[Survey] Image Segmentation in Foundation Model Era: A Survey
BaseInfo
| Title | Image Segmentation in Foundation Model Era: A Survey |
| Adress | https://arxiv.org/pdf/2408.12957 |
| Journal/Time | - |
| Author | 北理工、上交、浙大 CCAI 、瑞士苏黎世联邦理工学院、德国慕尼黑工业大学 |
| Code | https://github.com/stanley-313/ImageSegFM-Survey |
1. Introduction
通用图像分割(即语义分割、实例分割、全景分割)
可提示的图像分割(即交互式分割、指代分割、少样本分割)

开创性算法 N-Cut、FCN 和 MaskFormer -> adapting FMs: CLIP、Stable Diffusion、DINO -> SAM, SAM2 专有的。
将像素划分为不同的组 -> 更高级目标(包括物理场景理解、基于视觉常识的推理、感知社交关联)-> 自动驾驶、医学图像分析、自动监控和图像编辑等众多领域
- 传统的非深度学习方法,如阈值分割 [1, 2]、直方图模式搜索 [3, 4]、区域生长和合并 [5, 6]、空间聚类 [7]、能量扩散 [8]、超像素 [9]、条件随机场和马尔可夫随机场 [10]
- 深度学习方法,例如基于全卷积网络(FCN)的方法 [11 - 20],尤其是 DeepLab 系列 [17 - 20]、基于 RNN 的方法 [21]、基于 Transformer 的方法 [22 - 28] 以及 R - CNN 系列 [29 - 31]。
- 基础模型(FMs): 包括自然语言处理 [33]、计算机视觉 [34] 以及许多跨学科领域 [35 - 37]。著名的例子包括大语言模型(LLMs),如 GPT - 3 [38] 和 GPT - 4 [39],多模态大语言模型(MLLMs),如 Flamingo [40] 和 Gemini [41],以及扩散模型(DMs),如 Sora [42] 和 Stable Diffusion(SD) [43] : 生成推理链 [46]、在对话场景中提供类似人类的回复 [38]、创建逼真的视频 [42] 以及合成新颖的程序 [47].
- 分割领域的新任务:如 zero-shot 、few-shot、开放词汇语义分割、不同的提示分割
- Training-free segmentation :无训练分割是近年来兴起的一个新兴研究领域。它旨在从预训练的FMs中提取分割知识,这标志着与已有的学习范式(如监督学习、半监督学习、弱监督学习和自监督学习)的不同。CLIP,Stable Diffusion 或DINO/DINOv2,最初不是为分割目的而设计,也可以很轻易得到 mask。
- integrating LLMs into segmentation systems : 将大语言模型融入分割系统,参考图像分割 Referring Image Segmentation 和推理图像分割 Reasoning Image Segmentation
- Generative models:特别是文本到图像的扩散模型

2. Background
分别将 X \mathcal{X} X和 Y \mathcal{Y} Y表示为输入空间和输出分割空间。图像分割解决方案旨在学习一个理想的映射函数 f f f: f : X ↦ Y ,其中 X = I × P , Y = M × C f: \mathcal{X} \mapsto \mathcal{Y} ,其中\mathcal{X} = \mathcal{I} \times \mathcal{P},\mathcal{Y} = \mathcal{M} \times \mathcal{C} f:X↦Y,其中X=I×P,Y=M×C 这里 f f f通常具体化为一个神经网络。输入空间 X \mathcal{X} X被分解为 I × P \mathcal{I} \times \mathcal{P} I×P,其中 I \mathcal{I} I代表图像域(仅包含单个图像 I I I ), P \mathcal{P} P指的是提示集合,在某些分割任务中会专门使用。输出空间 Y = M × C \mathcal{Y} = \mathcal{M} \times \mathcal{C} Y=M×C,它包含一组分割掩码 M \mathcal{M} M以及与这些掩码相关的语义类别词汇表 C \mathcal{C} C。
-
通用图像分割(GIS)输入空间仅包含图像,即 X ≡ I \mathcal{X} \equiv \mathcal{I} X≡I,这表明 P = ∅ \mathcal{P} = \emptyset P=∅ 。根据测试词汇表 C t e s t \mathcal{C}_{test} Ctest是否包含训练词汇表 C t r a i n \mathcal{C}_{train} Ctrain中不存在的新类别,这三个任务在两种设置下进行研究:封闭词汇(即 C t r a i n ≡ C t e s t \mathcal{C}_{train} \equiv \mathcal{C}_{test} Ctrain≡Ctest )和开放词汇(即 C t r a i n ⊂ C t e s t \mathcal{C}_{train} \subset \mathcal{C}_{test} Ctrain⊂Ctest )分割。
- 语义分割: 图像中每个像素所属的语义类别,该类别来自 C \mathcal{C} C
- 实例分割: 将属于同一语义类别的像素分组为单独的对象实例。
- 全景分割: 结合了语义分割和实例分割,以预测每个像素的类别和实例标签,并且能够提供全面的场景解析。
-
提示图像分割(PIS)额外纳入了一组提示 P \mathcal{P} P,用于指定要分割的目标。
- 交互式分割旨在根据用户输入(通常通过点击、涂抹、绘制框或多边形提供,即 P = { click, scribble, box, polygon } \mathcal{P} = \{\text{click, scribble, box, polygon}\} P={click, scribble, box, polygon} )分割出特定对象或部分。
- 指称分割 提取由文本短语所指的相应区域,即 P = { l i n g u i s t i c p h r a s e } \mathcal{P} = \{linguistic \space phrase\} P={linguistic phrase} 指的是文本提示。
- 少样本分割(图 1f)旨在利用少量带注释的支持图像在给定查询图像中分割新对象,即 P = { ( i m a g e , m a s k ) } \mathcal{P} = \{(image, mask)\} P={(image,mask)} 指的是图像 - 掩码对的集合。
学习策略:
i)监督学习:现代图像分割方法通常以完全监督的方式进行学习,这需要一组训练图像及其期望的输出,即每个像素的注释。
ii)无监督学习:在没有明确标注监督的情况下,逼近f 的任务属于无监督学习。现有的大多数基于无监督学习的图像分割模型利用自监督技术,用从图像数据自动生成的伪标签来训练网络。
iii)弱监督学习:在这种情况下,监督信息可能不准确、不完整或不正确。对于不准确的监督,标签通常来自更容易标注的领域(如图像标签、边界框、涂抹 )。对于不完整的监督,仅为训练图像的一个子集提供标签。不准确的监督意味着虽然存在噪声,但为所有训练图像提供每个像素的注释。
iv)自由训练:除了上述策略之外,在基础模型时代,无需训练的分割受到了关注,它旨在直接从预训练的基础模型中提取分割信息,而无需进行任何模型训练。
基础模型:any model that is trained on broad data (generally using self-supervision at scale) that can be adapted to a wide range of downstream tasks
- Language Foundation Model 语言基础模型
- Large Language Models (LLMs)
- Multimodal Large Language Models (MLLMs) 将推理能力与处理非文本模态(如视觉、音频 )的能力相结合。
- Visual Foundation Model 视觉基础模型
- Contrastive Language-Image Pre-training (CLIP). 对比学习 CLIP 和 ALIGN
- Diffusion Models (DMs) 扩散模型
- Self-Distillation with No Labels (DINO&DINOv2).
- Segment Anything (SAM)
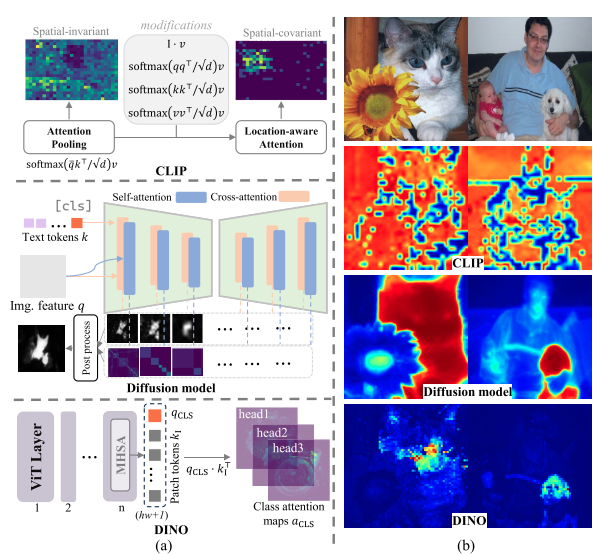
SEGMENTATION KNOWLEDGE EMERGES FROM FMS
- CLIP 学习的是整体视觉特征,位置信息相对不变。Mask-CLIP :修改 CLIP 的图像编码器:(1) 删除查询和关键嵌入层; (2) 将值嵌入层和最后一个线性层重新组合成两个各自的 1×1 卷积层。. GEM:计算 k q v 的各自通过矩阵乘法得到关联矩阵。 softmax ( q q ⊤ ) + softmax ( k k ⊤ ) + softmax ( v v ⊤ ) \text{softmax}(\mathbf{q}\mathbf{q}^\top)+\text{softmax}(\mathbf{k}\mathbf{k}^\top)+\text{softmax}(\mathbf{v}\mathbf{v}^\top) softmax(qq⊤)+softmax(kk⊤)+softmax(vv⊤)
- DM :关键在于分割源自扩散模型中的交叉注意力图。
m = CrossAttention ( q , k ) = softmax ( q k ⊤ / d ) m = \text{CrossAttention}(q, k)=\text{softmax}(qk^\top / \sqrt{d}) m=CrossAttention(q,k)=softmax(qk⊤/d) 。其中, q = Φ ( z t ) ∈ R h w × d q = \Phi(z_t) \in \mathbb{R}^{hw \times d} q=Φ(zt)∈Rhw×d , k = Ψ ( e ) ∈ R N × d k = \Psi(e) \in \mathbb{R}^{N \times d} k=Ψ(e)∈RN×d。 Φ \Phi Φ 和 Ψ \Psi Ψ 是 U - Net 中在隐空间进行去噪的线性层。 m ∈ R h w × N m \in \mathbb{R}^{hw \times N} m∈Rhw×N 表示单个头的交叉注意力图。 - DINO : 在最后一层注意力头中,通过计算类别标记 [CLS] 的查询特征 q CLS \boldsymbol{q}_{\text{CLS}} qCLS 和图像块标记 [I] 的键特征 k I ⊤ \boldsymbol{k}^{\top}_{\text{I}} kI⊤ 的点积,得到亲和向量 α CLS = q CLS ⋅ k I ⊤ ∈ R 1 × M \boldsymbol{\alpha}_{\text{CLS}} = \boldsymbol{q}_{\text{CLS}} \cdot \boldsymbol{k}^{\top}_{\text{I}} \in \mathbb{R}^{1 \times M} αCLS=qCLS⋅kI⊤∈R1×M 。对每个注意力头 α CLS \boldsymbol{\alpha}_{\text{CLS}} αCLS 进行平均,对这个最终注意力图进行二值化处理(比如设置一个阈值,大于阈值的像素设为 1,小于阈值的设为 0 ),就可以得到分割掩码.一些工作还直接利用图像块标记之间的相似性来定位目标。
4. FOUNDATION MODEL BASED GIS
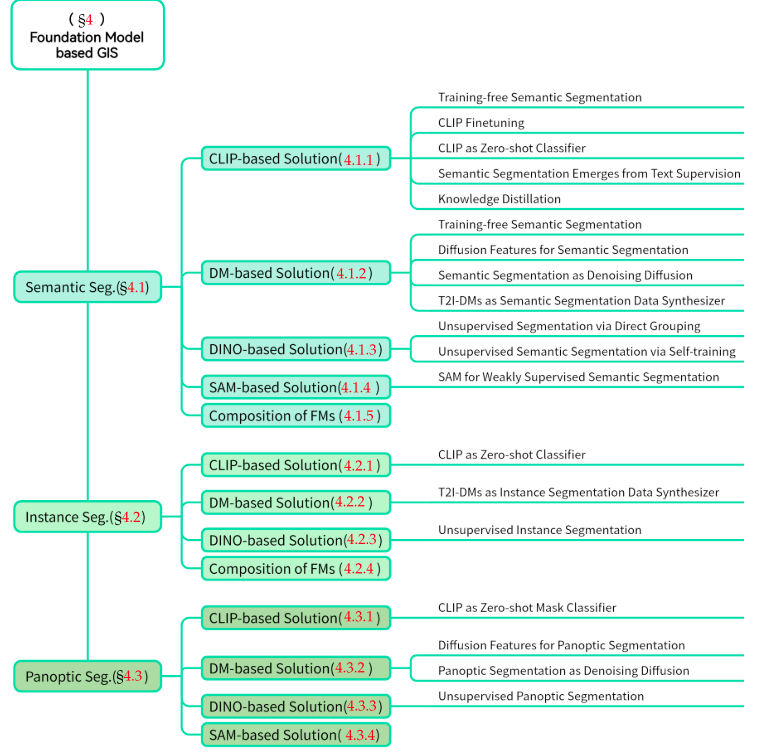
- 如何将 CLIP 中的预训练知识迁移到分割任务中?
- Training free Semantic Segmentation :对自注意力模块稍作修改,从 CLIP 导出分割掩码是可行的。)利用 CLIP 文本编码器作为分类器来确定每个掩码的类别,从而实现语义分割,整个过程无需额外训练或微调。
- CLIP 微调:遵循流行的 “预训练 - 微调” 范式,大量方法使用分割数据对 CLIP 进行微调,可分为全量微调或参数高效微调方法。全量微调方法需调整 CLIP 的整个视觉或文本编码器。防止对已见类别过拟合,它们都学习特定于图像的文本嵌入,以实现更准确的像素 - 文本对齐;
- CLIP 作为零样本分类器:掩码分类方法(文献 [128]-[136] )通常遵循两阶段范式,即首先提取与类别无关的掩码提议,然后使用预训练的 CLIP 对提议进行分类。像素分类:像素分类方法(文献 [101]、[137]-[141] )使用 CLIP 识别像素。
- 文本监督下的语义分割:TagAlign(文献 [147] )也专注于优化部分,并引入精细属性作为监督信号,实现密集的图像 - 文本对齐。
- 知识蒸馏(KD):CLIP-DINOiser(文献 [153] )将 DINO 作为教师模型,引导 CLIP 学习类似 DINO 的、有利于分割的特征。
- 扩散模型(DMs):
- Training free Semantic Segmentation:
- 利用扩散模型潜在特征进行语义分割:多数用 T2I - DMs(主要是 SD )挖掘语义表示。
- 去噪扩散模型的语义分割:将语义分割重新表述为去噪扩散过程,通过迭代去噪过程学习预测给定随机噪声 和图像编码器视觉特征条件下的噪声图
- 利用 T2I - DMs 进行数据增强,而非直接生成合成掩码。
- DINO
- 通过直接分组实现无监督分割: 直接利用 DINO 特征进行区域分组. 利用 k - means 聚类 或基于图的。
- 通过自训练实现无监督语义分割: 尝试从 DINO 特征训练分割模型,自动从 DINO 特征中获取伪标签。
- SAM : 缺乏语义感知能力,但它具有通用且出色的分割能力。在弱监督场景下常被用于提升分割质量, 比如利用 SAM 对分割掩码进行后处理,以及将其用于零样本推理.
CLIP 在语义理解方面表现出色,SAM 和 DINO 则专注于空间定位 。
5. FOUNDATION MODEL BASED PIS
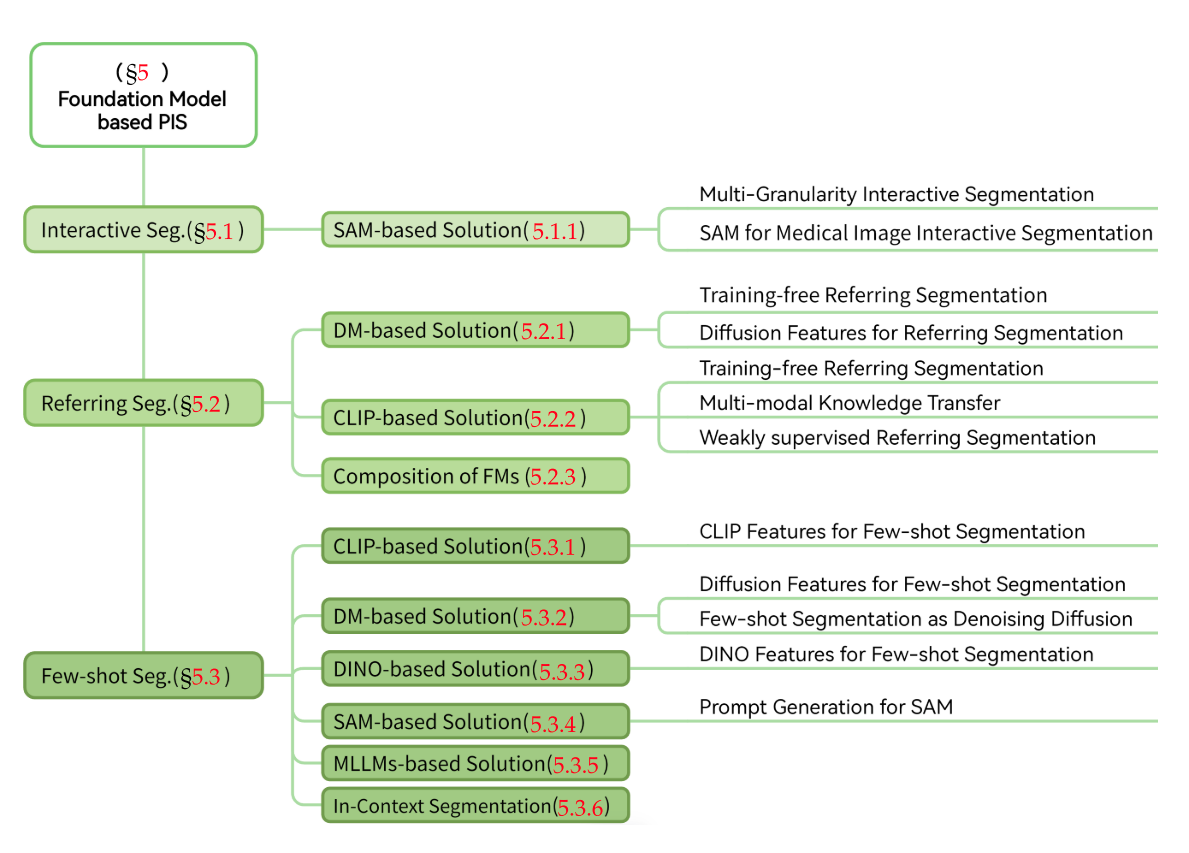
- 交互式分割:SAM 引入多粒度交互式分割流程,每次用户交互时,期望的分割区域可能涉及附近不同部分的对象概念。通过将查询分割区域与 CLIP 的相应文本表示对齐来微调 SAM 。
- Referring Segmentation:
基于 CLIP
- Training-free : 文献 :Zero-shot referring image seg- mentation with global-local context features 和 Text augmented spatial aware zero-shot referring image segmentation 基于跨模态相似度识别目标掩码
- 多模态知识迁移:常见方法是将 CLIP 特征与文本特征融合,训练文本到像素的对比学习,在每个阶段整合桥接模块。
- 弱监督:TSEG 用 CLIP 计算文本目标相似度,通过多补丁分配机制指导分类目标。
基于 DMs - Training-free :前景掩码优化问题。
- 扩散特征:模型反转注意力图可直观得到初始视觉密集表示,用于生成最终分割掩码。
基于 LLMs:实现推理分割。
BERT因其简单性和实用性成为首选。多数方法设计融合模块,连接视觉编码器和解码器与 BERT。
使用大型语言模型作为多模态统一处理工具,将图像和文本融合为统一特征空间,生成强大对话能力。
增强视觉基础的方法广泛用于丰富分割先验知识,提供提示驱动框架连接 CLIP 和 SAM,构建提示机制,在编码器 - 解码器架构中结合 CLIP 和 SAM,采用简单高效的双编码器设计,分别适配 SAM 和 LLM 提取图像和文本特征,融合多模态特征进行分割预测。
- 小样本分割
- 基于 CLIP 的特征表示,通过函数图像生成原型,计算查询原型距离
- DMs 的内部表示对小样本分割有用,可将支持图像特定时间步的表示作为输入,解码为原始图像并输入掩码解码器。通过去噪扩散过程处理小样本分割,微调 SD 以明确生成掩码。
- 利用 DINO/DINOv2 丰富的潜在表示来增强查询和支持图像的特征
- 基于支持查询图像对的相似性生成候选点,突出查询图像的语义,用于指导目标导向提示。
- 一些基于 LLM/MLLM 的通过指令设计解决 FSS 问题。
上下文分割(ICS),即仅用少量示例预测分割掩码,无需特定微调。
6. OPEN ISSUE AND FUTURE DIRECTION
- 解释: 不同 FMs 在架构、数据和训练方式上有差异,但当前方法无法充分解释模型如何学习,尤其是像素与其他模态交互,需新方法理解像素在 FMs 中的作用,这对减少负面影响、拓展应用很关键。
- In-Context Segmentation. 上下文学习。
- 缓解基于 MLLMs 模型的物体幻觉问题:幻觉问题(模型生成不存在或错误物体描述)
- 强大且可扩展的数据引擎
- 扩散模型作为新数据源
- 高效图像分割模型:基于 FM 的分割模型计算量大、需精细调整,影响实际应用。
@article{zhou2024SegFMSurveytitle={Image Segmentation in Foundation Model Era: A Survey},author={Zhou, Tianfei and Xia, Wang and Zhang, Fei and Chang, Boyu and Wang, Wenguan and Yuan, Ye and Konukoglu, Ender and Cremers, Daniel},journal={arXiv preprint arXiv:2408.12957},year={2024},
}