Spring AI 本地直接运行 Onnx Embedding 模型,结合 Milvus 实现语义向量的存储和检索
一、Huggleface Embedding 模型转为 Onnx 格式
在本专栏上篇文章中,我们介绍了使用 vLLM 私有化部署 Embedding 模型,JAVA 端通过远程API获得Embedding 能力,确实是一个非常不错的方案。但有时候可能期望 JAVA 端能直接运行 Embedding 模型,而不依赖于第三方远程API。为此,SpringAI 早就考虑到了这一点,基于 ONNX Java Runtime 封装了 TransformersEmbeddingModel 可以灵活的运行任何 Huggleface Embedding 模型。
官方文档地址:
https://docs.spring.io/spring-ai/reference/api/embeddings/onnx.html
因为是基于 ONNX Java Runtime 封装而来,所以 Embedding 模型,需要转为 Onnx 格式后进行使用。
将模型转为 Onnx 格式可以借助optimum-cli工具,需要依赖Python 环境,转换过程如下:
安装依赖:
pip install optimum onnx onnxruntime sentence-transformers
转换格式
optimum-cli export onnx --task sentence-similarity --model {转换前的模型地址} {转换后模型存储位置}
仅模型的格式转换依赖Python环境,转换后JAVA端后续运行无需依赖Python环境。
例如,我这里将 bge-small-zh-v1.5 模型转为 onnx 格式
这里我先使用 modelscope 下载 bge-small-zh-v1.5 模型到本地(如果你有魔法连接Huggleface网络正常,则无需先下载,转换时会自动下载)
modelscope download --model=BAAI/bge-small-zh-v1.5 --local_dir BAAI/bge-small-zh-v1.5

下载结束后,转为 Onnx 格式:
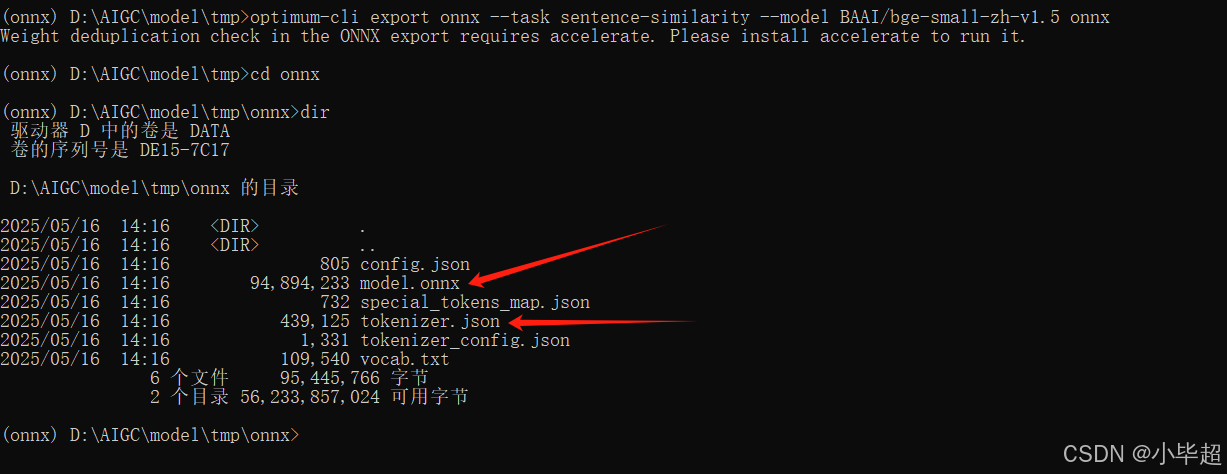
optimum-cli export onnx --task sentence-similarity --model BAAI/bge-small-zh-v1.5 onnx
执行结束后,可以看到转换后的模型,由于是语言模型,这里 tokenizer.json 也是后续需要使用到的。
二、SpringAI 本地运行 Onnx Embedding 模型
新建 SpringBoot 项目,在 pom 中修改如下依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><groupId>com.example</groupId><modelVersion>4.0.0</modelVersion><artifactId>embedding</artifactId><version>0.0.1-SNAPSHOT</version><name>embedding</name><description>embedding</description><properties><java.version>17</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>3.3.0</spring-boot.version><spring-ai.version>1.0.0-SNAPSHOT</spring-ai.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-transformers</artifactId></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><repositories><repository><name>Central Portal Snapshots</name><id>central-portal-snapshots</id><url>https://central.sonatype.com/repository/maven-snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases></repository></repositories><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>17</source><target>17</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring-boot.version}</version><configuration><mainClass>com.example.embedding.EmbeddingApplication</mainClass><skip>true</skip></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build></project>将上面转好后的 model.onnx 和 tokenizer.json 放到项目的 resources 下,具体子路径可自行定义:
2.1 使用 TransformersEmbeddingModel 直接运行Onnx模型
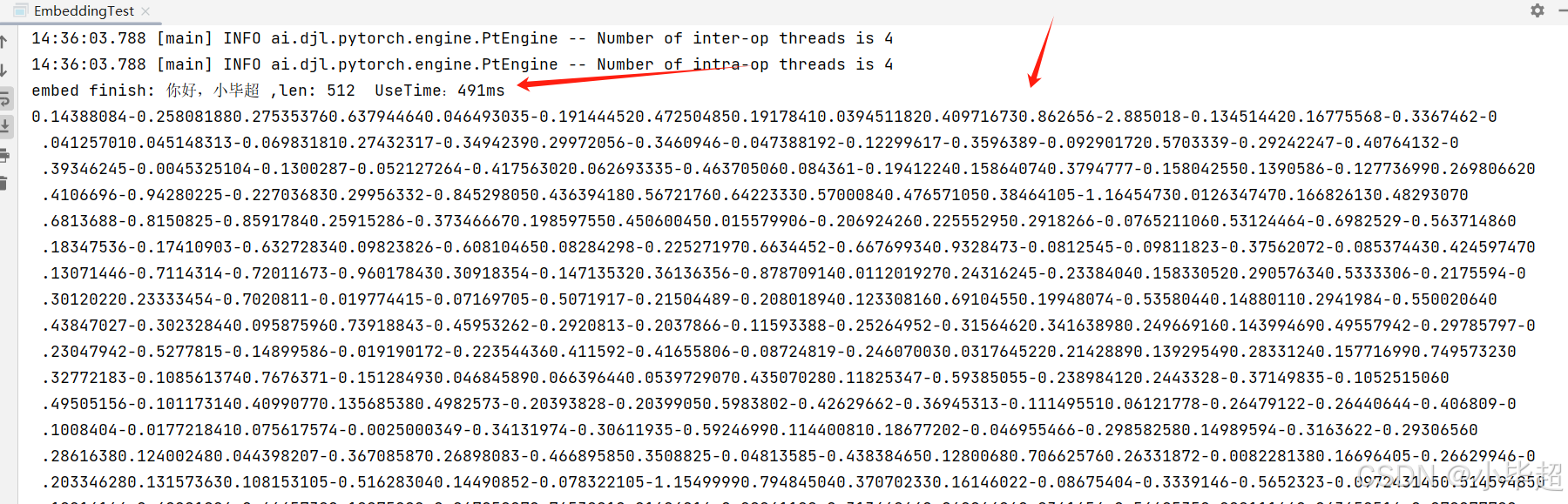
public class EmbeddingTest {public static void main(String[] args) throws Exception {TransformersEmbeddingModel embeddingModel = new TransformersEmbeddingModel();// 设置tokenizer文件路径embeddingModel.setTokenizerResource("classpath:/onnx/bge-small-zh-v1.5/tokenizer.json");// 设置Onnx模型文件路径embeddingModel.setModelResource("classpath:/onnx/bge-small-zh-v1.5/model.onnx");// 缓存位置embeddingModel.setResourceCacheDirectory("/tmp/onnx-cache");// 自动填充embeddingModel.setTokenizerOptions(Map.of("padding", "true"));// 模型输出层的名称,默认是 last_hidden_state, 需要根据所选模型设置embeddingModel.setModelOutputName("token_embeddings");embeddingModel.afterPropertiesSet();String text = "你好,小毕超";long t = System.currentTimeMillis();// 生成文本嵌入向量float[] embed = embeddingModel.embed(text);long useTime = System.currentTimeMillis() - t;System.out.println("embed finish: " + text + " ,len: " + embed.length + " UseTime:" + useTime + "ms");for (float f : embed) System.out.print(f);}
}
运行后可以看到处理后的结果,可以看到模型输出的维度是512维,CPU的平均处理时间为 500ms 左右。
2.2. 在 Spring 中通过配置的方式运行
修改 application.yml 文件,加入如下配置:
spring:ai:embedding:transformer:onnx:modelUri: classpath:/onnx/bge-small-zh-v1.5/model.onnxmodelOutputName: token_embeddingstokenizer:uri: classpath:/onnx/bge-small-zh-v1.5/tokenizer.json
文本向量化处理:
@SpringBootTest
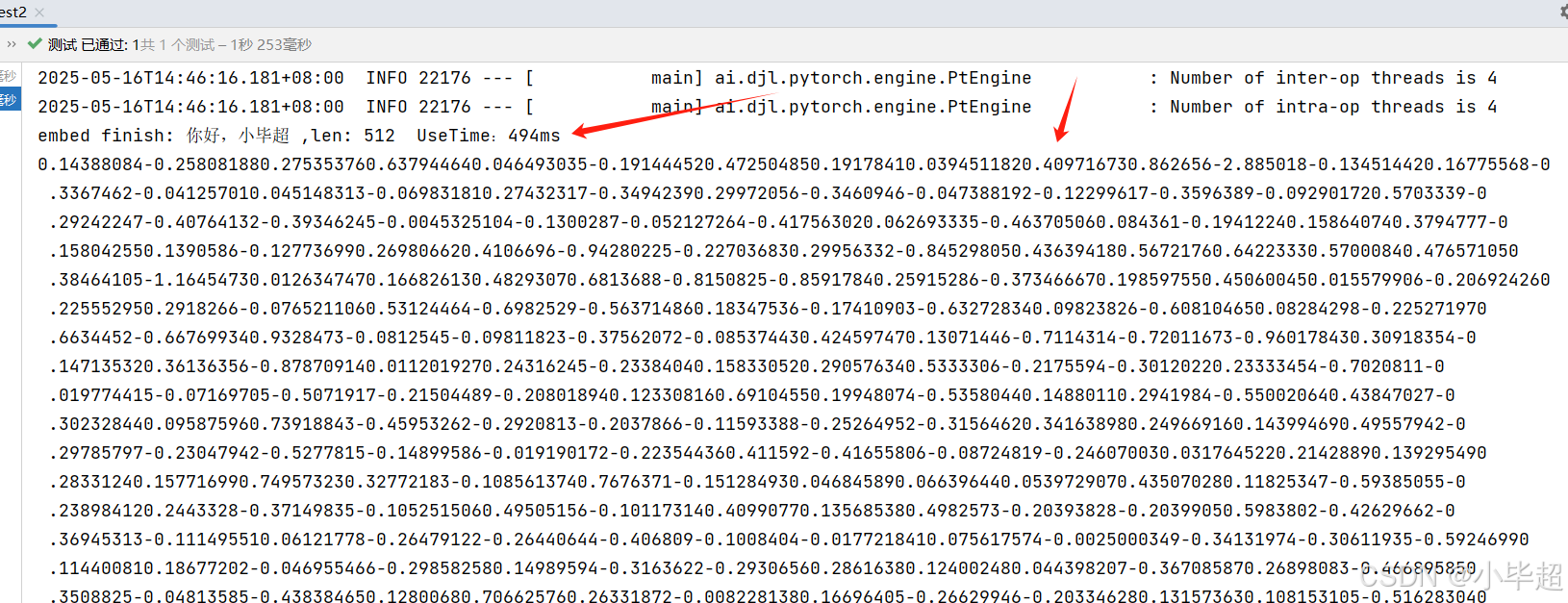
public class EmbeddingTest2 {@Resourceprivate EmbeddingModel embeddingModel;@Testvoid contextLoads() {String text = "你好,小毕超";long t = System.currentTimeMillis();float[] embed = embeddingModel.embed(text);long useTime = System.currentTimeMillis() - t;System.out.println("embed finish: " + text + " ,len: " + embed.length + " UseTime:" + useTime + "ms");for (float f : embed) System.out.print(f);}}
运行后可以看到如下结果
三、结合 Milvus 实现向量存储和检索
需要提前部署好 Milvus 向量数据库,如果没有安装,可参考下面文章部署:
Milvus 向量数据库介绍及使用
Spring AI 关于 Milvus 的操作文档如下:
https://docs.spring.io/spring-ai/reference/api/vectordbs/milvus.html#milvus-properties
在 pom 中增加 Milvus 依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>
application.yml 中添加 Milvus 的链接信息:
spring:ai:embedding:transformer:onnx:modelUri: classpath:/onnx/bge-small-zh-v1.5/model.onnxmodelOutputName: token_embeddingstokenizer:uri: classpath:/onnx/bge-small-zh-v1.5/tokenizer.jsonvectorstore:milvus:client:host: 127.0.0.1port: 19530username: "root"password: "milvus"databaseName: "default"collectionName: "vector_onnx"embeddingDimension: 512indexType: IVF_FLATmetricType: COSINEinitialize-schema: true
注意这里模型的维度是 512 维,上面测试的时候已经提到了。
3.1 内容持久化至向量库中
@SpringBootTest
class MilvusTests {@ResourceVectorStore vectorStore;@Testvoid toMinvus() {List<Document> documents = List.of(new Document("我的爱好是打篮球", Map.of("name", "张三", "age", 18)),new Document("我的爱好的是学习!", Map.of("name", "李四", "age", 30)),new Document("今天的天气是多云", Map.of("name", "王五", "age", 50)),new Document("我的心情非常愉悦", Map.of("name", "赵六", "age", 25)),new Document("我叫小毕超", Map.of("name", "小毕超", "age", 28)));vectorStore.add(documents);}
}
运行后,可在 Milvus 中看到自动创建的 collection:
3.2 语义内容检索
@SpringBootTest
class MilvusTests {@ResourceVectorStore vectorStore;@Testvoid similarity() {List<Document> results = vectorStore.similaritySearch(SearchRequest.builder().query("你叫什么名字").topK(3).similarityThreshold(0.2).build());Optional.ofNullable(results).ifPresent(res->{res.forEach(d -> System.out.println(d.getText()+" "+d.getMetadata()));});}
}
