六、Hadoop初始化与启动
成功部署一个Hadoop集群并不仅仅是安装好软件那么简单。在它真正能够为我们处理海量数据之前,还需要一系列精心的初始化和启动步骤。这些步骤确保了各个组件能够正确协同工作。完成启动后,Hadoop还提供了便捷的 Web 用户界面 (Web UI),帮助我们监控集群状态和作业运行情况。
一、准备工作:集群启动前的基石
在深入初始化和启动细节之前,有几个前提条件必须得到满足:
- Hadoop 安装与配置:所有集群节点上都已正确安装了Hadoop,并且核心配置文件(如
core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml以及workers(或slaves) 文件)已根据集群规划(例如 NameNode、ResourceManager 的位置,DataNode 和 NodeManager 列表等)妥善配置。 - Java 环境:所有节点都已安装并配置了合适版本的 Java Development Kit (JDK),且
JAVA_HOME环境变量已正确设置。 - SSH 免密登录:为了让主节点 (通常是运行 NameNode 和 ResourceManager 的节点) 能够通过脚本启动和停止其他节点上的Hadoop守护进程,需要配置从主节点到所有工作节点 (以及主节点自身) 的SSH 免密登录。
二、HDFS 初始化:格式化文件系统 (关键且仅一次)
对于一个全新的Hadoop集群,或者当你想彻底清空HDFS数据并重新开始时,需要对HDFS进行格式化。这个操作至关重要,因为它会创建NameNode所需的初始文件系统结构和元数据存储目录。
- 操作命令:在NameNode所在的机器上执行:
hdfs namenode -format
- 重要警告:
- 此操作会清空NameNode配置的元数据目录 (由
dfs.namenode.name.dir参数指定)。 - 绝对不要在一个已经存有数据的生产环境 HDFS上执行此命令,除非你确切知道你在做什么,并且打算删除所有数据!
- 这通常是一个一次性的操作,仅在首次部署集群时进行。
- 此操作会清空NameNode配置的元数据目录 (由
格式化成功后,你会在NameNode的元数据目录下看到初始化的文件和子目录结构。
三、启动与停止 Hadoop 集群:唤醒与休眠巨象
集群的启动和停止通常分两步进行:先操作 HDFS 服务,再操作 YARN 服务。除了整体启停脚本,Hadoop也提供了针对单个组件的启停命令,这在调试或特定维护场景下非常有用。
(一) HDFS 服务的启动与停止
- 整体启动/停止 HDFS:
启动:在主节点 (NameNode所在节点) 上执行:
start-dfs.sh
此脚本会启动NameNode、所有DataNode及SecondaryNameNode。
停止:在主节点上执行:
stop-dfs.sh
- 单独启动/停止 NameNode:
启动:在NameNode机器上执行:
hdfs --daemon start namenode
# 或者 hdfs namenode (前台运行,用于调试)
停止:在NameNode机器上执行:
hdfs --daemon stop namenode
- 单独启动/停止 DataNode:
- 启动:在每个 DataNode机器上执行:
hdfs --daemon start datanode
# 或者 hdfs datanode (前台运行)
停止:在每个 DataNode机器上执行:
hdfs --daemon stop datanode
- 单独启动/停止 SecondaryNameNode:
- 启动:在SecondaryNameNode机器上执行:
hdfs --daemon start secondarynamenode
# 或者 hdfs secondarynamenode (前台运行)
停止:在SecondaryNameNode机器上执行:
hdfs --daemon stop secondarynamenode
(二) YARN 服务的启动与停止
- 整体启动/停止 YARN:
- 启动:在主节点 (ResourceManager所在节点) 上执行:
start-yarn.sh
此脚本会启动ResourceManager及所有NodeManager。
停止:在主节点上执行:
stop-yarn.sh
- 单独启动/停止 ResourceManager:
- 启动:在ResourceManager机器上执行:
yarn --daemon start resourcemanager
# 或者 yarn resourcemanager (前台运行)
停止:在ResourceManager机器上执行:
yarn --daemon stop resourcemanager
- 单独启动/停止 NodeManager:
- 启动:在每个 NodeManager机器上执行:
yarn --daemon start nodemanager
# 或者 yarn nodemanager (前台运行)
停止:在每个 NodeManager机器上执行:
yarn --daemon stop nodemanager
(三) 一键启动/停止 (可选但需谨慎)
Hadoop也提供了一键启停脚本:
- 启动:
start-all.sh
- 停止:
stop-all.sh
这些脚本实际上是依次调用对应的 *-dfs.sh 和 *-yarn.sh 脚本。在较新版本中,它们可能已被标记为不推荐使用,建议分开操作以获得更清晰的控制和问题排查能力。
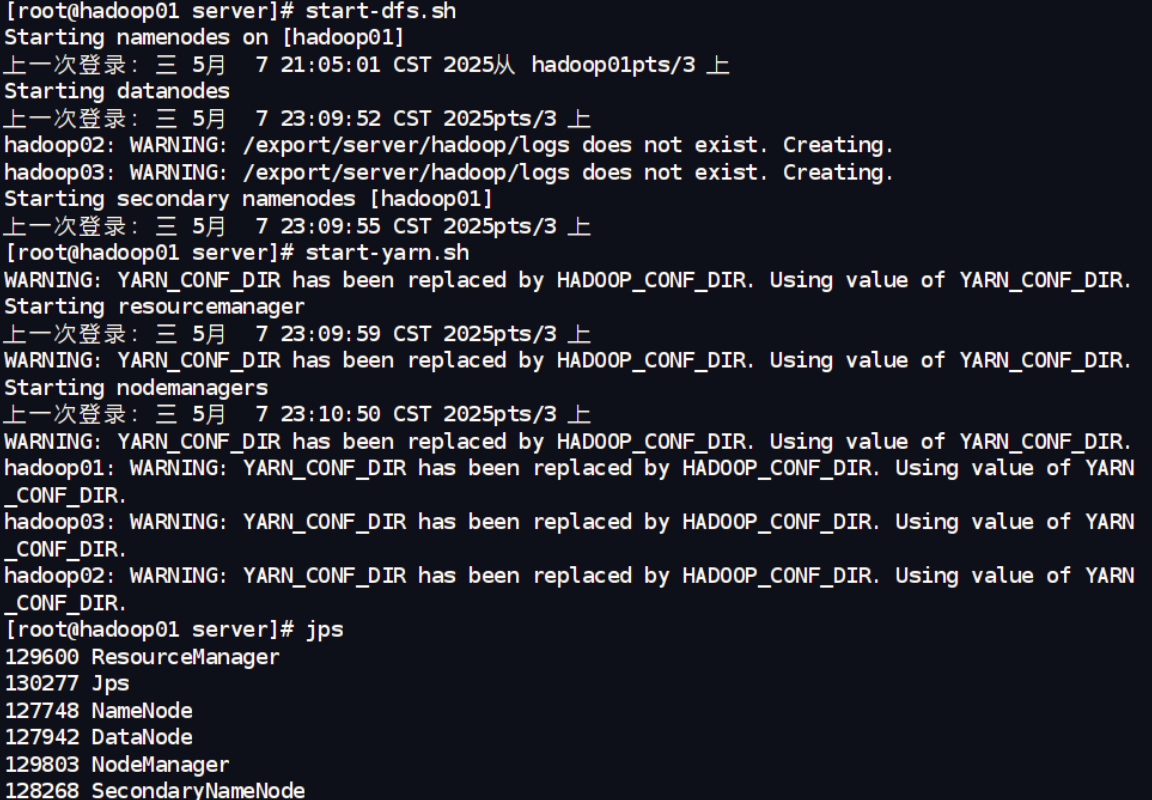
(四) 验证启动状态
在启动任何服务后,都应进行验证:
- 使用
jps命令在相应节点上检查Java进程是否存在 (如NameNode进程、DataNode进程、ResourceManager进程、NodeManager进程等)。 - 仔细查看各个组件的日志文件 (通常位于Hadoop安装目录下的
logs文件夹),排查是否有错误或警告信息。
四、访问 Hadoop Web UI:集群的仪表盘
一旦集群成功启动,你就可以通过Web浏览器访问各个组件的用户界面,来监控集群状态、浏览HDFS文件、跟踪应用程序进度等。
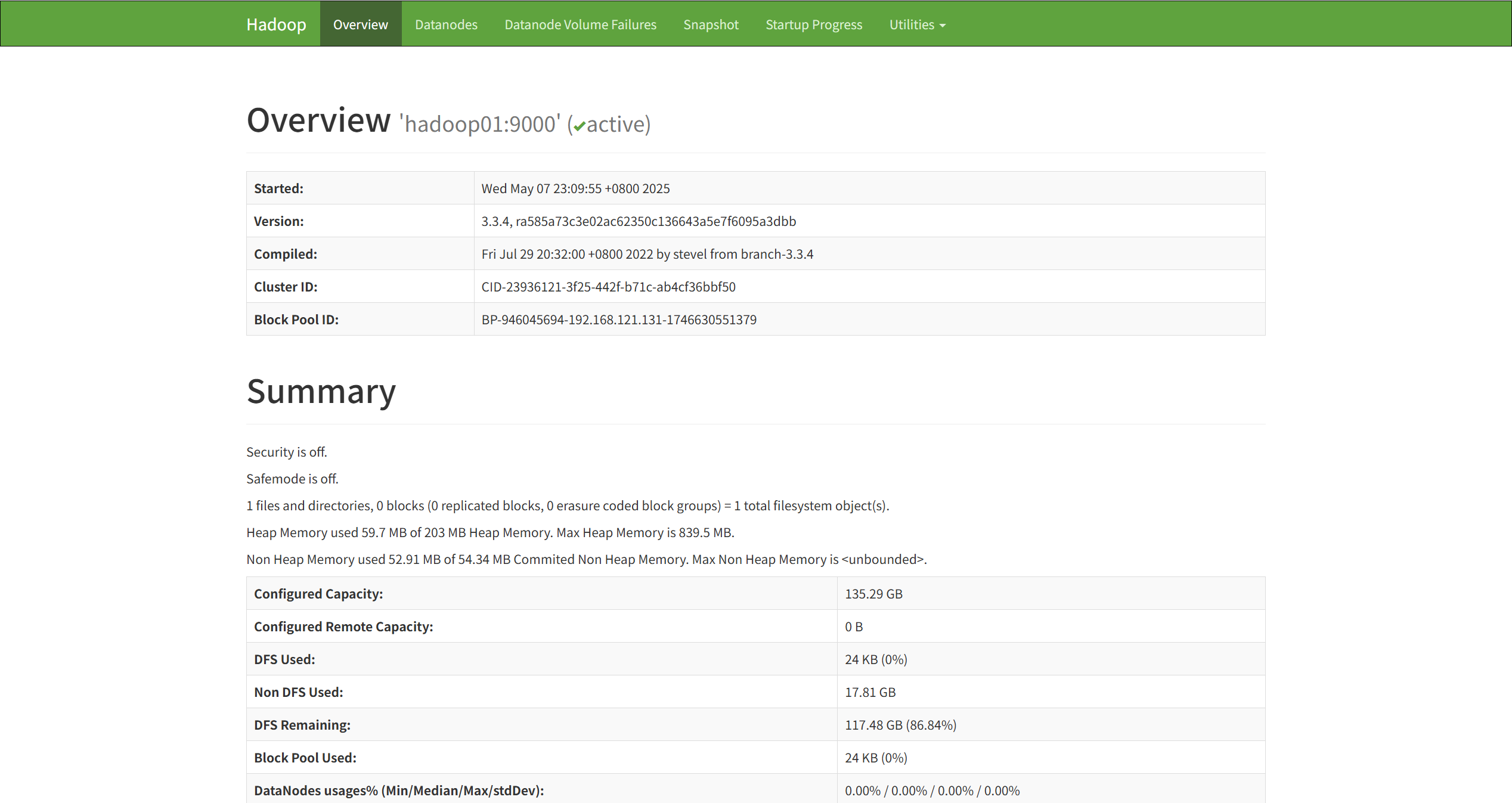
- HDFS NameNode Web UI (Overview):
默认端口:Hadoop 3.x:9870, Hadoop 2.x:50070
访问地址:主机名或IP:端口号
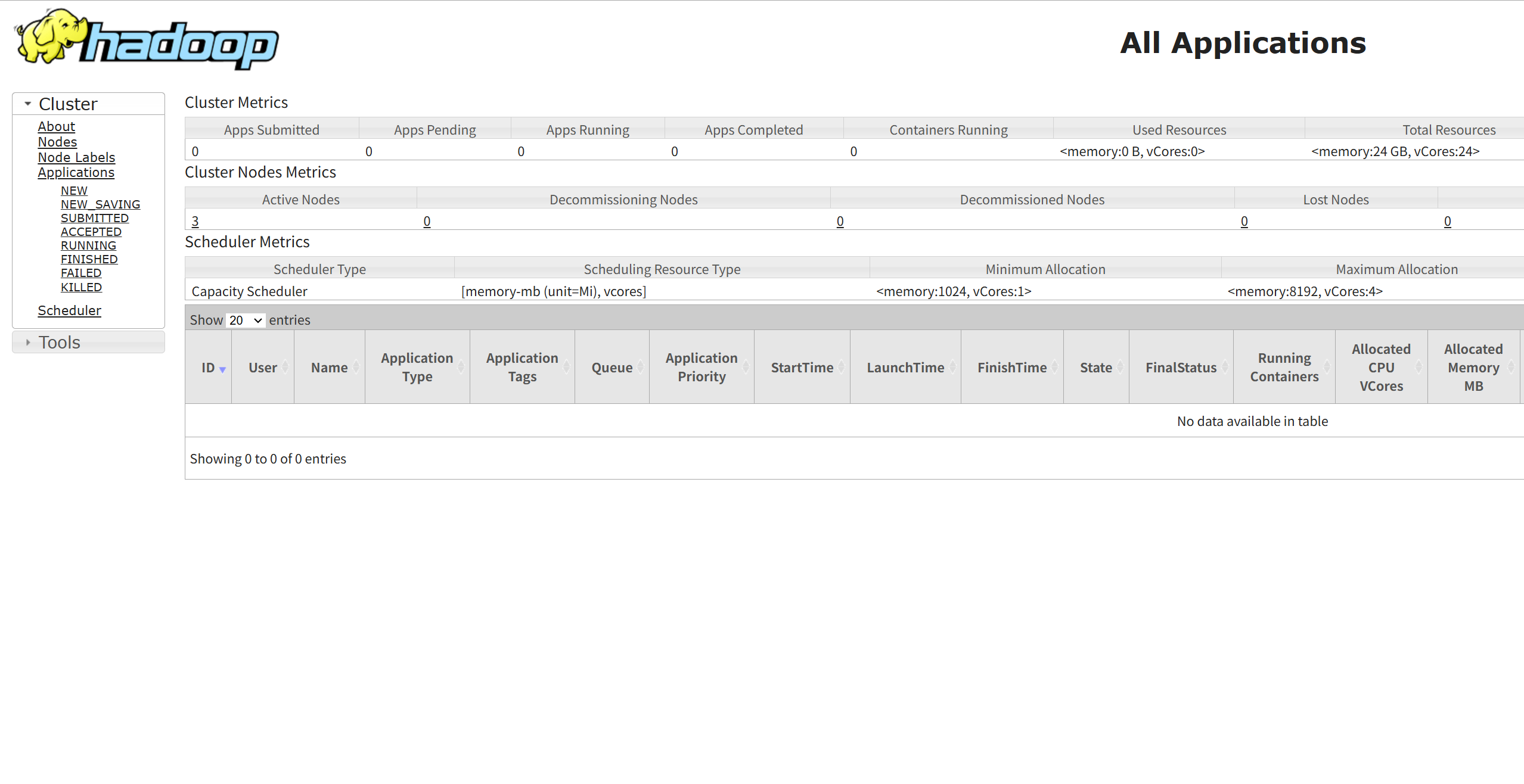
2. YARN ResourceManager Web UI (All Applications):
默认端口:8088
访问地址:主机名或IP:8088
结语:平稳运行的开端
Hadoop集群的正确初始化和启动是其后续稳定运行的关键前提。无论是整体启停还是精细到单个组件的独立操作,都需要操作者清晰理解其背后的逻辑。而熟练运用其Web UI,则能让你像一位经验丰富的船长一样,时刻掌握这艘数据巨轮的航行状态,及时发现问题并做出调整。随着实践的深入,这些操作会变得越来越得心应手。
好的,我们精简Web UI部分,只保留您截图中展示的 HDFS NameNode Overview 和 YARN ResourceManager All Applications 这两个核心界面。