【Python训练营打卡】day22 @浙大疏锦行
test 复习日
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。
作业:
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
kaggle泰坦里克号人员生还预测
一、注册账号
之前注册时一直没有出现人机验证,百思不得其解,参考的这篇文章问题就解决了。
【kaggle集合】kaggle的注册(有手就行!!)+加速下载【会更新】_kaggle注册-CSDN博客

成功出现人机身份验证,后面就是正常注册就好了
二、数据集下载

可以搜索框搜索,也可以进行一些筛选

该数据集的一些相关信息描述可以在这里查看
点击右上角的download按钮即可下载
三、kaggle泰坦里克号人员生还预测
(1)导入包
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import make_scorer,accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息(2)加载数据集
train_data=pd.read_csv('train.csv')
train_data.info()
train_data.head(10)
查看一下缺失值
train_data.isnull().sum() 
cabin缺失太多了,所以我打算直接删掉
对于age:先查看一下age与survived的相关性
g = sns.FacetGrid(train_data, col='Survived')
g.map(plt.hist, 'Age', bins=20) 
从结果来看:年龄<=4的存活率很高;年龄 = 80的也幸存下来了;大部分15-25 岁的人无法生存;大多数乘客的年龄在 15-35 岁之间。年龄和存活与否有相关性,所以对于age我选择保留下来,并进行缺失值填补
(3)整理、清洗数据
删除无用特征name、Ticket 、Cabin,补全缺失值
train_data = train_data.drop(columns=["Name","Ticket","Cabin"])#连续
continuous_features=train_data.select_dtypes(include=['float64','int64']).columns.tolist()
#离散
discrete_features=train_data.select_dtypes(exclude=['float64','int64']).columns.tolist()#离散特征使用众数进行补全
for feature in discrete_features:if train_data[feature].isnull().sum()>0: mode_value = train_data[feature].mode()[0] train_data[feature].fillna(mode_value, inplace=True)#连续变量用中位数进行补全
for feature in continuous_features: if train_data[feature].isnull().sum()>0: median_value = train_data[feature].median() train_data[feature].fillna(median_value, inplace=True)
train_data.info()
再次查看
train_data.head(10)
接下来对sex、embarked进行独热编码
# 对Sex、Embarked进行独热编码
train_data["Sex"]=pd.get_dummies(train_data["Sex"],dtype=int,drop_first=True)
train_data = pd.concat([train_data.drop("Embarked", axis=1), pd.get_dummies(train_data["Embarked"], prefix="Embarked", dtype=int, drop_first=False)], axis=1)# 查看数据
train_data.head(10)
(4)构建模型并预测结果
到这里才发现,其实一开始应该把train和test合起来一起做数据预处理的,这样不用再写一遍几乎一样的代码......光想着处理训练集、看训练集情况了
#合起来一起处理的代码
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
combine = [train_data, test_data] # 合并数据
# 这样的话整理清洗数据的操作只需要对combine做一遍,就能实现train、test同时被同样的预处理 #
# 注意:这只是放到一个列表,不是合并
#combined_data = pd.concat([train_data, test_data], axis=1, ignore_index=True)这才是合并
#combine.head()会报错,因为列表没有head方法
test_data = pd.read_csv('test.csv')
test_data.info()
#删除无用特征Name、Ticket 、Cabin,补全缺失值
test_data = test_data.drop(columns=["Name","Ticket","Cabin"])#连续
continuous_features=test_data.select_dtypes(include=['float64','int64']).columns.tolist()
#离散
discrete_features=test_data.select_dtypes(exclude=['float64','int64']).columns.tolist()#离散特征使用众数进行补全
for feature in discrete_features:if test_data[feature].isnull().sum()>0: mode_value = test_data[feature].mode()[0] test_data[feature].fillna(mode_value, inplace=True)#连续变量用中位数进行补全
for feature in continuous_features: if test_data[feature].isnull().sum()>0: median_value = test_data[feature].median() test_data[feature].fillna(median_value, inplace=True)
test_data.info()test_data.head(10)
# 对Sex、Embarked进行独热编码
test_data["Sex"]=pd.get_dummies(test_data["Sex"],dtype=int,drop_first=True)
test_data = pd.concat([test_data.drop("Embarked", axis=1), pd.get_dummies(test_data["Embarked"], prefix="Embarked", dtype=int, drop_first=False)], axis=1)# 查看数据
test_data.head(10)
test_data.info()
from sklearn.model_selection import train_test_split
X = train_data.drop(['Survived'], axis=1) # 特征,axis=1表示按列删除
y = train_data['Survived'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))
# 对测试集进行预测
test_pred = rf_model.predict(test_data)# 创建提交文件
submission = pd.DataFrame({'PassengerId': test_data['PassengerId'], # 从测试数据中获取乘客ID'Survived': test_pred # 模型预测的结果
})# 保存为CSV文件
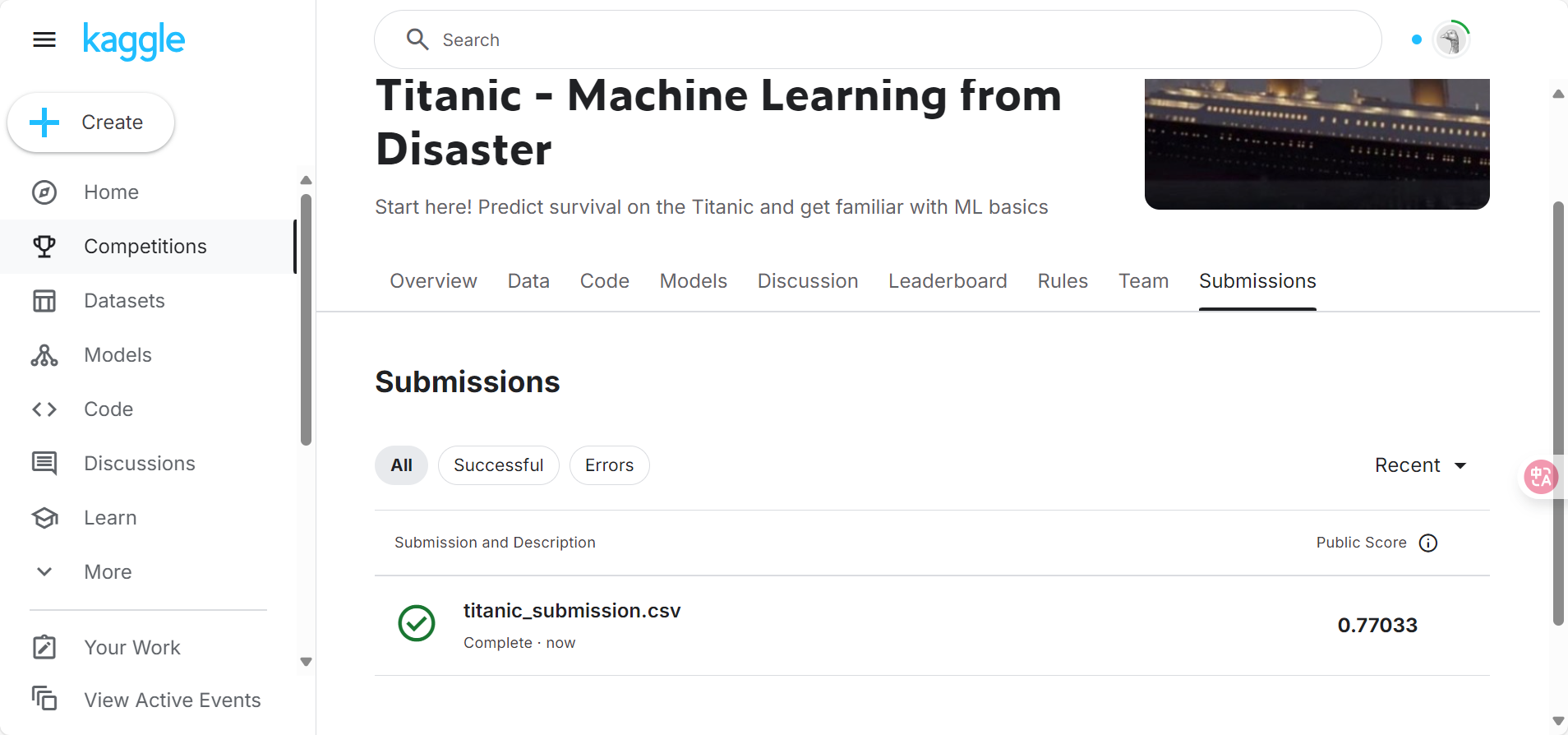
submission.to_csv('titanic_submission.csv', index=False)最后提交到kaggle上试试
笔记
1.#describe()方法只描述数值型数据
2.train_df.describe(include=['O']): 获取非数值型(对象型)列的描述性统计信息的方法
count:非缺失值的数量。
unique:唯一值的数量,表示多少种数值
top:出现次数最多的值。
freq:出现次数最多的值的频数。
3.使用正则表达式提取Title特征:
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand=False)
# 从姓名字符串中匹配一个或多个字母,并且以句点 (.) 结尾的部分,这通常是表示称号的部分
# 提取的称号被存储在一个新的 Title 列中
4.学习和参考了一下训练营其他友友的打卡分享,感叹一下人和人的差距怎么可以这么大......我太菜了
@浙大疏锦行