Dify 快速构建和部署基于LLM的应用程序
本文先对Dify做一个初步的认识,然后以一个实际的简单金融问答案例,配置chatflow 工作流。
一、Dify简介
如果你是第一次接触Dify,可以先创建一个简单的聊天助手,初步感觉一下,Dify在构建聊天问答类应用的过程。
比如下面这个聊天助手,是基于知识库的,直接编辑一段提示词,然后在选择一个你自己的PDF 或者 word 文档,就可以实现一个简单的基于知识库的聊天助手。
提示词不会写,影响不大,你写一点,可以使用自动生成提示词这个功能,帮你自动完善提示词。
Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,可以快速从原型到生产。以下是其核心功能列表:
-
工作流: 在画布上构建和测试功能强大的 AI 工作流程,利用以下所有功能以及更多功能。
-
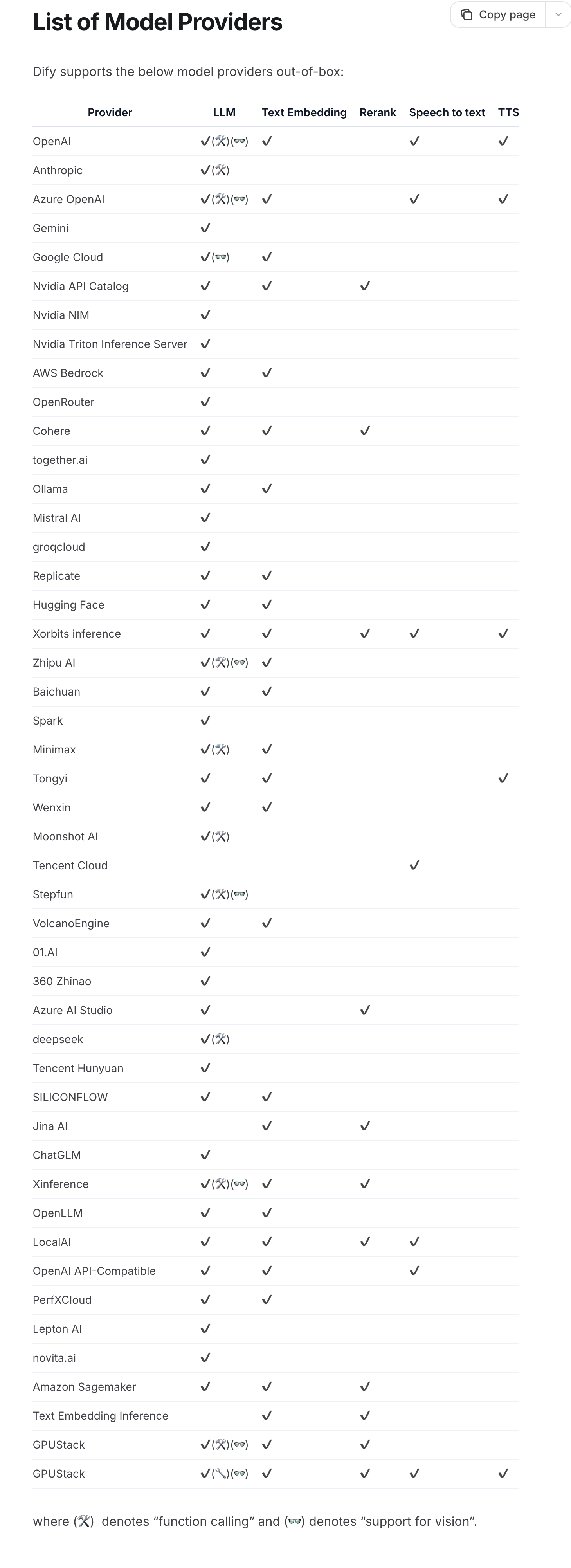
全面的模型支持: 与数百种专有/开源 LLMs 以及数十种推理提供商和自托管解决方案无缝集成,涵盖Tongyi系列、DeepSeek 、GPT等模型。完整的支持模型提供商列表可在此处找到。
-
Prompt IDE: 用于制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)的直观界面。
-
RAG Pipeline: 广泛的 RAG 功能,涵盖从文档摄入到检索的所有内容,支持从 PDF、PPT 和其他常见文档格式中提取文本的开箱即用的支持。
-
Agent 智能体: 可以基于 LLM 函数调用或 ReAct 定义 Agent,并为 Agent 添加预构建或自定义工具。Dify 为 AI Agent 提供了 50 多种内置工具,如谷歌搜索、DALL·E、Stable Diffusion 和 WolframAlpha 等。
-
LLMOps: 随时间监视和分析应用程序日志和性能。您可以根据生产数据和标注持续改进提示、数据集和模型。
-
后端即服务: 所有 Dify 的功能都带有相应的 API,因此您可以轻松地将 Dify 集成到自己的业务逻辑中。
二、安装社区版
2.1 系统要求
在安装 Dify 之前,确保机器满足以下最低系统要求:
CPU >= 2 Core
RAM >= 4 GiB
2.2 快速启动
首先把代码 clone 到本地,仓库地址,下载版本最好不要选择 master,不稳定,在 tags 里选择一个已经发布的版本。
启动 Dify 服务器的最简单方法是运行 docker-compose.yml 文件。在运行安装命令之前,确保机器上安装了 Docker 和 Docker Compose:
cd docker
cp .env.example .env
export EXPOSE_NGINX_PORT=8080
docker compose up -d
运行后,可以在浏览器上访问 http://localhost:8080/install 进入 Dify 控制台并开始初始化安装操作。
2.3 自定义配置
如果需要自定义配置,参考 .env 文件中的注释,并更新 .env 文件中对应的值。此外,可能需要根据具体部署环境和需求对 docker-compose.yaml 文件本身进行调整,例如更改镜像版本、端口映射或卷挂载。完成任何更改后,需要重新运行 docker-compose up -d。可以在此处找到可用环境变量的完整列表。
三、案例-金融问答
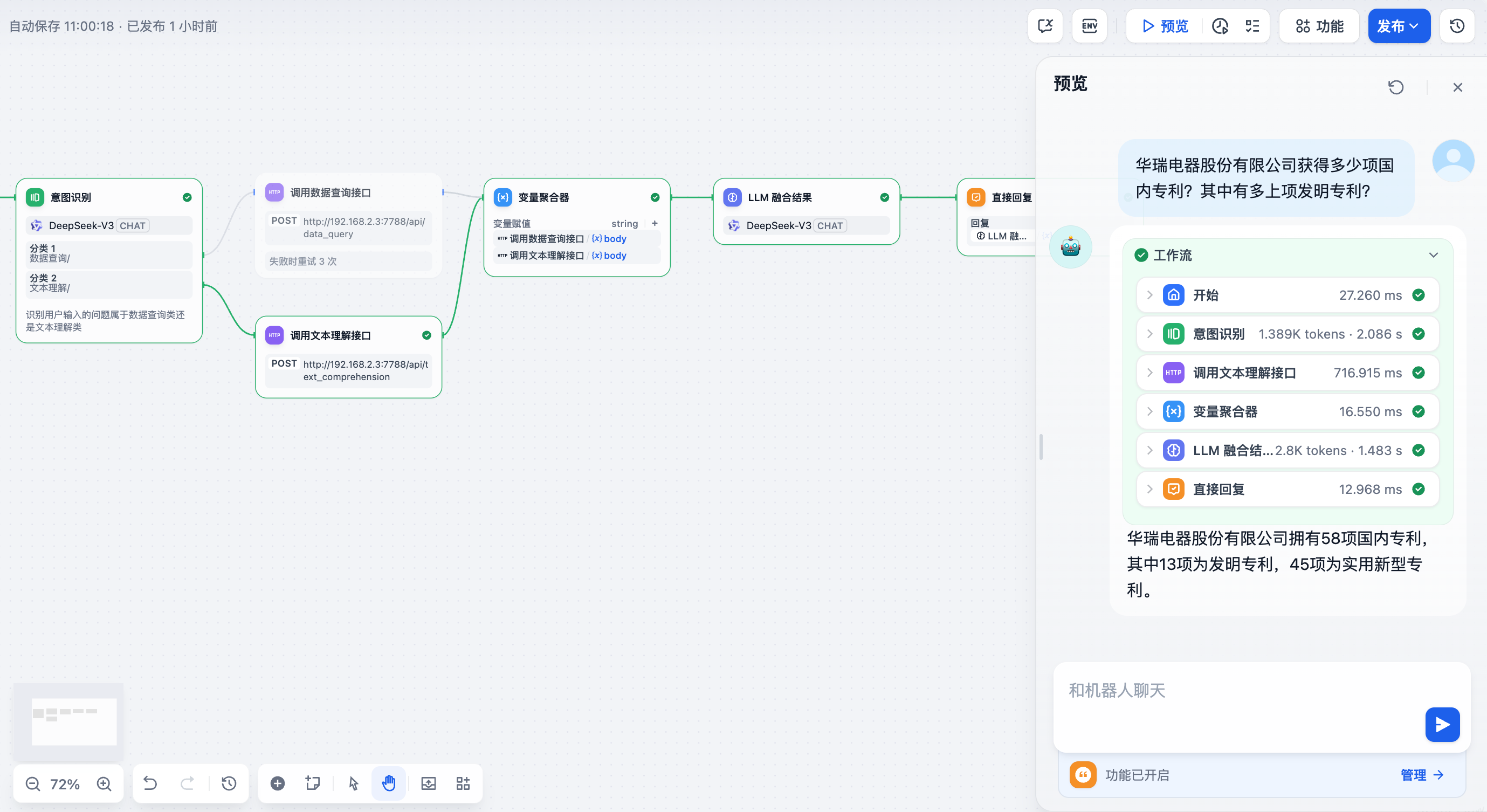
结合一个实际的案例,使用 Dify构建一个基于大语言模型LLM构建一个金融问答系统,问答内容涉及基金/股票/债券/招股书等不同数据来源,融合了数据查询与文本理解两大任务,体现了Agent核心思想:根据不确定输入,判断用户意图,并调用相应服务或功能生成答案。
-
数据查询
任务目标:根据用户的问题,生成相应的SQL查询语句,精准查询问题结果。处理多表之间的复杂关联,如理解基金股票持仓明细与A股日行情表的连接,并确保查询的高准确性。
例如用户输入问题:嘉实基金管理有限公司2019年成立了多少基金?。
应用需要先把此问题,识别为数据查询类,再把自然语言转换成为 SQL 查询语句,然后调用数据查询工具,从关系型数据库中查询结果,在把数据库的结果,交给大模型融合之后,生成最终结果返回给用户。 -
文本理解题
任务目标:对长文本进行细致检索与解读,高效提取关键信息。处理长文本的复杂结构,确保信息完整性。对超长文本,选手需合理分块,并从文档分块中准确提炼答案。
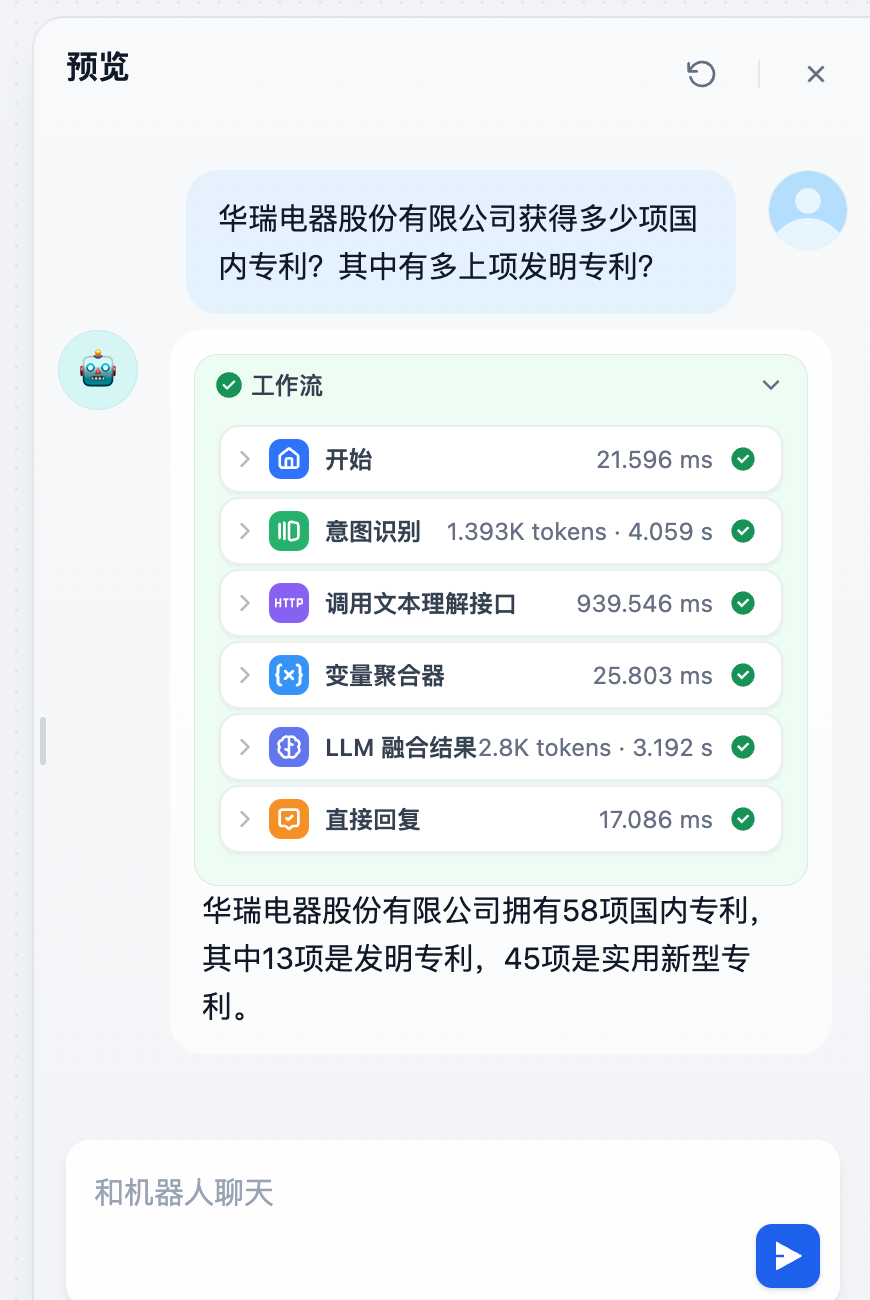
例如用户输入问题:华瑞电器股份有限公司获得多少项国内专利?其中有多上项发明专利?。
应用需要先把此问题,识别为文本理解类,再把自然语言作为参数,调用文本查询工具,从向量数据库中进行检索获得结果,或者结合全文检索,在把文本结果做精排之后,交给大模型融合之后,生成最终结果返回给用户。
3.1 工作流简介
工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
Dify 工作流分为两种类型:
-
Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。 -
Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
下图就是一个Chatflow
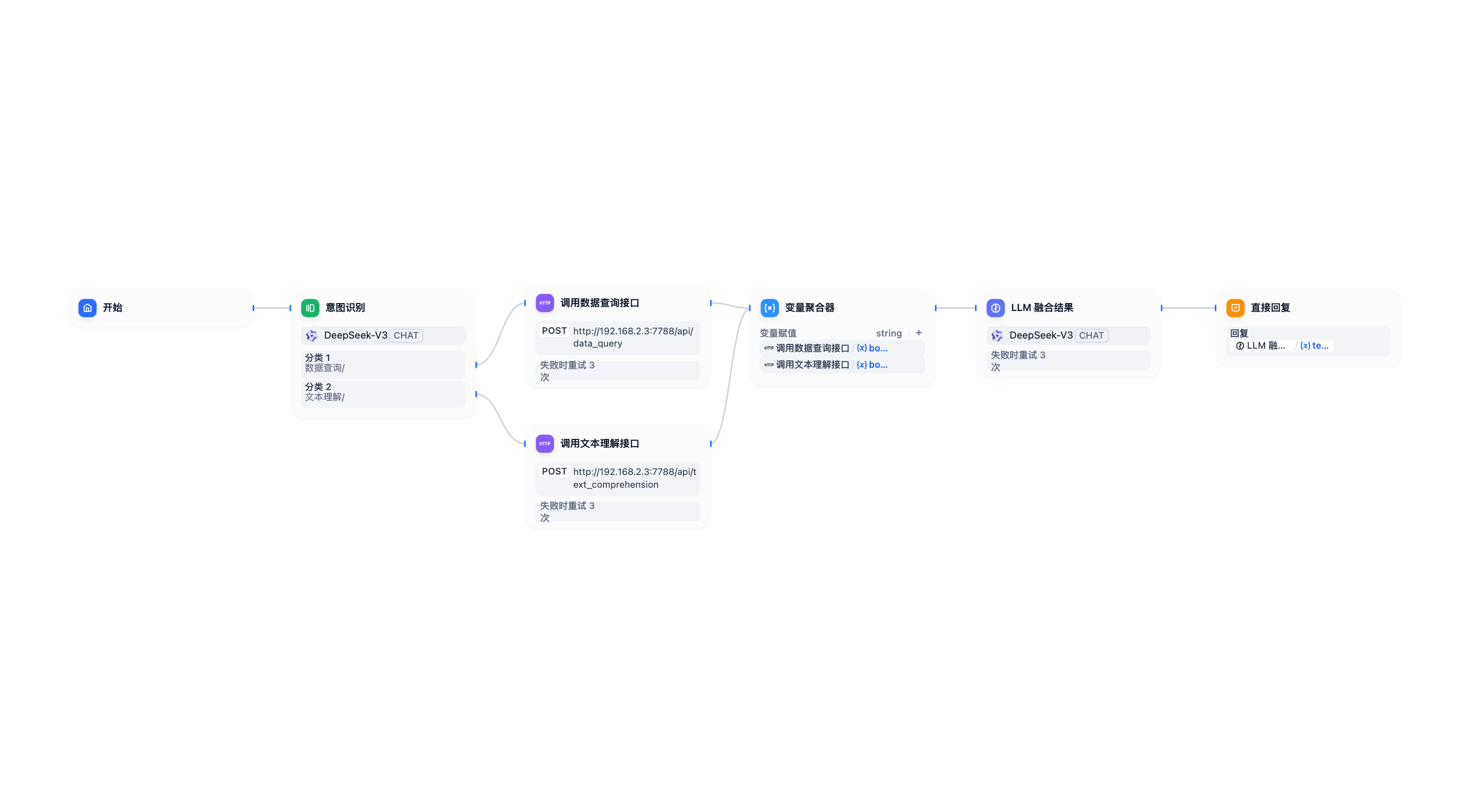
3.2 创建Chatflow
进入到编排界面
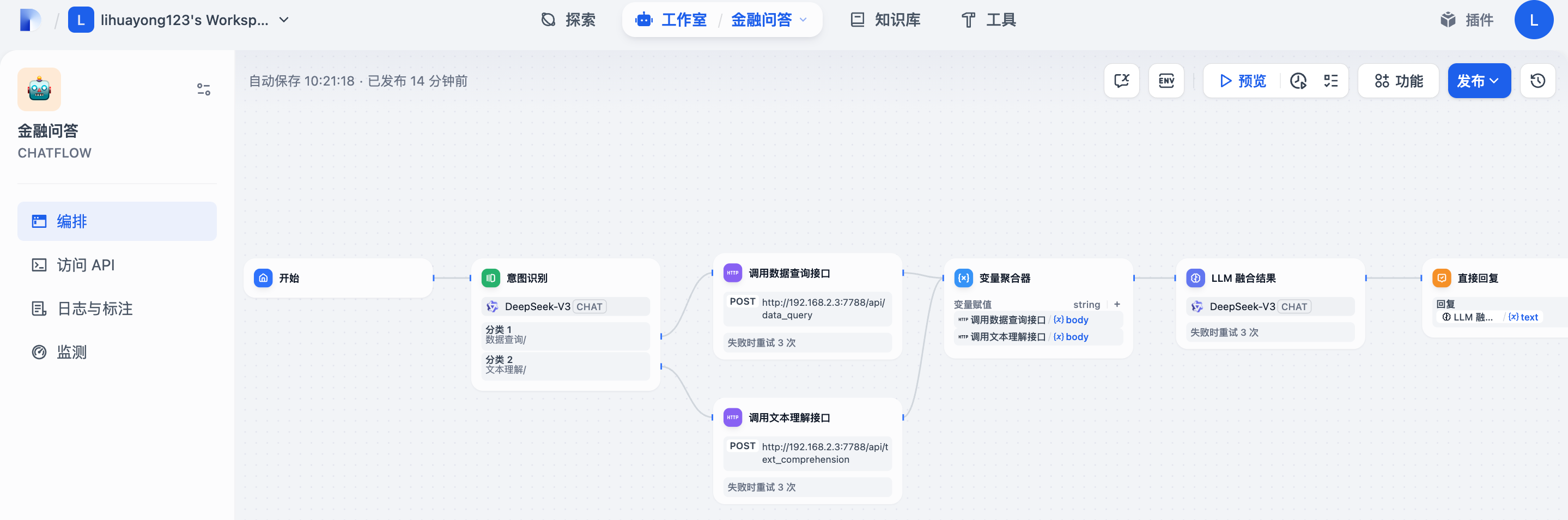
3.3 创建问题分类器
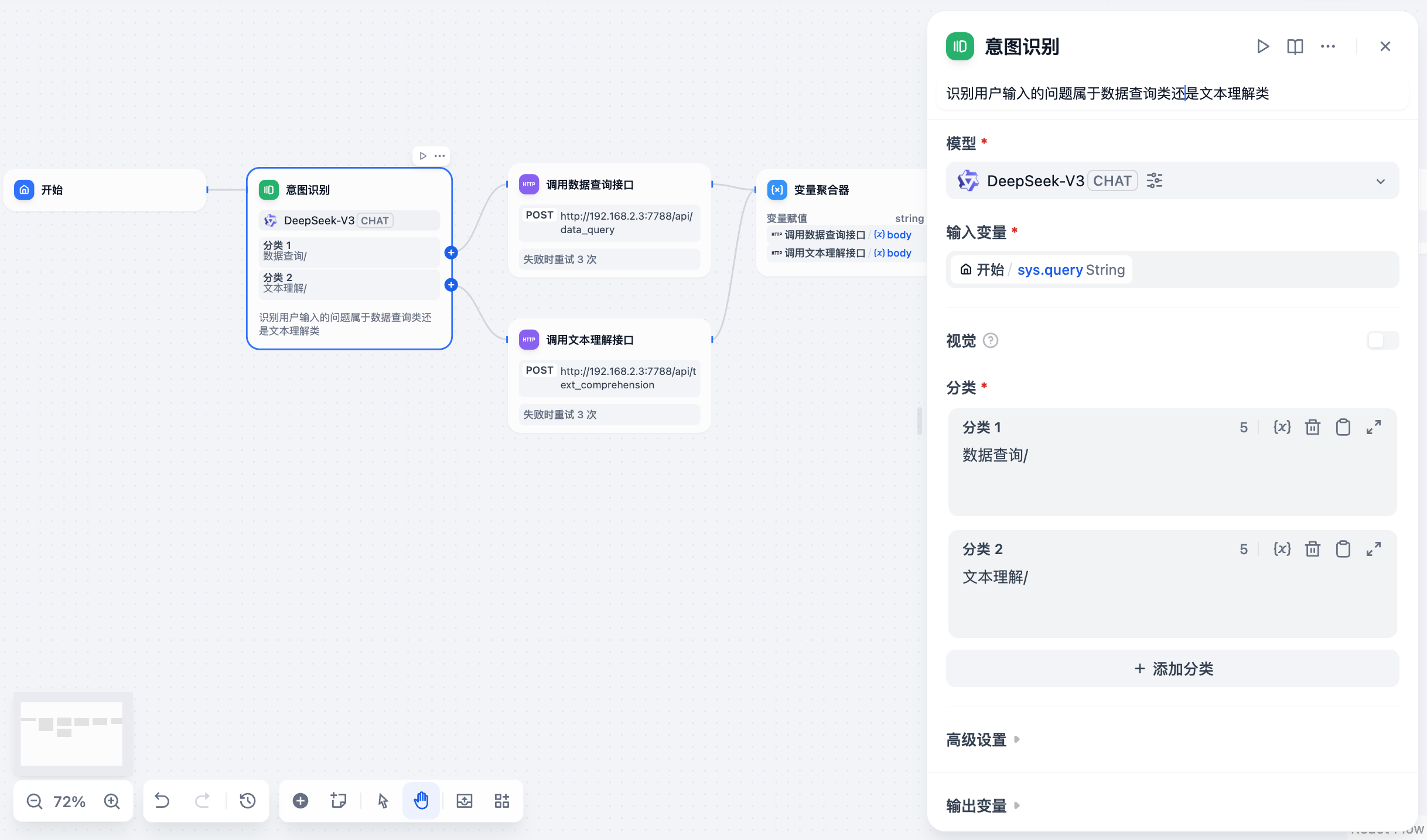
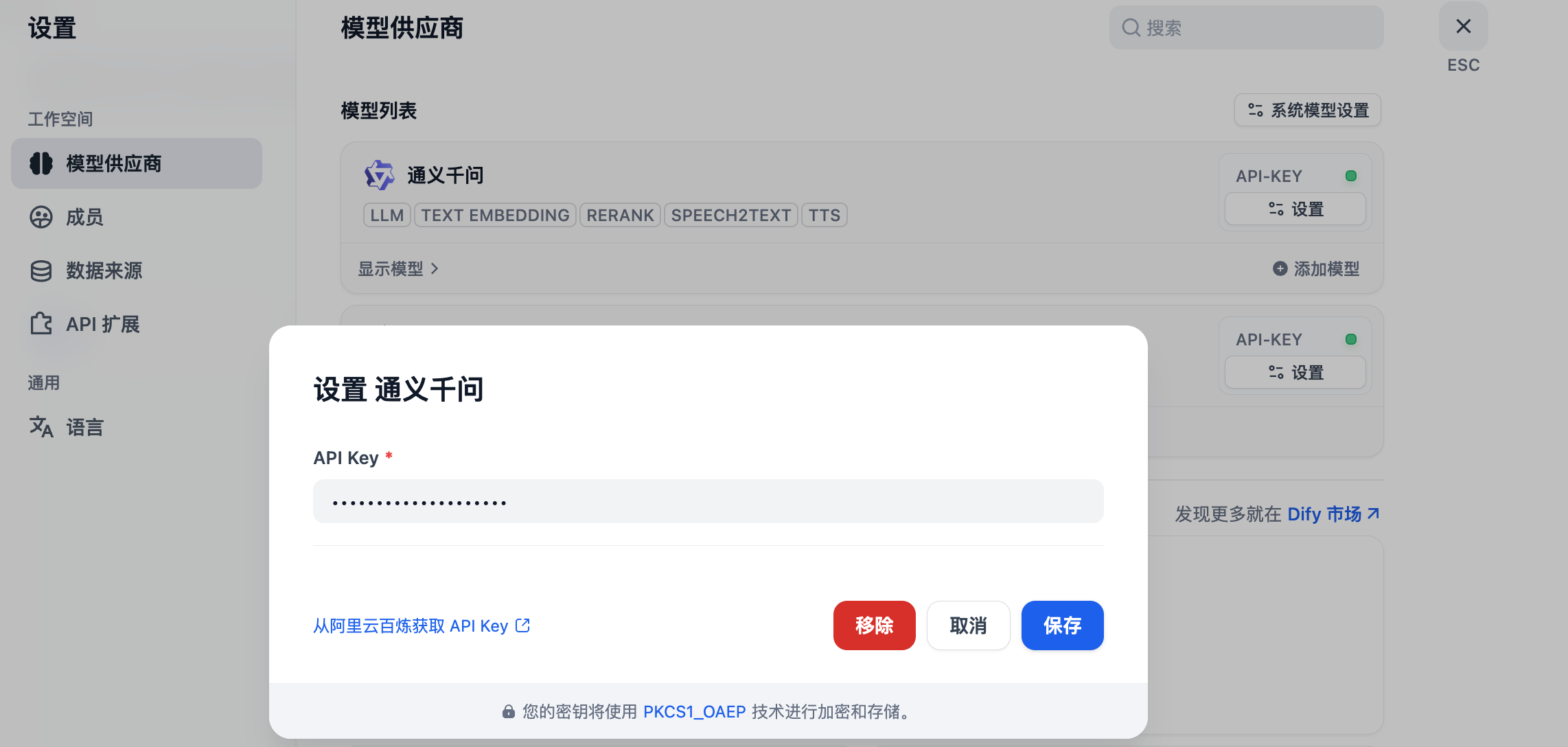
首先需要选择模型,这个模型需要提前安装和配置,从模型供应商中选择,然后在配置 api-key
比如我选择的是通义千问系列模型,需要提供通义千问的 api-key,这个api-key在阿里百炼平台去生成。
在高级设置里,需要添加提示词,以便模型能够更好的理解用户的问题,并进行问题分类
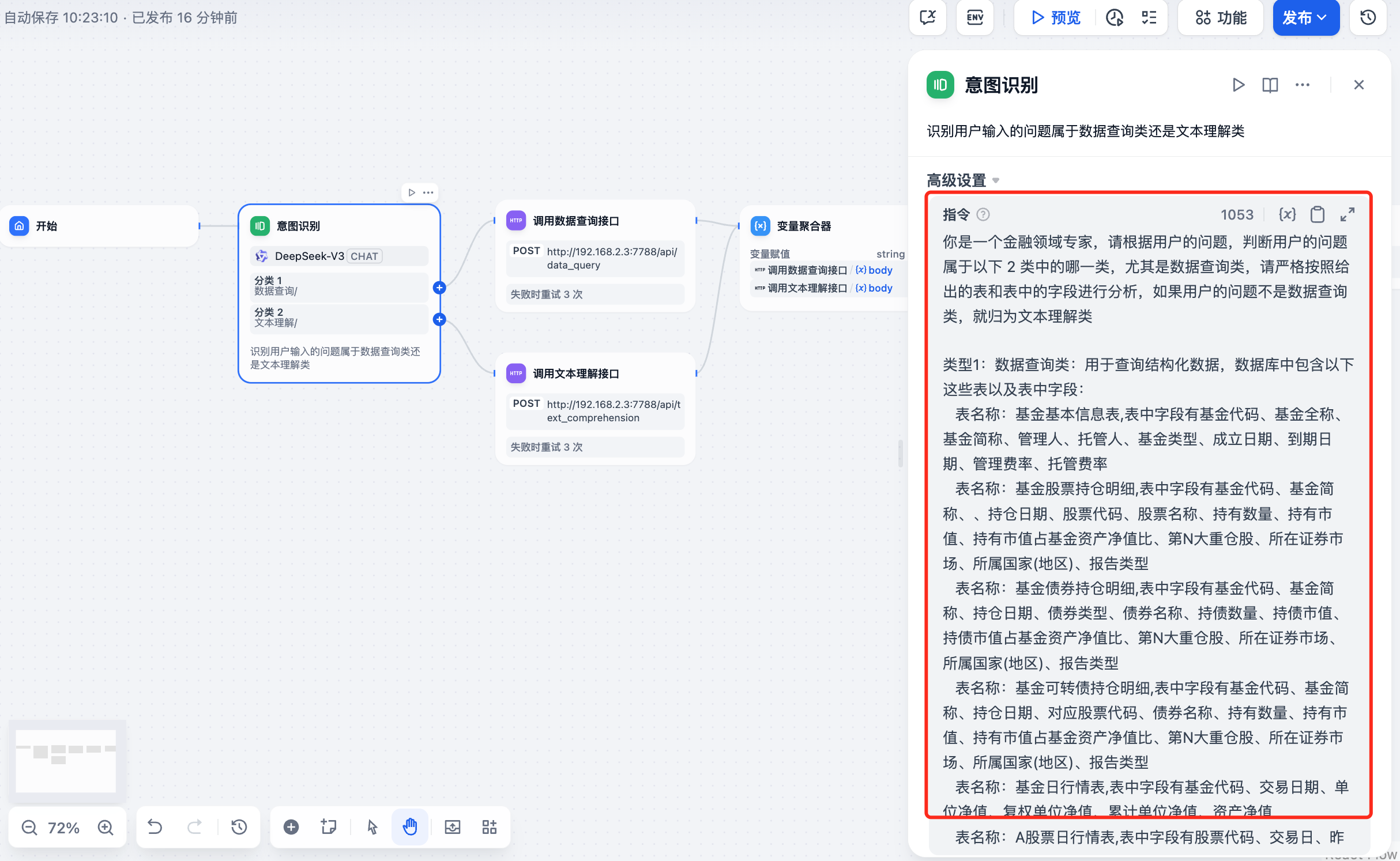
比如我写的
你是一个金融领域专家,请根据用户的问题,判断用户的问题属于以下 2 类中的哪一类,尤其是数据查询类,请严格按照给出的表和表中的字段进行分析,如果用户的问题不是数据查询类,就归为文本理解类类型1:数据查询类:用于查询结构化数据,数据库中包含以下这些表以及表中字段:表名称:基金基本信息表,表中字段有基金代码、基金全称、基金简称、管理人、托管人、基金类型、成立日期、到期日期、管理费率、托管费率......表名称:基金规模变动表,表中字段有基金代码、基金简称、公告日期、截止日期、报告期期初基金总份额、报告期基金总申购份额、报告期基金总赎回份额、报告期期末基金总份额、定期报告所属年度、报告类型......类型2:文本理解类:用于招股说明书文本理解,包含:风险因素披露、行业竞争分析、财务数据说明、公司战略规划等等用户问题:
{{#sys.query#}}
3.4 创建 Http 请求
问题分类器创建完成之后,需要根据不同的意图,调用不同的接口去获取用户的问题对应的答案。我在后台单独写了 2 个接口,
- 一个接口是提供数据查询服务,主要把用户的问题,转换成SQL查询语句,然后调用 Mysql 数据库,执行数据检索,最后把结果返回。
- 一个接口是提供文本理解服务,主要是根据用户的问题,到向量数据库中去检索答案,最后把结果返回。
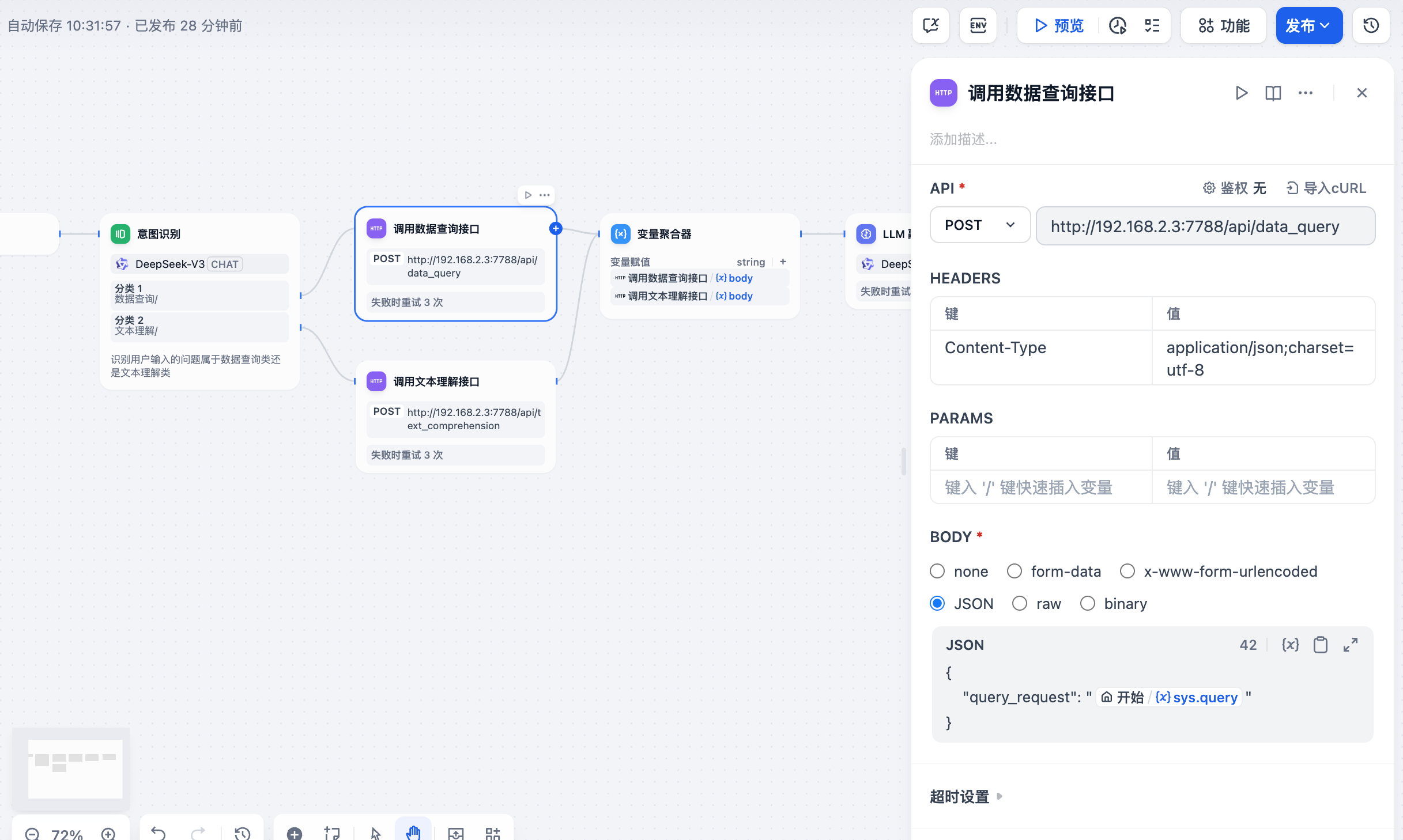
需要注意一下,本地部署的 Dify,是在 docker 容器中,如果要调用 本地的 http 接口,不要直接写localhost 或者 127.0.0.1 地址,否则会调用失败
3.5 创建变量聚合器
变量聚合器是将多路分支的变量聚合为一个变量,以实现下游节点统一配置。
变量聚合节点是工作流程中的一个关键节点,它负责整合不同分支的输出结果,确保无论哪个分支被执行,其结果都能通过一个统一的变量来引用和访问。这在多分支的情况下非常有用,可将不同分支下相同作用的变量映射为一个输出变量,避免下游节点重复定义。
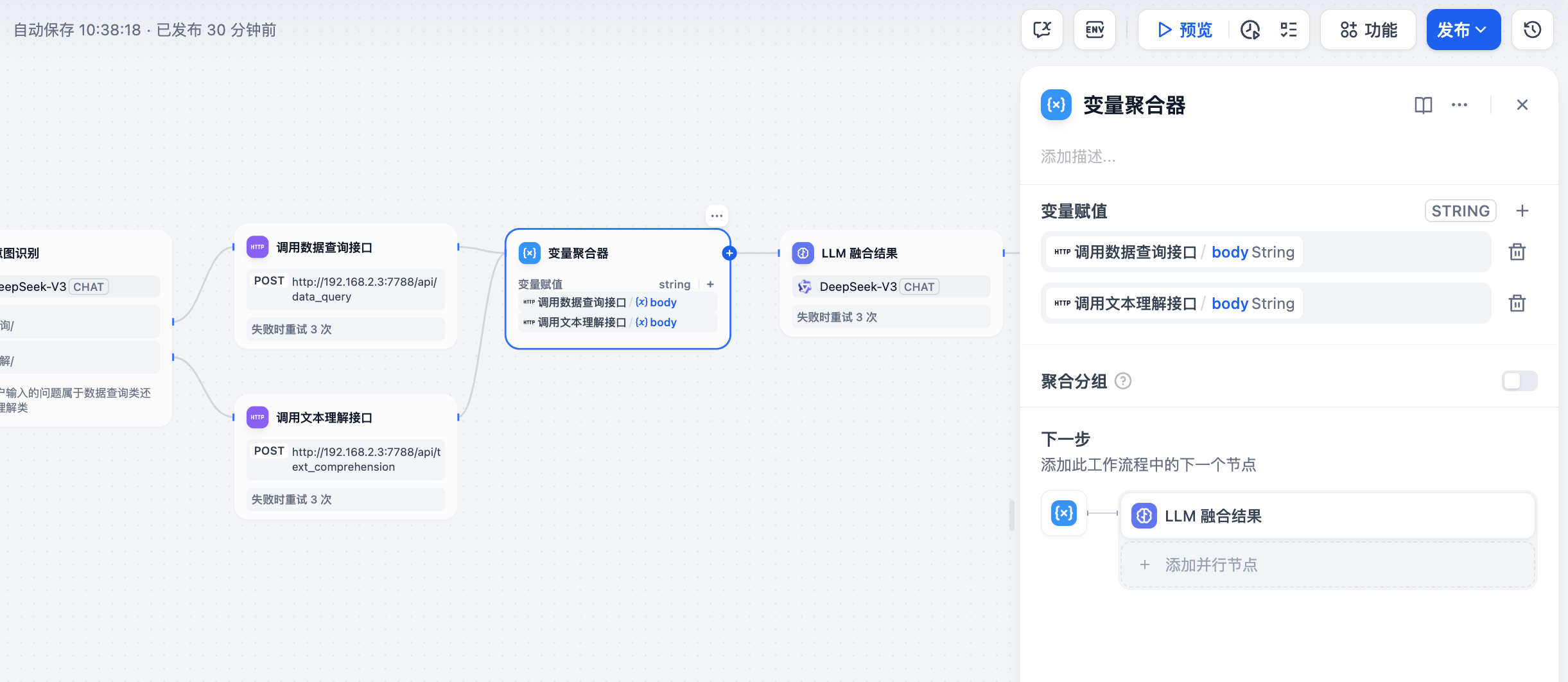
3.6 创建LLM
创建一个 LLM节点,调用大语言模型的能力,处理用户在 “开始” 节点中输入的信息(自然语言、上传的文件或图片),给出有效的回应信息。
应用场景
LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
- 意图识别,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
- 文本生成,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
- 内容分类,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
- 文本转换,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
- 代码生成,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
- RAG,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
- 图片理解,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
此案例中,经过前面两个步骤之后,针对用户的问题,找到一个结果,但是这个结果是 数据库返回的数字结果,
比如用户问题:嘉实基金管理有限公司2019年成立了多少基金?
http 接口返回结果是:
[(55,)]
这样的结构是数据库返回的数字结果,也不止这种结构,还有其他的结构,总是返回结果是不固定的。
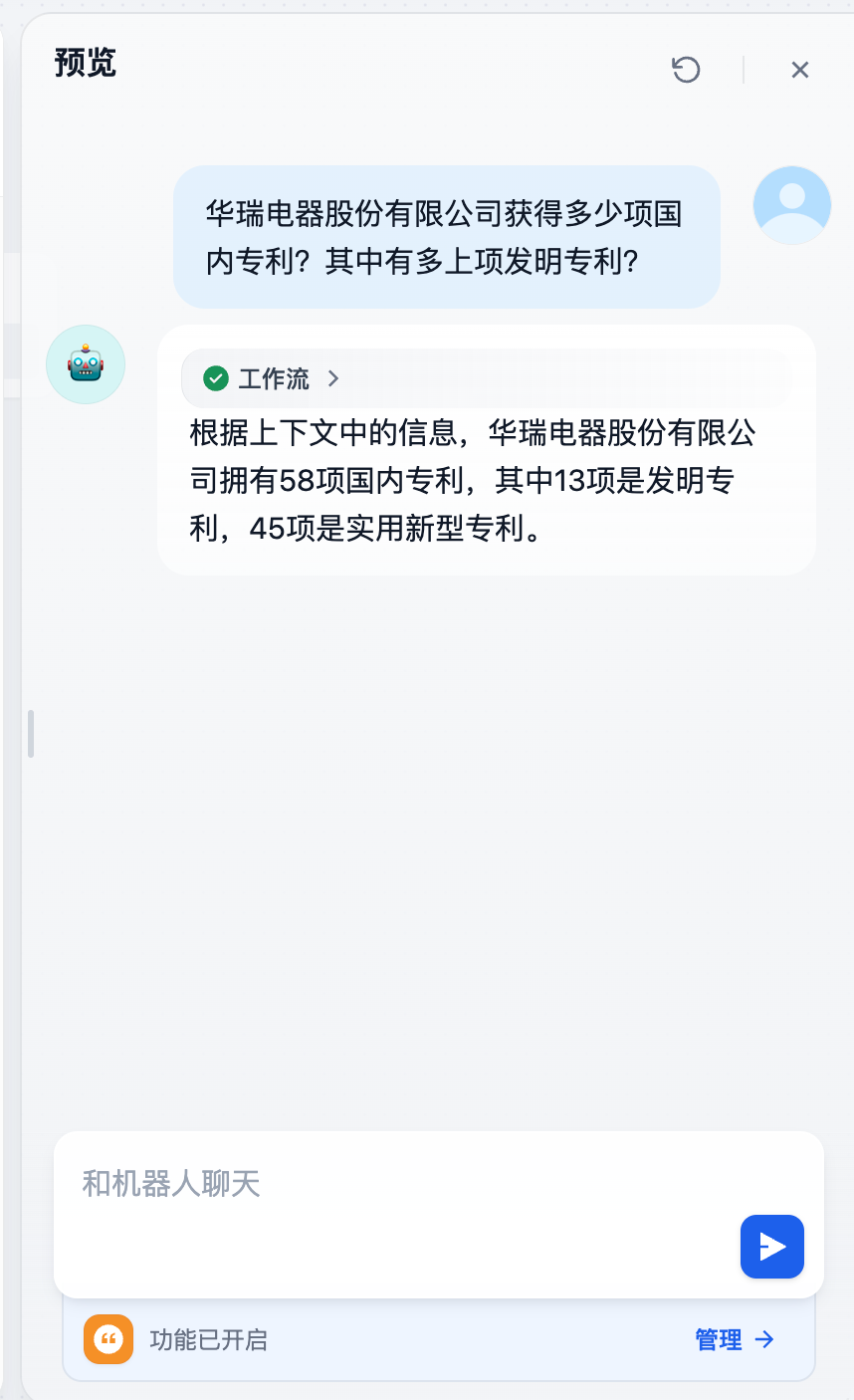
又或者是文本类型的,比如用户问题:华瑞电器股份有限公司获得多少项国内专利?其中有多上项发明专利?
http 接口返回结果是:
招股意向书 \n1-1-27 \n公司结合电机市场的未来发展趋势,以全塑型工艺、一次成型工艺为突破\n口,逐渐形成了生产自动化、产品多样化和工艺精细化的生产研发体系,并具\n备了多种专业设备和各类产品的自主开发能力。
截至本招股意向书签署日,公\n司拥有国内专利58 项,其中13 项发明专利,45 项实用新型专利。公司通过了\nISO14001 环境管理体系认证、OHSAS18001 职业健康安全管理体系认证和\nISO/TS16949 汽车生产供应链质量管理体系认证。
宁波胜克研发中心被认定为\n“浙江省工程技术研究中心”,公司的全塑型换向器及自动化生产工艺装备被\n宁波市科学技术局认定为“科学技术成果”。 \n公司目前已经形成了多元化的产品和客户体系。
这种问题的答案,是隐藏在本文结果里的
基于以上情况,需要创建一个 LLM 节点,让大语言模型,从文本结果中提炼出答案。
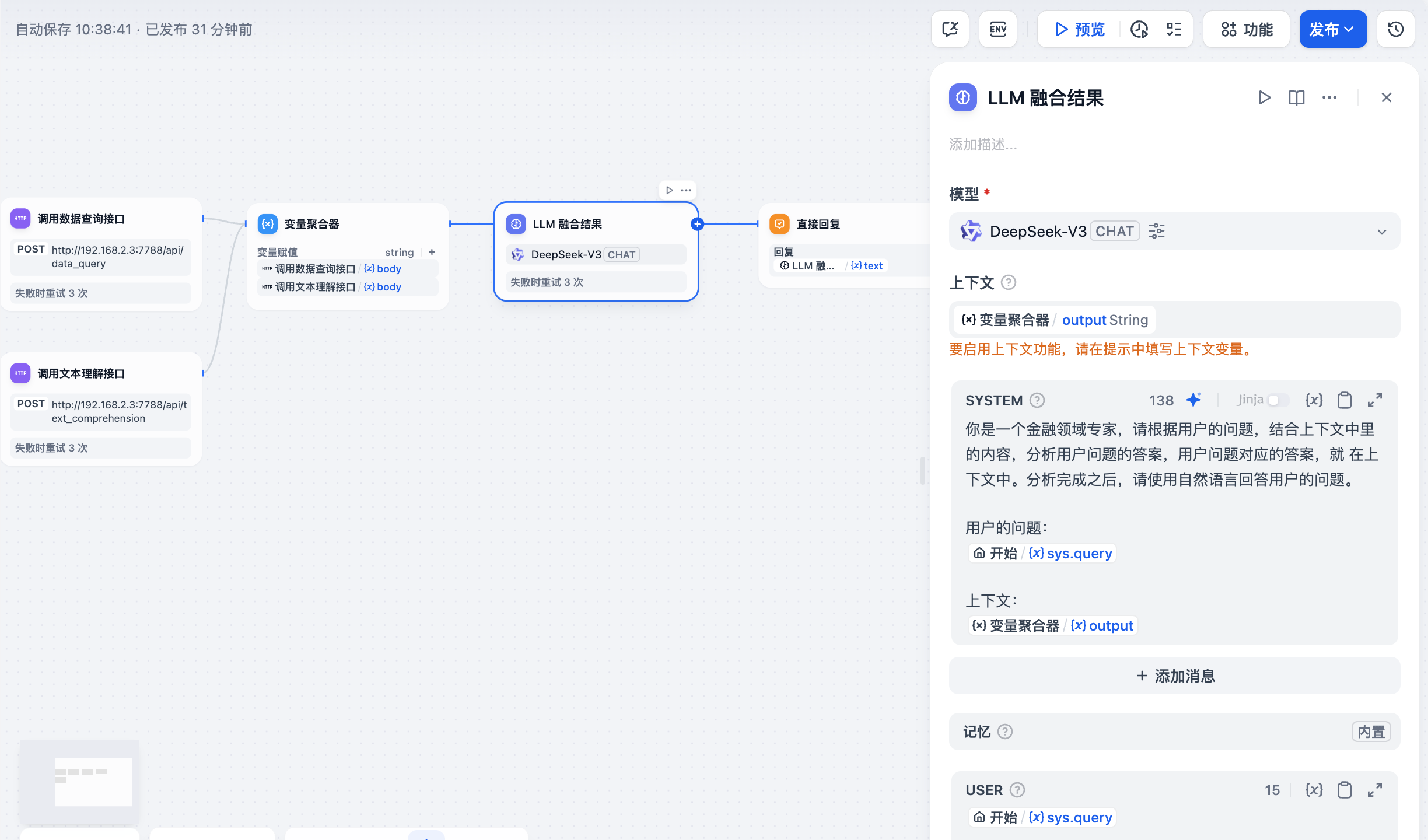
LLM 节点,这个场景中,我只配置了 3 个重要选项,一个是选择模型,一个是上下文,一个是填写提示词,上下文就是调用 Http接口返回的原始结果,提示词主要是告诉大模型,要完成什么任务。
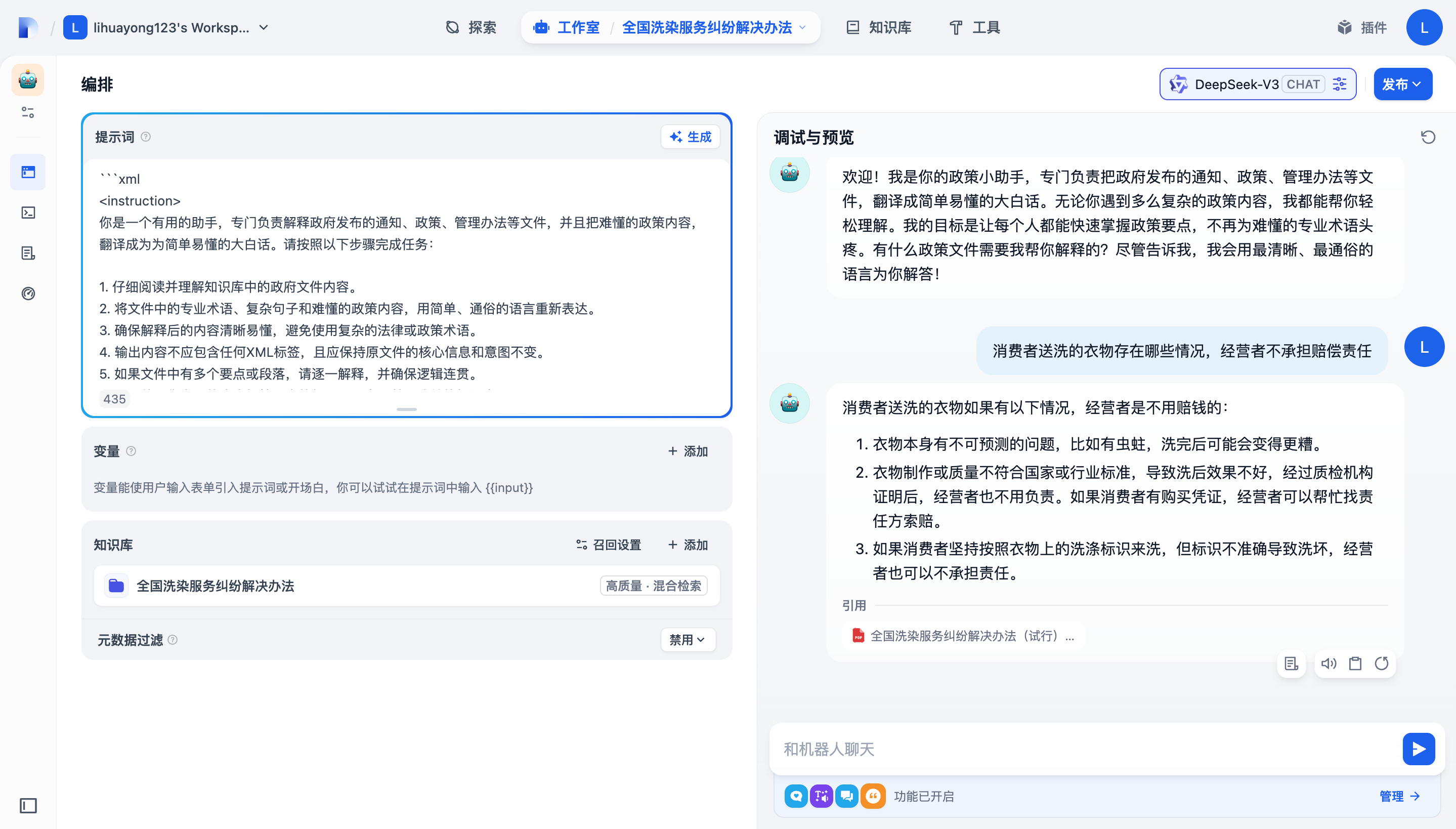
你是一个金融领域专家,请根据用户的问题,结合上下文中里的内容,分析用户问题的答案,
用户问题对应的答案,就在上下文中。分析完成之后,请使用自然语言回答用户的问题。用户的问题:
{{#sys.query#}}上下文:
{{#****.output#}}
下图就是大模型处理效果
3.7 直接回复
最后一个节点是直接回复,目的是直接把大模型融合之后的结果,显示在界面上,提供给用户查看
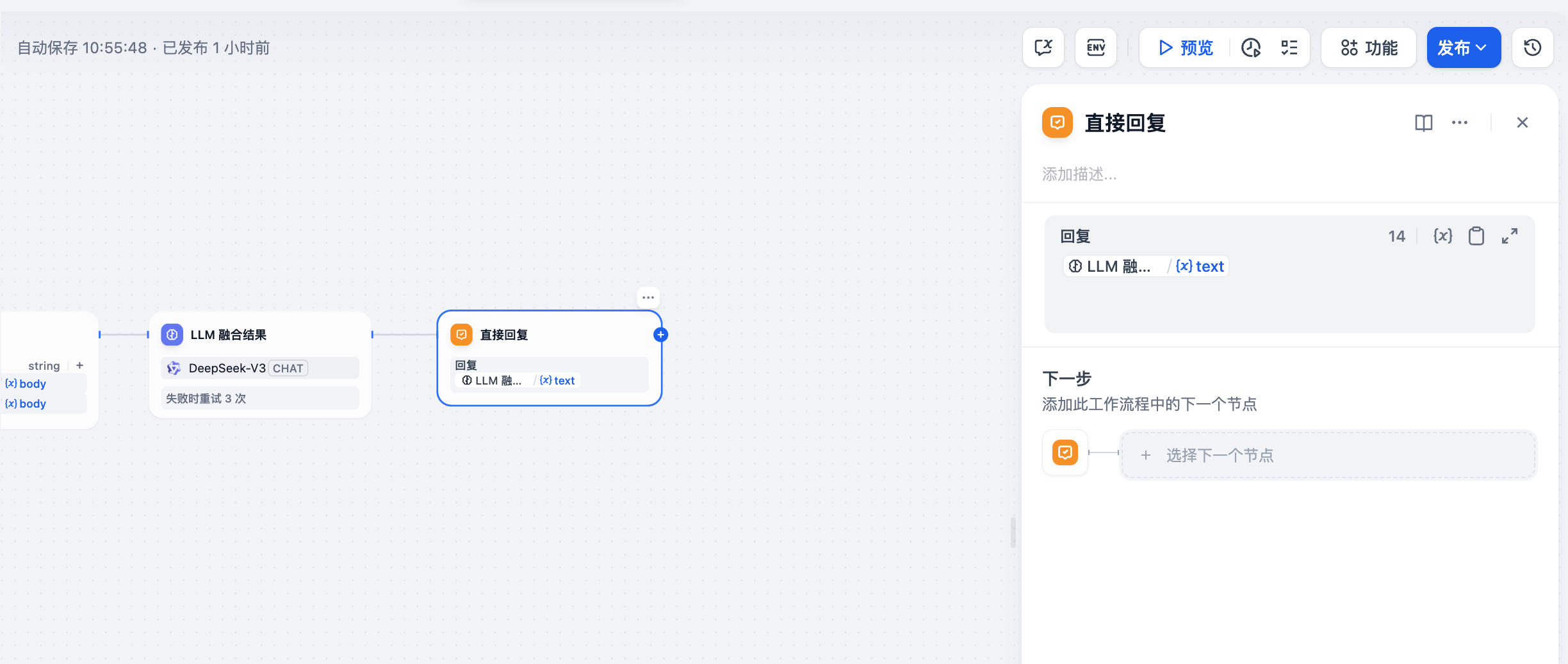
预览功能还能看到,每一步测试的结果,方便调试