车道线检测----Lane-ATT

本文针对车道线检测----Lane-ATT论文所有细节进行阐述,有帮助的话点个收藏关注吧
保持对车道的关注:注意力引导的车道检测
摘要
但许多方法在保持实时效率方面存在问题,这对于自动驾驶车辆至关重要。在本文中,我们提出了LaneATT:一种基于锚框的深度车道检测模型,与其他通用深度目标检测器类似,它在特征池化步骤中使用锚框。由于车道遵循规则的模式并且高度相关,我们假设在某些情况下全局信息对于推断它们的位置至关重要,特别是在遮挡、车道标记缺失等条件下。因此,我们提出了一个新的基于锚框的注意力机制,用于聚合全局信息。
1. 引言
用于现实场景的模型应能抵御多种不利条件,如极端的光照和天气条件。此外,车道标记可能会被其他物体(例如汽车)遮挡,这对于自动驾驶汽车来说是一个非常常见的案例。一些方法,如多项式回归模型,可能还会受到长尾效应引起的数据不平衡问题的困扰,因为曲线更为明显的案例较为少见。此外,模型不仅要稳健,还要高效。在许多应用中,车道检测应在实时环境中执行,这是许多模型难以应对的要求。由于该任务对于自动驾驶汽车的发展至关重要,文献中有许多关于此问题的工作。在深度学习出现之前,几种方法采用了更传统的计算机视觉技术,例如霍夫线[3, 1]。随着卷积神经网络(CNN)的发展,研究重点转向了深度学习方法[12, 16, 10, 17]。通常,车道检测问题被表述为一个分割任务,其中,给定输入图像,输出是具有每个像素预测的分割图[16]。尽管深度学习的最新进展使得分割网络能够实时工作[21],但各种模型在实时工作方面仍存在困难。因此,分割方法的骨干选项相当有限。因此,一些近期的工作提出了其他方向的解决方案[12, 22]。此外,车道检测工作中还有其他常见问题,例如需要后处理步骤(通常是启发式方法)、较长的训练时间以及缺乏源代码,这阻碍了比较和可重复性。在本文中,我们介绍了一种比大多数现有最先进方法更快、更准确的车道检测方法。我们提出了一个名为LaneATT的基于锚框的单阶段车道检测模型。其架构使得使用轻量级骨干CNN成为可能(例如ResNet-34[8]),同时保持高精度。我们还提出了一个新的基于锚框的注意力机制,用于聚合全局信息。在[ ]上展示了广泛实验结果,包括与最先进方法的比较、效率权衡讨论以及我们设计选择的消融研究。总结来说,我们的主要贡献是:
-
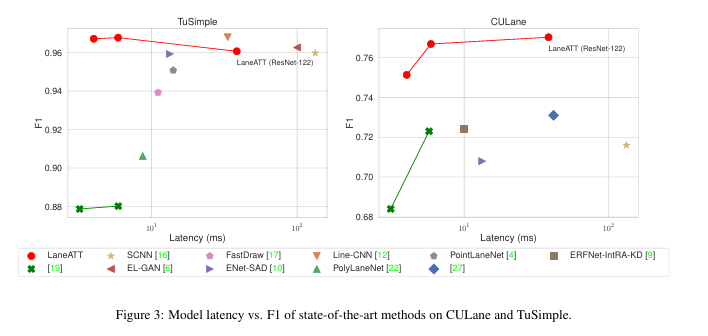
一种在训练和推理时间上比大多数其他模型更快的模型(达到250 FPS,比之前最高精度方法的MACs少了一个数量级);
-
一种新的基于锚框的注意力机制,可能在其他被检测物体相关的领域有用。
2. 相关工作
尽管最初的车道检测方法依赖于经典计算机视觉,但深度学习方法在准确性和效率方面取得了实质性进展。因此,本综述重点关注深度车道检测器。我们首先讨论基于分割的方法[16, 10, 28, 14]或逐行分类方法[9, 19, 26],然后回顾其他方向的解决方案。最后讨论了车道检测工作中缺乏可重复性(一个常见问题)。
基于分割的方法
这种方法基于每个像素进行预测,将每个像素分类为车道或背景。生成分割图后,需要后处理步骤将其解码为车道集合。在SCNN[16]中,作者提出了一种专门设计用于长薄结构的方案,并展示了其在车道检测中的有效性。然而,该方法速度较慢(7.5 FPS),限制了其在现实场景中的应用。由于较大的骨干网络是速度较慢的主要原因,作者在[10]中提出了一种自注意力蒸馏(SAD)模块来聚合上下文信息,从而允许使用更轻量级的骨干网络,在保持实时效率的同时实现高性能。在CurveLanes-NAS[25]中,作者提出使用神经架构搜索(NAS)来寻找更好的骨干网络。尽管他们在数据集上取得了最先进的结果,但其NAS计算成本极高,每个数据集需要5000 GPU小时。
其他方法
其他方法也在之前的工作中被提出。例如,在FastDraw[17]中,作者提出了一种新的基于学习的方法来解码车道结构,避免了基于分割和逐行分类方法所需的聚类后处理步骤。尽管所提出的方法被证明能够达到高速,但其在准确性方面并未超越现有的最先进方法。同样的效果在PolyLaneNet[22]中也得到展示,其中提出了一个更快的基于深度多项式回归的模型。在这种方法中,模型学习为每个车道输出一个多项式。尽管其速度快,但该模型在处理数据集不平衡方面存在困难,如其预测对直线车道的高偏差所示。在Line-CNN[12]中,提出了一种基于锚框的车道检测方法。该模型在公共数据集上取得了最先进的结果,并在另一个未公开的数据集上取得了有希望的结果。尽管具有实时效率,但该模型比其他方法慢得多。此外,由于代码未公开,结果难以重现。还有些工作专注于车道检测流程的其他部分。在[11]中,提出了一种专注于遮挡案例的后处理方法,其结果比其他工作高出许多,但其速度显著较低(大约4 FPS)。为了提高夜间图像的结果,刘等[14]提出使用生成对抗网络(GAN)将日间图像生成夜间图像用于训练。
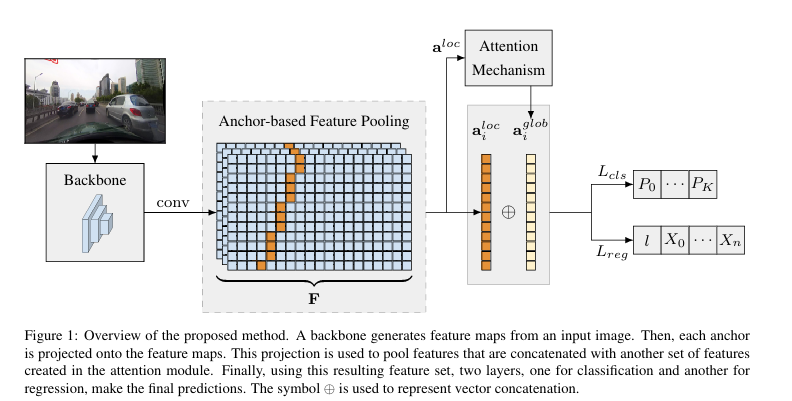
Lcls负责预测锚框属于K种车道类型或背景类的概率,输出为K+1个概率值。Lreg则输出车道提议的长度和Npts个偏移量,这些偏移量表示预测的车道位置与锚框之间的水平距离。
定义了一些锚框,这些锚框是根据车道线可能出现的位置和形状预先设定的
对于每个锚框,我们把它投影到特征图F上,特征图F是由骨干网络生成的,包含了图像的高层次特征。
我们从特征图F中提取与锚框相交的点的特征,这些特征组成了局部特征向量。比如,锚框i对应的局部特征向量就是特征图F中与锚框i相交的点的特征组合。
注意力模块先接收所有锚框的局部特征向量。
它通过一个全连接层处理这些局部特征向量,为每个锚框生成一组权重。这些权重表示每个锚框的信息在全局范围内的相对重要性。
这些权重被用来组合所有锚框的局部特征,生成全局特征向量。全局特征向量综合了所有锚框的信息,使得模型在预测车道线时,不仅能考虑到局部信息,还能参考全局的上下文信息。
3. 提出的方法
LaneATT是一个基于锚框的单阶段模型(类似于YOLOv3[20]或SSD[15]),用于车道检测。方法概述如图1所示。它接收来自车辆前视相机的RGB图像I∈R3×HI×WI作为输入。输出是车道边界线(以下遵循文献中的常规术语称为车道)。为了生成这些输出,卷积神经网络(CNN),称为骨干网络,生成特征图,然后通过池化过程提取每个锚框的特征。这些特征与注意力模块生成的一组全局特征相结合。通过结合局部和全局特征,模型可以更容易地使用来自其他车道的信息,这在遮挡或车道标记不可见等情况下可能是必要的。最后,将组合特征传递给全连接层以预测最终的输出车道。

3.2 骨干网络
所提方法的第一阶段是特征提取,可以由任何通用CNN(如ResNet[8])执行。该阶段的输出是从中提取每个锚框特征的特征图Fback∈RC′F×HF×WF。为了降低维度,在Fback上应用1×1卷积,生成通道压缩后的特征图F∈RCF×HF×WF。进行此压缩是为了降低计算成本。

3.4 注意力机制

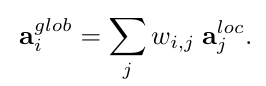
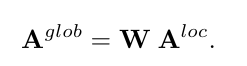
3.5 提议预测
为每个锚框预测车道提议,包括三个主要组成部分:(i)K+1个概率(K种车道类型和一个用于“背景”或无效提议的类别),(ii)Npts个偏移量(预测与锚框线之间的水平距离),以及(iii)提议的长度l(有效偏移量的数量)。提议的起始索引(s)直接由锚框的原点y坐标(yorig,见第3.1节)确定。因此,结束索引可以确定为e=s+⌊l⌋−1。为了生成最终提议,通过连接aloc•和aglob•来聚合局部和全局信息,生成增强特征向量aaug•∈RNanc×2⋅CF⋅HF。此增强向量被输入到两个并行全连接层,一个用于分类(Lcls),另一个用于回归(Lreg),以产生最终提议。Lcls负责预测pi,即K+1个概率(项目i),而Lreg输出ri,即l和Npts个偏移量(项目ii和iii)。









最后经过nms就是最终的结果 nms根据提议间距是否小于阈值来进行筛选