大模型day4 - LangChain
一.LangChain 是什么
LangChain 通过组合模块和能力抽象来扩展大型语言模型(LLM)的应用
开发者文档:https://python.langchain.com/docs/integrations/llms/
代码实现:https://github.com/langchain-ai/langchain/tree/master/libs/langchain/langchain/llms
二.为什么需要LangChain
- 统一了对接LLM的抽象,便于行业沟通协作
- LangChain 预实现了一些模块,例如帮助开发者更方便的管理 memory 和 提示词模板
三.Model I/O

model I/O 这个模块主要负责处理大模型的输入输出
大模型的输入:通常是提示模板(prompt)
大模型的输出:是模型对输入提示词的处理结果。 大语言模型的输出通常不稳定,langchain的output可以将不同大模型的结果规范化处理
BaseLanguageModel
LanguageModelInput = Union[PromptValue, str, Sequence[MessageLikeRepresentation]]
LanguageModelOutputVar = TypeVar("LanguageModelOutputVar", BaseMessage, str)
class BaseLanguageModel(RunnableSerializable[LanguageModelInput, LanguageModelOutputVar], ABC
):
BaseLanguageModel 是与大预言模型进行交互的抽象
主要提供三种方法:
| 方法名 | 输入类型 | 输出类型 | 使用场景 |
|---|---|---|---|
| generate_prompt | List[PromptValue] | LLMResult | 底层批量生成、多输出控制 |
| predict | str(单个 prompt) | str | 单次文本生成,简单问题回答 |
| predict_messages | List[BaseMessage] | BaseMessage | 聊天模型对话,适配聊天上下文 |
虽然是顶级的抽象,但是三个方法也是存在直接或者间接的调用关系的
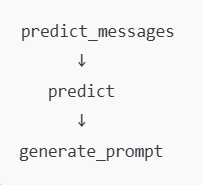
Demo1:调用大模型
from langchain_openai import OpenAI
llm = OpenAI(model_name="gpt-3.5-turbo-instruct")
print(llm.invoke("what is your name?"))
Demo2:格式化输出
这里需要注意一个点,格式化输出是将模型返回的非结构数据转换成结构化的数据,这中间是存在失败的可能性的
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_openai import OpenAI# 创建一个输出解析器,用于处理带逗号分隔的列表输出
output_parser = CommaSeparatedListOutputParser()# 获取格式化指令,该指令告诉模型如何格式化其输出
format_instructions = output_parser.get_format_instructions()# 创建一个提示模板,它会基于给定的模板和变量来生成提示
prompt = PromptTemplate(template="List five {subject}.\n{format_instructions}", # 模板内容input_variables=["subject"], # 输入变量partial_variables={"format_instructions": format_instructions} # 预定义的变量,这里我们传入格式化指令
四.Chain
Chain 是 LangChain 中所有链式组件的抽象基类,它定义了结构化调用序列的统一接口。
核心特性
- 链式组合:通过串联模型、检索器等组件构建复杂流程
- 状态管理:通过 memory 属性实现有状态调用
- 可观测性:通过 callbacks 支持日志记录等扩展功能
- 灵活调用:提供多种执行方式(call/run/invoke)
关键属性
| 属性 | 说明 | 默认值 |
|---|---|---|
| memory | 存储调用状态和变量 | None |
| callbacks | 生命周期事件处理器 | None |
| verbose | 是否输出详细日志 | 全局设置 |
| tags | 调用标签(用于分类) | None |
| metadata | 自定义元数据 | None |
LLMChain
LLMChain 是 LangChain 中最基础的链式组件,由两大核心部分构成:
PromptTemplate - 定义输入变量的模板结构
语言模型 - 实际执行推理的 LLM 或 ChatModel
Demo1
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain# 定义模板和模型
prompt = PromptTemplate.from_template("请用{style}风格回答:{question}")
llm = OpenAI(temperature=0.7)# 创建链
chain = LLMChain(llm=llm, prompt=prompt)# 执行调用
response = chain.run(style="幽默", question="如何学习AI?")
SimpleSequentialChain(简单顺序链)
特点:
- 单输入单输出流水线
- 前一个链的输出自动作为下一个链的输入
- 适合线性处理流程
典型结构:
[链A] -> [链B] -> [链C]
Demo1
from langchain.chains import SimpleSequentialChain# 假设已定义3个LLMChain:summary_chain, translate_chain, style_chain
pipeline = SimpleSequentialChain(chains=[summary_chain, translate_chain, style_chain],verbose=True
)# 执行整个流水线
result = pipeline.run("原始文本内容")
SequentialChain(通用顺序链)
特点:
- 支持多输入多输出
- 需要显式指定输入/输出变量名
- 适合复杂分支流程
关键参数:
- input_variables: 整个流水线的初始输入变量
- output_variables: 最终需要输出的变量
- chains: 包含的链列表
Demo1:
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI# 初始化模型(使用实际API key替换)
llm = OpenAI(temperature=0.7, openai_api_key="your-api-key")# ========== 第一步:关键词提取 ==========
keyword_prompt = PromptTemplate(input_variables=["document"],template="请从以下文本中提取3-5个最重要的关键词:\n{document}"
)
keyword_chain = LLMChain(llm=llm,prompt=keyword_prompt,output_key="keywords", # 指定输出键名verbose=True
)# ========== 第二步:问题生成 ==========
question_prompt = PromptTemplate(input_variables=["keywords"],template="根据这些关键词生成3个相关问题: {keywords}"
)
question_chain = LLMChain(llm=llm,prompt=question_prompt,output_key="generated_questions",verbose=True
)# ========== 第三步:回答问题 ==========
answer_prompt = PromptTemplate(input_variables=["document", "generated_questions"],template="基于以下文本回答问题:\n文本内容:{document}\n\n问题:{generated_questions}"
)
answer_chain = LLMChain(llm=llm,prompt=answer_prompt,output_key="final_answer",verbose=True
)# ========== 构建顺序链 ==========
overall_chain = SequentialChain(chains=[keyword_chain, question_chain, answer_chain],input_variables=["document"], # 初始输入output_variables=["keywords", "generated_questions", "final_answer"], # 最终输出verbose=True
)# ========== 执行链 ==========
input_text = """
人工智能是模拟人类智能的计算机系统。这些系统能够学习、推理、解决问题、理解自然语言和感知环境。
当前AI技术包括机器学习、深度学习和自然语言处理等。AI应用涵盖医疗诊断、自动驾驶和智能客服等领域。
"""result = overall_chain({"document": input_text})# ========== 打印结果 ==========
print("\n====== 原始输入 ======")
print(input_text)print("\n====== 提取的关键词 ======")
print(result["keywords"])print("\n====== 生成的问题 ======")
print(result["generated_questions"])print("\n====== 最终答案 ======")
print(result["final_answer"])
五.Memory
记忆系统是构建对话式AI应用的核心组件,它使模型能够保持上下文信息,实现连贯的多轮对话。
BaseMemory
关键方法解析
@property
@abstractmethod
def memory_variables(self) -> List[str]:"""定义记忆系统提供的变量名列表"""
声明记忆系统将向链注入哪些变量
@abstractmethod
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:"""根据当前输入加载记忆内容"""
执行时机:在链处理用户输入前调用
参数:
- inputs:链接收的原始输入字典
返回值:要合并到链输入中的额外变量
@abstractmethod
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:"""保存当前交互的上下文"""
执行时机:在链产生输出后调用
参数:
- inputs:链接收的原始输入
outputs:链产生的输出
@abstractmethod
def clear(self) -> None:"""重置记忆状态"""
基本交互流程
1.读取阶段(READ)
- 在链执行核心逻辑前
- 从记忆系统加载历史信息
- 自动扩充用户当前输入
2.写入阶段(WRITE)
- 在链执行核心逻辑后
- 将当前交互的输入/输出保存到记忆系统
- 供后续对话使用
几种不同的Memory
| ConversationBufferMemory | 保存原始对话历史 | 简单对话场景 |
|---|---|---|
| ConversationBufferWindowMemory | 只保留最近N条对话 | 限制上下文长度 |
| ConversationSummaryMemory | 保存对话的摘要 | 长对话压缩 |
| EntityMemory | 提取并跟踪实体信息 | 需要实体记忆的场景 |
ConversationBufferMemory(保存完整历史)
场景:简单的多轮对话机器人
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import ConversationChainmemory = ConversationBufferMemory()
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)# 第一轮对话
conversation.run("你好,我是小明")
# 输出: "你好小明!有什么我可以帮助你的吗?"# 第二轮对话(记住上下文)
conversation.run("你还记得我叫什么名字吗?")
# 输出: "当然记得,你叫小明。"
ConversationBufferWindowMemory(只保留最近N轮)
场景:限制上下文长度的客服系统
from langchain.memory import ConversationBufferWindowMemorymemory = ConversationBufferWindowMemory(k=2) # 只保留最近2轮
conversation = ConversationChain(llm=llm, memory=memory)conversation.run("我喜欢苹果")
conversation.run("苹果有营养吗?")
conversation.run("哪种水果最甜?")# 此时记忆只保留:
# Human: 苹果有营养吗?
# AI: 苹果确实富含营养...
# Human: 哪种水果最甜?
** ConversationSummaryMemory(摘要式记忆)**
场景:长时间对话的摘要保存
from langchain.memory import ConversationSummaryMemorymemory = ConversationSummaryMemory(llm=llm)
conversation = ConversationChain(llm=llm, memory=memory)conversation.run("Python是一种解释型语言")
conversation.run("它适合初学者学习")
conversation.run("拥有丰富的第三方库")print(memory.buffer)
# 输出摘要: "用户讨论了Python作为解释型语言的特点,适合初学者,并提到其丰富的库生态"
EntityMemory(实体记忆)
场景:需要记住特定信息的对话
from langchain.memory import ConversationEntityMemorymemory = ConversationEntityMemory(llm=llm)
conversation = ConversationChain(llm=llm, memory=memory)conversation.run("张三是百度的工程师,他擅长Java")
conversation.run("李四是腾讯的产品经理")
conversation.run("张三在哪家公司工作?")
# 输出: "张三在百度工作"
六.Data Connection
Data Connection 的五大步骤:
- 加载数据(Load)
- 转换数据(Transform)
- 向量化(Embed)
- 存储(Store)
- 检索(Retrieve)
1. 加载数据:Document Loaders
数据来源广泛,比如 GitHub 仓库、YouTube 视频、微博、Twitter、Office 文档(PPT、Word、Excel)等。
LangChain 提供了丰富的 Document Loaders,支持的格式包括:
- 文件格式:CSV、HTML、JSON、Markdown、PDF、本地目录等;
- 数据源平台:Arxiv、Bilibili、GitHub、Reddit、TensorFlow Datasets 等。
加载器基类是 BaseLoader,其核心方法是:
def load(self) -> List[Document]:
每个加载器会返回一个 Document 对象的列表。
2. 转换数据:Document Transformers
在加载原始数据后,往往需要进一步切分或处理,比如:
- 将一整本问答手册拆分为一个个问答对;
- 将 HTML 页面解析为纯文本;
- 对文档进行清洗、格式统一;
- 对本文根据语意进行拆分
- 等等
这部分由 Document Transformers 完成,支持包括分段、清洗、结构化处理等操作,是后续向量化前的关键步骤。
3. 向量化:Embedding Models
完成数据切分后,下一步就是将文本转换为向量,即embedding。
这些模型将文本转为固定维度的向量,作为后续存储与检索的基础。
4. 存储与检索:Vector Stores & Retriever
Embedding: 生成的向量会被存储到向量数据库中,
Retriever :模块负责根据查询向量查找最相似的 Document,用于 RAG(Retrieval-Augmented Generation)任务。
一个形象的比喻是:向量数据库就像是 AI 模型的“外接硬盘”,它能补充训练语料无法实时更新的缺陷,增强模型对实时和私域知识的获取能力。
Embedding 与 Vector Store 是一对组合
嵌入模型和向量数据库密切耦合,它们必须“对口”:
- 向量数据库只是一个容器,不关心向量内容;
- 嵌入模型负责将原始文本变成向量;
如果两者使用的向量空间不一致(如维度不同、模型不同),就会导致无法匹配和检索。
因此,Embedding Model 和 Vector Store 必须成对使用,保持一致的向量编码方式,才能在后续的检索中实现语义对齐。
七.Agent
通俗来讲,Agent 就像一个“具备感知、思考和行动能力”的智能个体。它通过环境输入感知信息,结合内在的记忆和推理机制,做出响应决策,并作用于环境,形成闭环。
Agent 的工作流程
[用户输入] → [Agent 感知输入] → [计划/推理/记忆] →
[工具调用或响应输出] → [更新记忆] → [继续任务 or 结束]
Demo
# -------------------------------
# 定义函数
from datetime import datetime
def get_current_time():return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# -------------------------------
# 根据函数构建工具
from langchain.tools import Tooltime_tool = Tool(name="GetCurrentTime",func=lambda x: get_current_time(),description="用来获取当前时间,不需要输入内容"
)
# -------------------------------from langchain.agents import initialize_agent, AgentType
from langchain.chat_models import ChatOpenAIllm = ChatOpenAI(temperature=0)agent = initialize_agent(tools=[time_tool],llm=llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,verbose=True,
)response = agent.run("现在几点了?")
print(response)
Agent 和function calling的区别
其实从代码实现上来看,Agent 与 function calling 有比较大的相似性,但是实际上二者的本质有所不同
对比:
| 维度 | Function Calling | Agent |
|---|---|---|
| 本质 | LLM 自动选择要调用的函数 | LLM 扮演“思考 + 工具调用 + 决策”的智能体 |
| 目标 | 根据用户意图调用合适的函数并返回结果 | 根据目标完成复杂任务,可多轮调用工具 |
| 控制 | 流程 一次调用,一问一答 | 可以多轮推理,多步调用工具 |
| 通常配合 | OpenAI API(Function Calling / Tool Calling) | LangChain / LlamaIndex 等框架 |
| 输入结构 | 定义 schema,模型自动填参数 | Agent 模拟人类思考,自己决定用什么工具、用几次 |
| 是否自动循环 | 否,需要自己控制是否再次调用 | 是,Agent 内部有决策机制控制调用流程 |
| 举个例子 | “帮我查一下北京天气” → 调用 get_weather(location=“北京”) | “计划今天出行”→ Agent 会先查天气,再查地图,最终给出建议 |