《Python星球日记》 第47天:聚类与KMeans
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
专栏:《Python星球日记》,限时特价订阅中ing
目录
- 一、聚类与分类的区别
- 1. 监督学习 vs 无监督学习
- 2. 目标与应用不同
- 3. 实际比较
- 二、KMeans 算法原理与迭代过程
- 1. KMeans 算法简介
- 2. 关键概念
- 3. 迭代过程
- 4. 数学表示
- 三、评估聚类效果:轮廓系数
- 1. 聚类评估的挑战
- 2. 轮廓系数原理
- 3. 实际应用
- 四、代码练习:客户分群与图像颜色压缩
- 1. 客户分群案例
- 2. 图像颜色压缩案例
- 五、KMeans 的优缺点与应用场景
- 1. 优点
- 2. 缺点
- 3. 常见应用场景
- 六、总结与进阶
- 进阶学习方向:
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第46天:决策树与随机森林
欢迎来到Python星球的第47天!🪐
今天我们将探索机器学习中一个非常重要的无监督学习方法——聚类分析,并深入了解最经典的聚类算法之一:K-Means。无论你是想了解客户购买行为、压缩图像还是发现数据中的隐藏模式,聚类都是一个强大的工具。让我们开始今天的学习吧!
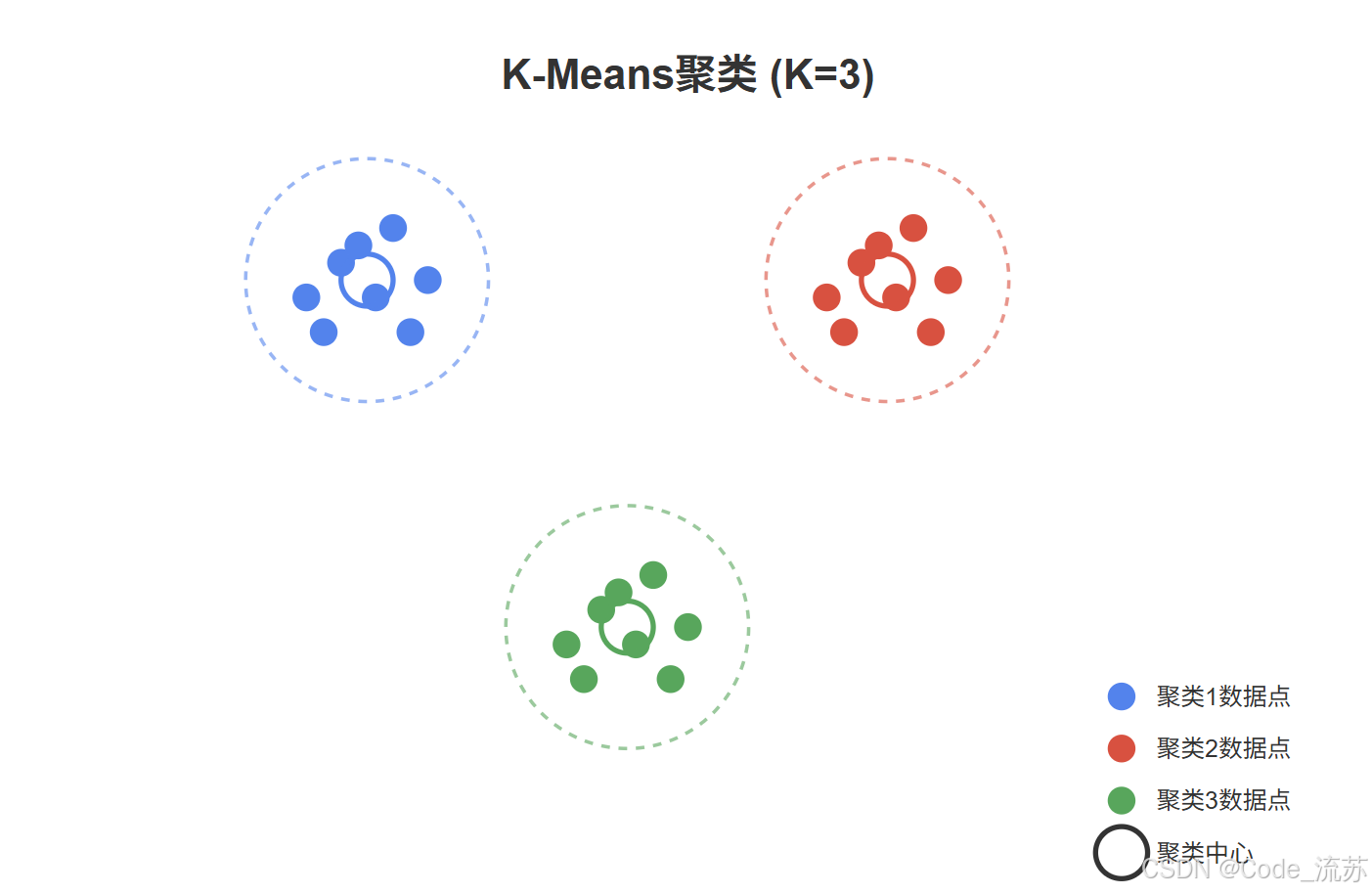
一、聚类与分类的区别
1. 监督学习 vs 无监督学习
分类是一种监督学习方法,而聚类是一种无监督学习方法。这是它们最根本的区别:
- 分类:需要有标记好的训练数据(即我们事先知道每个样本属于哪个类别),模型学习如何将新样本分配到已知的类别中。
- 聚类:没有标记数据,算法自己发现数据中的模式和结构,将相似的数据点分组到一起。
2. 目标与应用不同
-
分类的目标:将新数据正确分配到预定义的类别
- 例如:垃圾邮件过滤(是/否),疾病诊断(良性/恶性)
-
聚类的目标:发现数据的内在结构,将相似对象分组
- 例如:客户分群、文档主题发现、图像分割
3. 实际比较
假设你有一组客户数据:
- 分类任务:预测客户是否会购买某产品(需要历史购买记录作为标签)
- 聚类任务:根据购买行为将客户分成不同群体(不需要事先知道群体数量或特征)
二、KMeans 算法原理与迭代过程
1. KMeans 算法简介
K-Means 算法是最流行的聚类算法之一,因其简单直观而被广泛应用。算法名称中的 “K” 表示我们希望数据被分成的聚类数量,这是需要预先指定的。
算法的核心思想是:将数据分成 K 个组,使得同一组内的数据点彼此尽可能相似,不同组之间的数据点尽可能不同。
2. 关键概念
- 聚类中心(Centroid):每个簇的"中心点"或"平均点"
- 距离度量:通常使用欧几里得距离来衡量数据点之间的相似度
- 迭代优化:通过反复调整聚类中心位置来优化结果
3. 迭代过程
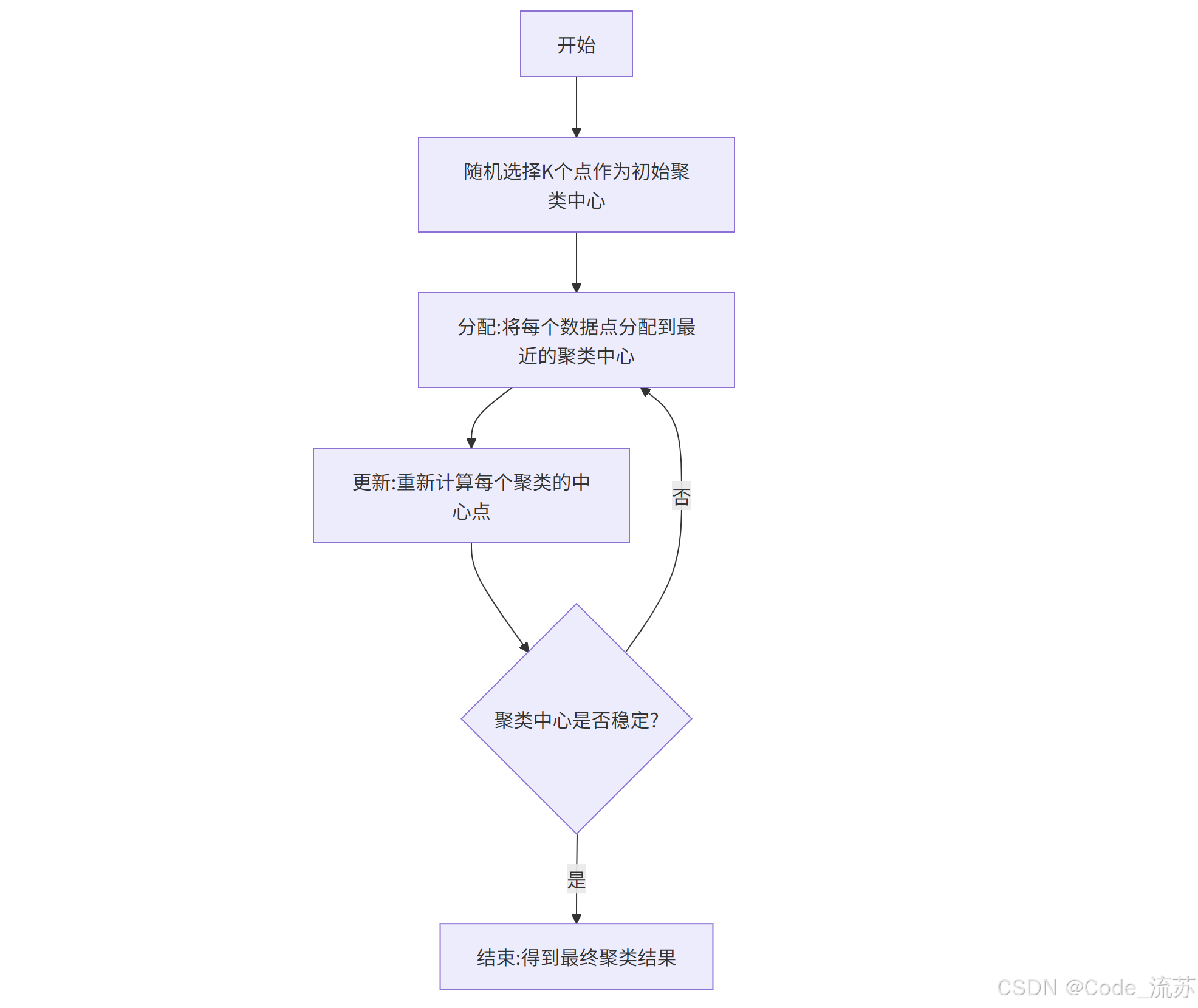
KMeans 算法的详细步骤如下:
-
初始化:
- 随机选择 K 个数据点作为初始聚类中心
-
迭代:
- 分配步骤:将每个数据点分配到距离最近的聚类中心
- 更新步骤:重新计算每个聚类的中心(所有点的平均位置)
- 重复以上两步,直到聚类中心基本不再变化或达到最大迭代次数
-
结束:
- 输出最终的 K 个聚类及其中心点
4. 数学表示
-
目标:最小化所有点到其聚类中心的距离平方和(即惯性,Inertia)
-
数学公式:
J = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 J = \sum_{i=1}^{k} \sum_{x \in C_i} ||x - \mu_i||^2 J=i=1∑kx∈Ci∑∣∣x−μi∣∣2
其中:
- J J J 是总体目标函数(需要最小化)
- k k k 是聚类数量
- C i C_i Ci 是第 i 个聚类
- μ i \mu_i μi 是第 i 个聚类的中心
- x x x 是属于聚类 C i C_i Ci 的数据点
三、评估聚类效果:轮廓系数
1. 聚类评估的挑战
与分类不同,聚类没有真实标签来评估结果。因此,我们需要使用内部指标来评估聚类质量:
- 紧凑性:同一聚类中的点应该彼此靠近
- 分离性:不同聚类之间应该明显分开
2. 轮廓系数原理
轮廓系数(Silhouette Coefficient)是一种综合评估聚类质量的指标,结合了紧凑性和分离性的考量。
对于每个数据点 i,计算:
a(i) = 平均簇内距离(i点到同簇其他点的平均距离)
b(i) = 最小簇间距离(i点到最近其他簇中所有点的平均距离)s(i) = (b(i) - a(i)) / max(a(i), b(i))
- s(i) 值范围在 [-1, 1] 之间
- s(i) 接近 1:数据点被很好地聚类
- s(i) 接近 0:数据点位于聚类边界
- s(i) 接近 -1:数据点可能被分配到错误的聚类
最终的轮廓系数是所有数据点 s(i) 的平均值。
3. 实际应用
轮廓系数可以帮助我们:
- 评估聚类的质量
- 确定最佳的 K 值(通常选择使轮廓系数最大的 K 值)
- 比较不同聚类算法的效果
# 使用 Scikit-learn 计算轮廓系数
from sklearn.metrics import silhouette_scoresilhouette_avg = silhouette_score(X, labels)
print(f"聚类的轮廓系数为: {silhouette_avg:.3f}")
四、代码练习:客户分群与图像颜色压缩
1. 客户分群案例
在营销和用户行为分析中,将客户分成不同群体是非常有价值的。下面,我们通过一个实例来展示如何使用 K-Means 进行客户分群:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score# 加载示例客户数据 (假设我们有购买金额和访问频率两个特征)
# 在实际应用中,你可能会从CSV文件或数据库加载数据
data = {'customer_id': range(1, 201),'purchase_amount': np.random.normal(500, 200, 200), 'visit_frequency': np.random.normal(10, 5, 200)
}
df = pd.DataFrame(data)# 为了模拟更真实的场景,我们创建几个高消费高频率和低消费低频率的客户
df.loc[0:20, 'purchase_amount'] = np.random.normal(1000, 100, 21)
df.loc[0:20, 'visit_frequency'] = np.random.normal(20, 2, 21)
df.loc[180:199, 'purchase_amount'] = np.random.normal(200, 50, 20)
df.loc[180:199, 'visit_frequency'] = np.random.normal(3, 1, 20)# 特征选择
X = df[['purchase_amount', 'visit_frequency']]# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 确定最佳聚类数 (使用轮廓系数)
silhouette_scores = []
K_range = range(2, 11)for k in K_range:kmeans = KMeans(n_clusters=k, random_state=42)labels = kmeans.fit_predict(X_scaled)silhouette_scores.append(silhouette_score(X_scaled, labels))# 找出最佳K值
best_k = K_range[np.argmax(silhouette_scores)]
print(f"最佳聚类数为: {best_k}")# 使用最佳K值进行最终聚类
kmeans = KMeans(n_clusters=best_k, random_state=42)
df['cluster'] = kmeans.fit_predict(X_scaled)# 可视化聚类结果
plt.figure(figsize=(10, 6))
colors = ['royalblue', 'crimson', 'forestgreen', 'darkorange', 'purple']for i in range(best_k):cluster_data = df[df['cluster'] == i]plt.scatter(cluster_data['purchase_amount'], cluster_data['visit_frequency'],c=colors[i % len(colors)], label=f'客户群 {i+1}')# 标记聚类中心
centers = scaler.inverse_transform(kmeans.cluster_centers_)
plt.scatter(centers[:, 0], centers[:, 1], s=200, marker='X', c='black', label='聚类中心'
)plt.title('客户分群 KMeans 结果')
plt.xlabel('购买金额')
plt.ylabel('访问频率')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()# 分析每个客户群的特征
for i in range(best_k):cluster_data = df[df['cluster'] == i]print(f"\n客户群 {i+1} 特征 (数量: {len(cluster_data)}):")print(f"平均购买金额: {cluster_data['purchase_amount'].mean():.2f}")print(f"平均访问频率: {cluster_data['visit_frequency'].mean():.2f}")
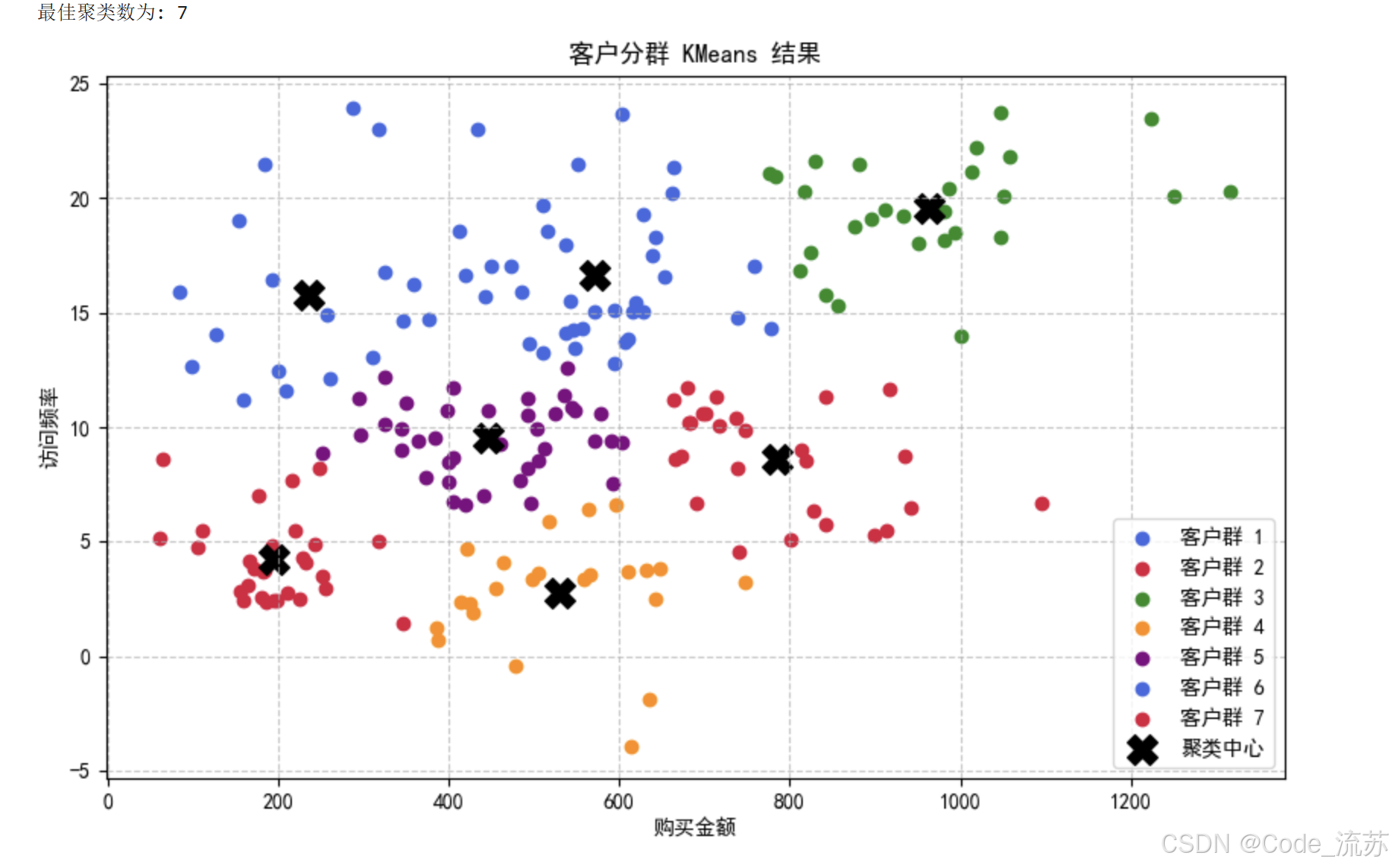

通过这个分析,我们可以识别出:
- 高价值客户:购买金额高且访问频率高
- 潜在发展客户:访问频率高但购买金额低
- 低活跃客户:访问频率低且购买金额低
- 季节性客户:购买金额高但访问频率低
2. 图像颜色压缩案例
K-Means 的另一个有趣应用是图像颜色压缩。通过将图像中的所有颜色聚类成 K 个代表颜色,可以大幅减少图像所需的颜色数量。
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.image import imread# 加载图片
img = imread(r'C:\Users\25399\Desktop\1.jpg') # 请使用本地的一张图片
print(f"原始图片大小: {img.shape}")# 将图片转换为二维数组,每行代表一个像素,有RGB三个通道
pixels = img.reshape(-1, 3)
print(f"转换后数据形状: {pixels.shape}")# 使用KMeans进行颜色聚类 (使用16个颜色)
n_colors = 16
kmeans = KMeans(n_clusters=n_colors, random_state=42)
kmeans.fit(pixels)# 替换每个像素的颜色为其所属聚类的中心颜色
compressed_palette = kmeans.cluster_centers_.astype('uint8')
compressed_pixels = compressed_palette[kmeans.labels_]
compressed_img = compressed_pixels.reshape(img.shape)# 显示对比结果
plt.figure(figsize=(12, 6))plt.subplot(1, 2, 1)
plt.imshow(img)
plt.title('原始图片 (数百万种颜色)')
plt.axis('off')plt.subplot(1, 2, 2)
plt.imshow(compressed_img)
plt.title(f'压缩后图片 (仅{n_colors}种颜色)')
plt.axis('off')plt.tight_layout()
plt.show()# 显示使用的调色板
plt.figure(figsize=(8, 2))
plt.title(f'使用的{n_colors}种颜色调色板')
for i in range(n_colors):plt.fill([i, i+1, i+1, i], [0, 0, 1, 1], color=compressed_palette[i]/255)
plt.xlim(0, n_colors)
plt.axis('off')
plt.show()
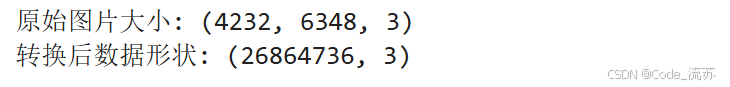

这个例子展示了 K-Means 如何帮助我们将图像从数百万种颜色压缩到仅 16 种颜色,同时保持图像的主要视觉特征。
五、KMeans 的优缺点与应用场景
1. 优点
- 简单直观:易于理解和实现
- 高效:计算复杂度较低,可以处理大数据集
- 适应性强:可用于各种类型的数据和应用场景
2. 缺点
- 需要预先指定 K 值:实际应用中可能难以确定
- 对初始聚类中心敏感:不同的初始化可能导致不同结果
- 对异常值敏感:异常值会显著影响聚类中心的位置
- 倾向于形成大小相等的簇:不适合处理不规则形状的簇
3. 常见应用场景
- 客户分群:识别具有相似购买行为的客户群体
- 图像分割与压缩:减少图像颜色数量,分割图像区域
- 异常检测:识别与主要聚类相距较远的数据点
- 文档聚类:将相似主题的文档分组在一起
- 推荐系统:基于用户行为相似性进行推荐
六、总结与进阶
今天我们学习了K-Means聚类算法,这是无监督学习中最重要的算法之一。我们了解了它与分类的区别,掌握了算法原理和迭代过程,学会了使用轮廓系数评估聚类效果,并通过客户分群和图像颜色压缩两个实例进行了实践。
进阶学习方向:
- 其他聚类算法:
- DBSCAN:基于密度的聚类,不需要预先指定聚类数量- 层次聚类:自下而上或自上而下构建聚类层次结构- 高斯混合模型:使用概率模型进行软聚类
- K-Means变种:
- K-Means++:改进的初始化方法,提高收敛速度- Mini-Batch K-Means:处理大数据集的优化版本
- 实际应用挑战:
- 高维数据处理:降维技术与聚类的结合- 可扩展性:处理超大规模数据集的技巧
到此为止,我们已经完成了第47天的学习内容。明天,我们将继续探索机器学习的精彩世界!如果你有任何问题,欢迎在评论区留言讨论。
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!