一、大模型原理:第一步分词Tokenization
分词往往是LLM第一步,本文将会从原理介绍下分词。以及现在最普遍用的BPE的原理与优缺点
什么是分词(Tokenization)?
分词Tokenization这个英文单词,可以看到它是个动词。由此得出Tokenization即是将文本分解成称为"token"(标记)的较小单元的过程。
这些标记作为语言模型的基本处理单位。这些标记随后被转换为计算机可以处理的数值ID。
我们选择如何分解文本会显著影响模型理解语言的能力和计算效率。
因此下文将会展开各个分词方法的优缺点。
| 分词方法 | 说明 | 优点 | 缺点 | 示例 |
|---|---|---|---|---|
| 基于词的分词 (Word-based) | 将文本分割成完整的词,按空格和标点符号分隔 | • 保留完整语义 • 直观易懂 | • 词汇表庞大(17万+) • 无法处理未见词 • 词形变化困难 | “Working on NLP” → [“Working”, “on”, “NLP”] |
| 基于字符的分词 (Character-based) | 将文本分解为单个字符 | • 词汇表极小 • 无未见词问题 | • 丢失语义信息 • 序列过长 • 计算成本高 | “Working” → [“W”, “o”, “r”, “k”, “i”, “n”, “g”] |
| 子词分词(BPE) (Byte Pair Encoding) | 基于频率合并字符对,形成子词单元 | • 平衡词表大小 • 处理未见词 • 保留语义 • 主流选择 | • 中文等语言效率低 | “tokenization” → [“token”, “ization”] “unusualification” → [“un”, “usual”, “ification”] |
1. 基于词的分词(Word-based)
最直观的方法是将文本分割成完整的词。对于英文,这可以简单到按空格和标点符号进行分割。
优点:
- 保留完整词作为有意义的语义单位
- 比基于字符的方法更能表达语义
缺点:
- 导致词汇表极其庞大(牛津词典有超过170,000个词)
- 难以处理词汇表外(OOV)的词
- 无法处理词的细微变化(例如"cat"与"cats")
2. 基于字符的分词(Character-based)
在另一端,基于字符的分词将文本分解为单个字符。
优点:
- 词汇表极小(几千个字符就能覆盖大多数语言)
- 只要字符在词汇表中就没有OOV问题
缺点:
- 丢失词级语义信息
- 创建非常长的标记序列
- 增加表示文本的计算成本
3. 子词分词
子词方法在词和字符方法之间取得平衡。
它是基于统计相邻词当作词表的处理算法。
分词的结果类似于jieba分词,但它是基于传入的数据本身训练得到的。
字节对编码(BPE)
BPE最初是一种压缩算法,现已成为NLP的基础。它被GPT等模型使用。
💡需要注意的是,token本身是一个较为模糊的概念,是由设计者人为定义的。同一个符号序列是否成为一个token,取决于其在语料库中的出现频率:
这种分词策略完全由语言模型的设计者决定,每个语言模型采用的token规则也各不相同。例如,GPT-3.5和GPT-4使用的token系统就有所区别。
BPE工作原理:
- 初始化:从单个字符的词汇表开始
- 训练:
- 统计语料库中相邻字符对的频率
- 将最频繁的对合并为新的标记
- 将这个新标记添加到词汇表
- 重复直到达到所需的词汇表大小
完整的BPE训练过程演示
1. 准备数据
假设我们要训练一个BPE分词器,语料库如下:
语料:{"usual": 5,"unusual": 3,"usualness": 2,"super": 4,"superb": 3,"supermarket": 2
}
初始状态
- 字符级词汇表:[‘u’, ‘s’, ‘l’, ‘a’, ‘n’, ‘e’, ‘p’, ‘r’, ‘b’, ‘m’, ‘k’, ‘t’, ‘’]
- 初始分词状态:
- “usual” → [‘u’, ‘s’, ‘u’, ‘a’, ‘l’, ‘’]
- “unusual” → [‘u’, ‘n’, ‘u’, ‘s’, ‘u’, ‘a’, ‘l’, ‘’]
- “usualness” → [‘u’, ‘s’, ‘u’, ‘a’, ‘l’, ‘n’, ‘e’, ‘s’, ‘s’, ‘’]
- …
第1次合并:寻找最频繁字符对
统计相邻字符对的出现频率:
- (‘u’, ‘s’): 10次(出现在usual、unusual、usualness中)
- (‘s’, ‘u’): 5次
- (‘u’, ‘a’): 5次
- (‘p’, ‘e’): 9次(出现在super、superb、supermarket中)
选择:(‘u’, ‘s’) → 合并为 ‘us’
更新后:
- 词汇表:[‘u’, ‘s’, ‘l’, ‘a’, ‘n’, ‘e’, ‘p’, ‘r’, ‘b’, ‘m’, ‘k’, ‘t’, ‘’, ‘us’]
- “usual” → [‘us’, ‘u’, ‘a’, ‘l’, ‘’]
- “unusual” → [‘u’, ‘n’, ‘us’, ‘u’, ‘a’, ‘l’, ‘’]
第2次合并
寻找最频繁对:
- (‘us’, ‘u’): 10次
- (‘s’, ‘u’): 5次(现在减少了)
- (‘p’, ‘e’): 9次
选择:(‘us’, ‘u’) → 合并为 ‘usu’
第3-5次合并
继续合并过程:
- (‘usu’, ‘a’): 10次 → 合并为 ‘usua’
- (‘usua’, ‘l’): 10次 → 合并为 ‘usual’
- (‘p’, ‘e’): 9次 → 合并为 ‘pe’
最终BPE词典(部分)
标准词汇:
- 'usual': 完整的token
- 'us': 高频前缀
- 'un': 否定前缀
- 'super': 完整的token
- 'er': 高频后缀
- 'ness': 高频后缀
有了这个词表,当用户输入词时我们就可以通过词表分割及标记了。
未见词处理演示
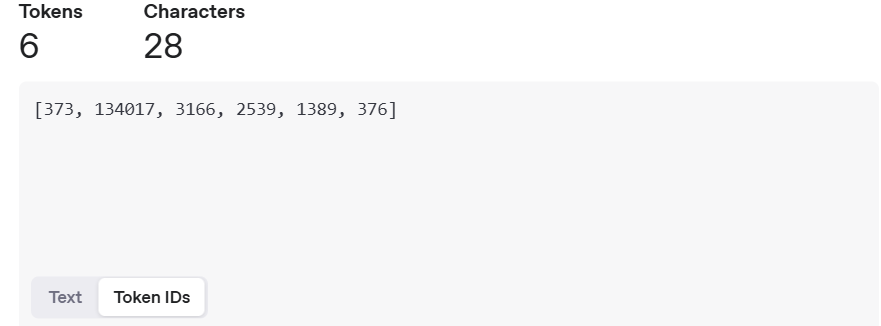
示例1:处理"unusualification"
由于这个词未在训练数据中出现,BPE会分解它:
- 先找出能识别的子词
- 分解结果:[‘un’, ‘usual’, ‘ification’]
- 或者:[‘un’, ‘usual’, ‘ify’, ‘cation’]
示例2:处理"supernewest"
- 分解结果:[‘super’, ‘new’, ‘est’]
- 即使"supernewest"从未出现过,我们仍然可以理解其含义
- “super” - 前缀,表示"超级"
- “new” - 新的
- “est” - 最高级后缀
如图模拟openai的分词结果。
可见通过BPE算法,一个未知的词能被分解为多个token,而后续我们对该词的embedding我们也可以通过拆分这些词能猜到这个未见词的含义
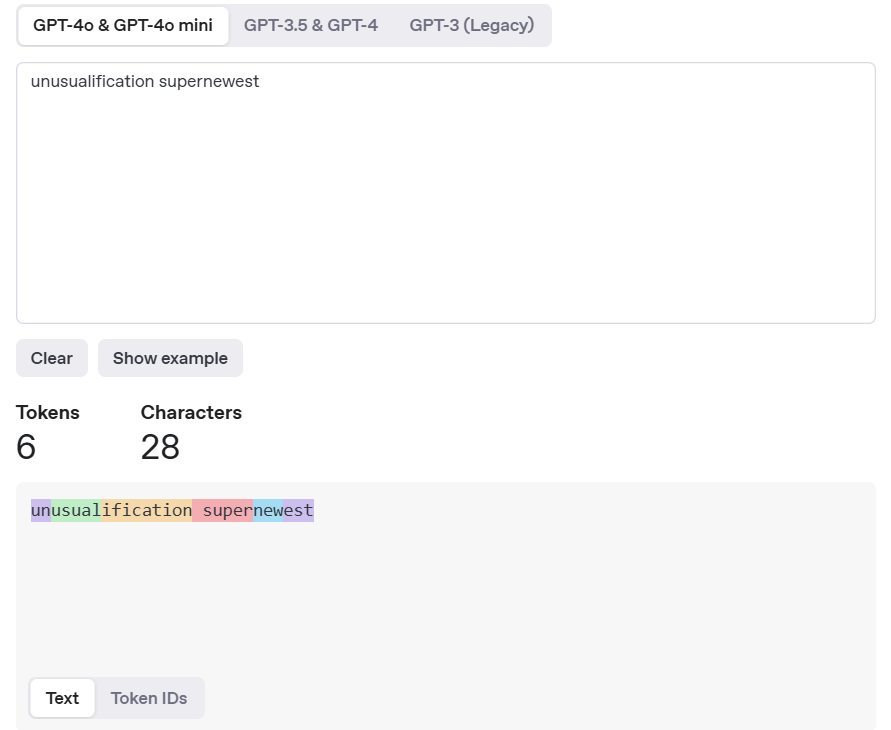
如下图将这些文字/单词用数字表示就实现了分词Tokenization。