DataWhale LLM
LLM介绍
1.1 大型语言模型
大语言模型指的是理解和生成人类语言的人工智能模型,LLM通常包含更多的参数,国内的有DeepSeek,通义千问,豆包,Kimi,文心一言,GLM
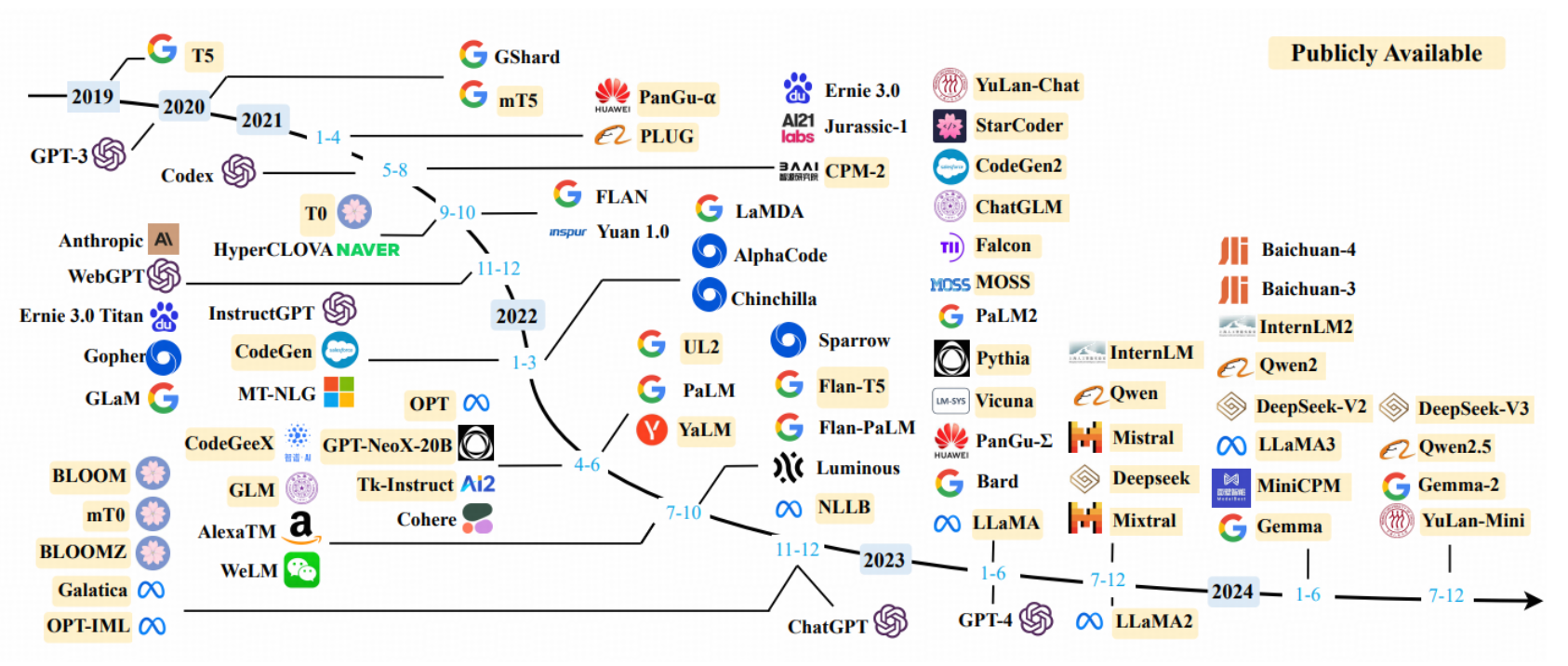
语言建模历史:
从上世纪90年代,主要集中在统计学方法进行预测词汇。在2003年使Bengio提出使用神经网络模型,在2018年提出transformer网络,提高各种模型在自然语言处理中的表现。通常大模型由三个阶段构成:预训练、后训练和在线推理。在2024年9月之前,大模型存在Scaling Law,之后随着Open AI 推出,后训练和在线推理也各自拥有了Scaling Law,随着计算量的增加,大模型的性能进一步增强。
1.1.1 常见的LLM模型
OpenAI
OpenAI 公司提出GPT模型,将世界知识压缩到仅仅解码器的Transformer模型中,这样可以恢复世界知识的语义,能成功的关键点在于:
- 训练能够准确地预测下一个单词的decoder-only 的Transformer语言模型
- 扩展语言模型的大小
Claude
是由OpenAI离职人员Anthropic公司开发的闭源语言大模型
是收款混合推理模型,支持标准模式和推理思考模式,编码能力异常强大
PaLM
是Google开发的,发布了Gemini
文心一言
文心一言是百度文心大模型知识增强语言大模型
LLaMA
LLaMA是Meta开源的一组参数规模从8B到405B的基础语言模型
采用的技术包括:
- Pre-Normalization正则化:对每个Transformer子层输入进行RMSNorm归一化,避免了梯度爆炸的问题和提高了模型的收敛性
- SwiGLU激活函数:将ReLU非线性替换为SwiGLU激活函数,增加了网络的表达能力和非线性,减少了参数量和计算量
- 旋转位置编码:输入不在使用位置编码,在网络的每一层增加了位置编码,RoPE位置编码可以有效的捕获输入序列的相对位置信息,具有较好的泛化能力
- 分组查询注意力:通过查询分组在组内共享键和值,减少了计算量,同时保留了模型性能,提高了大模型的推理效率
DeepSeek
主要改进:
- 多头潜在注意力:将键值缓存显著压缩为潜在向量来保证高效推理的同时不降低效果
- DeepSeekMoE:通过稀疏计算
- 一系列的推理加速技术:
1.1.2 LLM的特点和能力
- 巨大的规模:LLM通常规模巨大
- 预训练和微调:LLM采用预训练和微调的方法,首先在大规模的文本数据上进行预训练,学习通用的语言表达
- 上下文感知:LLM在处理文本时有上下文感知能力
- 多语言支持:支持多种语言
- 多模态支持:扩展到支持多模态数据,包括文本,图片和声音
- 伦理和风险问题
- 高计算资源需求
1.1.2.1 涌现能力
涌现能力随着模型规模随着模型性能迅速提升,超过了随即水平,也就是量变引起质变,LLM的涌现能力:
- 上下文学习能力:在提供自然语言指令和多个任务情况下,通过理解上下文并生成相应的输出执行任务
- 指令遵循:通过使用自然语言描述的多任务数据进行微调,也就是指令微调。无须事先展示具体示例,展现了强大的泛化能力
- 逐步推理:小语言模型通常能力解决多个推理步骤复杂任务,LLM通过思维链推理策略,利用中间的推理步骤的提示机制解决这些任务
1.1.2.2 支持多个应用能力
多个应用可以只依赖于一个或者几个大模型进行统一的建设,大语言模型就是使用统一的模型极大的提高了研发效率,相比于每次开发单个的模型的方式,这是一个本质上的进步
1.2RAG
RAG指的是检索增强生成,这个框架巧妙的整合了从庞大的知识库中检索到的相关信息,以此为基础,指导大语言模型生成更为准确的答案
LLM困境:
- 信息偏差,信息幻觉:LLM产生与事实不符合的信息,导致用户接收的信息不准确,RAG通过检索可以确保输出内容的精确性和可信度,减少信息偏差
- 知识更新滞后性:LLM基于静态的数据集训练,无法及时的反应最新的信息动态,RAG通过实时检索最新的数据,保证内容的时效性
- 内容的不可追溯:LLM生成的内容往往缺乏明确的信息来源,影响内容可信度。RAG将生成内容和检索到的原始资料进行链接,增强了内容的可追溯性,从而提升了用户对生成内容的信任度
- 专业知识能力欠缺:RAG通过检索特定的相关文档,为模型提供丰度的上下文信息,提高了在专业领域的回答问题的质量和深度
- 推理能力限制:RAG结合检索的信息和模型生成能力通过提供额外的知识作为支持,增强了模型的推理和理解能力
- 应用场景适应性受限:RAG使得LLM能够通过检索对应应用场景,灵活的适应问答推荐系统
- 长文本处理能力较弱:RAG通过检索整合长文本的信息,强化了模型对上下文的理解和生成,有效的突破了输入长度限制,同时降低了调用成本,提升了整体的整合效率
1.2.1 RAG工作流程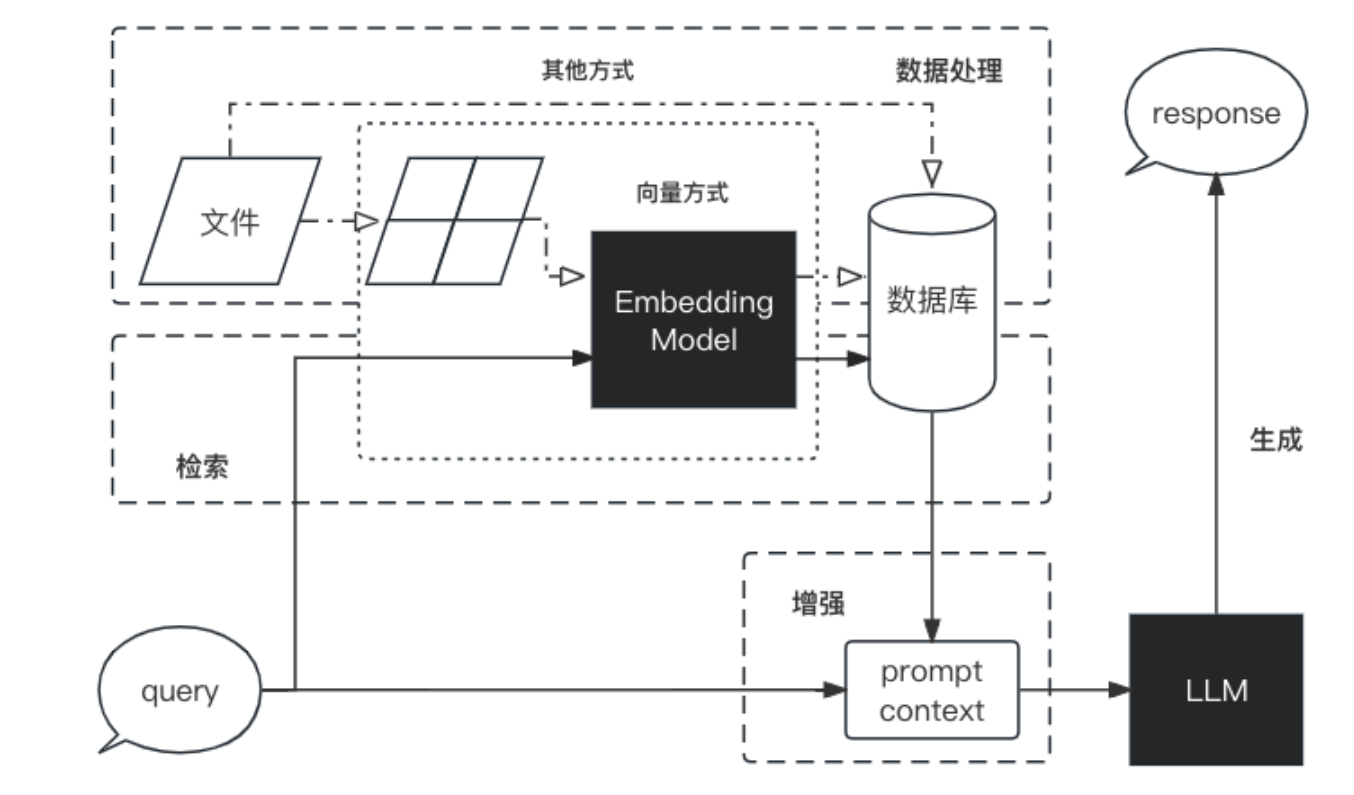
- 1.数据处理阶段:
– 对原始数据进行清洗和处理
– 将处理之后的数据转化为检索模型可以使用的格式
– 将处理好的数据存储在对应的数据库中 - 2.检索阶段:
– 将用户的问题输入到检索系统中,从数据库检索相关信息 - 3.增强阶段:
– 对检索的信息进行增强,以便生成模型可以更好的理解和使用 - 4.生成阶段:将增强之后的信息输入到生成模型中,生成模型根据这些生成答案
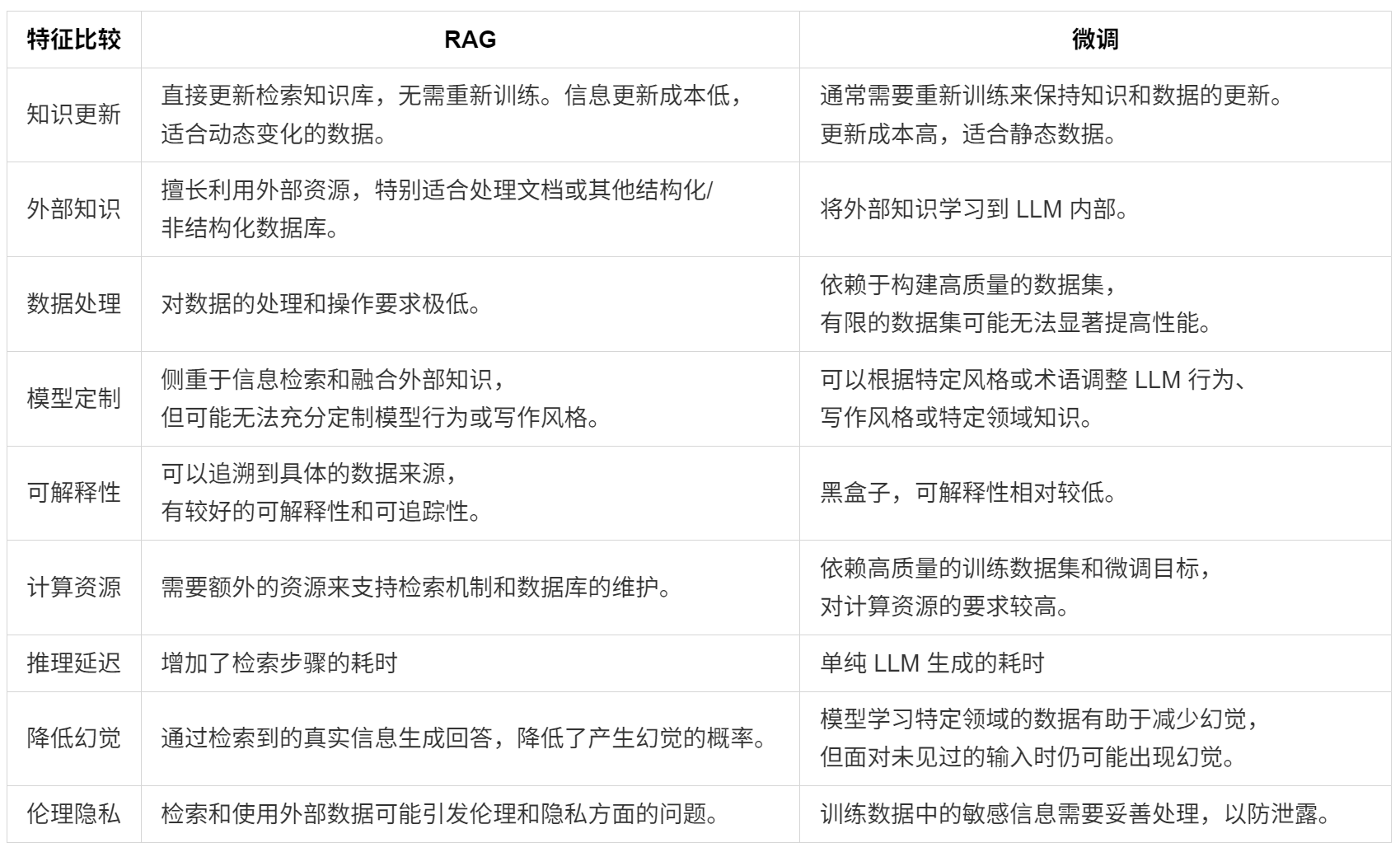
1.2.2RAG VS FineTune
1.3LangChain
LangChain框架是一个开源的工具,充分利用了大型语言模型的强大的能力,以便开发下游应用,目的是为了各种的大预言模型提供通用接口,简化应用程序的开发流程
1.3.1 LangChain核心组件
模型输入输出:与语言交互的接口
数据连接:与特定应用数据进行交互的接口
链:将组件组合实现到端到端的应用,搭建检索问答链检索问答
记忆:用于链多次运行之间的持久化应用程序
代理:扩展模型的代理能力
回调:扩展模型的推理能力
1.4大模型开发
以大语言模型为功能核心,通过大语言模型的强大理解能力和生成能力,结合特殊的数据或者业务逻辑来提供独特的功能的应用称为大模型开发,一般不会修改模型,将大模型作为一个调用工具,通过使用Prompt Engineering,数据工程,业务逻辑分解的手段充分发挥大模型的能力,适配应用任务。
1.4.1 大模型开发的流程
- 1.确定目标
- 2.设计功能
- 3.搭建整体架构
- 4.搭建数据库
- 5.Prompt Engineering
- 6.验证迭代
- 7.前后端搭建
- 8.体验优化