理解概率密度函数
概率密度函数
目录
1. 基本概念
2. 说明
3. 连续随机变量的问题
4. PDF如何工作?
5. PDF之定义
6. 示例
7. 概率密度不是概率
1. 基本概念
在概率论中,概率密度函数 (PDF——probability density function)(又称密度函数(density function)或绝对连续随机变量的密度(density))是这样一个函数,即其在样本空间(sample space)(随机变量所取的可能值之集合)中任何已知样本(或点)的值都可以解释为:提供了一种随机变量值等于该样本的相对可能性(relative likelihood),用于刻画连续随机变量的分布。概率密度是每单位长度的概率,换言之,连续随机变量取任何特定值的绝对可能性为 0(因为一开始就有无限个可能值),两个不同样本的 PDF 值可用于推断:在任何特定的随机变量抽取中,随机变量接近一个样本的可能性比接近另一个样本的可能性大多少。
更准确地说,概率密度函数 (PDF) 用于指定随机变量落入特定值域的概率,而不是取任意一个值。该概率由该变量的概率密度函数在该域上的积分给出,也就是说,它由密度函数下方、横轴上方、该域最小值与最大值之间的面积给出。概率密度函数处处非负,且整条曲线下的面积等于 1。
概率分布函数(probability distribution function)和概率函数(probability function)这两个术语有时也用于表示概率密度函数。然而,这种用法在概率学家和统计学家之间并不规范。在其他资料中,“概率分布函数”可能指概率分布被定义为一般值集上的函数,也可能指累积分布函数,或者指概率质量函数(PMF—probability mass function)而非密度函数。“密度函数”本身也用于概率质量函数,这会导致进一步的混淆。但一般来说,PMF 用于离散随机变量(取值于可数集的随机变量),而 PDF 用于连续随机变量。
2. 说明
指定随机变量的概率分布主要有两种方法:
(1) 为变量可能取的每一个值分配一个概率;
(2) 为变量可能取值的区间分配概率。
当变量的可能值集合可数(变量为离散变量)时,使用方法 (1)。当集合不可数(变量为连续变量)且方法 (1) 无法使用时,使用方法 (2)。方法 (2) 涉及概率密度函数。
3. 连续随机变量的问题
当可能值集合不可数时,上述方法(1)无法使用。这种不可能性源于许多基本的数学原因。例如:不可数集合的元素无法排列成序列;如果我们尝试为变量的每一个可能值分配概率,我们将无序可循;即使我们设法将概率分配给单个值,我们也无法检查它们的和是否等于 1 ;事实上,没有办法对不可数集合中的所有数求和。为了规避这种不可能性,数学家们发明了一种依赖于概率密度函数和积分的“技巧”。
4. PDF如何工作?
连续随机变量在已知区间内取值的概率等于其概率密度函数在该区间上的积分。
反之,等分等于xy 平面中由x轴,PDF 和与区间边界应于的垂线所界定的区域的面积。
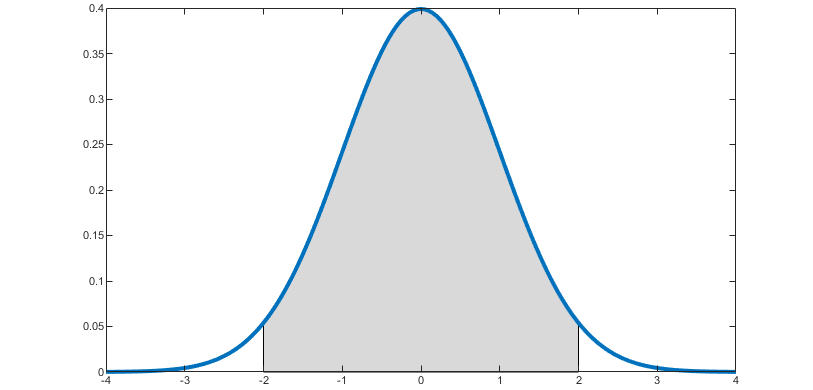
例如,下图中蓝线是正态随机变量(译注:即符合Gauss概率分布的随机变量)的概率密度函数,灰色区域的面积等于随机变量取值在 -2 到 2 区间的概率。
5. PDF之定义
定义:一个连续随机变量 x 的概率密度函数是一个集合 X 上的映射 ,其使得
( 对于任意区间
),
其中 P 表示概率。使得 f (x) > 0 的 x 的集合称为集合 X 的支集 (support)。
6. 示例
假设一个随机变量 x 具有概率密度函数
。
为了计算 x 在区间 [1,2] 内取值的概率,我们需要对该区间的概率密度函数进行积分:
。
7. 概率密度不是概率
理解以下两个函数之间的根本区别至关重要:
● 概率密度函数,表征连续随机变量的分布;
● 概率质量函数(probability mass function),表征离散随机变量的分布。
谨记:
● 离散型随机变量可以取可数个值;
● 连续型随机变量可以取不可数个值。
离散变量 Y 的概率质量函数是一个函数 ,对于任何实数 y,其都给出Y 将等于 y 的概率。
但是,若 X 是一个连续随机变量,其概率密度函数 f (x) 在已知点 x 处估算值不是 X 将等于 x的概率。事实上,对于任意 x ,这个概率等于 0 ,因为
。