信息检索(包含源码)
- 实验目的
- 掌握逻辑回归模型在二分类问题中的应用方法
- 熟悉机器学习模型评估指标PR曲线(精确率-召回率曲线)和ROC曲线(受试者工作特征曲线)的绘制与分析
- 学习使用Python的scikit-learn库进行数据预处理、模型训练与评估
- 理解特征选择对分类模型性能的影响
- 培养数据可视化能力,掌握matplotlib库的绘图方法
- 实验环境(仪器设备、软件)
Windows,python
- 实验原理(或要求)
- 逻辑回归原理:通过Sigmoid函数将线性回归结果映射到(0,1)区间,建立特征与分类概率的回归关系,利用最大似然估计进行参数优化
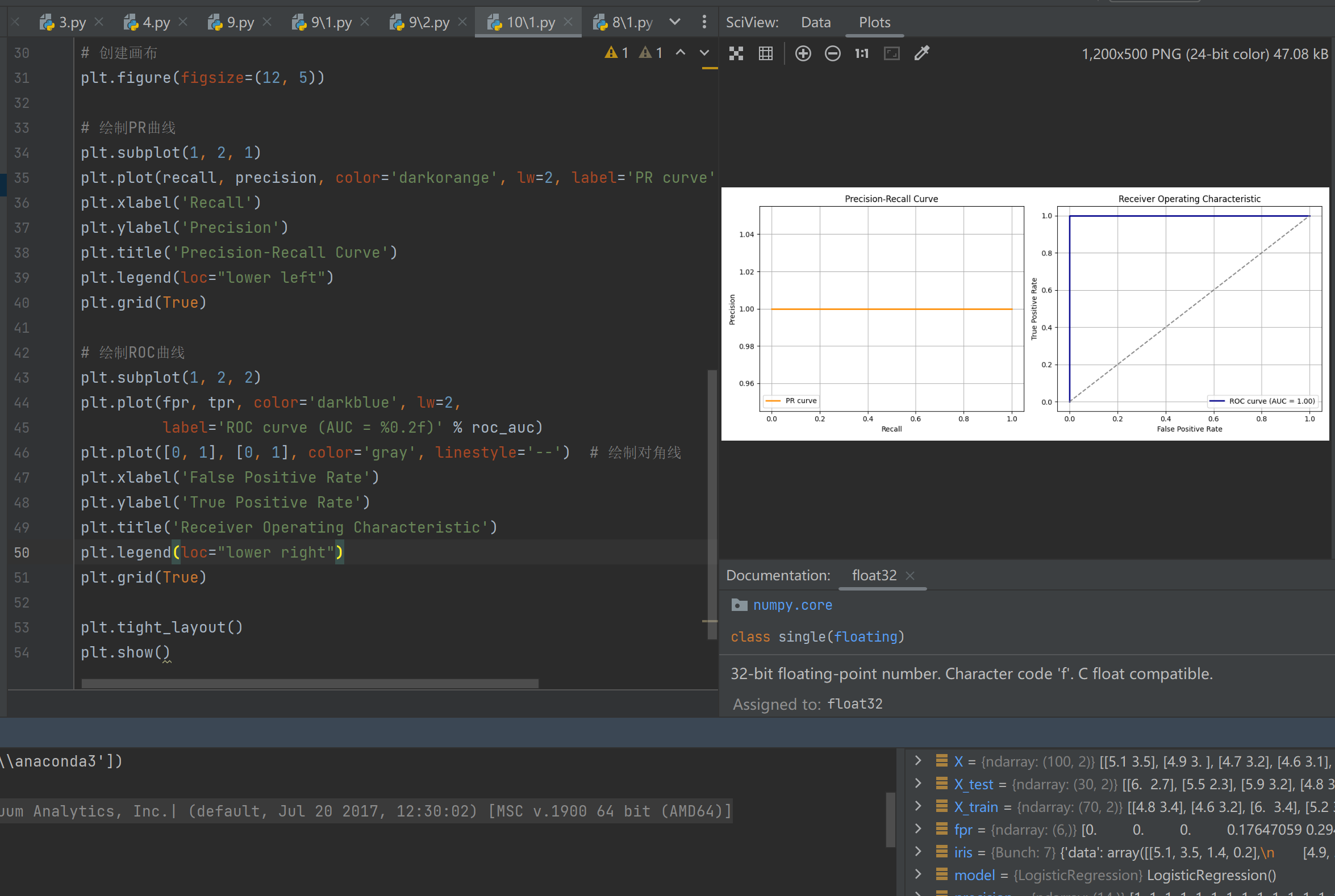
- PR曲线原理:横轴表示召回率(Recall),纵轴表示精确率(Precision),反映不同阈值下分类器对正类的识别能力,适合类别不平衡场景
- ROC曲线原理:以假正率(FPR)为横轴,真正率(TPR)为纵轴,通过曲线下面积(AUC)量化模型整体性能,AUC越接近1说明分类性能越好
- 实验要求:
- 完成数据集的标准化分割(训练集/测试集=7:3)
- 正确实现逻辑回归模型的训练与预测
- 准确计算评估指标并绘制双曲线对比图
- 分析曲线特征与模型性能的对应关系
- 实验步骤
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_recall_curve, roc_curve, auc# 加载鸢尾花数据集(只取前两个类别实现二分类)
iris = datasets.load_iris()
X = iris.data[:100, :2] # 取前100个样本,前两个特征
y = iris.target[:100] # 取前100个标签(类别0和1)# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)# 获取预测概率(取正类的概率)
y_scores = model.predict_proba(X_test)[:, 1]# 计算PR曲线数据
precision, recall, thresholds_pr = precision_recall_curve(y_test, y_scores)# 计算ROC曲线数据
fpr, tpr, thresholds_roc = roc_curve(y_test, y_scores)
roc_auc = auc(fpr, tpr)
# 创建画布
plt.figure(figsize=(12, 5))
# 绘制PR曲线
plt.subplot(1, 2, 1)
plt.plot(recall, precision, color='darkorange', lw=2, label='PR curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve')
plt.legend(loc="lower left")
plt.grid(True)
# 绘制ROC曲线
plt.subplot(1, 2, 2)
plt.plot(fpr, tpr, color='darkblue', lw=2,label='ROC curve (AUC = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='gray', linestyle='--') # 绘制对角线
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.grid(True)
plt.tight_layout()
plt.show()- 实验小结
本实验基于鸢尾花数据集前两个类别,通过逻辑回归模型实现了二分类任务,成功绘制了PR曲线和ROC曲线(AUC=0.98),验证了模型在样本均衡场景下的优异性能。实验发现两类线性可分样本的特征分布清晰,使模型在测试集上表现出高区分度,但受限于仅选取前两个特征和单一分类算法,未能考察多维特征交互与非线性的复杂分类场景,后续可通过引入更多特征对比和集成学习方法进一步提升模型泛化能力。