实战:用 Spring Boot 快速构建一个 Kafka 消息系统
在微服务架构中,消息中间件几乎是标配。而 Kafka,以其高吞吐、可扩展、可靠的特性,成为了很多项目的不二之选。
今天,我们来一场实战演练 ——
用 Spring Boot 快速搭建一个 Kafka 消息系统,从零到一掌握核心流程!
1. 环境准备
首先确保你的开发环境安装了:
-
JDK 17 或以上
-
Maven 3.8+
-
本地或远程的 Kafka 集群(推荐配合 Zookeeper 部署)
-
IDEA 或其他 IDE 工具
如果本地没有 Kafka,可以用 Docker 快速启动:
docker run -d --name kafka \-p 9092:9092 -e KAFKA_ZOOKEEPER_CONNECT=zk_host:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \wurstmeister/kafka2. 新建 Spring Boot 项目
创建一个普通的 Spring Boot 项目,添加必要依赖。
在 pom.xml 中引入 Kafka Starter:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>这样,Spring Boot 会帮你自动配置 Kafka 的核心组件。
3. 配置 Kafka 连接参数
在 application.yml 中添加 Kafka 配置:
spring:kafka:bootstrap-servers: localhost:9092consumer:group-id: test-groupauto-offset-reset: earliestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerproducer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer解释一下关键配置:
-
bootstrap-servers:Kafka 集群地址
-
group-id:消费者所属组
-
auto-offset-reset:无 offset 时从最早消息开始消费
-
序列化 & 反序列化:默认使用字符串格式
4. 编写生产者(Producer)
生产者发送消息到 Kafka Topic:
@Service
public class KafkaProducerService {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String topic, String message) {kafkaTemplate.send(topic, message);}
}KafkaTemplate 是 Spring Boot 提供的封装,简单易用。
发送是异步的,可以配置回调监听发送结果。
5. 编写消费者(Consumer)
消费者监听消息并处理:
@Service
public class KafkaProducerService {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String topic, String message) {kafkaTemplate.send(topic, message);}
}-
@KafkaListener 注解实现自动监听,无需手动轮询。
-
支持批量消费、消息过滤、异常处理等高级特性。
6. 测试系统
可以在 Controller 中快速验证:
@RestController
@RequestMapping("/kafka")
public class KafkaController {@Autowiredprivate KafkaProducerService producerService;@PostMapping("/send")public String send(@RequestParam String message) {producerService.sendMessage("test-topic", message);return "Message sent!";}
}启动项目后,访问接口发送一条消息,查看消费者是否成功收到。
示例:
curl -X POST "http://localhost:8080/kafka/send?message=HelloKafka"控制台输出:
Received message: HelloKafka系统通了!🚀
7. Spring Boot 集成 Kafka 的优势
-
自动装配,减少繁琐配置
-
简化生产者和消费者开发
-
内建连接池与容错机制
-
与 Spring Cloud Stream 等生态无缝衔接
8. 后续进阶方向(扩展版)
初步搭建好系统之后,如果你想真正用 Kafka 支撑起生产级别的业务,还需要掌握更深入的能力。下面列出几个重要的进阶方向:
8.1 消费者手动提交 Offset
默认情况下,Spring Kafka 会自动提交 offset,意味着一旦消息被拉取就认为已经消费成功。
但在实际生产中,为了避免消息丢失或者误处理,手动提交 offset 是更安全的做法。
可以通过配置关闭自动提交:
spring.kafka.consumer.enable-auto-commit: false然后在业务代码中显式调用 Acknowledgment:
@KafkaListener(topics = "test-topic")
public void listen(String message, Acknowledgment ack) {// 处理逻辑ack.acknowledge(); // 手动提交
}这种方式能精准控制 offset 的提交时机,比如确保消息真正处理成功之后再提交,极大提升了系统的可靠性。
8.2 批量发送与批量消费
批量处理是提升 Kafka 系统性能的利器:
-
生产者端可以将多条消息一起发送,减少网络开销
-
消费者端可以一次性拉取并处理一批消息,提升处理效率
Spring Kafka 支持消费者批量消费,只需要简单配置:
spring.kafka.listener.type: batch然后监听方法参数改为 List 类型:
@KafkaListener(topics = "test-topic")
public void listen(List<String> messages) {messages.forEach(System.out::println);
}批量消费不仅提升性能,还能结合事务性处理,做到批处理+原子提交。
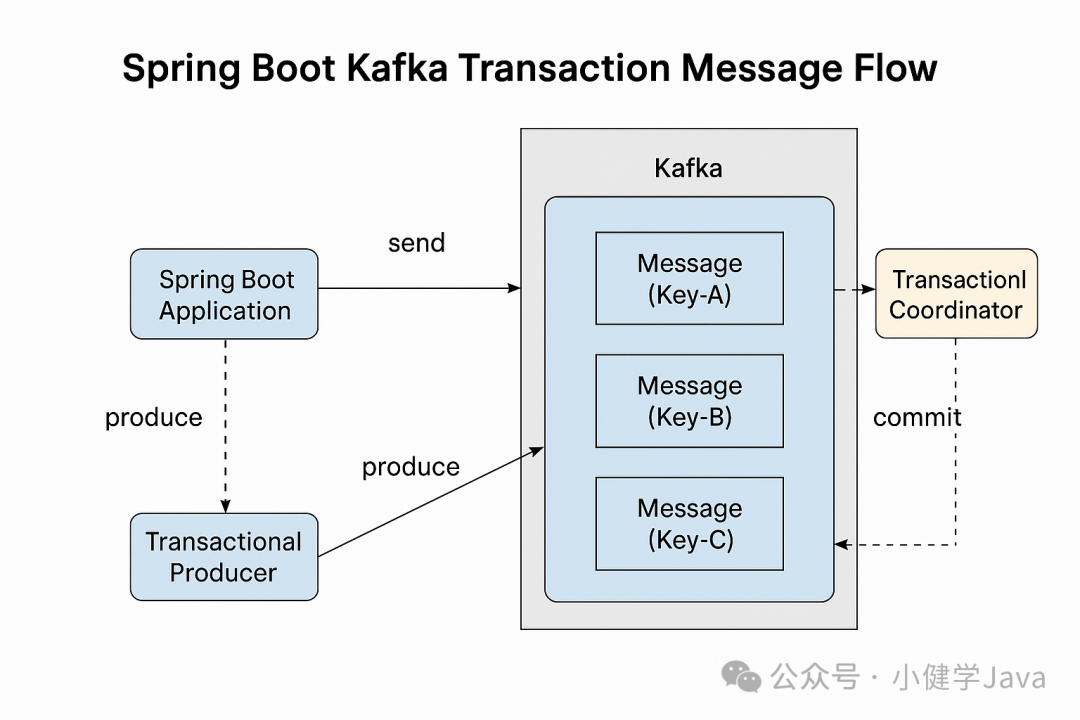
8.3 Kafka 事务消息机制
在某些业务场景中,需要保证消息的发送与数据库操作的一致性。
Kafka 支持基于 事务 的可靠消息发送(Exactly Once Semantics,EOS)。
启用事务需要在生产者端配置:
spring.kafka.producer.transaction-id-prefix: tx-然后在业务中开启事务控制:
@Transactional
public void sendTransactionalMessage(String topic, String message) {kafkaTemplate.executeInTransaction(kafkaTemplate -> {kafkaTemplate.send(topic, message);// 也可以配合数据库事务操作return true;});
}这样可以做到生产者发送的多条消息要么全部成功,要么全部失败回滚,非常适合金融、电商等场景。
8.4 多分区与消息顺序控制
Kafka 天然是分区(Partition)架构,不同分区之间消息是无序的,但在同一个分区内部,Kafka 能严格保证顺序。
如果你的业务需要顺序消费,比如:
-
订单创建 -> 付款 -> 发货
-
用户行为日志按时间排序
就必须确保同一组相关消息发送到同一个分区。
在发送消息时,可以指定 key:
kafkaTemplate.send("order-topic", "orderId-123", "下单消息");Kafka 会根据 key 的 hash 值选择分区,同样 key 的消息一定落到同一个分区,从而保证顺序。
8.5 与 Schema Registry + Avro 格式结合实践
随着系统复杂度增加,消息格式演变与兼容性管理成为新挑战。
传统的 String 序列化方式难以支撑复杂结构。推荐使用:
Apache Avro 作为序列化格式
Confluent Schema Registry 来统一管理消息结构
Spring Kafka 也支持 Avro 集成,只需添加依赖,并在配置中指定使用 Avro 序列化器、反序列化器。
优点:
-
节省消息体大小(Avro 是二进制格式)
-
版本管理、兼容性检查
-
保证生产者与消费者之间协议一致
这一步虽然复杂,但极大提升了系统的长期可维护性和演进能力。
9. 小结
从最基础的生产消费,到批量优化、事务保障,再到顺序控制与协议升级,
Kafka + Spring Boot 的应用,可以从轻量级快速搭建,一路进阶到支撑复杂系统的骨干中间件。
掌握了这些进阶技能,才能真正把 Kafka 用得又稳又强大!