【数据结构与算法】——图(二)
前言
本文主要介绍深度优先遍历(DFS)和广度优先遍历(BFS),邻接矩阵和邻接表度的计算方法
本人其他博客:https://blog.csdn.net/2401_86940607
图的基本概念和存储结构:【数据结构与算法】——图(一)
源代码见gitte: https://gitee.com/mozhengy
正文
本文所用代码声明Graph.h文件
#pragma once
#include<iostream>
#include<math.h>
#include<stdio.h>#define MAXV 20
#define INF 1e9
typedef int InfoType;
typedef struct ANode
{int adjvex; //该边的邻接点的编号struct ANode* nextarc; //指向下一边的指针int weight; //该边的相关信息(这里是整形的权值)
}ArcNode; //边结点的类型typedef struct Vnode
{InfoType data; //顶点的其他信息ArcNode* firstarc;//指向第一个边结点
}VNode; //邻接表头结点的类型typedef struct
{VNode adjlist[MAXV];//邻接表头结点的数组int n; //顶点数int e; //边数
}AdjGraph; //完整图的类型//创建图
void CreateAdj(AdjGraph*& G, int A[MAXV][MAXV], int n, int e);//输出
void DisAdj(AdjGraph* G);//销毁
void DeatroyAdj(AdjGraph* G);//度的计算
// 无向图
int GetGraph(AdjGraph* G, int v);//有向图
int GetOutDegree(AdjGraph* G, int v);//出度
int GetInDegree(AdjGraph* G, int v); //入度//深度优先遍历
void DFS(AdjGraph* G, int v);//广度优先遍历
void BFS(AdjGraph* G, int v);
1.图的遍历
从给定图的任意指定顶点出发(称为初始点),按照某种搜索方法沿着图的边访问图的所有顶点,每个顶点访问一次,这个过程称为图的遍历
由于图从初始点到顶点有多条路径,当图沿着一条路径访问过顶点之后,可能还要沿着一条路径回到顶点,即存在回路。为了避免重复访问,可设置一个标记数组visited[ ],第i个结点访问过置为1,否则为0.
根据搜索方式的不同,图的遍历分为深度优先遍历和广度优先遍历
1.1 图的深度优先遍历
>基本思路
从某个顶点v出发
(1)先访问v
(2)选择一个与v相邻但未访问的结点w,从w开始深度优先遍历(这里可以看出是递归了)
(3)当w没有相邻结点或者所有相邻结点已经访问完成,从w回溯到v,再选择一个和v相邻但没有与w重复的结点 w 1 w_1 w1
(4)重复上述过程直到所有顶点都访问过为止
下面以邻接表为例,邻接表实现代码见上一篇文章图的基本概念和存储结构:【数据结构与算法】——图(一)
深度优先遍历实现
//深度优先遍历
int visites[MAXV] = { 0 };
void DFS(AdjGraph* G, int v)
{ArcNode* p;visites[v] = 1;printf("%d ", v);p = G->adjlist[v].firstarc;while (p != NULL){if (!visites[p->adjvex]){DFS(G, p->adjvex);}p = p->nextarc;}
}测试函数
void test() {int A[MAXV][MAXV] = {{0, 1, 2, INF},{1, 0, INF, 3},{2, INF, 0, 4},{INF, 3, 4, 0}};int n = 4; // 顶点数int e = 5; // 边数AdjGraph* G;// 创建图CreateAdj(G, A, n, e);// 输出图的邻接表printf("图的邻接表表示:\n");DisAdj(G);printf("DFS算法\n");DFS(G, 0);printf("\n");// 销毁图DeatroyAdj(G);printf("图已销毁。\n");
}
int main()
{test();return 0;
}
示例图
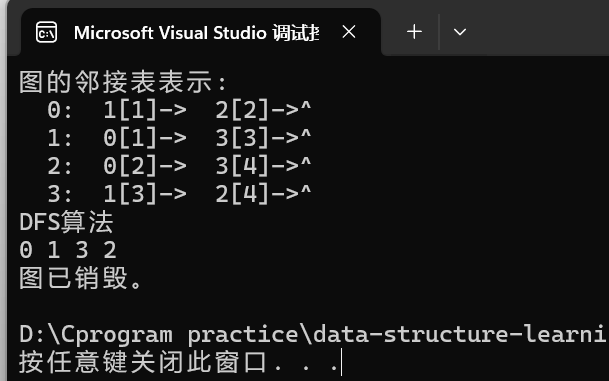
注意:当v连接多个顶点时,一般优先遍历较小的一个
1.2 图的广度优先遍历
- 定义与核心思想
广度优先遍历(Breadth-First Search, BFS) 是一种基于队列的图遍历算法,其核心思想是:
- 逐层访问:从初始顶点出发,依次访问其所有邻接顶点,再按顺序访问这些邻接顶点的邻接顶点,以此类推。
- 队列辅助:使用队列记录待访问的顶点,确保按层级顺序遍历。
特点:
- 适用于无权图的最短路径查找(单源最短路径)。
- 遍历结果形成一棵“广度优先树”。
- 算法流程
2.1 基本步骤
- 初始化:
- 选择起始顶点 ( v ),标记为已访问。
- 将 ( v ) 加入队列。
- 循环处理队列:
- 从队列头部取出顶点 ( w )。
- 遍历 ( w ) 的所有未访问邻接顶点:
- 标记为已访问。
- 加入队列尾部。
- 终止条件:
- 队列为空时结束遍历。
2.2 流程图解
- 示例解析
示例描述
图示例:
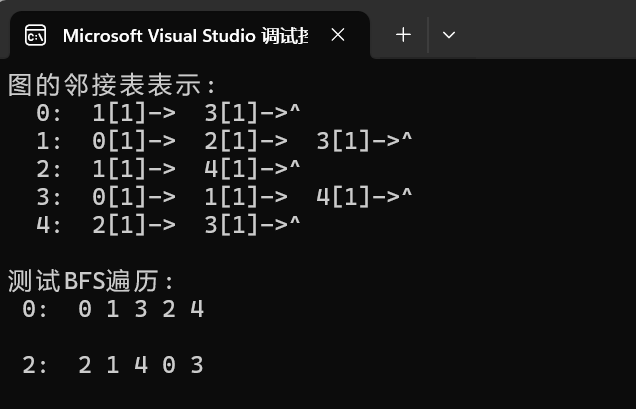
从顶点0开始进行BFS遍历:
- 邻接表结构:顶点0的邻接点为1、3,顶点1的邻接点为3、2,顶点3的邻接点为4,顶点2的邻接点为4。
** 遍历过程**
- 初始队列:
[0],访问顺序:0。 - 处理顶点0,邻接点1、3入队。队列:
[1, 3],访问顺序:0 → 1 → 3。 - 处理顶点1,邻接点2入队。队列:
[3, 2],访问顺序:0 → 1 → 3 → 2。 - 处理顶点3,邻接点4入队。队列:
[2, 4],访问顺序:0 → 1 → 3 → 2 → 4。 - 处理顶点2和4,无新邻接点,队列清空。
最终访问序列:0 → 1 → 3 → 2 → 4 或 0 → 3 → 1 → 2 → 4(因邻接点访问顺序可能不同)。
- 代码实现与解析
4.1 代码框架
void BFS(AdjGraph *G, int v) {int w, i;ArcNode *p;SqQueue *qu; // 定义环形队列指针InitQueue(qu); // 初始化队列int visited[MAXV]; // 访问标记数组for (i = 0; i < G->n; i++) // 初始化标记数组visited[i] = 0;printf("%2d", v); // 访问起始顶点visited[v] = 1; // 标记已访问enQueue(qu, v); // 起始顶点入队while (!QueueEmpty(qu)) { // 队列非空时循环deQueue(qu, &w); // 出队顶点wp = G->adjlist[w].firstarc; // 指向w的第一个邻接点while (p != NULL) { // 遍历所有邻接点if (visited[p->adjvex] == 0) { printf("%2d", p->adjvex); // 访问邻接点visited[p->adjvex] = 1; // 标记已访问enQueue(qu, p->adjvex); // 邻接点入队}p = p->nextarc; // 处理下一个邻接点}}printf("\n");
}
void test1()
{// 创建一个包含5个顶点的示例图AdjGraph* G;int n = 5; // 顶点数int e = 7; // 边数// 邻接矩阵表示int A[MAXV][MAXV] = {{0, 1, 0, 1, 0}, // 顶点0连接到顶点1和3{1, 0, 1, 1, 0}, // 顶点1连接到顶点0,2,3{0, 1, 0, 0, 1}, // 顶点2连接到顶点1和4{1, 1, 0, 0, 1}, // 顶点3连接到顶点0,1,4{0, 0, 1, 1, 0} // 顶点4连接到顶点2和3};// 创建图CreateAdj(G, A, n, e);// 输出图的邻接表printf("图的邻接表表示:\n");DisAdj(G);// 测试BFS从顶点0开始printf("\n测试BFS遍历:\n");BFS(G, 0);printf("\n");// 测试BFS从顶点2开始BFS(G, 2);// 销毁图DeatroyAdj(G);
}
int mian()
{test1()return 0;
}
总结:广度优先遍历通过队列实现层级扩展,适合解决最短路径和连通性问题,其时间复杂度与图的存储结构密切相关。
循环队列代码:
// 循环队列类型定义
typedef struct {int data[MAXV];int front, rear;
} SqQueue;// 初始化队列
void InitQueue(SqQueue* qu) {qu->front = qu->rear = 0;
}// 判断队列是否为空
int QueueEmpty(SqQueue* qu) {return qu->front == qu->rear;
}// 判断队列是否已满
int QueueFull(SqQueue* qu) {return (qu->rear + 1) % MAXV == qu->front;
}// 入队 - 修改为返回状态码
int enQueue(SqQueue* qu, int x) {if (QueueFull(qu)) {printf("Error: Queue is full\n");return 0; // 失败}qu->rear = (qu->rear + 1) % MAXV;qu->data[qu->rear] = x;return 1; // 成功
}// 出队 - 修改为返回状态码和值
int deQueue(SqQueue* qu, int* x) {if (QueueEmpty(qu)) {printf("Error: Queue is empty\n");return 0; // 失败}qu->front = (qu->front + 1) % MAXV;*x = qu->data[qu->front];return 1; // 成功
}1.3 总结与对比
- 时间复杂度分析
| 存储结构 | 时间复杂度 | 原因说明 |
|---|---|---|
| 邻接表 | (O(n + e)) | 需遍历所有顶点和边的链表。 |
| 邻接矩阵 | O ( n 2 ) O(n^2) O(n2) | 需检查每个顶点的所有 (n) 个元素。 |
- BFS与DFS对比
| 特性 | BFS | DFS |
|---|---|---|
| 数据结构 | 队列 | 栈(递归或显式栈) |
| 遍历顺序 | 按层级逐层遍历 | 深度优先,回溯探索 |
| 空间复杂度 | 最坏 (O(n))(队列存储) | 最坏 (O(n))(递归栈深度) |
| 应用场景 | 最短路径、连通性检测 | 拓扑排序、回溯问题 |
2 度的计算
1. 度的定义
在图中,顶点的度(Degree) 表示与该顶点直接相连的边的数量:
无向图:顶点的度 = 邻接顶点的数量。
有向图:
- 出度(Out-degree):以该顶点为起点的弧的数量。
- 入度(In-degree):以该顶点为终点的弧的数量。
公式:
无向图的边数 e = 1 2 ∑ i = 0 n − 1 T D ( v i ) e = \frac{1}{2} \sum_{i=0}^{n-1} TD(v_i) e=21∑i=0n−1TD(vi)
有向图的边数 e = ∑ i = 0 n − 1 O D ( v i ) = ∑ i = 0 n − 1 I D ( v i ) e = \sum_{i=0}^{n-1} OD(v_i) = \sum_{i=0}^{n-1} ID(v_i) e=∑i=0n−1OD(vi)=∑i=0n−1ID(vi)
2. 无向图的度计算
2.1 计算逻辑
- 输入检查:验证顶点索引是否合法。
- 遍历邻接链表:统计邻接链表中节点的数量。
2.2 代码实现
int GetGraph(AdjGraph* G, int v) {if (v < 0 || v >= G->n) return -1; // 输入合法性检查int d = 0;ArcNode* p = G->adjlist[v].firstarc; // 指向顶点v的邻接链表头while (p != NULL) { // 遍历链表d++;p = p->nextarc;}return d; // 返回度
}
3. 有向图的入度与出度计算
3.1 出度计算
逻辑:与无向图相同,直接统计邻接链表长度。
int GetOutDegree(AdjGraph* G, int v) {return GetGraph(G, v); // 复用无向图度计算函数
}
3.2 入度计算
逻辑:遍历所有顶点的邻接链表,统计指向目标顶点的边数。
int GetInDegree(AdjGraph* G, int v) {if (v < 0 || v >= G->n) return -1; // 输入合法性检查int inDegree = 0;for (int u = 0; u < G->n; u++) { // 遍历所有顶点ArcNode* p = G->adjlist[u].firstarc;while (p != NULL) { // 遍历顶点u的邻接链表if (p->adjvex == v) inDegree++; // 找到指向v的边p = p->nextarc;}}return inDegree;
}
4. 代码实现解析
4.1 关键数据结构
AdjGraph:图的邻接表结构,包含顶点表adjlist[]和顶点数n。ArcNode:邻接链表的节点,包含邻接顶点索引adjvex和指向下一个节点的指针nextarc。
4.2 入度计算优化:若使用逆邻接表(存储指向顶点的边),可将时间复杂度从 O ( n + e ) O(n+e) O(n+e) 降至 O ( e ) O(e) O(e)。
5. 时间复杂度分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 无向图度计算 | O ( d ) O(d) O(d) | d d d 为顶点的度 |
| 有向图出度计算 | O ( d ) O(d) O(d) | d d d 为顶点的出度 |
| 有向图入度计算 | O ( n + e ) O(n + e) O(n+e) | 需遍历所有顶点和边 |
总结:
无向图度计算直接高效,时间复杂度为 O ( d ) O(d) O(d)。
有向图入度计算需全局遍历,时间复杂度较高,实际应用中需结合存储结构优化。
总结
深度优先遍历和广度优先遍历时图中十分重要的内容,在下一篇文章有重要作用
如有错误还望多多指正,写作耗时还望三连支持