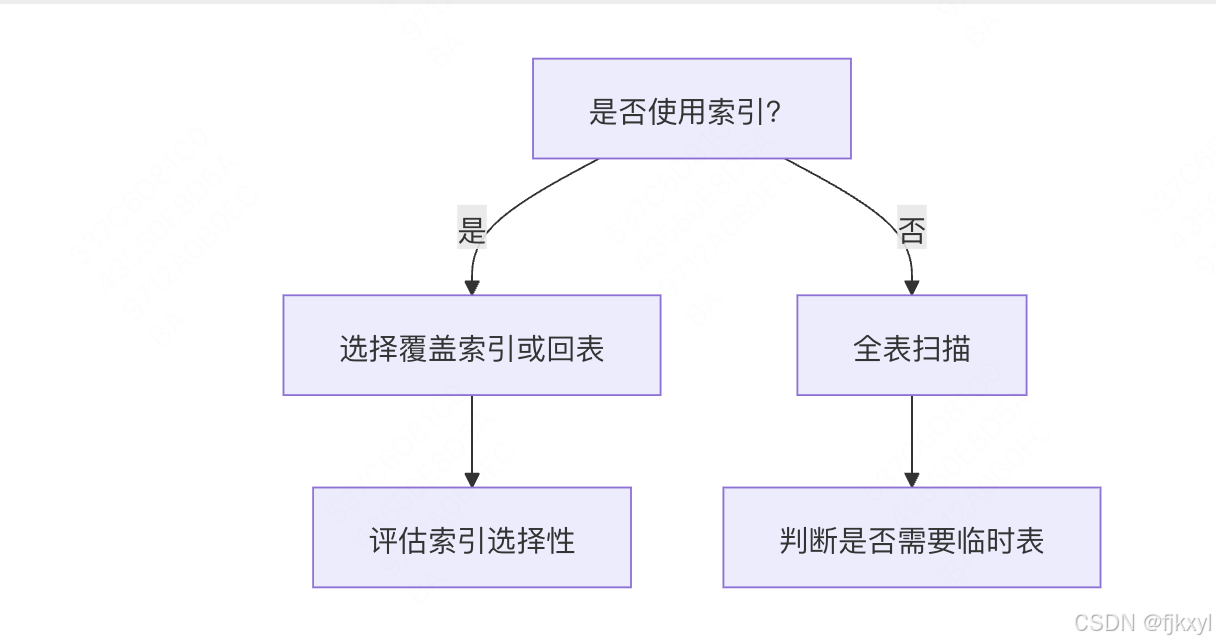
优化器行为示例:
• 索引选择:若 u.age 有索引,优先使用索引范围扫描。
• 连接顺序:小表驱动大表(如 users 表 100 行,orders 表 10 万行 → 先扫描 users)。
三、物理执行流程
3.1 执行计划生成
3.2 存储引擎交互时序
四、关键性能影响因素
4.1 索引使用情况对比
| 场景 | 执行时间 | I/O次数 | 是否回表 |
|---|---|---|---|
| 使用覆盖索引 | 0.1ms | 2次(索引树扫描) | ❌ |
| 使用普通索引+回表 | 0.5ms | 3次(索引+数据页) | ✔️ |
| 全表扫描 | 2.5ms | 10万次数据页读取 | ❌ |
4.2 临时表与文件排序
触发条件:
-- 多字段排序且无复合索引
SELECT * FROM users
ORDER BY create_time DESC, age ASC;
执行流程:
五、实战优化技巧
5.1 索引优化
最左前缀原则应用:
-- 创建联合索引
CREATE INDEX idx_name_age ON users(name, age);-- 有效查询
SELECT * FROM users WHERE name LIKE 'A%' AND age=25;-- 无效查询(跳过name)
SELECT * FROM users WHERE age=25;
5.2 避免临时表
优化前:
SELECT u.name, COUNT(o.id)
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id;
优化后(添加冗余索引):
ALTER TABLE orders ADD INDEX idx_user_id (user_id);
六、诊断工具使用
EXPLAIN 关键字段解读
EXPLAIN SELECT * FROM users WHERE id = 1;
| 字段 | 含义 |
|---|---|
| type | 访问类型(ALL=全表扫描) |
| key | 实际使用的索引 |
| rows | 预估扫描行数 |
| Extra | 是否使用临时表/文件排序 |
总结
MySQL 查询执行流程是 解析 → 优化 → 执行 的精密协作过程。理解以下核心原则可显著提升性能:
- 优先使用覆盖索引,避免回表开销。
- 控制连接条件顺序,利用小表驱动大表。
- 避免隐式类型转换,防止索引失效。
通过结合 EXPLAIN 分析和索引优化,开发者可以高效定位性能瓶颈。下一篇我们将深入探讨 InnoDB 的 MVCC 实现原理,敬请期待!