【Linux】线程同步与互斥
在了解互斥和同步话题之前,我们回顾一下共享资源、临界资源等概念:
- 共享资源:在多线程中,所有线程都可以访问的资源就叫做共享资源,比如全局的变量等...
- 临界资源:多线程执行流中,被保护起来的共享资源就叫做临界资源。
- 临界区:每个线程内部,访问临界资源的代码,就是临界区
- 非临界区:在线程内部没有访问临界资源的代码
- 互斥:任何时刻,互斥都保证有且只有一个执行流进行临界区,访问临界资源
- 同步:任何时刻,所有的执行流都按照某种顺序,依次进行临界区,访问临界资源。
一.互斥
1.模拟抢票
// 操作共享变量会有问题的售票系统代码 #include <iostream> #include <cstdio> #include <cstdlib> #include <cstring> #include <unistd.h> #include <pthread.h>int ticket = 1000; void *route(void *arg) {char *id = (char *)arg;while (1){if (ticket > 0) // 1. 判断{usleep(1000); // 模拟抢票花的时间printf("%s sells ticket:%d\n", id, ticket); // 2. 抢到了票ticket--; // 3. 票数--}else{break;}}return nullptr; }int main(void) {pthread_t t1, t2, t3, t4;pthread_create(&t1, NULL, route, (void *)"thread 1");pthread_create(&t2, NULL, route, (void *)"thread 2");pthread_create(&t3, NULL, route, (void *)"thread 3");pthread_create(&t4, NULL, route, (void *)"thread 4");pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);return 0; }说明:这里我们写了一段模拟抢票过程的代码。首先创建4个线程,模拟多人同时进行抢票。共有1000张票,ticket--来模拟抢票成功。看结果:
这里的票数居然变成了负数,这是不符合实际情况的,其实就是发生了数据不一致问题。 我们观察线程的入口函数,其中涉及了对公共资源的访问,所有这段代码就属于临界区。
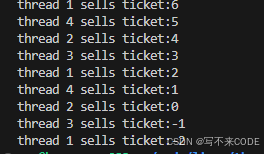
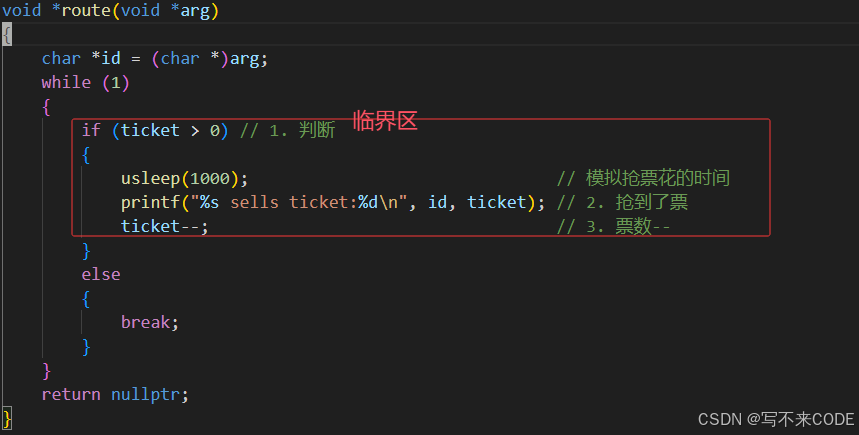
0x1.为什么票数会减到负数?
首先,ticket--;这句代码不是原子的,ticket--这段代码在底层翻译成汇编代码会变成三个指令:
- move ticket 到寄存器
- 运算器运算--
- move ticket到内存
在cpu内部执行ticket--这句代码,底层会有这三条指令,而同时cpu中的pc指针会指向将要执行的指令的地址。假如:线程A将ticket move到寄存器中,并完成了计算ticket = 99,但此时线程A被切换了。然后线程B开始抢票,因为线程A并没有将99写回内存,所以内存中还是100.在极端情况下,我们认为线程B将ticket已经减到了1,此时正准备下一次抢票,此时被切换走了,此时线程A被唤醒,并将99写回了内存,写回之后又被切换走了,线程B执行后,move到寄存器的内容就又原本的1,变成了99.这就导致了数据不一致的问题。
但是,ticket--并不会直接导致票数减到负数,我们可以看到,ticket--会使票数增多,导致售出很多票。而实际上,真正导致票数减到负数,是因为ticket>0这句判断!首先,肯定的是这个判断也不是原子的。
假设初始票数为1,此时线程A判断票数大于0,进入内部之后被切换了,此时线程B也判断票数大于0,进入内部并抢票成功,此时ticket=0。线程B退出,A唤醒,直接执行下面的ticket--操作,导致ticket=-1.如果还有更多的线程,就可能导致负数更多。
以上,就是因为多线程访问共享资源,没有施加保护,导致的并行问题,也就是线程安全问题。
现在,我们也可以暂时理解原子性就是c/c++代码转化为汇编代码后只有一句,这样就不会中途被切换了。
pc指针是怎么知道将要运行的下一句代码的地址呢?翻译成汇编指令后,每个指令都有自己的地址,除此之外还有指令的长度。而下一句指令的地址就是上一句指令的地址+上一个指令的长度。
那么线程切换的时间点是什么呢?时间片到了、阻塞式IO、sleep等,其实就是让线程陷入内核。那么什么时候选择新线程呢?从内核态,返回用户态的时候,进行检查。
0x2.解决方案:加锁
访问共享资源时,我们要对共享资源进行保护,一种方案就是加锁。当一个执行流要访问该临界资源时,先申请锁,申请成功了,再去执行后面的代码。如果申请失败了,就会链入申请锁的等待队列中。等别人释放锁了,你再申请。
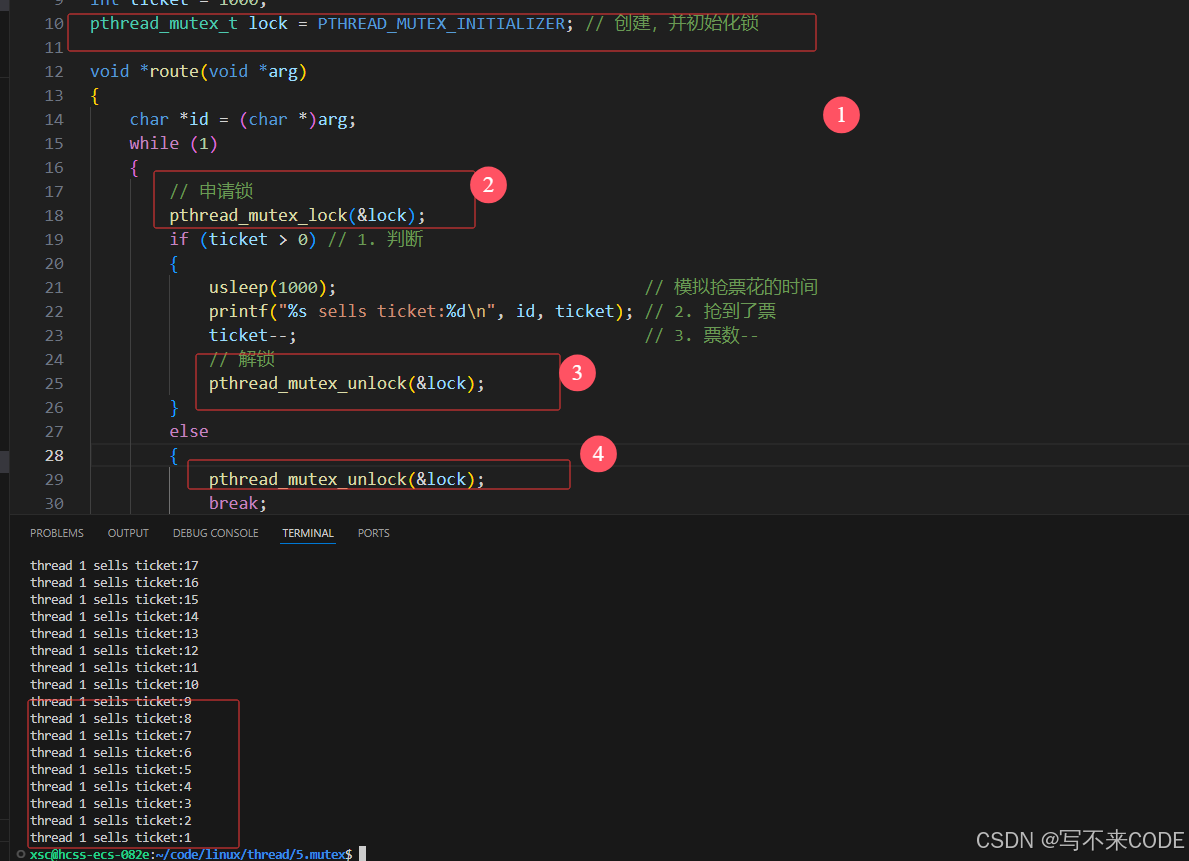
从结果来看,确实没有负数了,并且这次的打印速度比不加锁时慢。
那么既然所有人都要申请锁,那么锁也就是共享资源了,锁不需要保护么?
申请锁的过程是原子的,不会被打断。申请成功就执行继续执行下面的代码,失败阻塞挂起执行流。所以,锁提供的能力的本质:将执行临界区代码由并行转换为串行。
0x3.加锁的接口
SYNOPSIS#include <pthread.h>int pthread_mutex_destroy(pthread_mutex_t *mutex);int pthread_mutex_init(pthread_mutex_t *restrict mutex,const pthread_mutexattr_t *restrict attr);pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;SYNOPSIS#include <pthread.h>int pthread_mutex_lock(pthread_mutex_t *mutex);int pthread_mutex_trylock(pthread_mutex_t *mutex);int pthread_mutex_unlock(pthread_mutex_t *mutex);使用锁前,我们得有锁,我们可以直接定义一个全局的锁pthread_mutex_t,并用pthread_mutex_initializer初始化,该锁不需要被释放。如果创建的是局部的锁,则需要用pthead_mutex_init来初始化。并且再使用完之后还需要释放该锁。
有了锁,之后便是对临界区进行保护。首先,便是申请锁,pthread_mutex_lock,阻塞式申请。使用完后要解锁,pthread_mutex_unlock。trylock是非阻塞申请锁,不用考虑。
创建了锁,利用锁保护了临界资源,所有的线程都必须遵守,不然就会导致bug。
加锁之后,在临界区内部,线程是可以被切换的。因为当前的线程并没有释放锁,我是再持有锁的过程中被切换的,即使我不在,其他线程也无法申请锁。只能等到我回来执行完临界区代码,释放锁后,其他线程才开始竞争锁。
2.锁的理解
0x1.锁的原理
硬件原理:
之所以,会导致数据不一致问题就是因为才访问临界资源时被切换下去了。而实际上就是触发了时钟中断,进行了线程调度。所以硬件实现互斥锁就是关闭时钟中断。
软件原理:
在软件层实现互斥锁,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相互交换。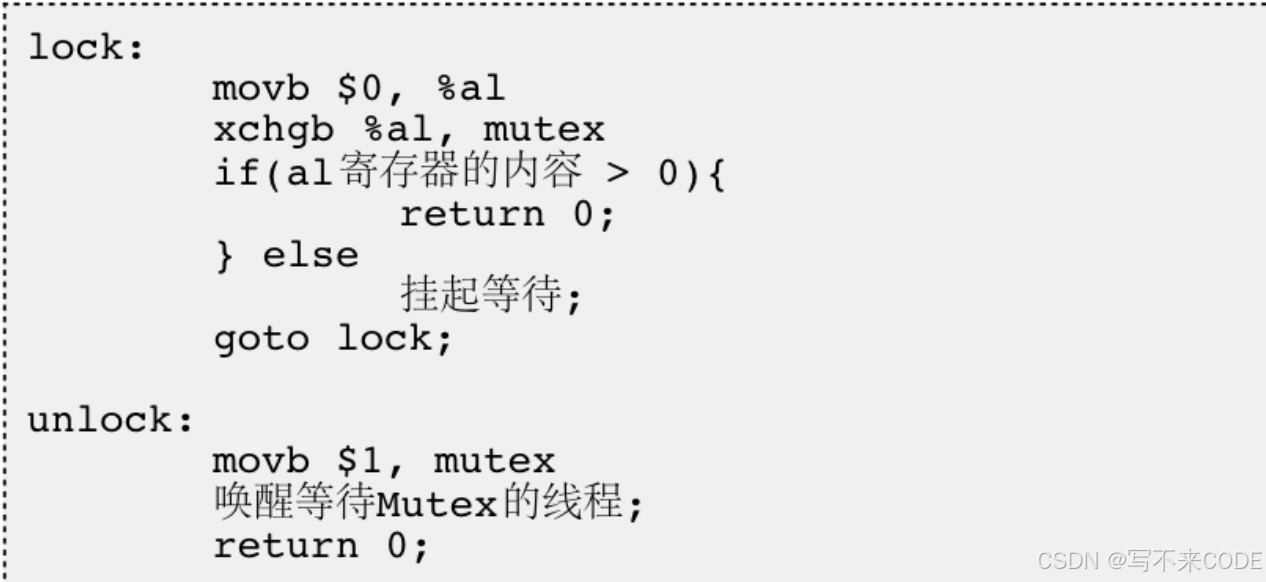
当我们创建一个锁,这个锁的内容其实就是一个数字1。申请锁的过程就是先将cpu中al寄存器置零。然后将al寄存器的内容和锁的内容进行交换,注意这里是交换,不是拷贝。如果交换成功,此时la寄存器为1,判断成功,就返回,表示申请成功。否则就会挂起等待。
当然,我们再清空al寄存器时会被切换,但是交换操作是原子的。当一个线程申请成功之后,下一个线程申请时,就只会从内存中交换0,所以不会成功。
解锁,直接让有锁的进程将内存中的锁置为1即可。不用清空al,因为al会在每一次申请锁时置零。
0x2.封装互斥锁
#pragma once#include <iostream>
#include <cstdio>
#include <cstring>
#include <pthread.h>namespace MyMutex
{class mutex{public:mutex(){int n = pthread_mutex_init(&_mutex, nullptr);if (n != 0){std::cerr << "init mutex fail " << std::strerror(n) << std::endl;return;}}void lock(){int n = pthread_mutex_lock(&_mutex);if (n != 0){std::cerr << "apply lock failed" << std::strerror(n) << std::endl;return;}}void unlock(){int n = pthread_mutex_unlock(&_mutex);if (n != 0){std::cerr << "unlock lock failed" << std::strerror(n) << std::endl;return;}}~mutex(){int n = pthread_mutex_destroy(&_mutex);if (n != 0){std::cerr << "destroy mutex fail " << std::strerror(n) << std::endl;return;}}private:pthread_mutex_t _mutex;};// RAII风格封装互斥锁// 利用对象的声明周期来管理资源class mutexguard{public:mutexguard(mutex& mutex):_m(mutex){_m.lock();}~mutexguard(){_m.unlock();}private:mutex& _m;};
}封装的使用:
#include "lock.hpp"
using namespace MyMutex;class mutexData
{
public:mutexData(MyMutex::mutex &lock, const std::string &name): _lock(&lock), _name(name){}~mutexData() {}MyMutex::mutex *_lock;std::string _name;
};int ticket = 1000;void *route(void *arg)
{mutexData* md = static_cast<mutexData*>(arg);while (1){// 加锁//md->_lock->lock();mutexguard lock(*md->_lock);if (ticket > 0) // 1. 判断{usleep(1000); // 模拟抢票花的时间printf("%s sells ticket:%d\n", md->_name.c_str(), ticket); // 2. 抢到了票ticket--; // 3. 票数--// 解锁//md->_lock->unlock();}else{//md->_lock->unlock();break;}}return nullptr;
}int main(void)
{// 创建锁MyMutex::mutex lock;pthread_t t1, t2, t3, t4;mutexData *d1 = new mutexData(lock, "thread-1");pthread_create(&t1, nullptr, route, d1);mutexData *d2 = new mutexData(lock, "thread-2");pthread_create(&t1, nullptr, route, d2);mutexData *d3 = new mutexData(lock, "thread-3");pthread_create(&t1, nullptr, route, d3);mutexData *d4 = new mutexData(lock, "thread-4");pthread_create(&t1, nullptr, route, d4);pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);return 0;
}二.同步
我们利用互斥解决了抢票的问题,这样解决并没有错,但是却不太公平。我们看,利用互斥解决抢票之后,虽然解决了负数的问题,但有可能导致一个人长时间能抢到票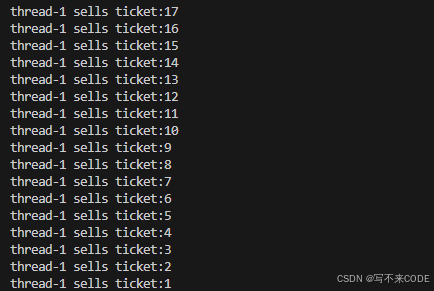
这说明1号线程频繁的申请到了锁。因为一号线程正持有锁,它释放锁之后,可以快速的回到申请锁的位置,而其他线程还得先唤醒,所以这样就导致1号线程频繁申请了锁,频繁的访问临界资源,导致其他线程无法获取锁,发生了饥饿问题,从而导致了结果不公平现象。
所以:
- 当一个线程释放锁之后,不能立马申请第二次。
- 阻塞挂起的线程要进行排队,不能都一股脑的竞争锁,要有一定的顺序性。释放锁的要跑到队尾,进行二次申请。
所以,再保证临界资源安全的前提下,让所有的执行流,访问临界区的时候,具有一定的顺序性去访问临界资源。这就是线程同步。
1.条件变量
条件变量通常与互斥锁一起使用,互斥锁用于保护共享资源,而条件变量用于线程间基于条件的等待和通知机制。
工作原理:
- 当一个线程需要等待某个特定条件满足时,它会先获取互斥锁,然后检查条件是否满足。如果不满足,线程会调用条件变量的等待函数,释放互斥锁并进入休眠状态。
- 当其他线程改变了可能影响等待条件的共享变量后,会调用条件变量的通知函数来唤醒一个或多个在条件变量上等待的线程。被唤醒的线程重新获取互斥锁,然后检查条件是否满足,如果满足就继续执行。
理解条件变量:
假设现在有一个放苹果的游戏,放苹果的人和拿苹果的人都被蒙着眼睛,因为放苹果的碗是临界资源,所以访问碗前要先申请锁。但是因为没有同步机制,如果拿苹果的人申请到了锁,发现里面没有苹果,释放锁之后,他就最有可能申请到下一次锁,导致一直在做无用功。如果是放苹果的先,他申请锁的可能性也很大,导致每一次进去都有苹果。
有了条件变量之后,当拿苹果的人,申请到锁,访问时发现没有苹果,就让他在该条件变量下等待。而放苹果的人,放了之后,就发一个通知给条件变量,条件变量就将在它下面等待的人叫出来一个,去取苹果。
所以,我们可以理解条件变量为一个铃铛,当条件满足了,就摇铃铛,通知阻塞队列中,如果条件不满足,就让线程在条件变量下的阻塞队列挂起。
2.条件变量接口
SYNOPSIS#include <pthread.h>// 销毁条件变量int pthread_cond_destroy(pthread_cond_t *cond);// 初始化条件变量int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr);pthread_cond_t cond = PTHREAD_COND_INITIALIZER; // 条件变量(全局的用宏来初始化)// 阻塞接口,让线程在指定的条件变量下等待int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex)// signal唤醒指定条件变量下等待的一个线程int pthread_cond_signal(pthread_cond_t *cond);// broadcast将指定条件变量下的线程全部唤醒int pthread_cond_broadcast(pthread_cond_t *cond);条件变量的使用与互斥锁的使用非常类似,所以这里就不过多介绍了。
注意:条件变量让线程进行阻塞等待是因为条件不满足,而这里的条件一定是对临界资源来说的,所以条件变量让线程等待是在临界区内部因为临界资源不满足某种条件导致线程等待的。所以条件变量的时候要在临界区中。
注意这里的wait接口,为什么传入一个环境变量外,还要传一个互斥锁呢?
首先,阻塞是在临界区内部的,线程阻塞了,说明其拿到了锁,但因为条件不满足,所以要进行阻塞,但是阻塞期间难道你要把锁一直拿着,不让别人访问临界资源么?当然不行了,所以,当线程阻塞之后,要将锁释放掉,以便其他线程申请锁。
3.生产者消费者模型
以我们日常生活中的超时为例,生产者将生产出来的商品直接送到超市,而消费者想要购买东西也直接从超时进行购买。
生产和消费之间:
如果没有这样的生产消费模式,而是直接让生产者和消费者对接的话,如果生产的多了,没有人买,生产者就没法再生产了,就得等有人消费了,再生产。如果消费的多了,生产者跟不上,消费者就得等生产者生产。
从上面就可以看出,消费者和生产者是同步关系。
而有了超市,生产者不需要管有没有消费者,只需要将生产的产品交给超市即可。对于消费者也一样,消费者不需要管生产者有没有产品,直接去超市消费即可。但是生产者再为超市上货时,本来有20箱,但是此时消费者同时也在买货,导致再最后核算的时候,导致数据不一致。所以,同一时间,生产者和消费者只能有一个人访问超市。
从上面就可以看出,生产者和消费者是互斥关系。
生产者之间:
对于同一个超市来说,超市能容纳的商品数是有上限的,一共100个货架,放了A厂的100个,就放不下B厂的
所以,生产者之间是互斥关系。
消费者之间:
与生产者之间类似,超市一共就这么多库存,你买了,我就买不了了。
所以,消费者之间也是互斥关系。
而在多线程编程中,生产者和消费者就用多个线程来承担,而超市就是一块共享的内存空间。该模型通常用于解决共享资源的访问和控制问题,适用于多个生产者线程产生数据并放入共享缓冲区,多个消费者线程从共享缓冲区中取出数据进行消费的场景。
总结:
在生产者和消费者模型中,一共有三种关系(生产-生产,消费-消费,生产-消费),两种角色(生产者和消费者,都由线程来承担),1个交易场所(1个共享的内存空间)。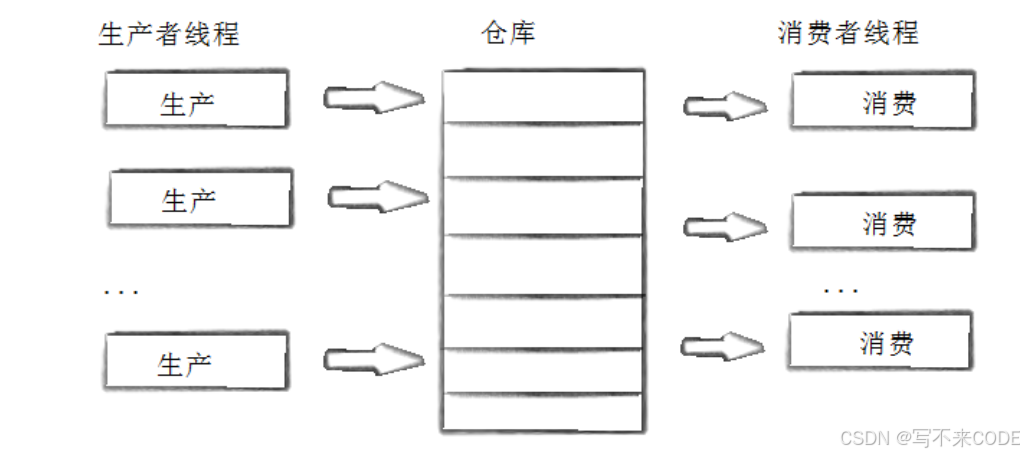
为什么要有生产者消费者模型呢?
- 解耦生产和消费过程:生产者和消费者之间没有直接的依赖关系,它们通过共享缓冲区进行通信。这使得生产者和消费者可以独立开发、测试和优化,增强了系统的模块化和可维护性。
- 支持忙闲不均:生产者 - 消费者模型通过共享缓冲区和同步机制,使得生产者和消费者可以在速度不匹配的情况下仍然能够高效地协作。它能够动态地适应生产者和消费者之间的“忙闲”差异,即生产者和消费者在生产、消费数据速度上的不均匀,从而保证系统的稳定性和资源的有效利用。
- 提高效率:在该模型中,最耗时的不是生产者将数据放入缓冲区,也不是消费者从缓冲区拿数据,而是产生数据和处理数据,而这两个过程是互相独立的。及生产者生产数据和消费者处理数据是可以同时进行的。
4.基于blockqueue的生产消费模型
0x1.阻塞队列
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。与普通队列的区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列为满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出。
也就是说,阻塞队列是一个有着固定大小的交易场所,所有的生产者线程在访问时,满了就不能在继续放数据了,所有的消费者在访问时,空的话就不能访问了。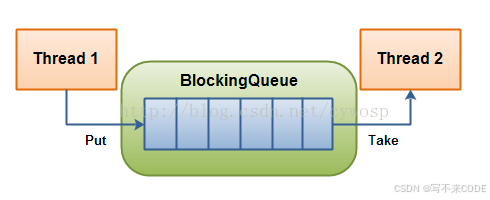
0x2.实现blockqueue
#pragma once#include <iostream>
#include <queue>
#include <pthread.h>const int defaultcap = 5;template<typename T>
class BlockQueue
{
private:bool isfull() { return _capacity <= _blockq.size(); }bool isempty() { return _blockq.empty(); }
public:BlockQueue(int cap = defaultcap):_capacity(cap), _consumer_sleep(0), _producer_sleep(0){// 初始化锁和条件变量pthread_mutex_init(&_mutex, nullptr);pthread_cond_init(&_consumer, nullptr);pthread_cond_init(&_producer, nullptr);}~BlockQueue(){// 销毁锁和条件变量pthread_mutex_destroy(&_mutex);pthread_cond_destroy(&_consumer);pthread_cond_destroy(&_producer);}void emplace(const T& data){// 1.插入数据时先加锁pthread_mutex_lock(&_mutex);// 2.如果阻塞队列满了,就在生产者条件变量下等待while(isfull()){_producer_sleep++;pthread_cond_wait(&_producer, &_mutex);_producer_sleep--;}// 3.阻塞队列没满就直接入队列_blockq.emplace(data);// 生产者生成一个数据之后,就可以唤醒消费者了if(_consumer_sleep > 0){pthread_cond_signal(&_consumer);}// 4.解锁pthread_mutex_unlock(&_mutex);}T pop(){// 1.访问数据先加锁pthread_mutex_lock(&_mutex);// 2.如果阻塞队列为空,则消费者的条件变量下等待while(isempty()){_consumer_sleep++;//std::cout << "队列为空,阻塞 " << _consumer_sleep << std::endl;pthread_cond_wait(&_consumer, &_mutex);_consumer_sleep--;}// 3.如果有数据就直接读取T ret = _blockq.front();_blockq.pop();// 消费者读取一个数据就有空间了,此时就可以唤醒生产者if(_producer_sleep > 0){pthread_cond_signal(&_producer);}// 4.解锁pthread_mutex_unlock(&_mutex);// 5.返回数据return ret;}
private:std::queue<T> _blockq;int _capacity;pthread_mutex_t _mutex;pthread_cond_t _producer;pthread_cond_t _consumer;int _consumer_sleep;int _producer_sleep;
};- 当条件不满足时,生产者线程/消费者线程要在对应的条件变量下进行等待,而等待的时候,需要将已经申请的锁给释放掉。
- 当线程被唤醒时,是在临界区内醒的,但因为访问临界区需要加锁,所以在ptherad_cond_wait内部会申请锁,如果申请成功就继续向后运行,否则就在锁上阻塞等待。
- pthread_cond_wait是函数,所以有可能会失败,如果线程阻塞失败了,会直接返回,而此时条件可能还不满足,直接向后运行,就可能导致数据不一致问题。并且我们在唤醒线程时,可能会一次性唤醒多个线程,但只有一个消费者/生产者可以执行后续代码,执行完毕后,剩下的线程不会在检查条件是否满足,而直接向后运行,也会导致数据不一致的问题——伪唤醒。所以,在调用pthread_cond_wait时要在循环中调用,避免阻塞失败/伪唤醒问题。
三.信号量
在进程间通信那里,我们了解了SystemV标准的信号量。而POSIX信号量与SystemV版的信号量是类似的。
1.信号量概念
信号量本质上就是一个计数器,是一种对资源的预定机制。当线程访问临界资源时,都要先申请信号量,本质上就是计数器--;使用完之后要释放信号量,本质上就是信号量++。而信号量要被所有的线程看到,所以也是临界资源。但信号量的PV操作都是原子的。
多线程使用临界资源,两种场景:
- 将目标资源整体使用,2元信号量+互斥锁。(只有一个座位的电影放映厅)
- 将目标资源按照不同的块分批使用。(普通电影放映厅,有多个作为,允许多个线程同时进入,访问不同的位置)
2.基于环形队列的生产者消费者模型
0x1.环形队列
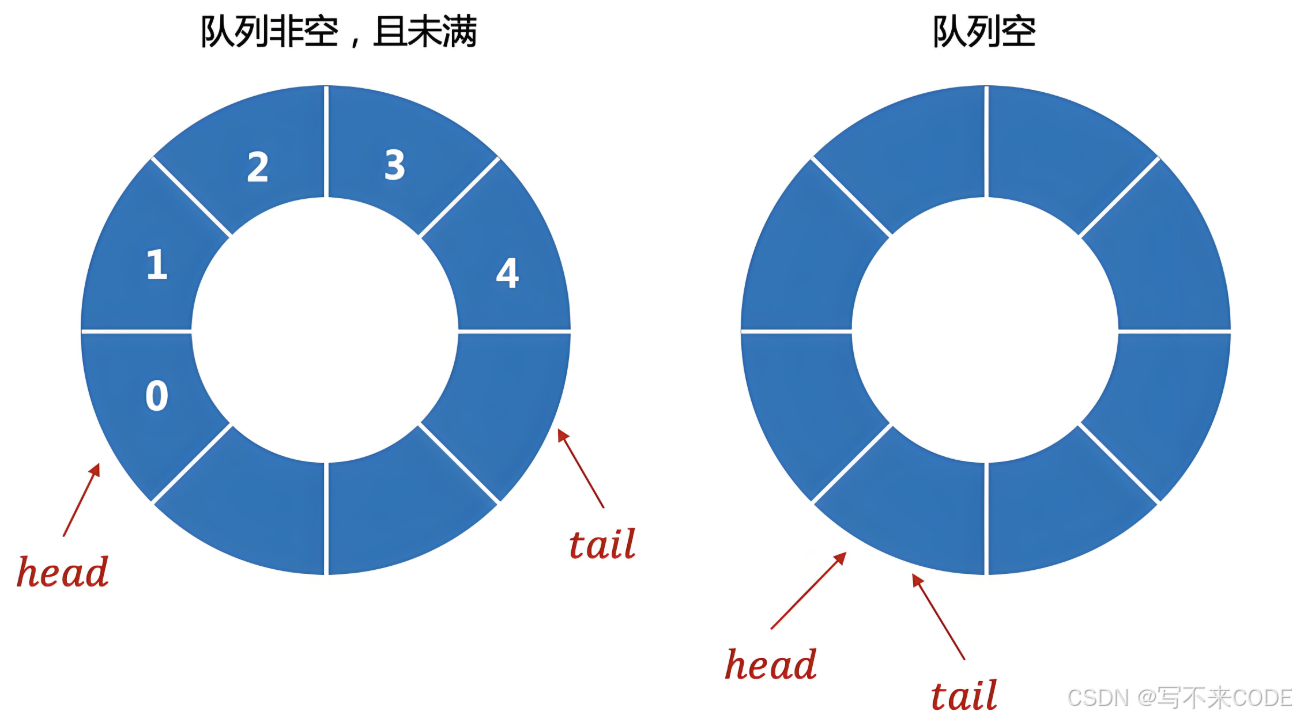
对于环形队列来说,当队列为空或者为满时,它的头尾指针都指向同一个位置,并不好判断此时队列到底是空还是满。所以为了解决问题,有两种方式:
- 定义一个int count,插入数据的同时count++,当count==capacity时,表示环形队列为满。
- 空一个位置,N个位置,只放N-1个元素,当tail->next==head时,表示队列为满。
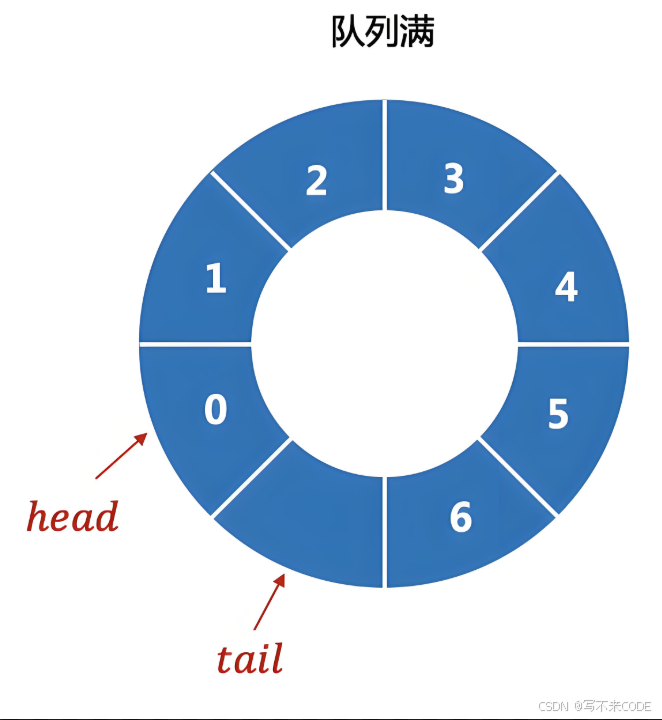
实现该环形队列,我们可以使用数组来模拟,定义一个大小固定的数组。为了使数组成环,所以我们在访问数组的时候要对下标进行取模运算。当要越界的时候,下标就会自动从头开始。
0x2.环形队列生产消费过程
在单生产者、单消费者的场景下,生产消费者需要遵守一下约定:
- 当队列为空时,此时只能让生产者先运行。
- 当队列为满时,此时只能让消费者先运行。
- 生产者不能将消费者套一个圈,生产者将消费者套一圈表明产生了数据覆盖。
- 消费者不能超过生产者,超过了,说明此时消费者会对空位置进行访问。
由以上约定,可以得出一下结论:
- 只要生产者和消费者不访问同一个位置,就可以同时进行生产消费。
- 当队列为空或者为满的时候,消费者和生产者在同一个位置。也就是说,当队列不为空,不为满的时候就可以同时进行!!!
- 为空时:只能(互斥),生产者先(同步)运行;为满时:只能(互斥),消费者先(同步)运行
那么我们如何通过实现这样的生产消费过程呢? 借助信号量!!!
而对于消费者和生产者而言,它们访问的资源是不一样的。生产者要访问的是空位置,而消费者要访问的是有数据的位置。所以,我们在使用信号量对这个位置进行管理的时候,需要使用两个信号量,分别描述空位置和有数据的位置——_consumer_sem, _producer_sem.
生产者:
1.先申请信号量_producer_sem;
2.申请成功开始生产,申请失败在信号量处阻塞等待;
3.生产成功后,此时就有了数据,就得让表示数据的信号量++,表示数据多了一个,_consumer_sem;
消费者:
1.先申请信号量_consumer_sem;
2.申请成功开始消费,申请失败在信号量处阻塞等待
3.消费成功后,就多了一个空位置,此时让表示空位置的信号量++,表示多了一个空位置,_producer_sem;
有了上述操作,就可以实现基于环形队列的生产消费模型了。
3.信号量接口
SYNOPSIS#include <semaphore.h>sem_t _sem; // 信号量 // 初始化信号量// 第二个参数表明是否要与进程关联,设为0即可// 第三个参数表示信号量个数int sem_init(sem_t *sem, int pshared, unsigned int value);// 销毁信号量int sem_destroy(sem_t *sem);// 申请信号量——p操作int sem_wait(sem_t *sem);// ++信号量——V操作int sem_post(sem_t *sem);信号量封装:
#pragma once#include <iostream>
#include <semaphore.h>const unsigned int defaultCapacity = 1;
namespace MySem
{class sem{public:sem(const unsigned int cap = defaultCapacity){sem_init(&_sem, 0, cap);}~sem(){sem_destroy(&_sem);}void P(){sem_wait(&_sem);}void V(){sem_post(&_sem);}private:sem_t _sem;};
}4.实现环形队列生产消费者模型
#include <iostream>
#include <vector>
#include "mutex.hpp"
#include "sem.hpp"using namespace MyMutex;
using namespace MySem;const int defaultCap = 5;template <typename T>
class RingQueue
{
public:RingQueue(const int cap = defaultCap): _Ringq(cap), _capacity(cap), _consumer_sem(0), _producer_sem(cap), _consumer_step(0), _producer_step(0){}~RingQueue() {}void emplace(const T& data){// 多生产,多消费// 需要维护生产者之间的互斥,以及消费者之间的互斥 --- 加锁_producer_sem.P();// 加锁_producer_mutex.lock();_Ringq[_producer_step++] = data;_producer_step %= _capacity;// 解锁_producer_mutex.unlock();_consumer_sem.V();生产者插入数据单生产1.申请信号量//_producer_sem.P();2.生产//_Ringq[_producer_step++] = data;3.维护环形特性,避免越界//_producer_step %= _capacity;4.生产一个,消费者就可以消费了,增加数据信号量//_consumer_sem.V();}void pop(T* out){// 消费者获取数据// 单消费// 1.申请信号量_consumer_sem.P();// 加锁_consumer_mutex.lock();// 2.消费*out = _Ringq[_consumer_step++];// 3.维护环形特性,避免下标越界_consumer_step %= _capacity;// 解锁_consumer_mutex.unlock();// 4.消费一个,就有了空盘子,增加空位置信号量_producer_sem.V();}
private:std::vector<T> _Ringq; // 数组模拟环形队列int _capacity; // 环形队列容量上限// 生产者消费者信号量---空信号量,有数据信号量sem _consumer_sem;sem _producer_sem;// 消费者生产者下标int _consumer_step;int _producer_step;// 锁---用来维护生产者之间,消费者之间的互斥关系mutex _consumer_mutex;mutex _producer_mutex;
};在单生产者单消费者模式下,只需要维护生产者和消费者之间的互斥和同步关系即可。
在多生产和多消费模式下,除了维护生产者和消费者之间的互斥同步之外,还有生产者之间消费者之间的互斥关系。
以多个生产者为例,我们需要保证同时只能由一个生产者进行生产,所以我们需要进行加锁,而加锁时,我们最好先申请信号量再加锁。这样就可以让所有的生产者先准备好资源,只需要等待锁即可。如果先申请锁的话,所有的生产者会先等锁,等锁的时候什么也干不了。
总结:
当我们访问的临界资源可以拆分,就是用信号量
当我们访问资源不可拆分,只能整体使用,就可以使用mutex互斥量。