Milvus(21):过滤搜索、范围搜索、分组搜索
1 过滤搜索
ANN 搜索能找到与指定向量嵌入最相似的向量嵌入。但是,搜索结果不一定总是正确的。您可以在搜索请求中包含过滤条件,这样 Milvus 就会在进行 ANN 搜索前进行元数据过滤,将搜索范围从整个 Collections 缩小到只搜索符合指定过滤条件的实体。
1.1 概述
在 Milvus 中,过滤搜索根据应用过滤的阶段分为两种类型--标准过滤和迭代过滤。
1.1.1 标准过滤
如果 Collections 同时包含向量嵌入及其元数据,您可以在 ANN 搜索之前过滤元数据,以提高搜索结果的相关性。Milvus 收到携带过滤条件的搜索请求后,会将搜索范围限制在符合指定过滤条件的实体内。
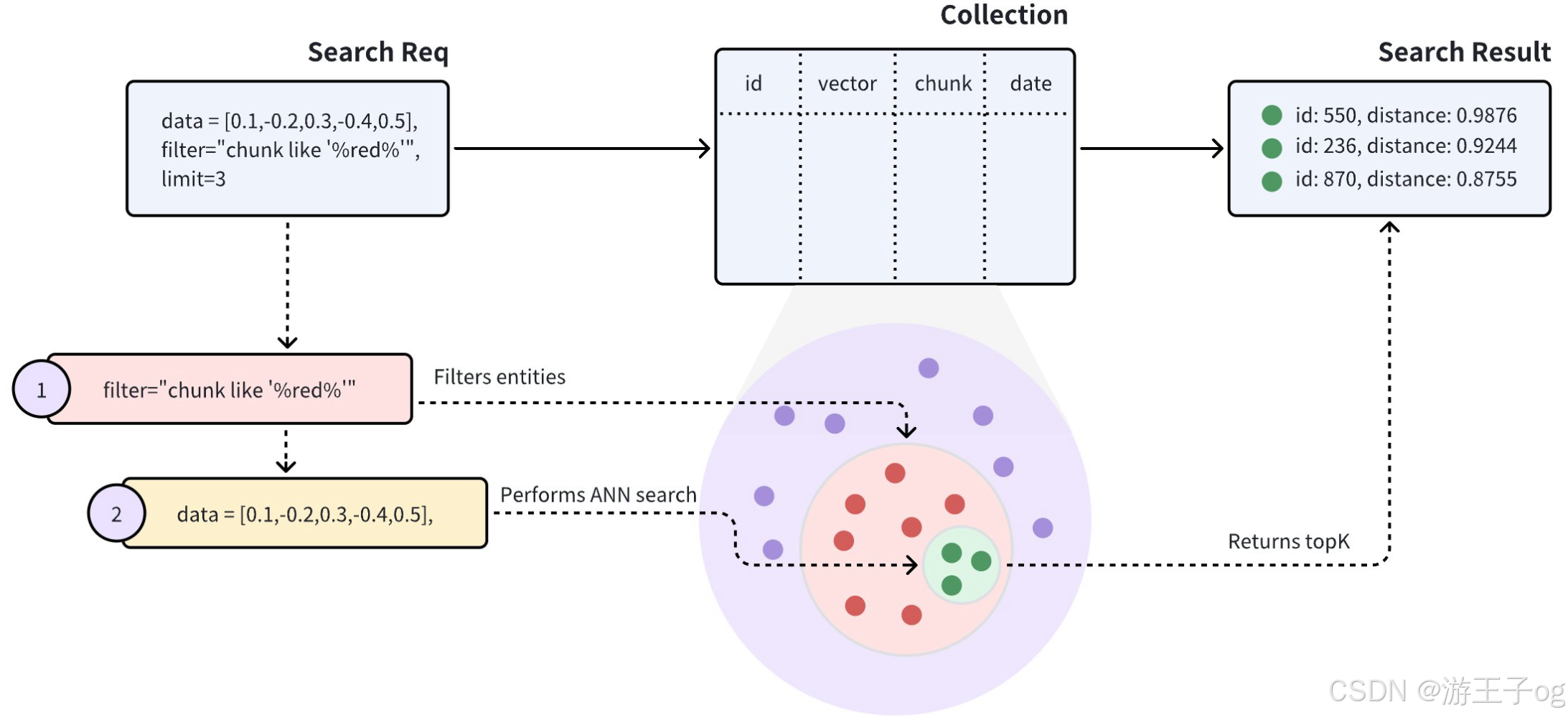
如上图所示,搜索请求携带chunk like "%red%" 作为过滤条件,表明 Milvus 应在chunk 字段中包含red 的所有实体内进行 ANN 搜索。具体来说,Milvus 会执行以下操作:
- 过滤符合搜索请求中过滤条件的实体。
- 在过滤后的实体中进行 ANN 搜索。
- 返回前 K 个实体。
1.1.2 迭代过滤
标准过滤过程能有效地将搜索范围缩小到很小的范围。但是,过于复杂的过滤表达式可能会导致非常高的搜索延迟。在这种情况下,迭代过滤可以作为一种替代方法,帮助减少标量过滤的工作量。
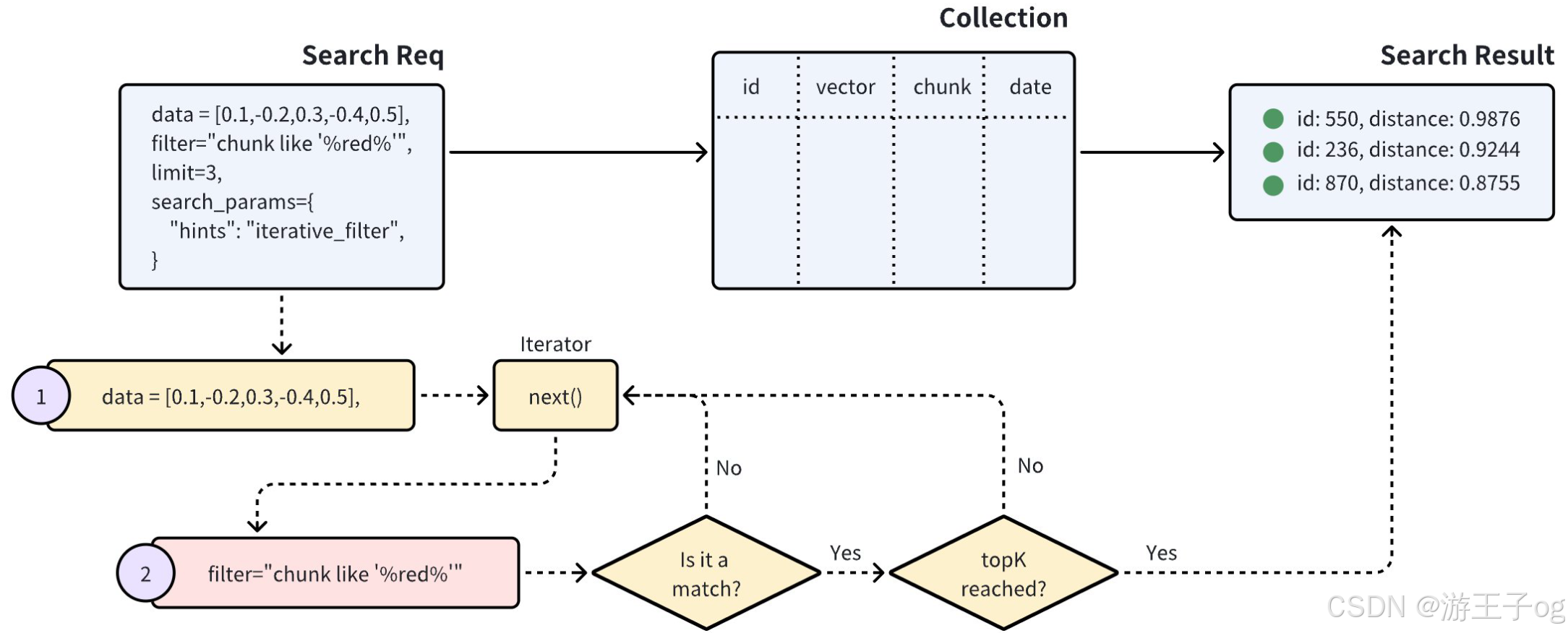
如上图所示,使用迭代过滤的搜索以迭代的方式执行向量搜索。迭代器返回的每个实体都要经过标量过滤,这个过程一直持续到达到指定的 topK 结果为止。这种方法大大减少了进行标量过滤的实体数量,特别有利于处理高度复杂的过滤表达式。不过,值得注意的是,迭代器一次处理一个实体。这种顺序方法可能会导致较长的处理时间或潜在的性能问题,尤其是在对大量实体进行标量过滤时。
1.2 示例
本节中的代码片段假定你已经在 Collections 中拥有以下实体。
[{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682", "likes": 165},{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025", "likes": 25},{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781", "likes": 764},{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298", "likes": 234},{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794", "likes": 122},{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222", "likes": 12},{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392", "likes": 58},{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510", "likes": 775},{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381", "likes": 876},{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976", "likes": 765}
]1.2.1 使用标准过滤进行搜索
下面的代码片段演示了使用标准过滤进行搜索,下面代码片段中的请求包含一个过滤条件和多个输出字段。
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]res = client.search(collection_name="my_collection",data=[query_vector],limit=5,# highlight-startfilter='color like "red%" and likes > 50',output_fields=["color", "likes"]# highlight-end
)for hits in res:print("TopK results:")for hit in hits:print(hit) 搜索请求中的过滤条件为color like "red%" and likes > 50 。它使用 and 操作符包含两个条件:第一个条件要求在color 字段中查找值以red 开头的实体,其他条件要求在likes 字段中查找值大于50 的实体。符合这些要求的实体只有两个。当 top-K 设置为3 时,Milvus 将计算这两个实体与查询向量的距离,并将它们作为搜索结果返回。
[{"id": 4, "distance": 0.3345786594834839,"entity": {"vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794", "likes": 122}},{"id": 6, "distance": 0.6638239834383389,"entity": {"vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392", "likes": 58}},
]1.2.2 使用迭代过滤搜索
使用迭代过滤进行过滤搜索的方法如下:
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]res = client.search(collection_name="my_collection",data=[query_vector],limit=5,# highlight-startfilter='color like "red%" and likes > 50',output_fields=["color", "likes"],search_params={"hints": "iterative_filter"}# highlight-end
)for hits in res:print("TopK results:")for hit in hits:print(hit)2 范围搜索
范围搜索可将返回实体的距离或得分限制在特定范围内,从而提高搜索结果的相关性。
2.1 概述
执行范围搜索请求时,Milvus 以 ANN 搜索结果中与查询向量最相似的向量为圆心,以搜索请求中指定的半径为外圈半径,以range_filter为内圈半径,画出两个同心圆。所有相似度得分在这两个同心圆形成的环形区域内的向量都将被返回。这里,range_filter可以设置为0,表示将返回指定相似度得分(半径)范围内的所有实体。
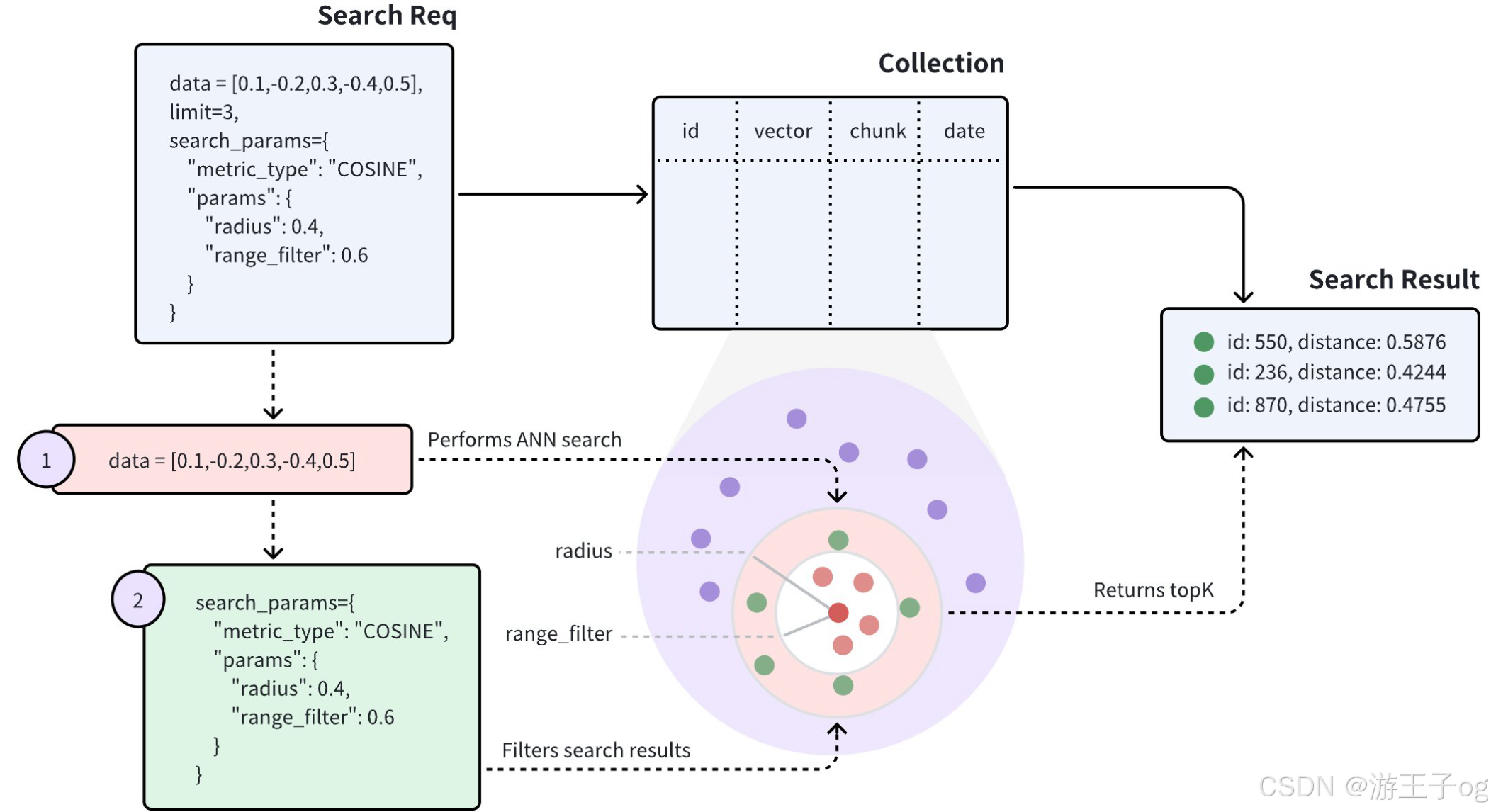
上图显示,范围搜索请求包含两个参数:半径和range_filter。收到范围搜索请求后,Milvus 会执行以下操作:
- 使用指定的度量类型(COSINE)查找与查询向量最相似的所有向量嵌入。
- 过滤与查询向量的距离或得分在半径和range_filter参数指定范围内的向量嵌入。
- 从筛选出的实体中返回前 K个实体。
设置radius和range_filter的方法因搜索的度量类型而异。下表列出了在不同度量类型下设置这两个参数的要求。
| 度量类型 | 名称 | 设置半径和范围筛选器的要求 |
|---|---|---|
|
| L2 距离越小,表示相似度越高。 | 要忽略最相似的向量 Embeddings,请确保 |
|
| IP 距离越大,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
|
| COSINE 距离越大,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
|
| Jaccard 距离越小,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
|
| 汉明距离越小,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
2.2 示例
以下代码片段中的搜索请求不带度量类型,表示使用默认度量类型COSINE。在这种情况下,请确保半径值小于range_filter值。在以下代码片段中,将radius 设为0.4 ,将range_filter 设为0.6 ,这样 Milvus 就会返回与查询向量的距离或分数在0.4至0.6 范围内的所有实体。
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]res = client.search(collection_name="my_collection",data=[query_vector],limit=3,search_params={# highlight-start"params": {"radius": 0.4,"range_filter": 0.6}# highlight-end}
)for hits in res:print("TopK results:")for hit in hits:print(hit)3 分组搜索
分组搜索允许 Milvus 根据指定字段的值对搜索结果进行分组,以便在更高层次上汇总数据。例如,您可以使用基本的 ANN 搜索来查找与手头的图书相似的图书,但也可以使用分组搜索来查找可能涉及该图书所讨论主题的图书类别。
3.1 概述
当搜索结果中的实体在标量字段中共享相同值时,这表明它们在特定属性上相似,这可能会对搜索结果产生负面影响。假设一个 Collections 存储了多个文档(用docId 表示)。在将文档转换成向量时,为了尽可能多地保留语义信息,每份文档都会被分割成更小的、易于管理的段落(或块),并作为单独的实体存储。即使文档被分割成较小的段落,用户通常仍希望识别哪些文档与他们的需求最相关。
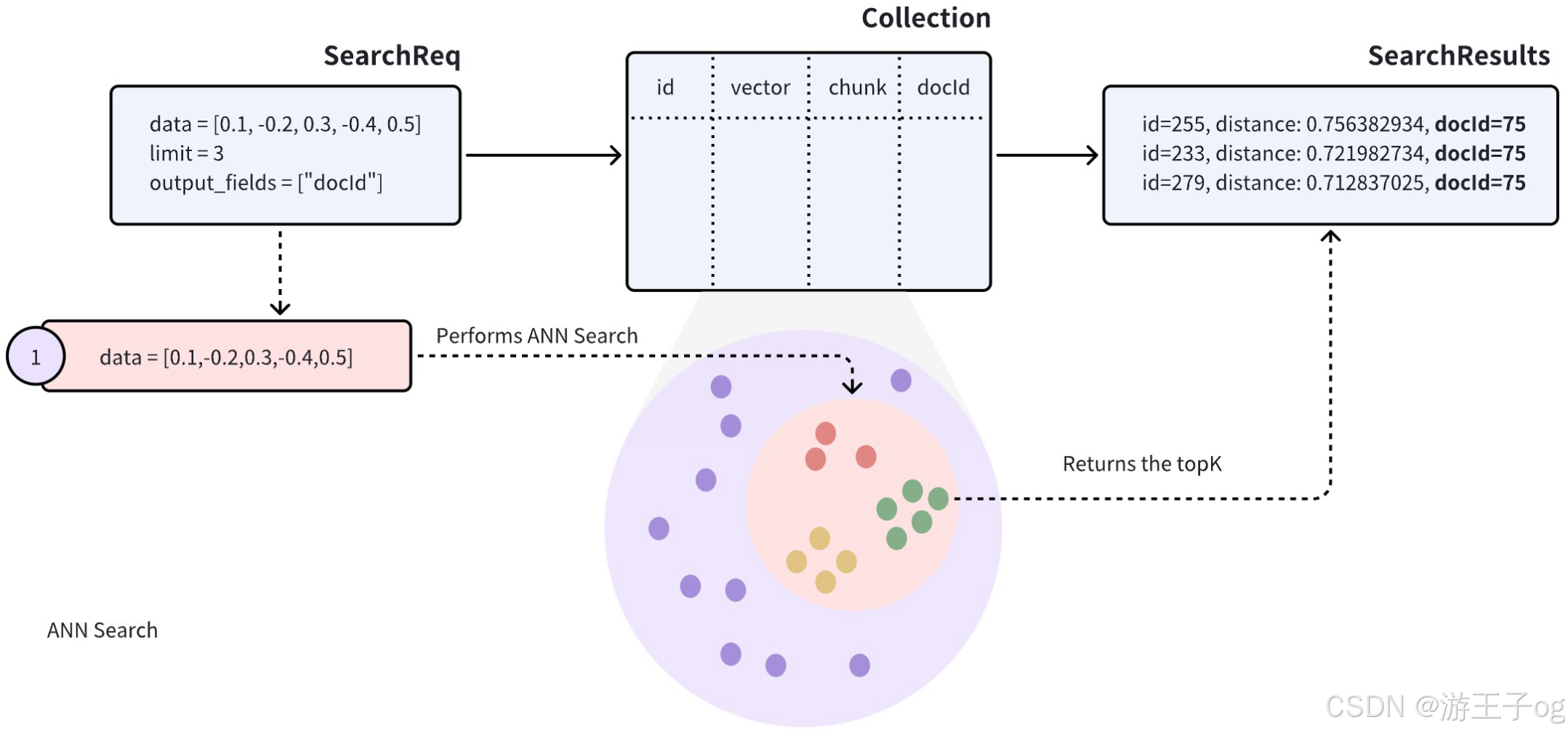
在对此类 Collections 执行近似近邻 (ANN) 搜索时,搜索结果可能包括同一文档中的多个段落,有可能导致其他文档被忽略,这可能与预期用例不符。
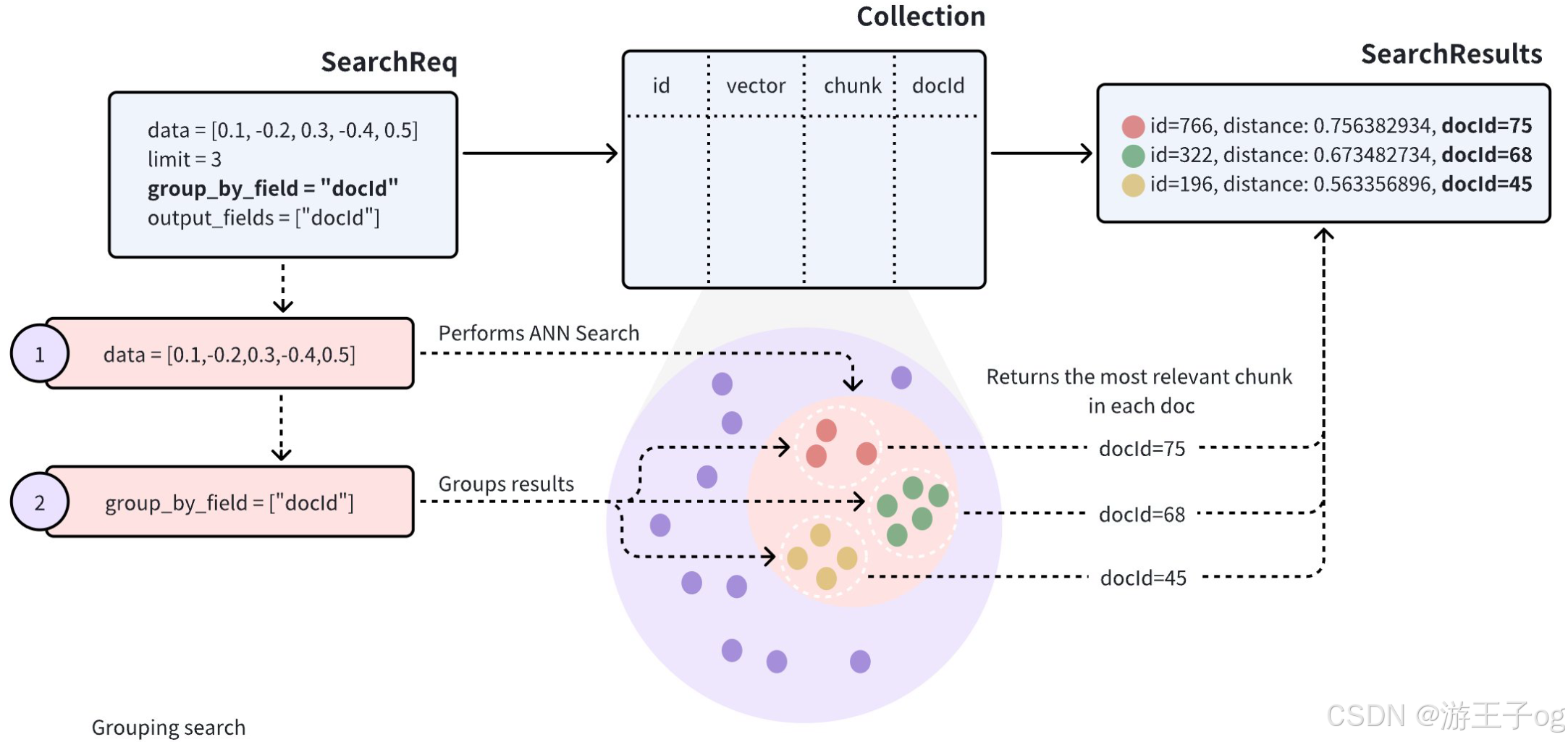
为了提高搜索结果的多样性,可以在搜索请求中添加group_by_field 参数来启用分组搜索。如图所示,您可以将group_by_field 设置为docId 。收到此请求后,Milvus 将
- 根据提供的查询向量执行 ANN 搜索,找到与查询最相似的所有实体。
- 按指定的
group_by_field对搜索结果进行分组,如docId。 - 根据
limit参数的定义,返回每个组的顶部结果,并从每个组中选出最相似的实体。
默认情况下,分组搜索每个组只返回一个实体。如果要增加每个组返回结果的数量,可以使用group_size 和strict_group_size 参数进行控制。
3.2 执行分组搜索
以下示例假定 Collections 包括id,vector,chunk 和docId 字段。
[{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "chunk": "pink_8682", "docId": 1},{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "chunk": "red_7025", "docId": 5},{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "chunk": "orange_6781", "docId": 2},{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "chunk": "pink_9298", "docId": 3},{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "chunk": "red_4794", "docId": 3},{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "chunk": "yellow_4222", "docId": 4},{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "chunk": "red_9392", "docId": 1},{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "chunk": "grey_8510", "docId": 2},{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "chunk": "white_9381", "docId": 5},{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "chunk": "purple_4976", "docId": 3},
] 在搜索请求中,将group_by_field 和output_fields 都设置为docId 。Milvus 将根据指定字段对结果进行分组,并从每个分组中返回最相似的实体,包括每个返回实体的docId 值。
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vectors = [[0.14529211512077012, 0.9147257273453546, 0.7965055218724449, 0.7009258593102812, 0.5605206522382088]]# 组搜索结果
res = client.search(collection_name="my_collection",data=query_vectors,limit=3,group_by_field="docId",output_fields=["docId"]
)# 检索‘ docId ’列中的值
doc_ids = [result['entity']['docId'] for result in res[0]] 在上面的请求中,limit=3 表示系统将从三个组中返回搜索结果,每个组都包含与查询向量最相似的单个实体。
3.3 配置组大小
默认情况下,分组搜索每个组只返回一个实体。如果希望每组有多个结果,请调整group_size 和strict_group_size 参数。
# 组搜索结果
res = client.search(collection_name="my_collection", data=query_vectors, # 查询向量limit=5, # 返回的组数group_by_field="docId", # 分组字段group_size=2, # 从每个组返回2个实体strict_group_size=True, # 是否应严格执行group_size 设置的计数。output_fields=["docId"]
)在上面的示例中
group_size:指定每个组要返回的实体数量。例如,设置group_size=2意味着每个组(或每个docId)最好返回两个最相似的段落(或块)。如果未设置group_size,系统将默认为每组返回一个结果。strict_group_size:这个布尔参数控制着系统是否应严格执行group_size设置的计数。当strict_group_size=True时,系统将尝试在每个组中包含group_size所指定的实体的确切数量(例如两个段落),除非该组中没有足够的数据。默认情况下(strict_group_size=False),系统会优先满足limit参数指定的组数,而不是确保每个组都包含group_size实体。在数据分布不均衡的情况下,这种方法通常更有效。
3.4 注意事项
- 索引:此分组功能仅适用于使用这些索引类型编制索引的 Collections:flat、ivf_flat、ivf_sq8、hnsw、hnsw_pq、hnsw_prq、hnsw_sq、diskann、sparse_inverted_index。
- 组数:
limit参数控制返回搜索结果的组的数量,而不是每个组内实体的具体数量。设置适当的limit有助于控制搜索多样性和查询性能。如果数据分布密集或考虑性能问题,减少limit可以降低计算成本。 - 每组实体:
group_size参数控制每个组返回的实体数量。根据使用情况调整group_size可以增加搜索结果的丰富性。但是,如果数据分布不均,某些组返回的实体数量可能少于group_size的指定数量,尤其是在数据有限的情况下。 - 严格的组大小:当
strict_group_size=True时,系统将尝试为每个组返回指定数量的实体 (group_size),除非该组中没有足够的数据。此设置可确保每个组的实体数一致,但在数据分布不均或资源有限的情况下可能会导致性能下降。如果不需要严格的实体数,设置strict_group_size=False可以提高查询速度。