51c大模型~合集123
我自己的原文哦~ https://blog.51cto.com/whaosoft/13877227
#Qwen3实测
从Llama4陨落之后,国内开源模型是世界第一,谁赞成,谁反对!
反对无效!
应该也没人反对吧。
Qwen3这波开的时机,真是恰到好处,五一都别休假了,加班跑模型吧。
我在上一篇已经介绍了Qwen3的一些基本情况,Qwen3开源!悉数几大核心变动!。
模型尺寸、榜单指标、首个混合推理模型,这篇就不重复介绍了,去看我上一篇内容吧。
这篇主要是针对Qwen3实测,看看真实测试效果到底如何!
测试可以在两个地方都可以
https://huggingface.co/spaces/Qwen/Qwen3-Demo
或者
https://chat.qwen.ai/
主要测试think和no think两种情况。
正式测试开始。
常规测试
将“I love Qwen3-235B-A22B”这句话的所有内容反过来写

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think

Qwen3-32B think

Qwen3-32B no-think
说明:结果正确。
依旧弱智吧
生蚝煮熟了叫什么?

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think

Qwen3-32B think

Qwen3-32B no-think
说明:结果正确,没有熟蚝就行。
用水来兑水,得到的是浓水还是稀水

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think

Qwen3-32B think

Qwen3-32B no-think
说明:结果正确,水还是水。
依旧小红,依旧老鹰
小红有2个兄弟,3个姐妹,那么小红的兄弟有几个姐妹

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
说明:4个,正确,小红在我这是女生。
未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
说明:这题确实难,老鹰反正不会飞!市面上的大模型都答不对。
数学
2024年高考全国甲卷数学(理)试题


Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
说明:对了。结果是、
R1满血测试题:在平面四边形ABCD中,AB = AC = CD = 1,\angle ADC = 30^{\circ},\angle DAB = 120^{\circ}。将\triangle ACD沿AC翻折至\triangle ACP,其中P为动点。 求二面角A - CP - B的余弦值的最小值。

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
说明:think对了,no think 没对,答案是 。
一个长五点五米的竹竿,能否穿过一扇高四米,宽三米的门?请考虑立体几何

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
大数计算:178939247893 * 299281748617等于多少?

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
说明:没对,答案是53553251005627872913981。
伦理、数学、生物终极测试
有一天,一个女孩参加数学考试只得了 38 分。她心里对父亲的惩罚充满恐惧,于是偷偷把分数改成了 88 分。她的父亲看到试卷后,怒发冲冠,狠狠地给了她一巴掌,怒吼道:“你这 8 怎么一半是绿的一半是红的,你以为我是傻子吗?”女孩被打后,委屈地哭了起来,什么也没说。过了一会儿,父亲突然崩溃了。请问这位父亲为什么过一会崩溃了?

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
说明:think模式没对,no think模型竟然答对了两点,数学和色盲。
代码
卡片:生成一个打工人时钟的html页面

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
创建一个红白机风格的"贪吃蛇"游戏,包含自动演示AI功能,使用纯HTML/CSS/JavaScript实现为单文件
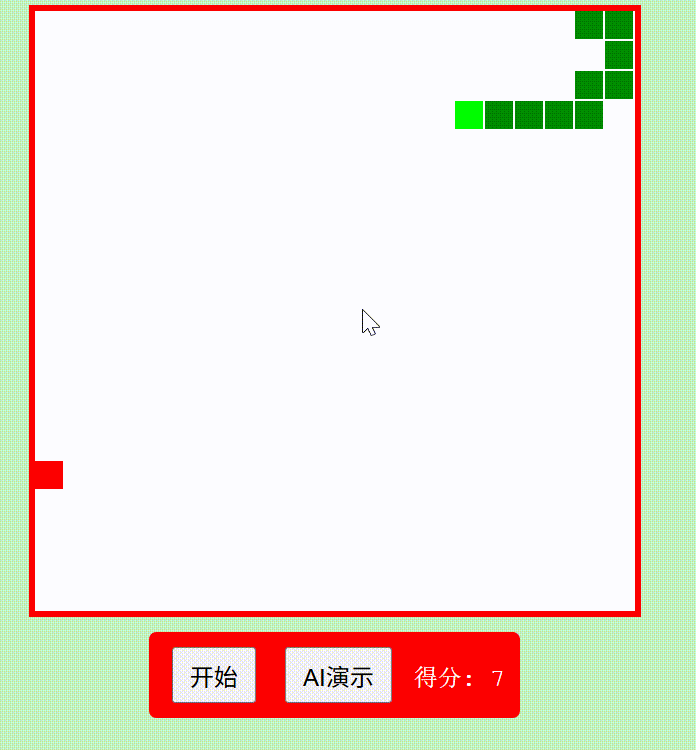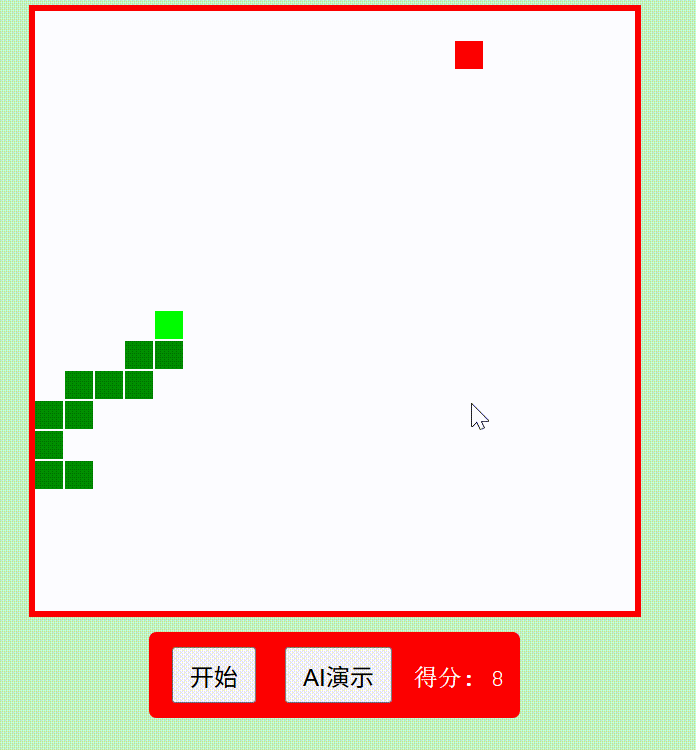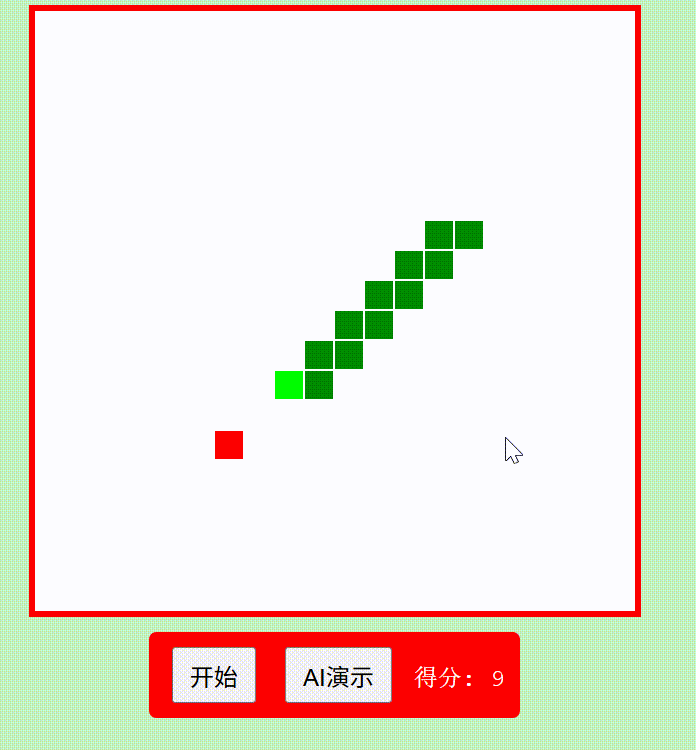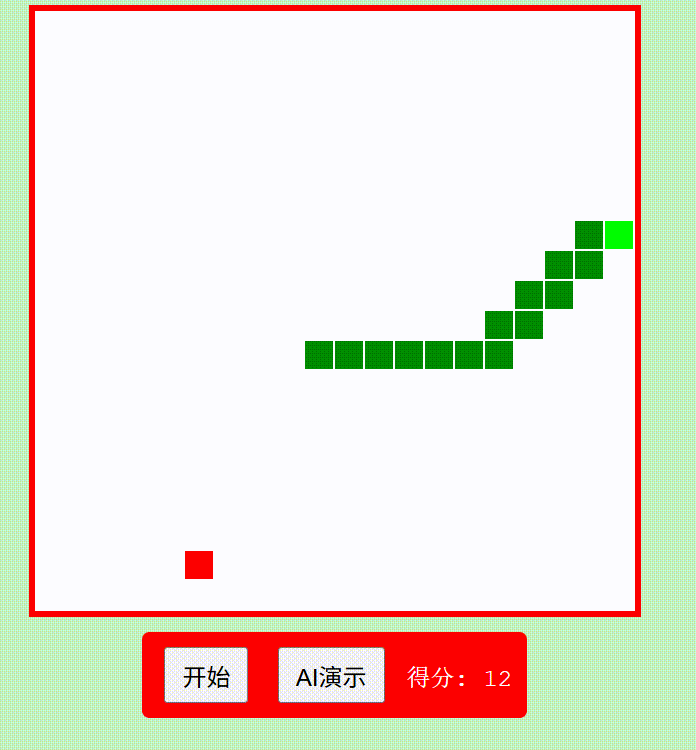
Qwen3-235B-A22B think
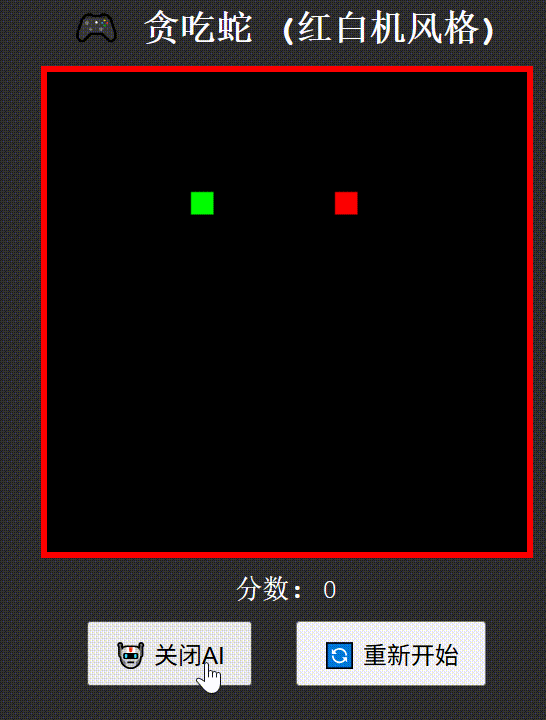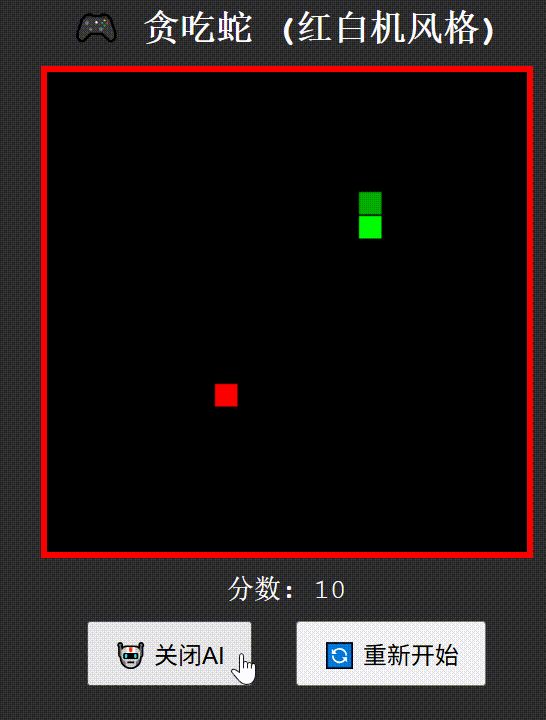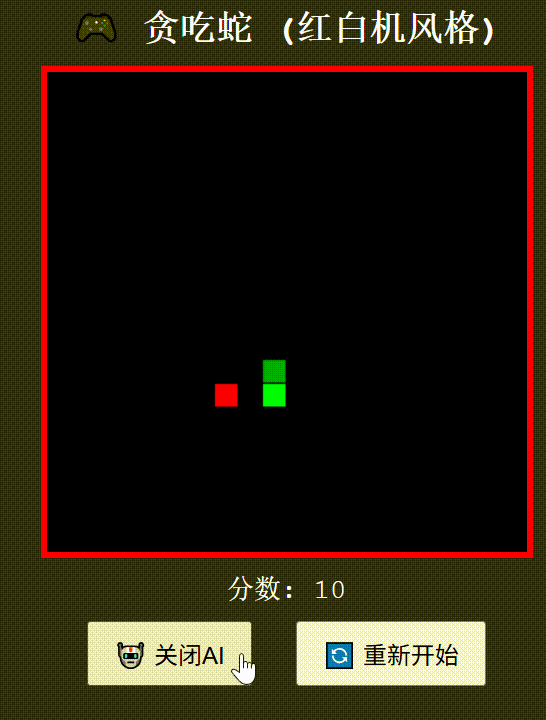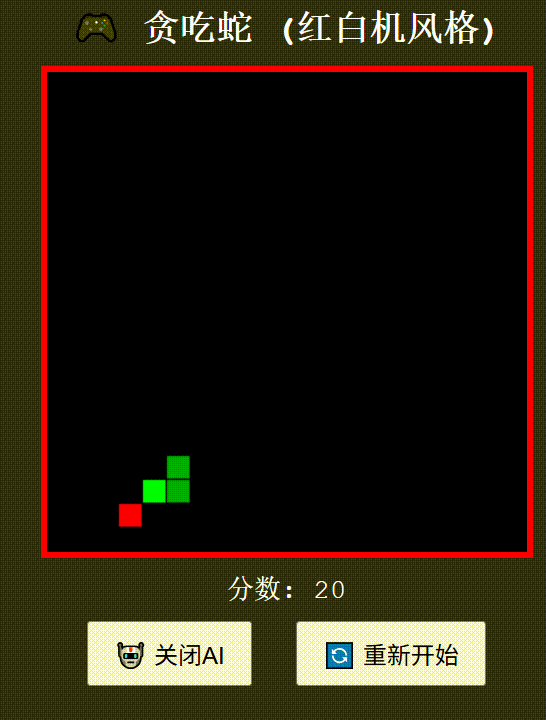
Qwen3-235B-A22B no-think
生成一个表情小游戏,提示词 来自 @甲木
请你扮演一个Web游戏开发者。设计并生成一个**表情符号反应堆 **的游戏。
1、核心创意: 一个快节奏的反应游戏。屏幕上会快速闪过一个目标表情符号(例如:笑脸😄),下方会同时出现3-4个选项表情符号,玩家需要在限定时间内(例如1-2秒)点击与目标匹配的那个表情符号。
2、玩法:
- 屏幕中央显示目标Emoji。
- 下方按钮区域快速刷新3-4个Emoji选项,其中一个是正确的。
- 玩家需在计时条走完前点击正确的Emoji。
- 点击正确得分,速度加快;点击错误或超时则游戏结束(或扣除生命值)。
- 显示最高分。
3、技术实现 (HTML/JS/CSS):
- HTML: 用于显示目标Emoji、选项按钮、计时条、得分。
- CSS: 设计简洁明快的界面,计时条动画。
- JavaScript:
存储一个Emoji列表。
随机选择目标Emoji和干扰项。
动态更新按钮内容。
实现计时器逻辑和倒计时动画。
处理点击事件,判断对错,更新得分/状态。
控制游戏节奏(逐渐加快)。
4、趣味点: 简单上手,考验反应速度,利用通用的Emoji增加亲和力和趣味性,适合碎片时间玩。
Qwen3-235B-A22B think
再来一个小游戏,提示词 来自 @甲木
请你扮演一个Web游戏开发者。设计并生成一个**单一的HTML文件**,使用HTML Canvas、CSS和JavaScript,制作一个简单的像素风格宠物收集小游戏。**重点要求:**
1、一定要注意审美,做出来的网页要有美感。
2、页面要有设计感,有足够的传播度**要求:**
1. **游戏内容 (由你生成):*** **游戏名称:** (例如:“像素爪爪接星星” 或 “方块萌宠大作战”)* **宠物描述:** 描述一个简单的像素宠物形象(可以用文字描述其构成,例如“一个10x10像素的橙色方块身体,上方有两个小三角形耳朵”),并给它起个名字。* **玩法说明:** 简要说明如何用左右箭头键移动宠物,目标是接住从上方掉落的“金元宝”(或其他像素物品),并显示得分。
2. **HTML结构:*** 包含标题、宠物描述和玩法说明。* 一个 `<canvas>` 元素 (`id="gameCanvas"`) 用于绘制游戏。* 一个区域 (`id="score"`) 显示当前得分。
3. **CSS样式 (内部 `<style>` 标签):*** 基础页面布局,将Canvas居中。* 为Canvas添加一个简单的边框。* 设置得分显示区域的样式。
4. **JavaScript逻辑 (内部 `<script>` 标签):*** 获取Canvas 2D渲染上下文。* 定义游戏对象:* `player`: 包含 x, y, width, height, color (或简单的像素绘制函数) 和速度。* `items`: 一个数组,存储掉落物对象,每个对象包含 x, y, width, height, color (或形状) 和下落速度。* **绘制函数:*** `drawPlayer()`: 在Canvas上绘制玩家宠物(根据描述用 `fillRect` 绘制简单的像素形状)。* `drawItems()`: 遍历 `items` 数组并在Canvas上绘制所有掉落物。* `clearCanvas()`: 清除画布。* **游戏逻辑:*** `updatePlayer()`: 根据按键状态(左右箭头)更新玩家位置,限制在画布边界内。* `updateItems()`: 更新每个掉落物的位置,移除掉到屏幕外的物品。随机生成新的掉落物。* `detectCollision()`: 检测玩家与掉落物的碰撞。如果碰撞,增加得分,并从 `items` 数组中移除该物品。* `updateScore()`: 更新HTML中得分显示。* **输入处理:** 添加 `keydown` 和 `keyup` 事件监听器来控制玩家移动状态。* **游戏循环:** 使用 `requestAnimationFrame(gameLoop)` 来持续调用更新和绘制函数。* 初始化游戏状态(玩家位置、得分、物品数组等)并启动游戏循环。请将完整的、包含HTML、CSS和JavaScript的单一HTML文件代码输出。确保包含了你生成的所有游戏内容和说明。提示用户在浏览器中打开该HTML文件即可玩。
Qwen3-235B-A22B think
利用大模型进行内容可视化,生成HTLM解释内容,@向阳乔木
你是一名专业的网页设计师和前端开发专家,对现代 Web 设计趋势和最佳实践有深入理解,尤其擅长创造具有极高审美价值的用户界面。你的设计作品不仅功能完备,而且在视觉上令人惊叹,能够给用户带来强烈的"Aha-moment"体验。请根据最后提供的内容,设计一个**美观、现代、易读**的"中文"可视化网页。请充分发挥你的专业判断,选择最能体现内容精髓的设计风格、配色方案、排版和布局。**设计目标:*** **视觉吸引力:** 创造一个在视觉上令人印象深刻的网页,能够立即吸引用户的注意力,并激发他们的阅读兴趣。
* **可读性:** 确保内容清晰易读,无论在桌面端还是移动端,都能提供舒适的阅读体验。
* **信息传达:** 以一种既美观又高效的方式呈现信息,突出关键内容,引导用户理解核心思想。
* **情感共鸣:** 通过设计激发与内容主题相关的情感(例如,对于励志内容,激发积极向上的情绪;对于严肃内容,营造庄重、专业的氛围)。**设计指导(请灵活运用,而非严格遵循):*** **整体风格:** 可以考虑杂志风格、出版物风格,或者其他你认为合适的现代 Web 设计风格。目标是创造一个既有信息量,又有视觉吸引力的页面,就像一本精心设计的数字杂志或一篇深度报道。
* **Hero 模块(可选,但强烈建议):** 如果你认为合适,可以设计一个引人注目的 Hero 模块。它可以包含大标题、副标题、一段引人入胜的引言,以及一张高质量的背景图片或插图。
* **排版:*** 精心选择字体组合(衬线和无衬线),以提升中文阅读体验。* 利用不同的字号、字重、颜色和样式,创建清晰的视觉层次结构。* 可以考虑使用一些精致的排版细节(如首字下沉、悬挂标点)来提升整体质感。* Font-Awesome中有很多图标,选合适的点缀增加趣味性。
* **配色方案:*** 选择一套既和谐又具有视觉冲击力的配色方案。* 考虑使用高对比度的颜色组合来突出重要元素。* 可以探索渐变、阴影等效果来增加视觉深度。
* **布局:*** 使用基于网格的布局系统来组织页面元素。* 充分利用负空间(留白),创造视觉平衡和呼吸感。* 可以考虑使用卡片、分割线、图标等视觉元素来分隔和组织内容。
* **调性:**整体风格精致, 营造一种高级感。
* **数据可视化:** * 设计一个或多个数据可视化元素,展示Naval思想的关键概念和它们之间的关系。* 可以考虑使用思想导图、概念关系图、时间线或主题聚类展示等方式。* 确保可视化设计既美观又有洞察性,帮助用户更直观地理解Naval思想体系的整体框架。* 使用Mermaid.js来实现交互式图表,允许用户探索不同概念之间的关联。**技术规范:*** 使用 HTML5、Font Awesome、Tailwind CSS 和必要的 JavaScript。* Font Awesome: [https://cdn.staticfile.org/font-awesome/6.4.0/css/all.min.css](https://cdn.staticfile.org/font-awesome/6.4.0/css/all.min.css)* Tailwind CSS: [https://cdn.staticfile.org/tailwindcss/2.2.19/tailwind.min.css](https://cdn.staticfile.org/tailwindcss/2.2.19/tailwind.min.css)* 非中文字体: [https://fonts.googleapis.com/css2?family=Noto+Serif+SC:wght@400;500;600;700&family=Noto+Sans+SC:wght@300;400;500;700&display=swap](https://fonts.googleapis.com/css2?family=Noto+Serif+SC:wght@400;500;600;700&family=Noto+Sans+SC:wght@300;400;500;700&display=swap)* `font-family: Tahoma,Arial,Roboto,"Droid Sans","Helvetica Neue","Droid Sans Fallback","Heiti SC","Hiragino Sans GB",Simsun,sans-self;`* Mermaid: [https://cdn.jsdelivr.net/npm/mermaid@latest/dist/mermaid.min.js](https://cdn.jsdelivr.net/npm/mermaid@latest/dist/mermaid.min.js)
* 实现完整的深色/浅色模式切换功能,默认跟随系统设置,并允许用户手动切换。
* 代码结构清晰、语义化,包含适当的注释。
* 实现完整的响应式,必须在所有设备上(手机、平板、桌面)完美展示。**额外加分项:*** **微交互:** 添加微妙而有意义的微交互效果来提升用户体验(例如,按钮悬停效果、卡片悬停效果、页面滚动效果)。
* **补充信息:** 可以主动搜索并补充其他重要信息或模块(例如,关键概念的解释、相关人物的介绍等),以增强用户对内容的理解。
* **延伸阅读:** 分析文件后,提供一份"进一步阅读"的简短清单,推荐 5 本最佳相关书籍或论文,并提供简要说明或链接。**输出要求:*** 提供一个完整、可运行的单一 HTML 文件,其中包含所有必要的 CSS 和 JavaScript。
* 确保代码符合 W3C 标准,没有错误或警告。请你像一个真正的设计师一样思考,充分发挥你的专业技能和创造力,打造一个令人惊艳的网页!待处理内容:{{content}},时长00:18
创作
用贴吧嘴臭老哥的风格点评大模型套壳现象

Qwen3-235B-A22B think

Qwen3-235B-A22B no-think
说明:还可以,有那味儿。
写在最后
我得整体测试下来还是不错的,
在生成复杂代码、数学推理上,think模式要比no think模型好,
并且Qwen3的整体预训练数据量是Qwen2.5的一倍,有36T Tokens,也是下来血本了。
#Sebastian Raschka 新书《从头开始推理》抢先看
揭秘推理模型基础
推理模型发展正盛,著名 AI 技术博主 Sebastian Raschka 也正在写一本关于推理模型工作方式的新书《Reasoning From Scratch》。在此之前,他已经出版了多本 AI 领域的著名书籍,包括《Build a Large Language Model (From Scratch)》、《Machine Learning Q and AI》、《Machine Learning with PyTorch and Scikit-Learn》。
近日,他在自己的博客上放出了这本书的第一章,为 LLM 领域的推理进行了入门级的介绍,同时还概述了推断时间扩展和强化学习等技术方法。
编译了这本书的第一章,以飨读者。
- 原文地址:https://magazine.sebastianraschka.com/p/first-look-at-reasoning-from-scratch
(注:为了行文清晰,本文会将 inference 译为「推断」,将 reasoning 译为「推理」;其中 inference 指模型根据输入生成输出的计算过程(如生成文本),而 reasoning 侧重模型通过思维链等方法进行逻辑分析、因果判断或问题解决的能力。)。
欢迎来到大型语言模型(LLM)的下一阶段:推理(reasoning)。
LLM 已经改变了我们处理和生成文本的方式,但它们的成功主要得益于统计模式识别。然而,推理方法正在取得新进展,这些新技术能让 LLM 处理更复杂的任务,例如求解逻辑难题或多步骤算术题。本书的核心便是理解这些方法。
本章将介绍的内容包括:
- 在 LLM 中,「推理」的具体含义;
- 推理与模式匹配的根本区别;
- LLM 的传统预训练和后训练阶段;
- 提升 LLM 推理能力的关键方法;
- 为什么从头开始构建推理模型可以帮助我们理解它们的优势、局限性和实践中权衡。
1、在 LLM 中,「推理」究竟是什么?
什么是基于 LLM 的推理(LLM-based reasoning)?这个问题的答案和讨论本身就足以写成一本书。然而,本书与之不同,目标则是从头开始实现 LLM 推理方法,因此会更注重实践和亲自动手编程,而不是概念层面上的推理。尽管如此,我认为简要定义在 LLM 语境中所说的「推理」依然很重要。
因此,在后续章节转向编程部分之前,我想在这本书的第一节定义 LLM 语境中的推理,以及它与模式匹配和逻辑推理的关系。这将为进一步讨论 LLM 目前的构建方式、它们如何处理推理任务以及它们的优点和缺点奠定基础。
在本书中,LLM 语境中的「推理」定义如下:
在 LLM 语境中,推理是指模型在提供最终答案之前产生中间步骤的能力。这个过程通常被描述为思维链(CoT)推理。在 CoT 推理中,LLM 会显式地生成结构化的陈述或计算序列,以说明其得出结论的过程。
图 1 展示了一个简单的 LLM 多步骤(CoT)推理示例。

图 1:LLM 处理一个多步骤推理任务的简版示例。推理模型所做的并不是简单回忆一个事实,而是将多个中间推理步骤组合起来得出正确的结论。根据实现方式的不同,中间推理步骤可能会展示给用户,也可能不会。
从图 1 中可以看到,LLM 产生的中间推理步骤看起来非常像一个人大声表达内心的想法。然而,这些方法(以及由此产生的推理过程)与人类推理的相似度究竟如何仍是一个尚待解答的问题,本书也不会试图回答这个问题。我们甚至不清楚这样的问题是否可以得到明确解答。
相反,本书侧重于解释和实现能提升 LLM 的推理能力的技术,从而让 LLM 更好地处理复杂任务。我希望通过上手实践这些方法,你能更好地理解和改进那些正在开发中的推理方法,甚至探索它们与人类推理的异同。
注:LLM 中的推理过程可能与人类思维非常相似,特别是在中间步骤的表达方式上。然而,目前尚不清楚 LLM 推理是否在内部认知过程方面与人类推理相似。人类的推理方式通常是有意识地操控概念、直觉理解抽象关系或基于少数示例进行概括。相比之下,当前的 LLM 推理主要基于从训练数据中的大量统计相关性中学习到的模式,而不是显式的内部认知结构或有意识的反思。
因此,尽管推理增强型 LLM 的输出看起来有点像人类,但其底层机制(很可能)存在很大差异,并且这也是一个活跃的探索领域。
2、LLM 训练过程简介
本节将简要总结 LLM 的典型训练方式,以便我们更好地理解它们的设计并了解它们的局限性。这一背景也将有助于我们讨论模式匹配和逻辑推理之间的差异。
在应用任何的推理方法之前,传统的 LLM 训练通常分为两个阶段:预训练和后训练,如下图 2 所示。

图 2:典型 LLM 的训练流程概述。一开始,初始模型使用随机权重初始化,然后在大规模文本数据集上通过预测下一个 token 进行预训练,以学习语言模式。然后,通过指令微调和偏好微调来优化模型,使 LLM 能够更好地遵从人类指令并与人类偏好对齐。
在预训练阶段,LLM 要使用大量(可达数 TB)未标记文本进行训练,其中包括书籍、网站、研究论文和许多其他来源。LLM 的预训练目标是学习预测这些文本中的下一个词(或 token)。
当使用 TB 级文本进行大规模预训练时,当前领先的 LLM 往往会使用数千台 GPU 运行数月时间,还会花费数百万美元资金,结果得到的 LLM 会非常强大。这意味着它们开始有能力生成与人类书写的非常相似的文本。此外,在某种程度上,经过预训练的 LLM 将开始表现出所谓的涌现属性(emergent property),这意味着它们能执行未经明确训练的任务,包括翻译、代码生成等。
然而,这些预训练模型仅仅是后训练阶段的基础模型,后训练阶段会使用两种关键技术:监督式微调(SFT,也称指令微调)和偏好微调。后训练的目的是让 LLM 学会响应用户查询,如下图 3 所示。

图 3:语言模型在不同训练阶段的示例响应。图中,提示词要求总结睡眠与健康之间的关系。预训练 LLM 给出了一个相关但没有重点的答案,没有直接遵从指令。指令微调版 LLM 生成了与提示词一致的简洁准确的总结。而偏好微调后的 LLM 更进一步改善了响应 —— 使用了友好的语气和更有感召力的语言,使答案更具相关性和以用户为中心。
如图 3 所示,指令微调能提高 LLM 的个人助理类任务的能力,如问答、总结和翻译文本等等。然后,偏好微调阶段可完善这些能力。它有助于根据用户偏好定制响应。此外,偏好微调也常被用于使 LLM 更安全。(一些读者可能很熟悉基于人类反馈的强化学习(RLHF)等术语,它们是实现偏好微调的具体技术。)
简而言之,我们可以将预训练视为「原始语言预测」(通过下一 token 预测),它能为 LLM 提供一些基本属性和生成连贯文本的能力。然后,后训练阶段可通过指令微调提高 LLM 的任务理解能力,并通过偏好微调让 LLM 有能力创建具有特定风格的答案。
对 LLM 预训练和后训练阶段细节感兴趣的读者可以参阅《Build A Large Language Model (From Scratch)》。而当前这本关于推理的书无需有关这些阶段的知识 —— 你一开始就会获得一个已经经过预训练和后训练的模型。
3、模式匹配:LLM 如何从数据中学习
LLM 在训练时,会「阅读」海量的文本数据,并学习如何根据前文预测下一个 token。它们是靠发现数据中的统计规律,而不是真正「理解」内容。所以,即使它们能写出流畅、通顺的句子,但本质上只是在模仿表面的关联,而不是进行深入的思考。
目前大多数 LLM(比如 GPT-4o、Meta 的 Llama 3,除非专门训练过推理能力)都是这样工作的 —— 它们不会像人一样一步步逻辑推理,而是根据输入的问题,从训练数据中找到最可能的答案。简单来说,它们不是通过真正的逻辑推导来回答问题,更像是在「匹配」输入和输出的模式。
可以参考以下示例:
提示词:德国的首都是……
回答:柏林
当 LLM 回答「柏林」时,它并不是通过逻辑推理得出的结论,而只是从训练数据中记住了 「德国→柏林」这个高频搭配。这种反应就像条件反射,我们称为「模式匹配」—— 模型只是在复现学到的文字规律,并没有真正一步步思考。
但如果遇到更复杂的问题呢?比如需要根据已知事实推导答案的任务?这时候就需要另一种能力:逻辑推理。
真正的逻辑推理,是指像解数学题一样,根据前提一步步推出结论。它需要中间思考步骤,能发现前后矛盾,也能基于已定的规则判断因果关系。这和单纯「匹配文字关系」完全不同。
举个例子:
所有鸟都会飞。企鹅是鸟。那企鹅会飞吗?
如果是人类(或者真正会推理的系统),马上就能发现不对劲 —— 根据前两句看起来企鹅应该会飞,但大家都知道企鹅其实不会飞,这就矛盾了(如下图 1.4 所示)
会推理的系统会立刻抓住这个矛盾,并意识到:要么第一句话说得太绝对(不是所有鸟都会飞),要么企鹅是个例外。

图 4:前提矛盾导致的逻辑冲突示意图。根据「所有鸟都会飞」和「企鹅是鸟」这两句话,我们会推出「企鹅会飞」 的结论。但这个结论和已知事实「企鹅不会飞」直接冲突,这就产生了矛盾。
依靠于统计学习的 LLM 并不会主动识别这种矛盾。它只是根据训练数据中的文字规律来预测答案。如果在训练数据中「所有鸟都会飞」这个说法出现得特别多,模型就可能会自信地回答:「是的,企鹅会飞。」
在下一节中,我们将用一个具体的例子看看 LLM 遇到这个「所有鸟都会飞.……」的问题时,实际上会怎么回答。
4、模拟逻辑推理:LLM 如何在没有显式规则的情况下模仿推理逻辑
上一节我们说到,当遇到自相矛盾的前提时(比如「所有鸟都会飞,但企鹅不会飞」),普通 LLM 其实不会主动发现这些矛盾。它们只是根据训练时学到的文字规律来生成回答。
现在让我们看个具体例子(见图 5):像 GPT-4o 这样没有专门加强推理能力的模型,遇到这个「所有鸟都会飞...」的问题时,会怎么回答呢?

图 5:语言模型(GPT-4o)如何处理矛盾前提的示例。
从图 5 的例子可以看到,虽然 GPT-4o 并不是专门的推理模型(不像 OpenAI 其他专门开发了推理功能的版本,比如 o1 和 o3),但它在这个问题上却给出了看似正确的回答。
这是怎么回事?难道 GPT-4o 真的会逻辑推理吗?其实不然,不过至少说明,4o 在它熟悉的场景中,能够非常逼真地「装」出逻辑推理的样子。
其实 GPT-4o 并不会主动检查说法是否自相矛盾。它的回答完全基于从海量数据中学到的「文字搭配概率」。
举个例子:如果在训练数据中,经常出现「企鹅不会飞」这样的正确说法,模型就会牢牢记住「企鹅」和「不会飞」之间的关联。就像图 5 展示的,虽然 4o 没有真正的逻辑推理能力,但靠着这种「文字概率记忆」,它也能给出正确答案。
简单来说:它不是在用逻辑规则思考,而是靠「见得多了自然记住」的方式在回答问题。
简单来说,模型之所以能「察觉」这个矛盾,是因为它在训练时反复见过类似的例子。这种能力完全来自于它在海量数据中学习到的文字规律 —— 就像我们常说的「熟能生巧」,见得多了自然就会了。
换句话说,就算像图 5 里那样,普通 LLM 看似在进行逻辑推理,其实它并不是按照规则一步步思考,而只是在运用从海量训练数据中学到的文字规律。
不过,ChatGPT 4o 能答对这个问题,恰恰说明了一个重要现象:当模型经过超大规模训练后,它的这种「隐性规律匹配」能力可以变得非常强大。但这种基于统计规律的模式也存在明显短板,比如遇到以下情况时就容易出错:
- 遇到全新题型(训练数据里完全没见过的逻辑问题)→ 就像让一个只会刷题的学生突然碰到从没见过的考题;
- 问题太复杂(需要环环相扣的多步推理)→ 类似让计算器解一道需要写证明过程的数学大题;
- 需要严格逻辑推导(但训练数据中没有类似案例)→ 好比让背过范文的学生现场创作全新体裁的文章。
既然规则系统这么靠谱,为什么现在不流行了?其实在 80、90 年代,基于规则的系统确实很火,像医疗诊断、法律判决、工程设计这些领域都在用。直到今天,在一些性命攸关的领域(比如医疗、法律、航天),我们还是能看到它们的身影 —— 毕竟这些场合需要清晰的推理过程和可追溯的决策依据。但这种系统有个硬伤:它完全依赖人工编写规则,开发起来特别费劲。相比之下,像 LLM 这样的深度神经网络,只要经过海量数据训练,就能灵活处理各种任务,适用性广多了。
我们可以这样理解:LLM 是通过学习海量数据中的规律来「装」逻辑推理的。虽然它们内部并不运行任何基于规则的逻辑系统,但可以通过一些专门的优化方法(比如增强推理计算能力和后训练策略)来进一步提升这种模拟能力。
值得一提的是,LLM 的推理能力其实是一个渐进发展的过程。早在 o1 和 DeepSeek-R1 这类专业推理模型出现之前,普通 LLM 就已经能展现出类似推理的行为了 —— 比如通过生成中间步骤来得出正确结论。而现在我们所说的 「推理模型」,本质上就是把这种能力进一步强化和优化的结果,主要通过两种方式实现:1. 采用特殊的推断计算扩展技术,2. 进行针对性的后训练。
本书后续内容将重点介绍这些提升大语言模型解决复杂问题能力的进阶方法,帮助你更深入地理解如何增强大语言模型这种「隐性」的推理能力。
5、提升 LLM 的推理能力
大语言模型的「推理能力」真正进入大众视野,是在 2024 年 9 月 12 日 OpenAI 发布 o1 的时候。在那篇官宣文章里,OpenAI 特别提到
这些新版 AI 不像以前那样秒回,而是会像人类一样先琢磨几秒,确保答案更靠谱。
OpenAI 还特别说明:
这种强化过的思考能力,对解决科学、编程、数学等领域的复杂问题特别有帮助 —— 毕竟这些领域的问题,往往需要多转几个弯才能想明白。
虽然 o1 的具体技术细节没有公开,但普遍认为它是在 GPT-4 等前代模型基础上,通过「增强推断计算能力」来实现更强的思考能力的。
几个月后的 2025 年 1 月,深度求索公司发布了 DeepSeek-R1 模型和技术报告,详细介绍了训练推理模型的方法,引起了巨大轰动。因为:
- 他们不仅免费开源了一个性能媲美甚至超越 o1 的模型;
- 还公开了如何开发这类模型的完整方案。
本书将通过从零实现这些方法,带你看懂这些提升 AI 推理能力的技术原理。如图 6 所示,目前增强大语言模型推理能力的方法主要可以分为三大类:

图 6:提升大语言模型推理能力的三大方法。这三大方法(推断计算增强、强化学习和知识蒸馏)通常是在模型完成常规训练后使用的。所谓常规训练包括:基础模型训练、预训练、指令微调和偏好微调。
如图 6 所示,这些增强方法都是用在已经完成上述常规训练阶段的模型上的。
推断时间计算增强
推断时间计算扩展(也叫推断计算增强、测试时增强等)包含一系列在推理阶段(即用户输入提示词时)提升模型推理能力的方法,这些方法无需对底层模型权重进行训练或修改。其核心思想是通过增加计算资源来换取性能提升,借助思维链推理(chain-of-thought reasoning)及多种采样程序等技术,使固定参数的模型展现出更强的推理能力。
强化学习(RL)
强化学习是一类通过最大化奖励信号来提升模型推理能力的训练方法。其奖励机制可分为两类:
- 广义奖励:如任务完成度或启发式评分
- 精准可验证奖励:如数学问题正确答案或编程任务通过率
与推断时间计算增强(inference-time compute scaling)不同,RL 通过动态调整模型参数(weights updating)实现能力提升。该机制使模型能够基于环境反馈,通过试错学习不断优化其推理策略。
注: 在开发推理模型时,需明确区分此处的纯强化学习(RL)方法与常规大语言模型开发中用于偏好微调的基于人类反馈的强化学习(RLHF)(如图 2 所示)。二者的核心差异在于奖励信号的来源:RLHF 通过人类对模型输出的显式评分或排序生成奖励信号,直接引导模型符合人类偏好行为;纯 RL 则依赖自动化或环境驱动的奖励信号(如数学证明的正确性),其优势在于客观性,但可能降低与人类主观偏好的对齐度。典型场景对比:纯 RL 训练:以数学证明任务为例,系统仅根据证明步骤的正确性提供奖励;RLHF 训练:需人类评估员对不同输出进行偏好排序,以优化符合人类标准(如表述清晰度、逻辑流畅性)的响应。
监督微调与模型蒸馏
模型蒸馏是指将高性能大模型习得的复杂推理模式迁移至更轻量化模型的技术。在 LLM 领域,该技术通常表现为:使用高性能大模型生成的高质量标注指令数据集进行监督微调(Supervised Fine-Tuning, SFT)。这种技术在 LLM 文献中常统称为知识蒸馏(Knowledge Distillation)或蒸馏(Distillation)。
与传统深度学习的区别:经典知识蒸馏中,「学生模型」需同时学习「教师模型」的输出结果和 logits,而 LLM 的蒸馏通常仅基于输出结果进行迁移学习。
注:本场景采用的监督微调(SFT)技术与常规大语言模型开发中的 SFT 类似,其核心差异体现在训练样本由专为推理任务开发的模型生成(而非通用 LLM)。也因此,其训练样本更集中于推理任务,通常包括中间推理步骤。
6、从头构建推理模型的重要性
自 2025 年 1 月 DeepSeek-R1 发布以来,提高 LLM 的推理能力已成为 AI 领域最热门的话题之一。原因也不难理解。更强的推理能力使 LLM 能够解决更复杂的问题,使其更有能力解决用户关心的各种任务。
OpenAI CEO 在 2025 年 2 月 12 日的一份声明也反映了这种转变:
我们接下来将发布 GPT-4.5,即我们在内部称之为 Orion 的模型,这是我们最后一个非思维链模型。在此之后,我们的首要目标是统一 o 系列模型和 GPT 系列模型,方法是打造可以使用我们所有工具、知道何时需要或不需要长时间思考并且可以广泛用于各种任务的系统。
以上引文凸显了领先的 LLM 提供商向推理模型的转变。这里,思维链是指一种提示技术,其能引导语言模型逐步推理以提高其推理能力。
另一点也值得一提,「知道何时需要或不需要长时间思考」也暗示了一个重要的设计考量:推理并不总是必要或可取的。
举个例子,推理模型在设计上就是为了解决复杂任务设计的,如解决难题、高级数学问题和高难度编程任务。然而,对于总结、翻译或基于知识的问答等简单任务来说,推理并不是必需的。事实上,如果将推理模型用于一切任务,则可能效率低下且成本高昂。例如,推理模型通常使用起来成本更高、更冗长,有时由于「过度思考」更容易出错。此外,这里也适用一条简单的规则:针对具体任务使用正确的工具(或 LLM 类型)。
为什么推理模型比非推理模型成本更高?
主要是因为它们往往会产生更长的输出,这是由于中间推理步骤解释了得出答案的方式。如图 7 所示,LLM 一次生成一个 token 的文本。每个新 token 都需要通过模型进行完整的前向传递。因此,如果推理模型产生的答案是非推理模型的两倍长,则需要两倍的生成步骤,从而导致计算成本增加一倍。这也会直接影响 API 使用成本 —— 计费通常基于处理和生成的 token 数量。

图 7:LLM 中的逐个 token 生成。在每一步,LLM 都会获取迄今为止生成的完整序列并预测下一个 token—— 可能代表词、子词或标点符号,具体取决于 token 化器。新生成的 token 会被附加到序列中,并用作下一步的输入。这种迭代解码过程既用于标准语言模型,也用于以推理为中心的模型。
这直接凸显了从头开始实现 LLM 和推理方法的重要性。这是了解它们的工作方式的最佳方式之一。如果我们了解 LLM 和这些推理模型的工作原理,我们就能更好地理解这些权衡。
7、总结
- LLM 中的推理涉及使用中间步骤(思维链)来系统地解决多步骤任务。
- 传统的 LLM 训练分为几个阶段:预训练,模型从大量文本中学习语言模式;指令微调,可改善模型对用户提示词的响应;偏好微调,使模型输出与人类偏好对齐。
- LLM 中的模式匹配完全依赖于从数据中学习到的统计关联,这可使得文本生成流畅,但缺乏明确的逻辑推理。
- 可以通过这些方式来提高 LLM 中的推理能力:推断时间计算扩展,无需重新训练即可增强推理能力(例如,思维链提示);强化学习,使用奖励信号显式地训练模型;监督微调和蒸馏,使用来自更强大推理模型的示例。
- 从头开始构建推理模型可以提供有关 LLM 能力、局限性和计算权衡的实用见解。
以上就是 Sebastian Raschka 新书《Reasoning From Scratch》第一章的主要内容,可以说通过一些基础介绍为这本书奠定了一个很好的基调。你对推理模型有什么看法,对这本书有什么期待吗?
#LoRA中到底有多少参数冗余
新研究:砍掉95%都能保持高性能
LoRA 中到底存在多少参数冗余?这篇创新研究介绍了 LoRI 技术,它证明即使大幅减少 LoRA 的可训练参数,模型性能依然保持强劲。研究团队在数学推理、代码生成、安全对齐以及 8 项自然语言理解任务上测试了 LoRI。发现仅训练 LoRA 参数的 5%(相当于全量微调参数的约 0.05%),LoRI 就能匹配或超越全量微调、标准 LoRA 和 DoRA 等方法的性能。

大型语言模型的部署仍然需要大量计算资源,特别是当需要微调来适应下游任务或与人类偏好保持一致时。
为了降低高昂的资源成本,研究人员开发了一系列参数高效微调(PEFT)技术。在这些技术中,LoRA 已被广泛采用。
不过,LoRA 仍然会带来显著的内存开销,尤其是在大规模模型中。因此,近期研究聚焦于通过减少可训练参数数量进一步优化 LoRA。
最近的研究表明,增量参数(微调后的参数减去预训练模型参数)存在显著冗余。受随机投影有效性和增量参数冗余性的启发,来自马里兰大学和清华大学的研究者提出了带有降低后的干扰的 LoRA 方法——LoRI(LoRA with Reduced Interference)。
LoRI 保持低秩矩阵 A 作为固定的随机投影,同时使用任务特定的稀疏掩码训练矩阵 B。为了保留 B 中最关键的元素,LoRI 通过选择所有层和投影中具有最高幅度的元素来执行校准过程,从而提取稀疏掩码。
如图 1(a) 所示,即使 B 具有 90% 的稀疏性且 A 保持冻结状态,LoRI 仍能保持良好性能。这表明适应过程不需要更新 A,且 B 存在相当大的冗余。通过应用比 LoRA 更受约束的更新,LoRI 显著减少了可训练参数的数量,同时在适应过程中更好地保留了预训练模型的知识。


多任务学习对于实现具有多任务能力的通用模型至关重要,传统上通过在任务特定数据集的组合上进行联合训练来实现。然而,在这种数据混合上训练大型模型在时间和计算资源上成本过高。模型合并是一种无需训练的替代方案,通过组合现有模型来构建强大的模型。这种方法非常适合合并 LoRA 适配器,使单个 LoRA 具备多任务能力。
然而,如图 1(b) 所示,直接合并异构 LoRA 通常会导致参数干扰,使合并后的 LoRA 性能低于单任务 LoRA。此外,许多现有的合并方法需要反复试验才能确定特定任务组合的最佳方法。
LoRI 通过实现适配器合并而无需手动选择合并方法来解决这些挑战。通过使用固定的、随机初始化的投影 A,LoRI 将任务特定的适配器映射到近似正交的子空间,从而减少合并多个 LoRI 时的干扰。
除了多任务处理外,安全关键场景要求每个新引入的适配器在增强模型能力的同时保持预训练基础模型的安全对齐。LoRI 提供了一种轻量级的持续学习方法,用于调整模型同时保持安全性,其中训练是在任务间顺序进行的。该策略首先在安全数据上微调适配器以建立对齐,然后分别适应每个下游任务。
然而,如图 1(c) 所示,持续学习常常导致灾难性遗忘,即对新任务的适应会严重损害先前获得的知识。LoRI 通过特定任务掩码利用矩阵 B 的稀疏性来减轻遗忘。这种跨任务参数更新的隔离促进了干扰最小化的持续学习,同时保持了安全性和任务有效性。
为评估 LoRI 的有效性,作者在涵盖自然语言理解、数学推理、代码生成和安全对齐任务的多种基准上进行了大量实验。
以 Llama-3-8B 和 Mistral-7B 作为基础模型,他们的结果表明,LoRI 达到或超过了全量微调(FFT)、LoRA 和其他 PEFT 方法的性能,同时使用的可训练参数比 LoRA 少 95%。值得注意的是,在使用 Llama-3 的 HumanEval 上,B 中具有 90% 稀疏度的 LoRI 比 LoRA 高出 17.3%。

除单任务适应外,他们还评估了 LoRI 在多任务环境中的表现,包括适配器合并和持续学习场景。LoRI 适配器的串联合并总体上始终优于 LoRA 适配器,与单任务 LoRA 基线的性能非常接近。在持续学习方面,LoRI 在减轻安全对齐的灾难性遗忘方面显著优于 LoRA,同时在下游任务上保持强劲表现。

- 论文标题:LoRI: Reducing Cross-Task Interference in Multi-Task LowRank Adaptation
- 论文链接:https://arxiv.org/pdf/2504.07448
- 代码链接:https://github.com/juzhengz/LoRI
- HuggingFace:https://huggingface.co/collections/tomg-group-umd/lori-adapters-67f795549d792613e1290011
方法概览
如下图所示,论文中提出的 LoRI 方法主要有以下要点:
- LoRI 冻结投影矩阵 A_t,并使用特定任务的掩码稀疏更新 B_t;
- LoRI 支持多个特定于任务的适配器合并,减少了参数干扰;
- LoRI 通过不断学习和减少灾难性遗忘来建立安全适配器。

在作者推文评论区,有人问这个方法和之前的方法(如 IA3)有何不同。作者回复称,「IA3 和 LoRI 在调整模型参数的方式上有所不同:IA3 学习键/值/FFN 激活的 scaling 向量。可训练参数就是 scaling 向量。LoRI(基于 LoRA)将权重更新分解为低秩矩阵。它将 A 保持冻结,并对 B 应用固定的稀疏性掩码。所以只有 B 的未掩蔽部分被训练。」

实验结果
作者采用 Llama-3-8B 和 Mistral7B 作为基准模型,所有实验均在 8 块 NVIDIA A5000 GPU 上完成。如图 1(a) 所示,LoRI 在矩阵 B 达到 90% 稀疏度时仍能保持强劲性能。为探究稀疏度影响,作者提供了两个 LoRI 变体:使用稠密矩阵 B 的 LoRI-D,以及对矩阵 B 施加 90% 稀疏度的 LoRI-S。
单任务性能
表 1 展示了不同方法在 8 个自然语言理解(NLU)基准测试中的单任务结果,表 2 则报告了不同方法在数学、编程和安全基准上的表现。


全参数微调(FFT)会更新所有模型参数,而 LoRA 和 DoRA 将可训练参数量降至约 1%。LoRI-D 通过冻结矩阵 A 进一步将参数量压缩至 0.5%,LoRI-S 则通过对矩阵 B 施加 90% 稀疏度实现 0.05% 的极致压缩——相比 LoRA 减少 95% 可训练参数。尽管调参量大幅减少,LoRI-D 和 LoRI-S 在 NLU、数学、编程及安全任务上的表现均与 LoRA、DoRA 相当甚至更优。
适配器融合
作者选取 NLU、数学、编程和安全四类异构任务进行 LoRA 与 LoRI 融合研究,该设定比融合同类适配器(如多个 NLU 适配器)更具挑战性。
表 3 呈现了四类任务的融合结果。作者对 LoRI-D 和 LoRI-S 变体分别采用串联融合与线性融合。由于 LoRI 已对矩阵 B 进行稀疏化,基于剪枝的方法(如幅度剪枝、TIES、DARE)不再适用——这些方法会剪枝矩阵 A,导致 AB 矩阵剪枝策略不一致。

如表 3 所示,直接融合 LoRA 会导致性能显著下降(特别是代码生成与安全对齐任务)。虽然剪枝方法(如 DARE、TIES)能提升代码性能,但往往以牺牲其他任务精度为代价。相比之下,LoRI 在所有任务上均表现稳健,其中 LoRI-D 的串联融合方案整体表现最佳,几乎与单任务基线持平,这表明 LoRI 适配器间存在最小干扰。
持续学习
虽然合并适配器能够实现多任务能力,但在需要强大安全保障的场景中,它无法提供稳健的安全对齐。如表 3 所示,通过 LoRA 或 LoRI 合并所能达到的最高安全得分为 86.6。
为了解决这一问题,作者采用了两阶段训练过程:首先,在 Saferpaca 安全对齐数据集上训练安全适配器;然后,将其分别适应到各个下游任务,包括自然语言理解(NLU)、数学和代码。
图 3 展示了这些持续学习实验的结果。LoRA 在安全对齐上表现出严重的灾难性遗忘——尤其是在安全→NLU 实验中——这可能是由于 NLU 训练集较大(约 17 万个样本)所致。在所有方法中,LoRI-S 实现了对安全对齐的最佳保留,甚至优于单任务 LoRI-D。这是因为其 B 矩阵具有 90% 的稀疏性,能够在安全对齐和任务适应之间实现参数更新的隔离。LoRI-D 也表现出一定的抗遗忘能力,得益于其冻结的 A 矩阵。对于任务适应,LoRI-D 通常优于 LoRI-S,因为后者激进的稀疏性限制了其适应能力。

总体而言,LoRI 提供了一种轻量级且有效的方法来构建安全适配器,在支持下游任务适应的同时保持对齐。
#ICML 2025放榜
接收率26.9%,高分被拒,低分录用惹争议
第 42 届国际机器学习大会(ICML)将于 2025 年 7 月 13 日至 19 日在加拿大温哥华举行。刚刚,ICML 官方向投稿者发送了今年论文接收结果的通知。
数据显示,今年大会共收到 12107 篇投稿,较去年增加了 28%。共有 3260 篇论文被接收,接收率为 26.9%。其中,只有 313 篇论文被选为「spotlight poster」。
在收到邮件的第一时间,不少研究者都晒出了自己被接收的论文。当然,也有研究者感到沮丧或对评审结果有所质疑。在这篇文章中,我们汇总了一些被接收的优秀论文以及有争议的论文,方便大家探讨。
被接收的高分论文
首先,我们检索了一些 spotlight 论文,因为这是 ICML 官方推荐度最高的一批论文,能搜到的论文包括但不限于:
- Neural Discovery in Mathematics: Do Machines Dream of Colored Planes?(数学中的神经发现:机器会梦见彩色的平面吗?)
- Monte Carlo Tree Diffusion (MCTD) for System 2 Planning(用于 System 2 规划的蒙特卡罗树扩散(MCTD)方法)
- Layer-wise Alignment:Examining Safety Alignment Across lmage Encoder Layers in Vision Language Models(逐层对齐:视觉语言模型中图像编码器层间的安全对齐)
- The Number of Trials Matters in Infinite-Horizon General-Utility Markov Decision Processes(试验次数在无限时域一般效用马尔可夫决策过程中的重要性)
- Implicit Language Models are RNNs: Balancing Parallelization and Expressivity(隐式语言模型即 RNN:平衡并行性与表达能力)
- ……




此外,我们还发现,一些国内大厂的论文在评审中拿到了高分或 Spotlight,比如字节跳动的两篇论文:
论文 1:MARS: Unleashing the Power of Variance Reduction for Training Large Models(平均得分:4.25)

MARS 是一个用于 LLM 的方差缩减自适应优化器框架,其收敛速率为𝒪(T⁻²/³),优于 AdamW 的𝒪(T⁻¹/²)。该方法的 2.0 版本将在之后发布。
论文 2:ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference(Spotlight)

还有一些论文虽然拿到了高分,但并未被选为 Spotlight,这类论文同样值得关注,比如下面这篇伊利诺伊大学厄巴纳-香槟分校的论文:EMBODIEDBENCH: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents(平均得分:4.5)

- 链接:https://arxiv.org/pdf/2502.09560

EmbodiedBench 是一个用于评估多模态大语言模型(MLLMs)作为视觉驱动的具身智能体的综合性基准测试平台。它包含 1128 个测试任务,涵盖四个环境,从高级语义任务(如家务)到涉及原子动作的低级任务(如导航和操作)。此外,EmbodiedBench 还设有六个精心策划的子集,用于评估智能体的关键能力,如常识推理、复杂指令理解、空间意识、视觉感知和长期规划。
充满争议的被拒论文
除了被接收的论文,一些被拒的论文同样值得讨论,因为这些论文的价值可能未被充分挖掘。
一个研究者晒出了元评审截图,尽管其论文获得高度评价,却仍被拒绝。

这并非孤例,其他研究者也反映了类似遭遇。

令人费解的是,一些评分较低的论文反而被接收。

另一位研究者表示,他收到了不完整、无关且敷衍的评审意见。虽然向科学诚信委员会举报并得到确认该评审质量确实低下,但领域主席(AC)依然拒绝了他的论文。

评审过程中的矛盾同样引人关注。
有研究者发现,他的论文实际获得了两个 4 分,但元评审却错误地将其记录为三个 3 分加一个 4 分。同时,元评审声称某位评审人还有疑问,而该评审人在反驳阶段已明确表示其疑虑已解决。

其他研究者也指出了评审和编辑的粗心。

#InfiGUI-R1
浙大&港理工等提出:利用强化学习,让GUI智能体学会规划任务、反思错误
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。
我们认为,要真正提升 GUI 智能体的能力,关键在于从「反应式」迈向「深思熟虑的推理者」(Deliberative Reasoners)。为此,浙江大学联合香港理工大学等机构的研究者们提出了 InfiGUI-R1,一个基于其创新的 Actor2Reasoner 框架训练的 GUI 智能体,旨在让 AI 像人一样在行动前思考,行动后反思。
论文标题:InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
论文链接:https://arxiv.org/abs/2504.14239
项目仓库:https://github.com/Reallm-Labs/InfiGUI-R1
模型地址:https://huggingface.co/Reallm-Labs/InfiGUI-R1-3B
从「反应行动」到「深思熟虑」:GUI 智能体面临的挑战
想象一下,你让 AI Agent 帮你完成一个多步骤的手机操作,比如「预订明天下午去北京的高铁票」。一个简单的「反应行动」式 Agent 可能会按顺序点击它认为相关的按钮,但一旦遇到预期外的界面(如弹窗广告、加载失败),就容易卡壳或出错,因为它缺乏「规划」和「反思」的能力。
为了让 GUI 智能体更可靠、更智能地完成复杂任务,它们需要具备深思熟虑的推理能力。这意味着智能体的行为模式需要从简单的「感知 → 行动」转变为更高级的「感知 → 推理 → 行动」模式。这种模式要求智能体不仅能看懂界面,还要能:
- 理解任务意图:将高层指令分解为具体的执行步骤
- 进行空间推理:准确理解界面元素的布局和关系,定位目标
- 反思与纠错:识别并从错误中恢复,调整策略
Actor2Reasoner 框架:两步走,打造深思熟虑的推理者
为了实现这一目标,研究团队提出了 Actor2Reasoner 框架,一个以推理为核心的两阶段训练方法,旨在逐步将 GUI 智能体从「反应式行动者」培养成「深思熟虑的推理者」。

图:Actor2Reasoner 框架概览
第一阶段:推理注入(Reasoning Injection)—— 打下推理基础
此阶段的核心目标是完成从「行动者」到「基础推理者」的关键转变。研究者们采用了空间推理蒸馏(Spatial Reasoning Distillation)技术。他们首先识别出模型在哪些交互步骤中容易因缺乏推理而出错(称之为「推理瓶颈样本」),然后利用能力更强的「教师模型」生成带有明确空间推理步骤的高质量执行轨迹。
通过在这些包含显式推理过程的数据上进行监督微调(SFT),引导基础模型学习在生成动作前,先进行必要的逻辑思考,特别是整合 GUI 视觉空间信息的思考。这一步打破了「感知 → 行动」的直接链路,建立了「感知 → 推理 → 行动」的基础模式。
第二阶段:深思熟虑增强(Deliberation Enhancement)—— 迈向高级推理
在第一阶段的基础上,此阶段利用强化学习(RL)进一步提升模型的「深思熟虑」能力,重点打磨规划和反思两大核心能力。研究者们创新性地引入了两种方法:
- 目标引导:为了增强智能体「向前看」的规划和任务分解能力,研究者们设计了奖励机制,鼓励模型在其推理过程中生成明确且准确的中间子目标。通过评估生成的子目标与真实子目标的对齐程度,为模型的规划能力提供有效的学习信号。
- 错误回溯:为了培养智能体「向后看」的反思和自我纠错能力,研究者们在 RL 训练中有针对性地构建了模拟错误状态或需要从错误中恢复的场景。例如,让模型学习在执行了错误动作后如何使用「返回」等操作进行「逃逸」,以及如何在「回到正轨」后重新评估并执行正确的动作。这种针对性的训练显著增强了模型的鲁棒性和适应性。
为了有效引导强化学习过程,研究者们还采用了一套专门适用于 GUI 多种任务场景的奖励函数,为智能体提供更佳的反馈。
InfiGUI-R1-3B:小参数,大能量
基于 Actor2Reasoner 框架,研究团队训练出了 InfiGUI-R1-3B 模型(基于 Qwen2.5-VL-3B-Instruct)。尽管只有 30 亿参数,InfiGUI-R1-3B 在多个关键基准测试中展现出了卓越的性能:
GUI 元素定位(Grounding)能力突出:
- 在跨平台(移动、桌面、网页)的 ScreenSpot 基准上,平均准确率达到 87.5%,在移动、桌面、Web 平台的文本和图标定位任务上全面领先,达到同等参数量模型中 SOTA 水平。
- 在更具挑战性、面向复杂高分屏桌面应用的 ScreenSpot-Pro 基准上,平均准确率达到 35.7%,性能比肩参数量更大且表现优异的 7B 模型(如 UI-TARS-7B),证明了其在复杂专业软件(例如 CAD、Office)界面上的指令定位准确性。

表:ScreenSpot 性能对比

图:ScreenSpot-Pro 性能对比
复杂任务执行(Trajectory)能力优异
在模拟真实安卓环境复杂任务的 AndroidControl 基准上(包含 Low 和 High 两个难度级别),成功率分别达到 92.1% 和 71.1%。这一成绩不仅超越了参数量相近的 SOTA 模型(如 UI-TARS-2B),甚至优于一些参数量远超自身的 7B 乃至 72B 模型(如 Aguvis-72B)。

表:AndroidControl 性能对比
这些结果充分证明了 Actor2Reasoner 框架的有效性。通过系统性地注入和增强推理能力,特别是规划和反思能力,InfiGUI-R1-3B 以相对较小的模型规模,在 GUI 理解和复杂任务执行方面取得了领先或极具竞争力的表现。
结语
InfiGUI-R1 和 Actor2Reasoner 框架的提出,为开发更智能、更可靠的 GUI 自动化工具开辟了新的道路。它证明了通过精心设计的训练方法,即使是小规模的多模态模型,也能被赋予强大的规划、推理和反思能力,从而更好地理解和操作我们日常使用的图形界面,向着真正「能思考、会纠错」的 AI 助手迈出了坚实的一步。