Xinference推理框架
概述
GitHub,官方文档。
核心优势
- 性能优化:通过vLLM、SGLang等引擎实现低延迟推理,吞吐量提升2-3倍;
- 企业级支持:支持分布式部署、国产硬件适配及模型全生命周期管理;
- 生态兼容:无缝对接LangChain、LlamaIndex等开发框架,加速AI应用构建。
特性:
- 全面且高效的模型管理
提供模型全生命周期管理功能,从模型导入、版本控制到部署上线,一切尽在掌握。还支持100+最新开源模型,涵盖文本、语音、视频以及embedding/rerank等多个领域,确保用户能够快速适配并使用最前沿的模型。 - 多推理引擎与硬件兼容
为了最大化推理性能,优化多种主流推理引擎,包括vLLM、SGLang、TensorRT等。广泛支持多种硬件平台,无论是国际品牌还是国产GPU(如华为昇腾、海光等),都能实现无缝对接,共同服务于AI推理任务。 - 高性能与分布式架构
借助底层算法优化和硬件加速技术,实现高性能推理。其原生分布式架构更是如虎添翼,支持水平扩展集群,轻松应对大规模数据处理需求。多种调度策略的应用使得Xinference能够灵活适应低延迟、高上下文、高吞吐等不同场景。 - 丰富的企业级特性
除了强大的推理能力外,提供众多企业级特性以满足复杂业务需求。这包括用户权限管理、单点登录、批处理、多租户隔离、模型微调以及全面的可观测性等。这些特性使得Xinference在保障数据安全与合规性的同时,也大大提升业务运营的效率与灵活性。
核心功能模块:
- 聊天&生成:大语言模型(LLM)
- 内置模型:支持Qwen、ChatGLM3、Vicuna、WizardLM等主流开源模型,涵盖中英文及多语言场景;
- 长上下文处理:优化高吞吐量推理,支持超长文本对话、代码生成及复杂逻辑推理;
- 函数调用:为Qwen、ChatGLM3等模型提供结构化输出能力,支持与外部API交互(如天气查询、代码执行),赋能智能体开发。
- 多模态处理
- 视觉模块
图像生成:集成Stable Diffusion等模型,支持文本到图像生成;
图文理解:通过多模态大模型(如Qwen-VL)实现图像描述、视觉问答等任务。 - 音频模块
语音识别:支持Whisper模型,实现语音转文字及多语言翻译;
语音生成(实验):探索文本到语音(TTS)能力,支持自定义音色生成。 - 视频模块(实验)
视频理解:基于多模态嵌入技术解析视频内容,支持片段检索与摘要生成。
- 视觉模块
- 嵌入&重排序
- 嵌入模型
文本/图像向量化:支持BGE、M3E等模型,生成跨模态统一语义向量;
应用场景:优化搜索、推荐系统的召回精度,支持混合模态检索。 - 重排序模型
精细化排序:通过交叉编码器优化检索结果排序,提升Top-K准确率。
- 嵌入模型
内置模型清单
| 模型类型 | 代表模型 | 关键特性 |
|---|---|---|
| 大语言模型 | Qwen-72B、ChatGLM3-6B、Vicuna-7B | 支持函数调用、长上下文、多轮对话 |
| 嵌入模型 | BGE-Large、M3E-Base | 跨模态语义对齐、低延迟推理 |
| 图像模型 | Stable Diffusion XL、Qwen-VL | 文生图、图像描述、视觉问答 |
| 音频模型 | Whisper-Large、Bark(实验) | 语音识别、多语言翻译、TTS生成 |
| 重排序模型 | bge-reranker-large | 动态调整检索结果排序 |
| 视频模型 | CLIP-ViT(实验) | 视频内容解析、跨模态检索 |
版本
| 功能 | 企业版本 | 开源版本 |
|---|---|---|
| 用户权限管理 | 用户权限、单点登录、加密认证 | tokens授权 |
| 集群能力 | SLA调度、租户隔离、弹性伸缩 | 抢占调度 |
| 引擎支持 | 优化过的vLLM、SGLang、TensorRT | vLLM、SGLang |
| 批处理 | 支持大量调用的定制批处理 | 无 |
| 微调 | 支持上传数据集微调 | 无 |
| 国产GPU支持 | 昇腾、海光、天数、寒武纪、沐曦 | 无 |
| 模型管理 | 可私有部署的模型下载和管理服务 | 依赖ModelScope和HuggingFace |
| 故障检测和恢复 | 自动检测节点故障并进行故障复位 | 无 |
| 高可用 | 所有节点都是冗余部署支持服务高可用 | 无 |
| 监控 | 监控指标API接口,和现有系统集成 | 页面显示 |
| 运维 | 远程cli部署、不停机升级 | 无 |
| 服务 | 远程技术支持和自动升级服务 | 社区支持 |
安装
# 安装所有
pip install "xinference[all]"
# Transformers 引擎
pip install "xinference[transformers]"
# vLLM引擎
pip install "xinference[vllm]"
# Llama.cpp 引擎
pip install xinference
pip install xllamacpp --force-reinstall --index-url https://xorbitsai.github.io/xllamacpp/whl/cu124
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# SGLang 引擎
pip install "xinference[sglang]"
# MLX引擎
pip install "xinference[mlx]"
运行
本地运行:
conda create --name xinference python=3.10
conda activate xinference
# 启动命令
xinference-local --host 0.0.0.0 --port 9997
# 启动模型命令
xinference engine -e http://0.0.0.0:9997 --model-name qwen-chat
# 其他参考
xinference launch --model-name <MODEL_NAME> \[--model-engine <MODEL_ENGINE>] \[--model-type <MODEL_TYPE>] \[--model-uid <MODEL_UID>] \[--endpoint "http://<XINFERENCE_HOST>:<XINFERENCE_PORT>"]
集群部署:
# 启动 Supervisor 用当前节点的 IP 来替换`${supervisor_host}`
xinference-supervisor -H "${supervisor_host}"
# 启动Worker
xinference-worker -e "http://${supervisor_host}:9997" -H "${worker_host}"
Docker部署:
# 英伟达显卡机器
docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9998:9997 --gpus all xprobe/xinference:<your_version> xinference-local -H 0.0.0.0 --log-level debug
# 只有CPU机器
docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9998:9997 xprobe/xinference:<your_version>-cpu xinference-local -H 0.0.0.0 --log-level debug
启动完成可在http://${supervisor_host}:9997/ui访问Web UI:
打开http://${supervisor_host}:9997/docs访问API文档:
部分API截图:
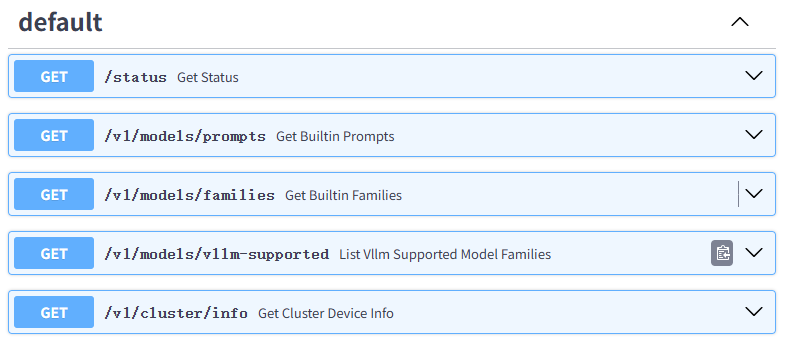
API
如上图,接口列表中包含大量接口,不仅有LLM模型的接口,还有其他模型(如Embedding或Rerank)的接口,都是兼容OpenAI API的接口。可使用Curl工具来调用其接口,示例如下:
curl -X 'POST' \'http://localhost:9997/v1/chat/completions' \-H 'Content-Type: application/json' \-d '{"model": "chatglm3","messages": [{"role": "user","content": "hello"}]}'
不同模型可使用不同的requestBody参数,但是大多都是类似的:
{"model": "deepseek-r1-distill-qwen-32b-awq","messages": [{"role": "user","content": "你是谁"}],"temperature": 0.1,"top_p": 0.6,"stream": true,"stop": ["<|im_end|>","<|endoftext|>"]
}
模型部署
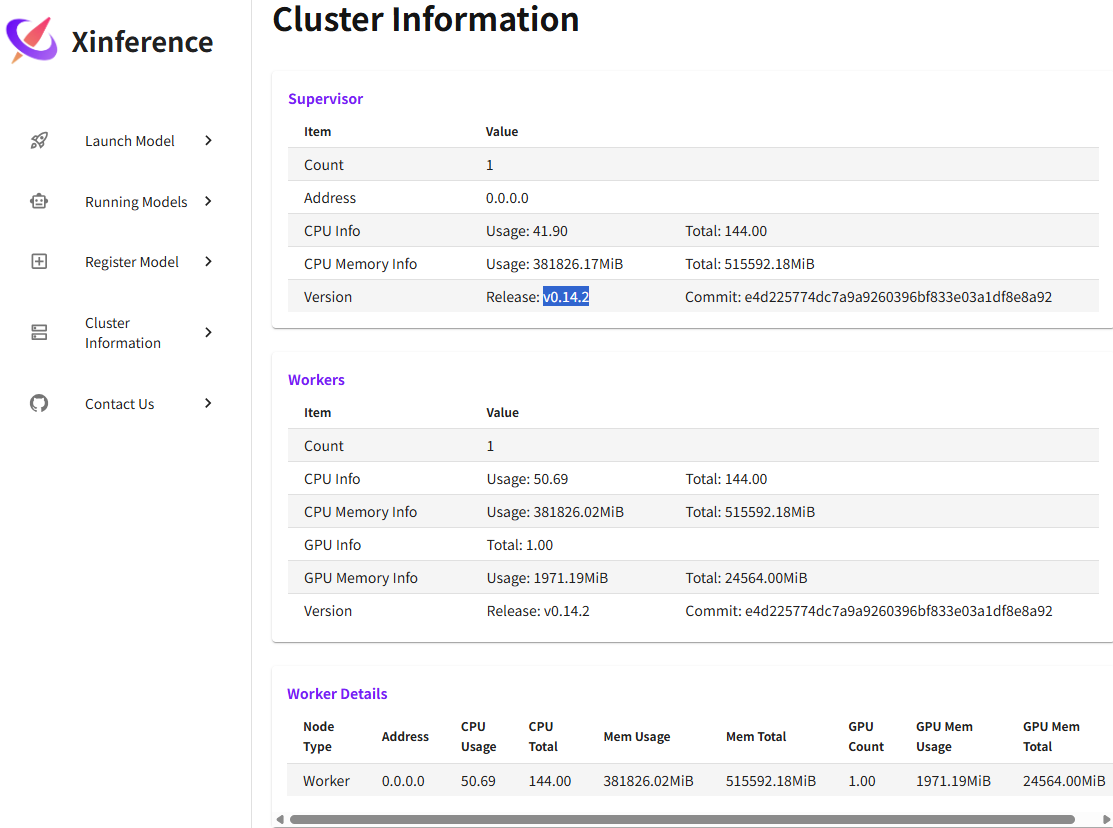
注:版本为v0.14.2
在Launch Model菜单中选择LANGUAGE MODELS标签,输入关键字,比如chatglm3:
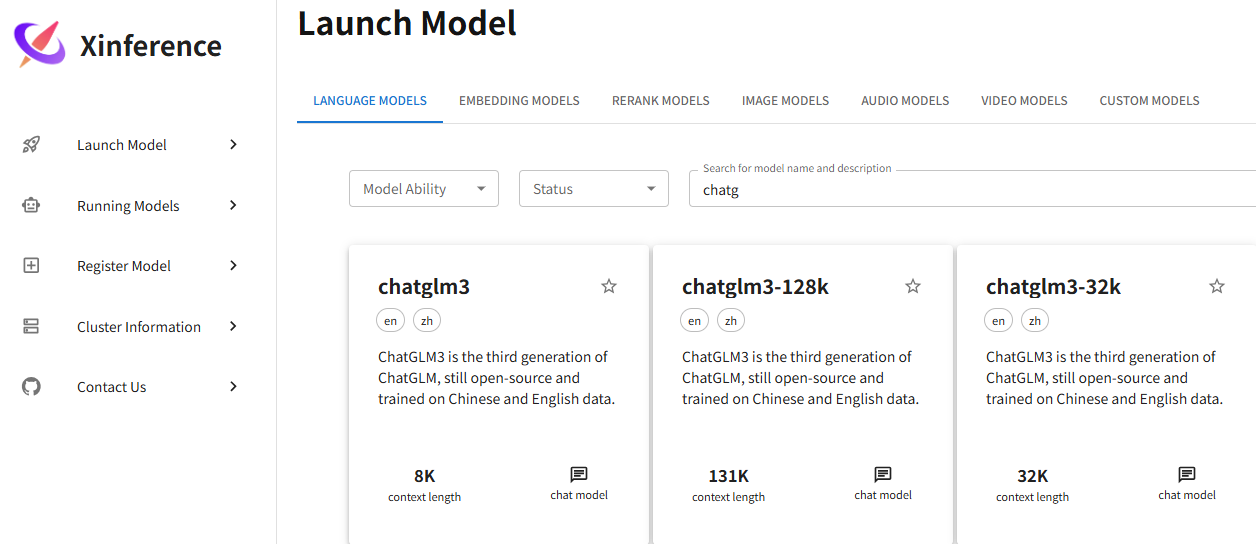
点击第一个:

可选参数:
- Model Engine:模型引擎,可选择Transformers和vLLM。选择Transformers后,截图如上。
- Model Format:模型格式,可选择量化和非量化的格式,非量化的格式是pytorch,量化格式有ggml、gptq等。不同的模型支持不同的格式。
- Model Size:模型的参数量大小,不同的模型,其可选择的参数量候选列表不一样。比如ChatGLM3只有6这个选项(表示6B,60亿参数);Llama2,有7、13、70等选项。
- Quantization:量化精度,4-bit、8-bit、none等。
- N-GPU:选择使用第几个GPU。
- Replica:副本数。
选择vLLM后,支持填入副本数:

和使用的GPU卡个数:

不管是Transformers还是vLLM,都支持填写其他可选参数:
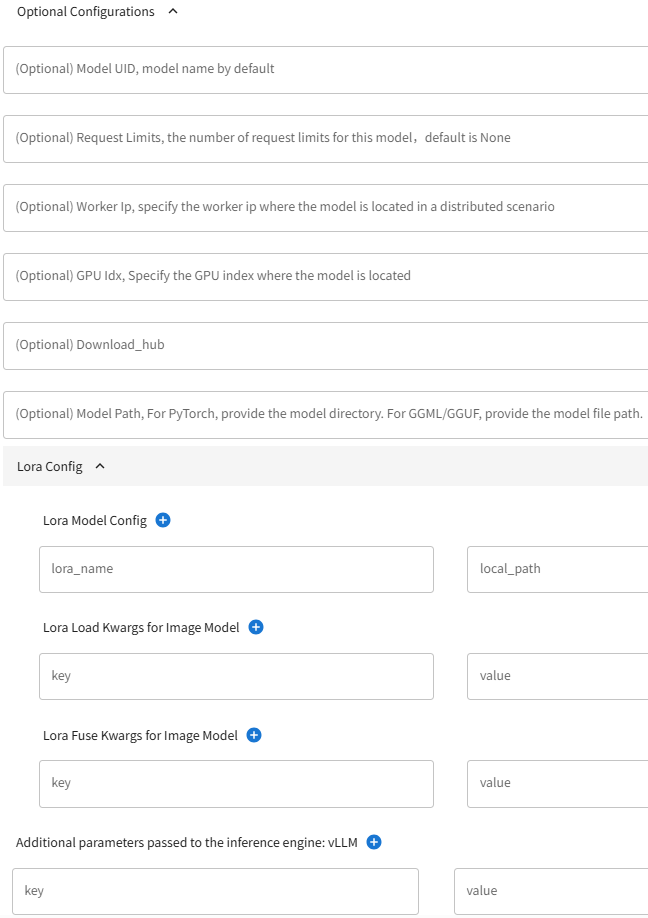
包括:
- Model UID:模型自定义名称,不填的话就默认用原始模型名称。
参数填写完成后,点击左边的火箭图标按钮即开始部署模型,后台会根据参数选择下载LLM模型。部署完成后,界面会自动跳转到Running Models菜单。
部署Embedding模型,只需要在Launch Model菜单中选择Embedding标签,然后选择相应模型,不像LLM模型一样需要选择参数,直接部署模型即可。
通过Curl命令调用API接口来验证部署好的Embedding模型:
curl -X 'POST' \'http://localhost:9997/v1/embeddings' \-H 'Content-Type: application/json' \-d '{"model": "bge-base-en-v1.5","input": "hello"
}'
验证rerank模型:
curl --location 'http://192.168.0.106:9997/v1/rerank' \
--header 'Content-Type: application/json' \
--data '{"model":"bge-reranker-v2-m3","query":"智能家居系统如何帮助提高家庭能源效率?","documents":["智能家居系统如何帮助提高家庭能源效率?213","fsdf"]
}'
对比
| Feature | Xinference | FastChat | OpenLLM | RayLLM |
|---|---|---|---|---|
| OpenAI-Compatible RESTful API | ✅ | ✅ | ✅ | ✅ |
| vLLM Integrations | ✅ | ✅ | ✅ | ✅ |
| More Inference Engines (GGML, TensorRT) | ✅ | ❌ | ✅ | ✅ |
| More Platforms (CPU, Metal) | ✅ | ✅ | ❌ | ❌ |
| Multi-node Cluster Deployment | ✅ | ❌ | ❌ | ✅ |
| Image Models (Text-to-Image) | ✅ | ✅ | ❌ | ❌ |
| Text Embedding Models | ✅ | ❌ | ❌ | ❌ |
| Multimodal Models | ✅ | ❌ | ❌ | ❌ |
| Audio Models | ✅ | ❌ | ❌ | ❌ |
| More OpenAI Functionalities (Function Calling) | ✅ | ❌ | ❌ | ❌ |