零基础实现把知识库接到聆思CSK6大模型开发板上
前言
大模型作为一个语言模型,实际上没有真正的记忆功能。所谓的对话记忆只是开发者将对话历史向GPT发送消息时将最近的对话历史通过提示工程组发送给ChatGPT。换句话说,如果对话历史超过了大模型的最大上下文,GPT会忘记之前的部分,这是大语言模型共有的局限性。
另外对专业领域知识的训练缺乏也是非常明显的短板。尽管这些模型在理解和生成自然语言方面有极高的性能,但它们在处理专业领域的问答时,却往往不能给出明确或者准确的回答。在医学、法律、工程等领域,人工智能可能被要求要理解和运用相当复杂和专业化的知识,然而这在目前的模型中仍是一个巨大的挑战。
针对专有和专业知识在大模型的应用落地出现不少解决方案,而向量数据库就是其中之一。当我们很多文档(例如客服培训资料或者产品操作手册)需要大模型根据它们的内容进行回答时,我们可以先将这份文档的所有内容转化成向量(这个过程称之为 Vector Embedding),然后当用户提出相关问题时,我们将用户的搜索内容转换成向量,然后在数据库中搜索最相似的向量,匹配最相似的几个上下文,最后将上下文返回给大模型。这样不仅可以大大减少模型的计算量,从而提高响应速度,更重要的是降低成本,并巧妙的减少 tokens 限制所带来的问题。
针对这种需求,聆思CSK6大模型开发板也配套提供了一个知识库方案,参考下面文档三步就能在智能硬件上接入自建的知识库
一、创建私有知识库
新建
在聆思大模型平台点击侧边栏的“知识库”模块,进入知识库页面,点击创建知识库即可进行知识创建流程;
在弹出的窗口输入知识库名称点击确定即可完成知识库创建。
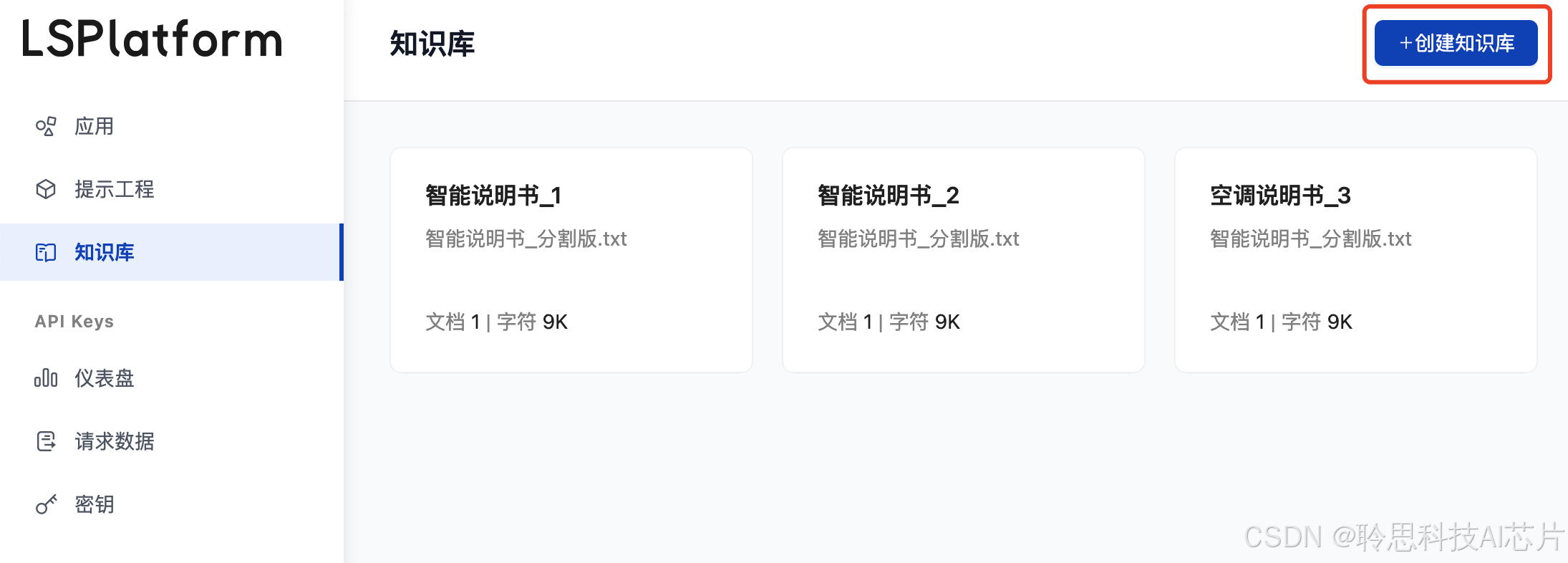
上传文档
点击对应的知识库应用,点击右侧的“上传文件”按钮,即可进入文档上传流程;
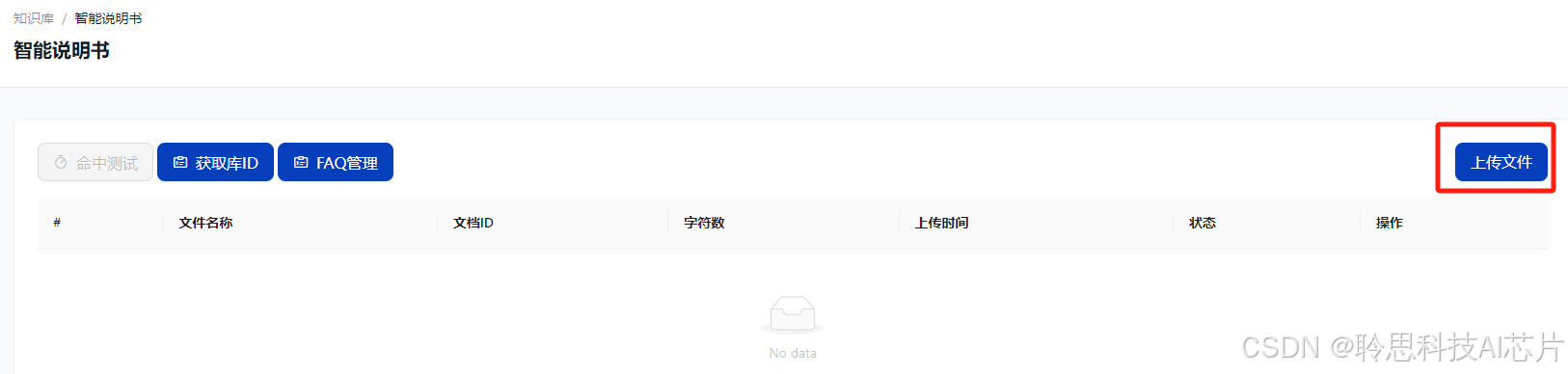
文档支持txt、doc、pdf格式,请将要建立索引的文档转换至上述格式再进行上传。
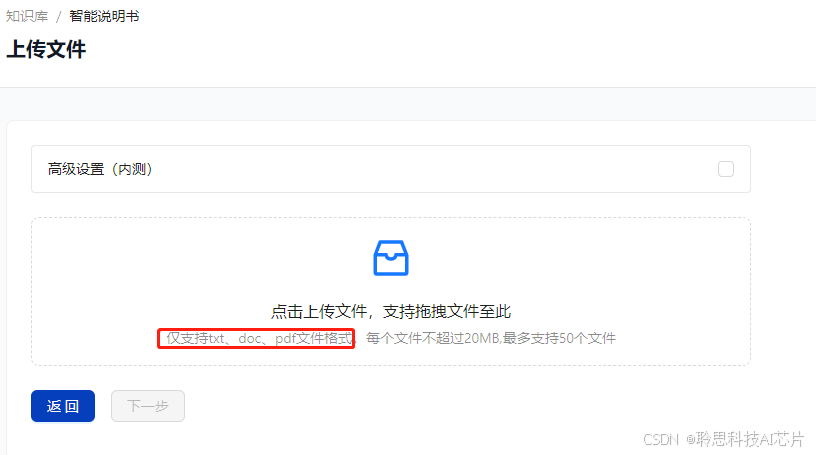
设置分片策略
平台提供两种分片策略,首次可以先选择智能分片方式快速了解流程。
智能分片
系统自动拆分片段,无需关注数据库底层的分片细节,适合应用在一些篇幅较长并且没有固定格式的泛文本内容。同时为了提高检索效果和效率,每个片段会控制在250token以内。
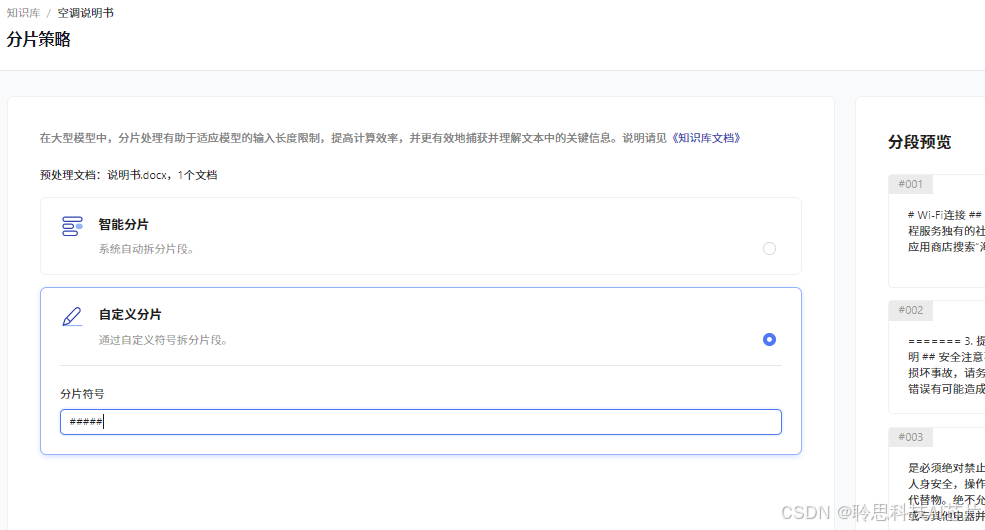
自定义分片
支持自定义分片符号(同时支持正则表达式)对文档进行分片,你可以填写\n\n,代表将文档中两个连续换行符视为分割符号进行文档分割。例如下方纯文本内容则会把一个QA对视为一个片段进行分割。
二、在大模型语音交互应用中关联私有知识库
创建私有应用
1、点击应用模板中心中大模型套件的添加应用按钮。
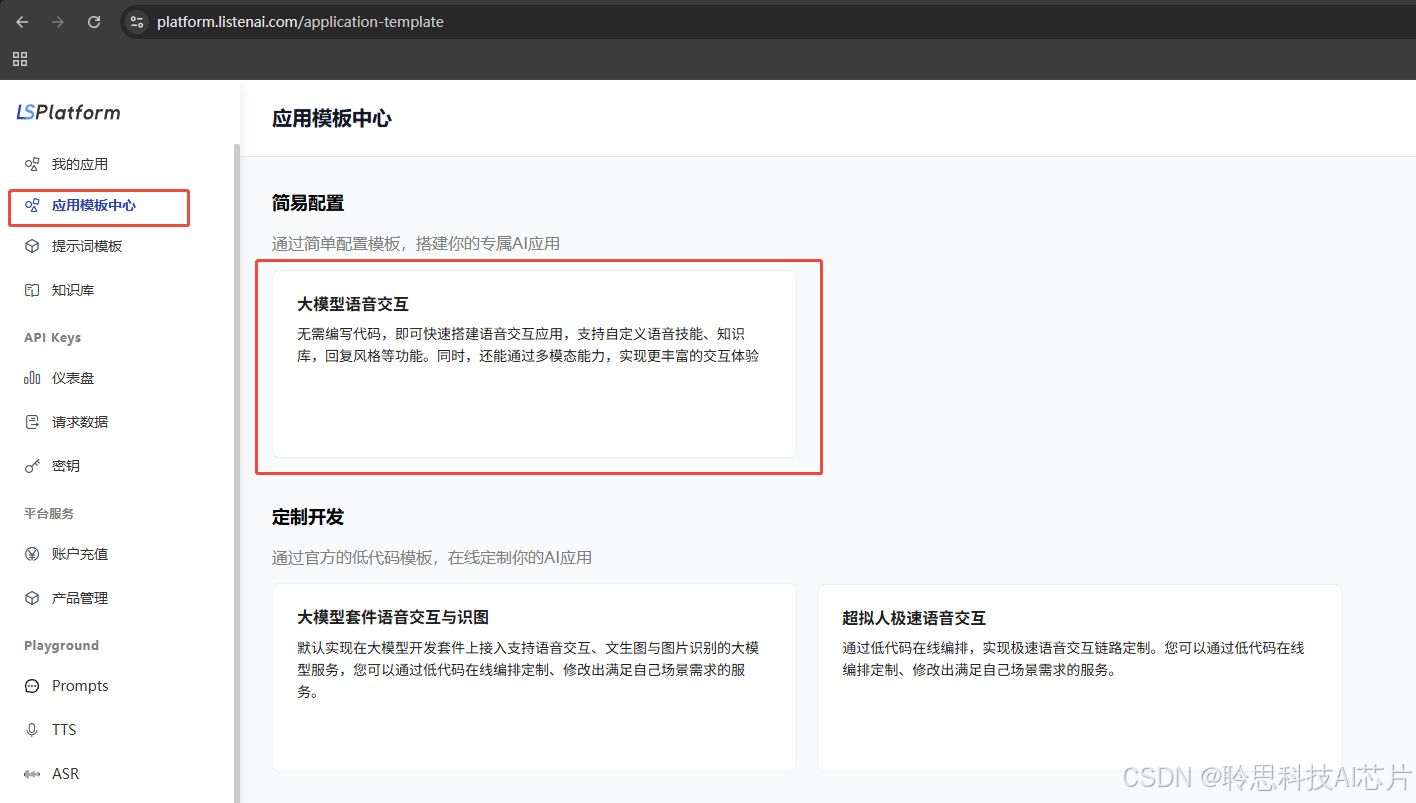
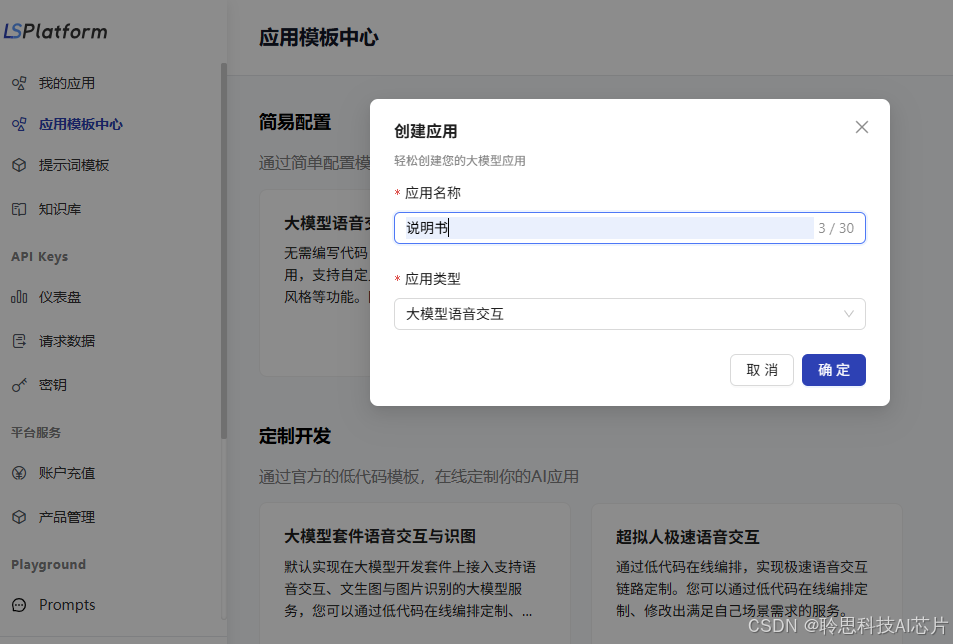
2、在弹出的对话框中给应用命名后点击【确定】。
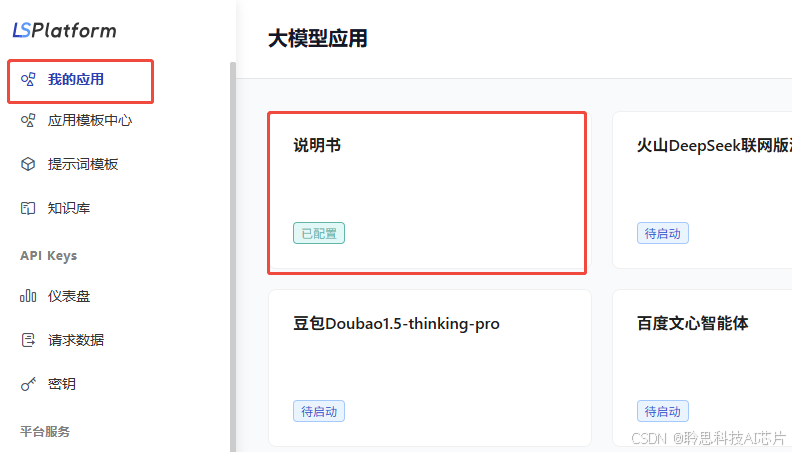
3、进入【我的应用】,可以看到刚才创建的【说明书】应用入口
在语音交互处理流程中引入知识库
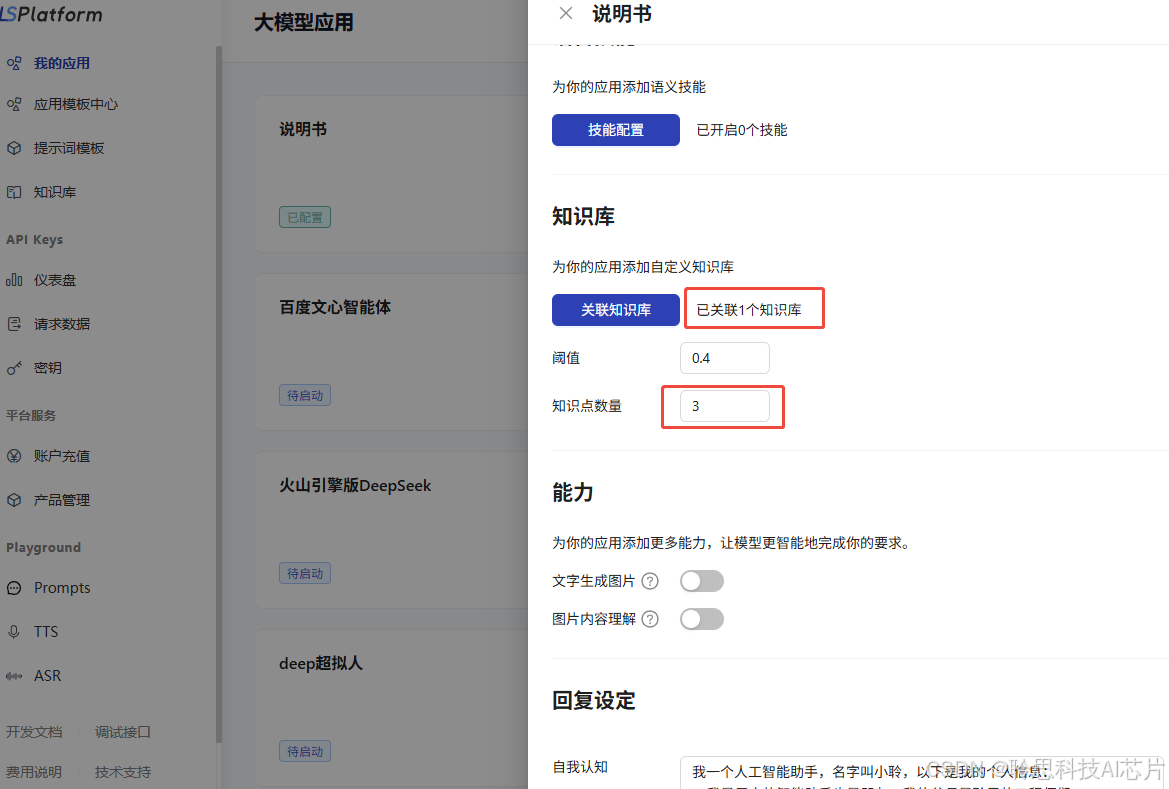
双击点开【说明书】,点击【关联知识库】。

在弹出的界面中打开自建的知识库后点击【确定】
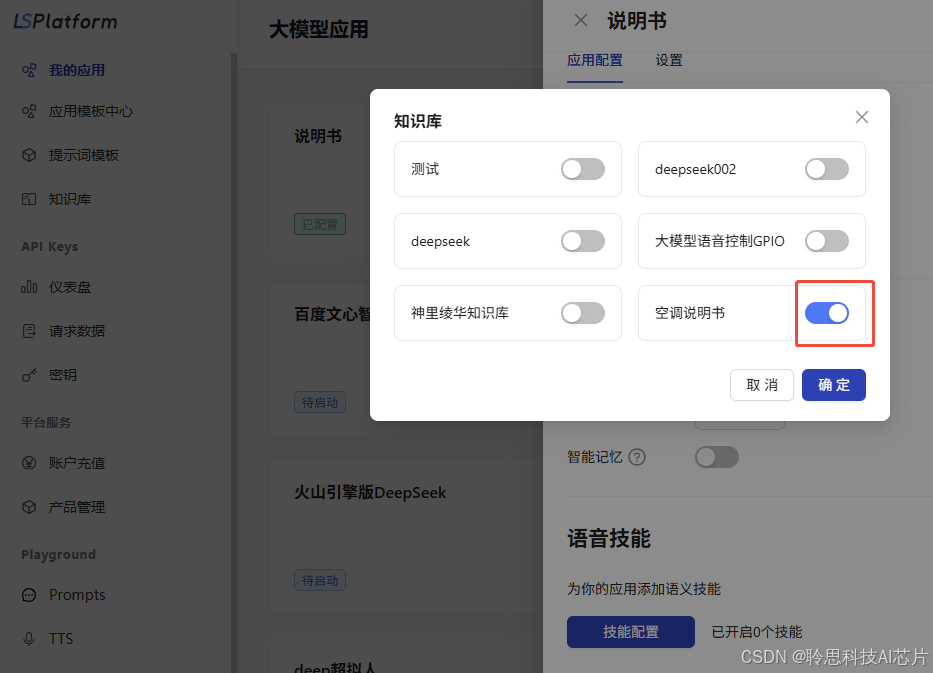
关联成功后会显示关联的知识库个数。在下方也可以自己配置每次问答需要搜索结合几条知识点来生成回答,默认是3条。
三、开发板接入知识库流程
完成云端配置后,仅需将产品ID与密钥写入设备,才能让设备连接对应的产品并完成鉴权服务。
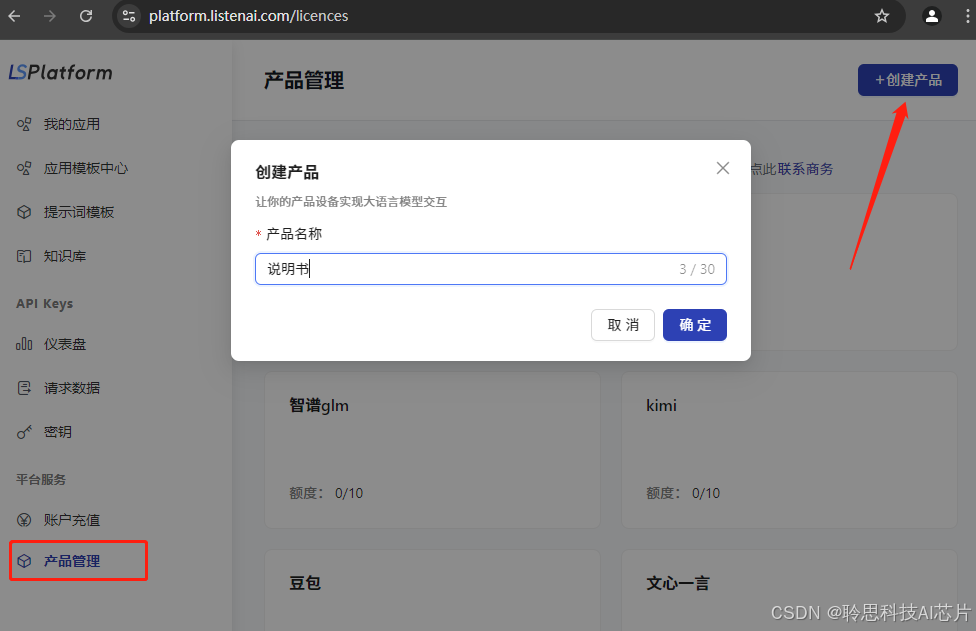
配置产品管理信息
1、打开产品管理,点击右上方的【创建产品】
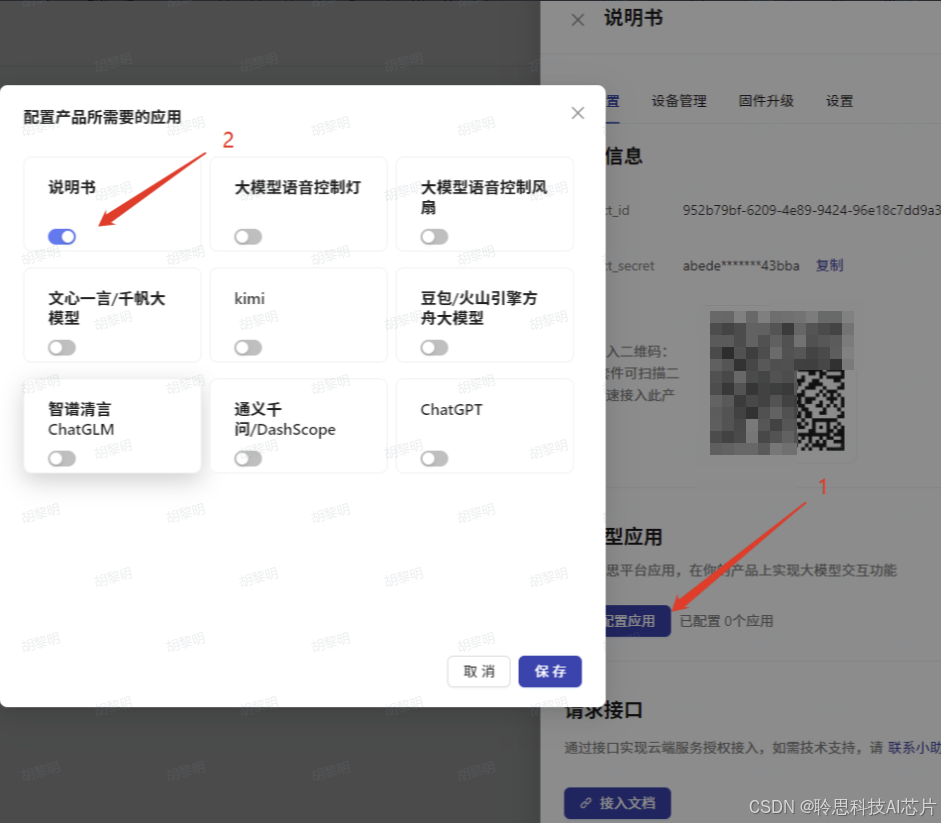
在弹出的页面中点击【配置应用】,选择前面配置的【说明书】应用,然后保存。
开发板关联新流程
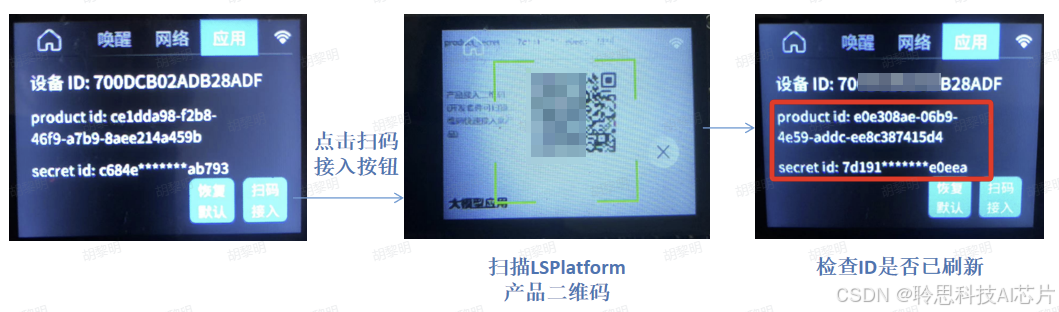
在开发板应用首页下滑调出菜单,以此点击设置图标 →应用,进入应用信息查看页:

点击右下角扫码接入按钮调出相机,将 LSPlatform 待接入的产品二维码置于屏幕绿色扫描框内,完成扫`描后,请在应用配置信息处检查product_id和secret_id是否已更新:
至此完成知识库接入到硬件的操作流程,此时语音交互会先从知识库中取结果,知识库没有的话就会由大模型来处理生成回复。

本文使用的聆思CSK6大模型开发板开箱联网就可以使用大模型语音交互,按照以上步骤就可以零基础接入自建知识库,详细功能参考:套件简介 | 聆思文档中心
博客持续更新实操和示例讲解,欢迎关注,也可以在评论区提问交流。
排错指引:
语音交互链路较长,包含云服务配置、网络传输、开发板端鉴权等,如果遇到问题可以参考以下流程按顺序检查处理。
一、排错流程顺序参考
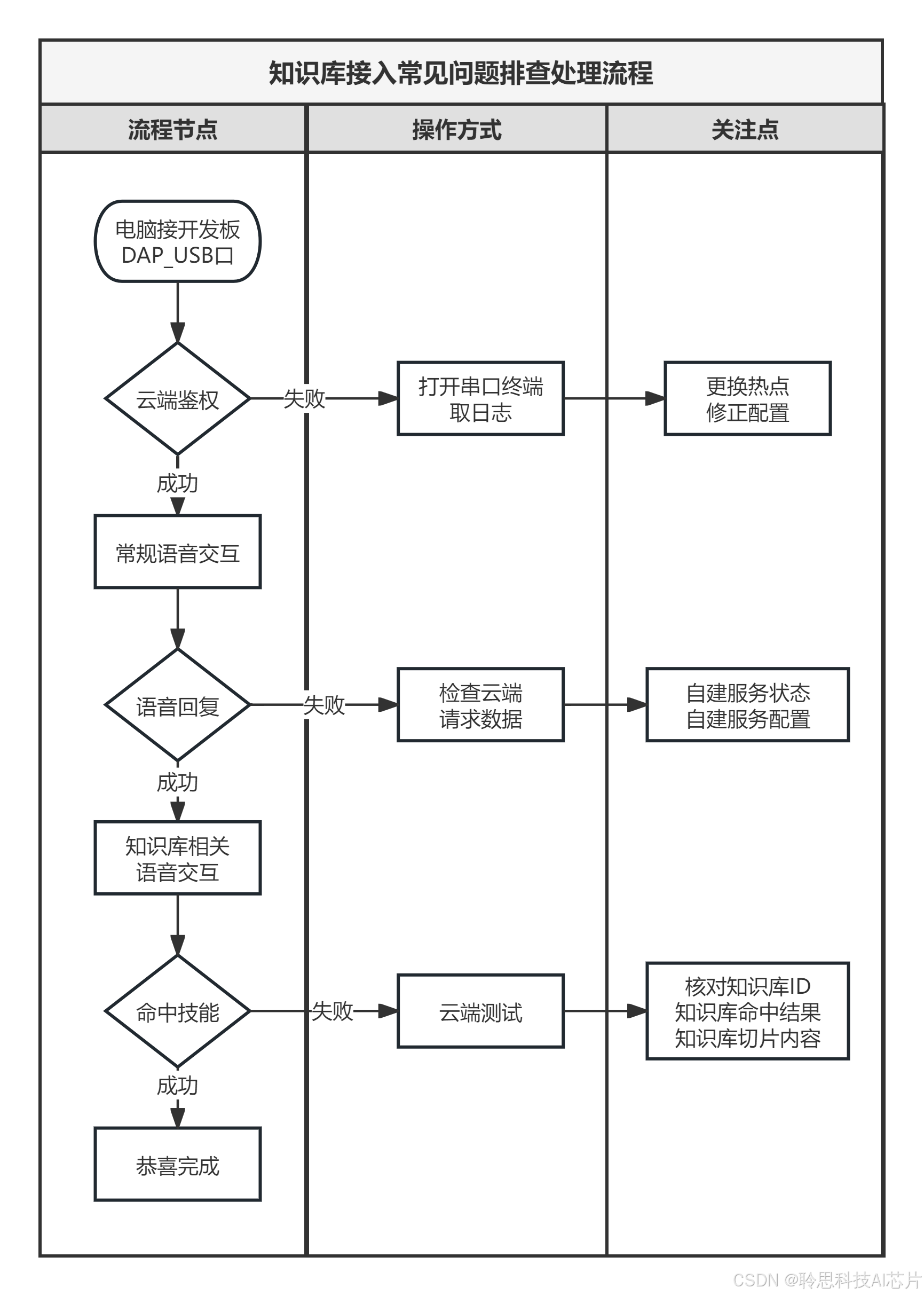
二、云端鉴权问题处理
原因1:聆思平台(platform)云端产品管理页没有添加开发板的设备ID
处理方法:按序号顺序操作,添加开发板设备ID
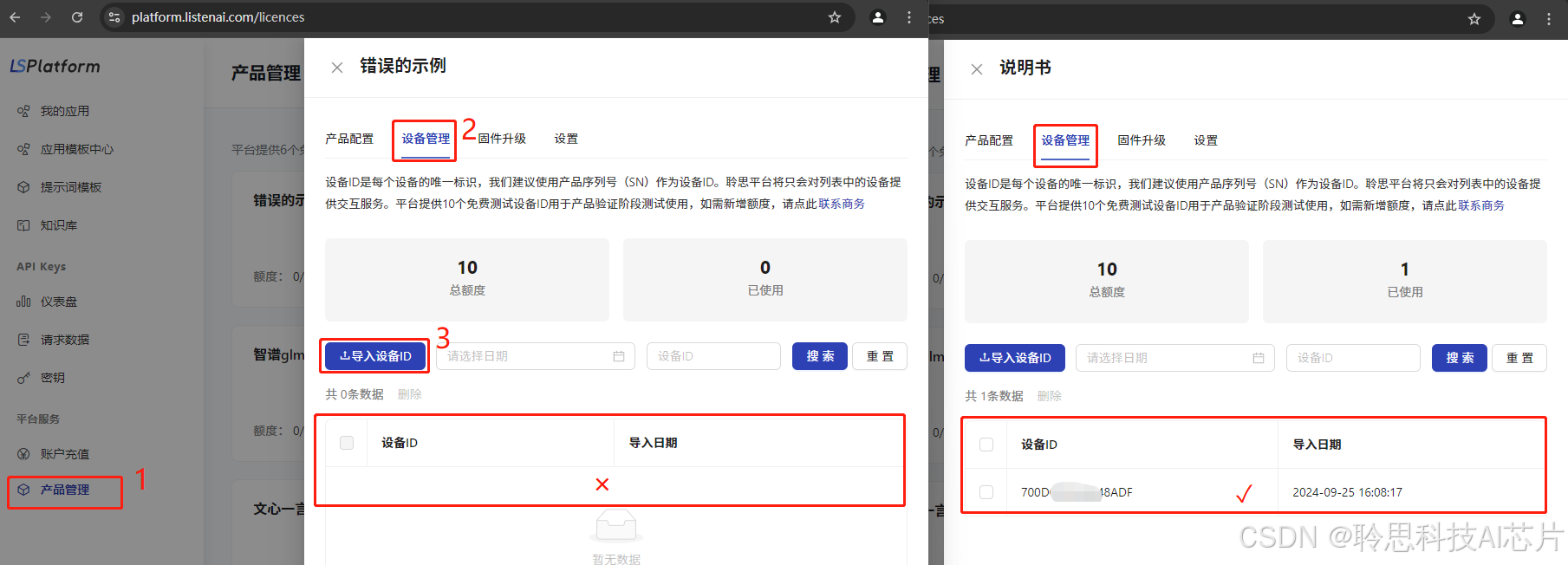
查看设备ID:
在开发板应用首页下滑调出菜单,以此点击设置图标 →应用,进入应用信息查看页:
原因2、更换过联网环境,DNS解析失败
如果不是以上两个原因,可以查下串口日志,如果出现以下信息则是网络问题

处理方法:重启设备,重新尝试。若多次尝试失败,建议更换网络。
三、提问无回复语音的处理
原因1:开发板关联了无效的product id和应用
如果开发板上的product id错误,使用开发板重新扫描上图位置中的二维码即可修正;
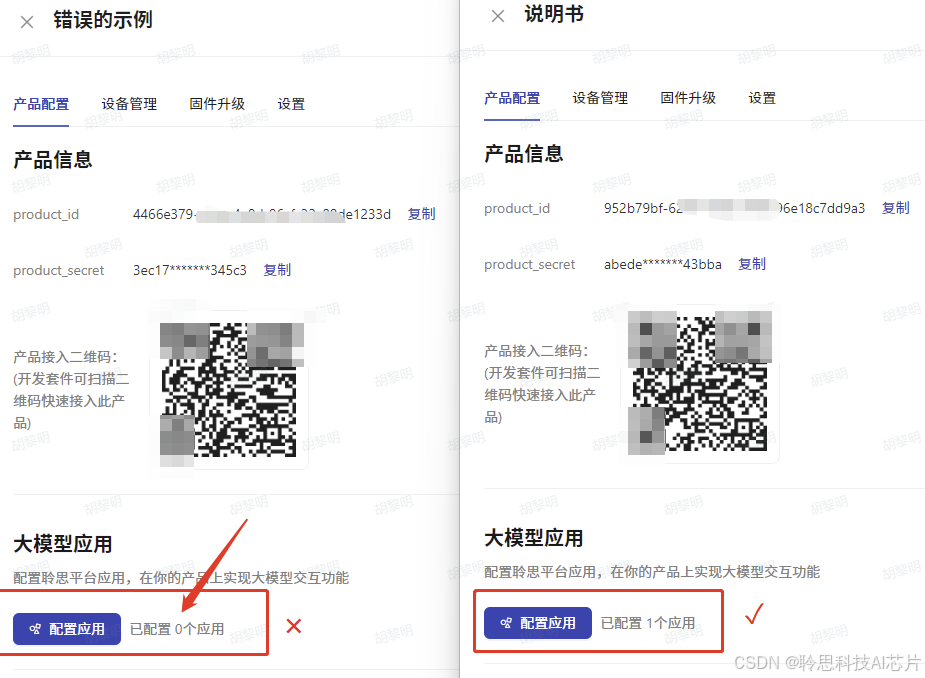
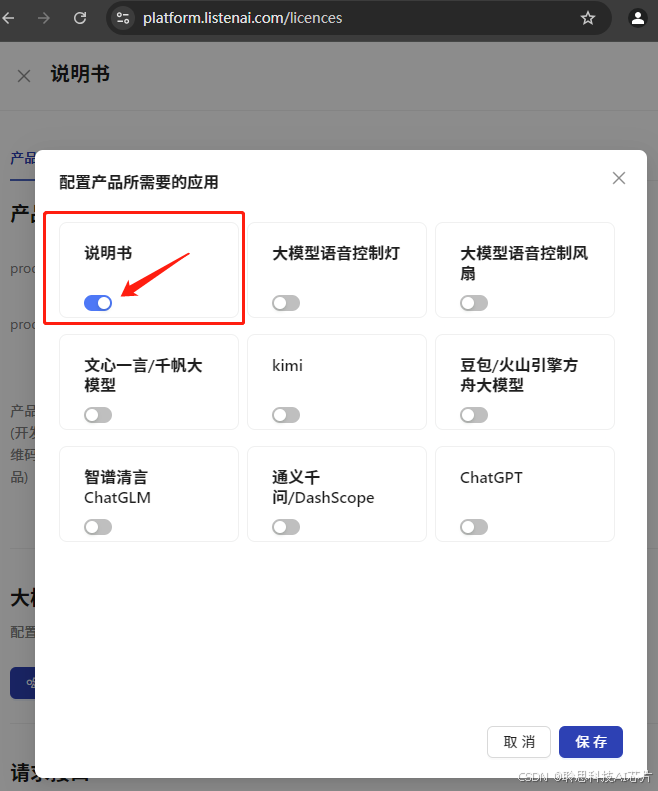
如果是配置应用显示为0,如下图所示,选择对应服务保存即可。
原因2:自建服务没有启动
测试环境和正式环境需要有一个是正常运行状态,如果是服务运行异常,可以启动对应服务来解决
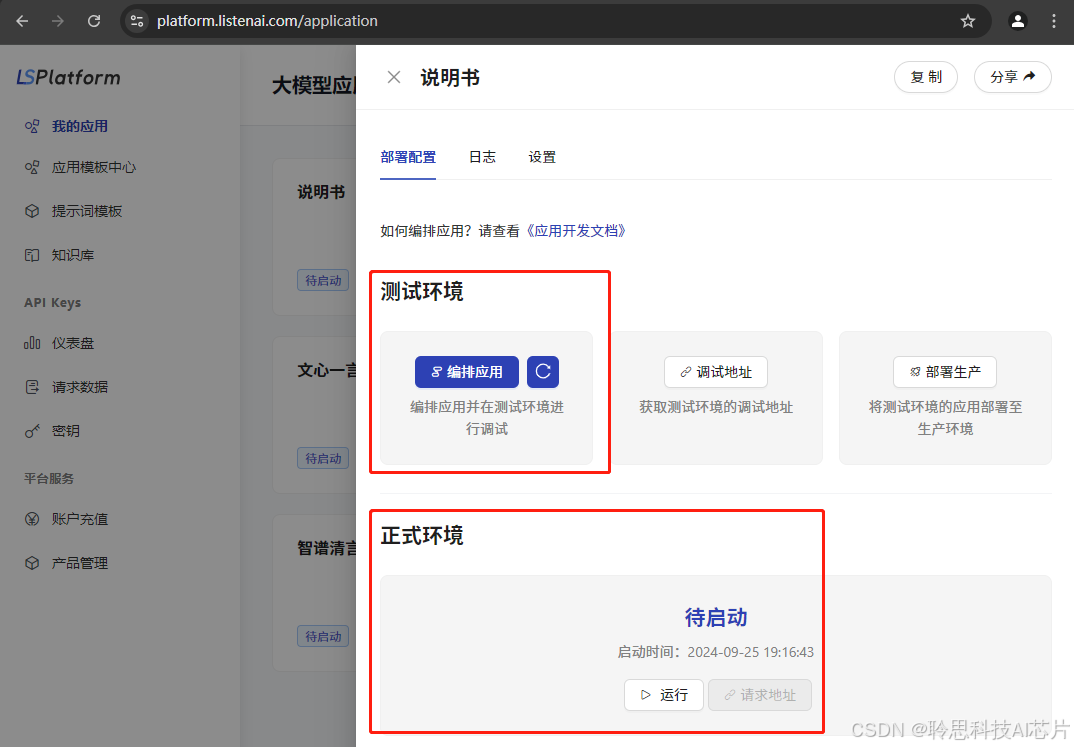
四、回复未调用知识库的处理
如果知识库相关的问题回复内容跟接入的知识库无关,此时可以判定为知识库调用失败。
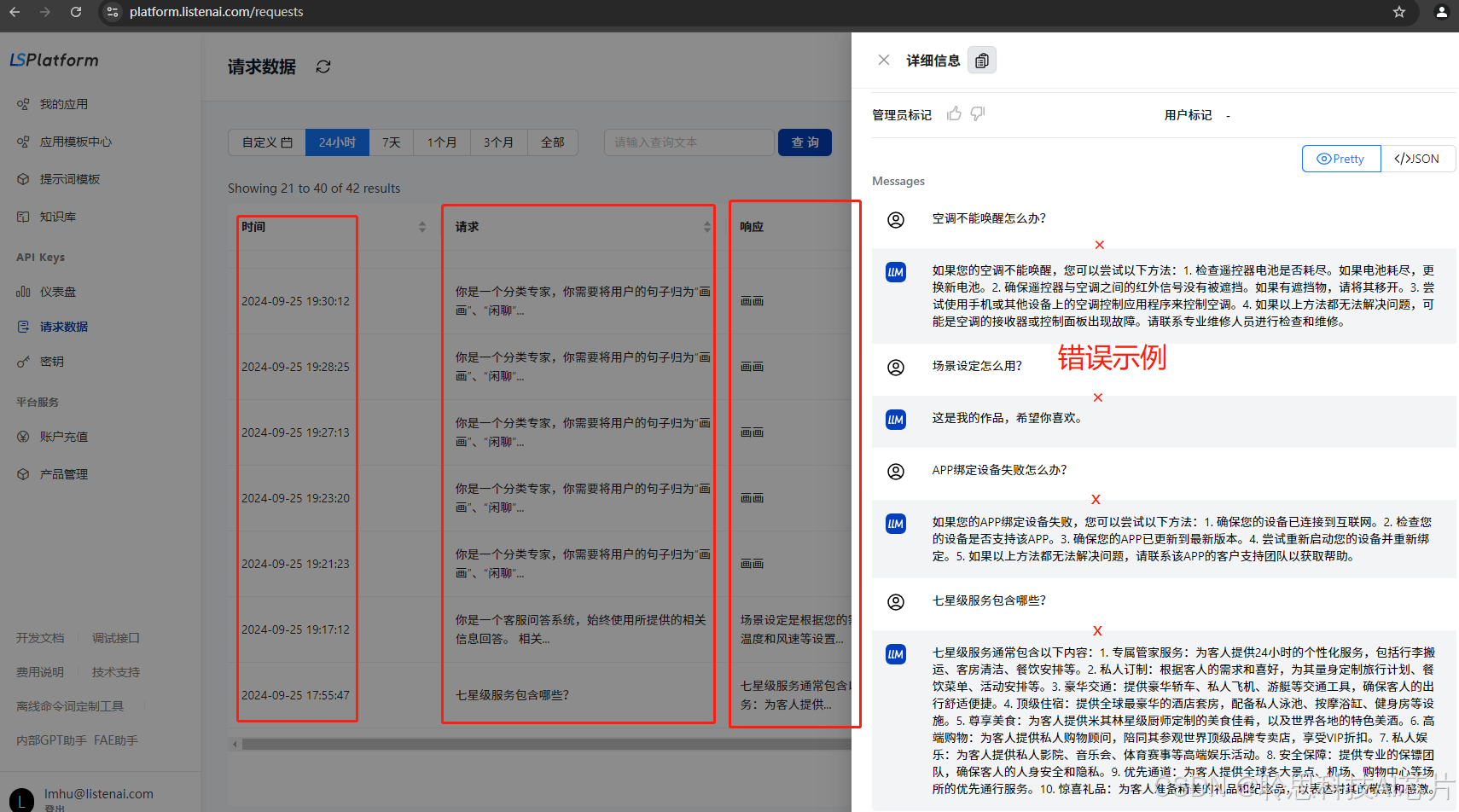
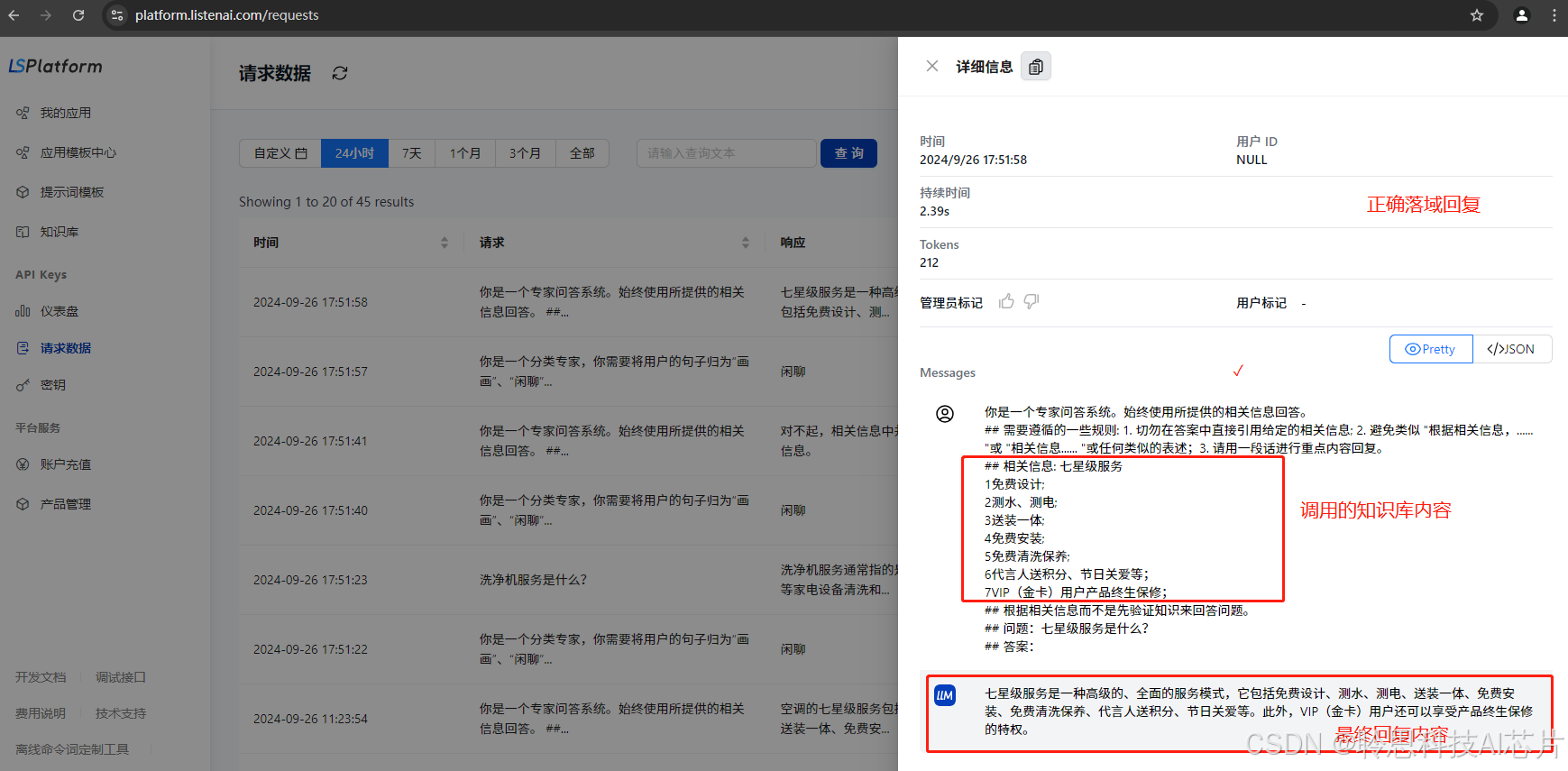
1、首先,在聆思平台(LSPlatform)后台查看语音请求是否正确理解,并落域到正确的节点处理
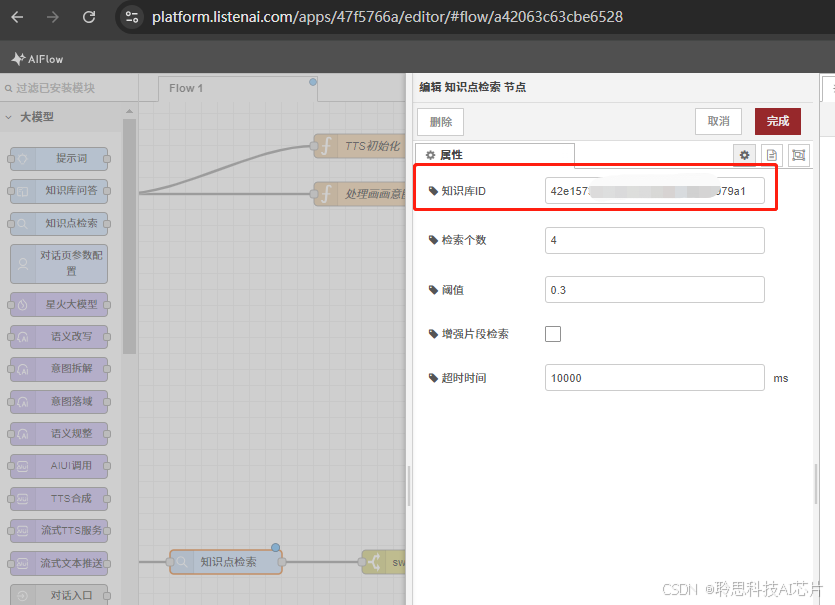
2、其次,检查大模型流程的【知识库】或【知识点检索】节点关联的[知识库ID]信息是否正确。
3、然后,使用【知识库体验】测试知识库回复内容是否符合预期
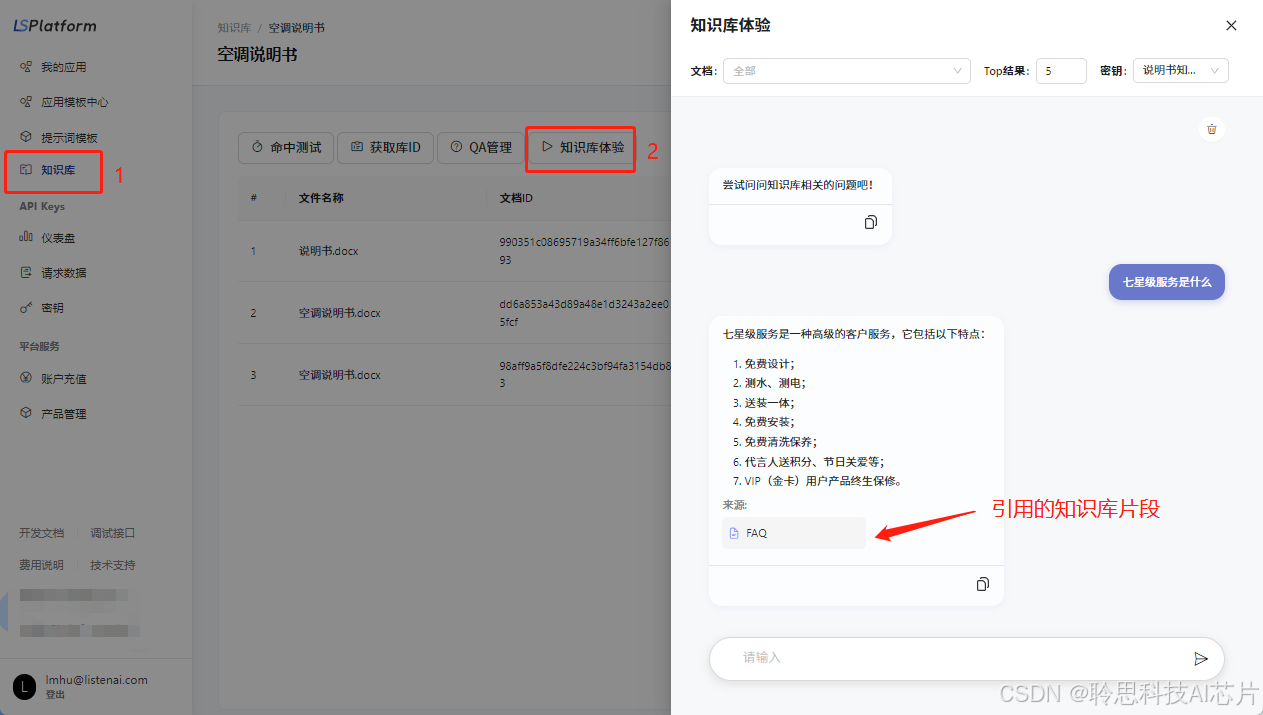
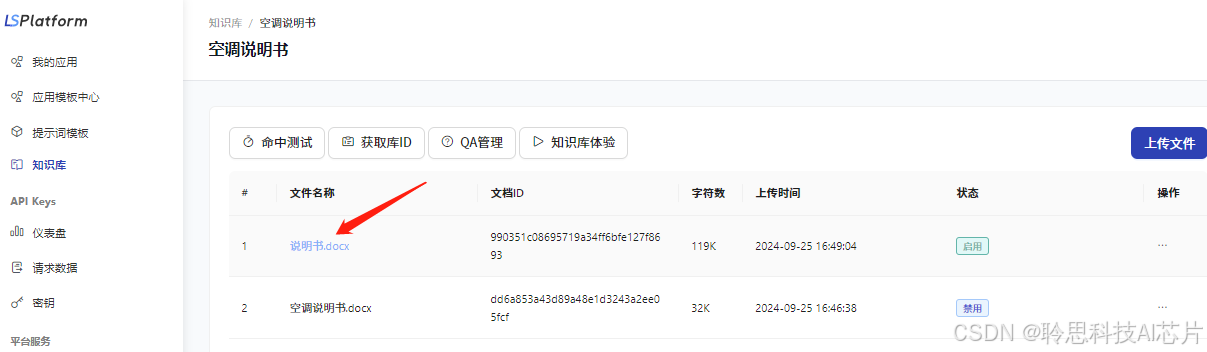
4、如果回复不符合预期,可以点击调用的知识库进入切片内容界面,通过关键词搜索快速定位切片信息,检查切片内容是否正确。
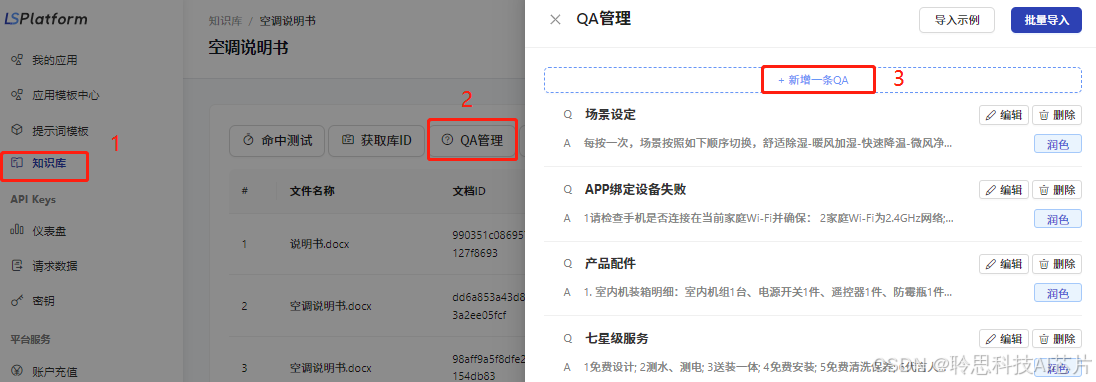
5、如果要补充问答信息,可以使用【QA管理功能】进行补充
五、知识库文档格式要求
如果使用智能分片处理文档生成的内容不符合预期,采用自定义分片的方式。
文档导入知识库前需要对文档内容和格式进行处理,可以参考官方文档进行:知识库文档最佳规范指南 | 聆思文档中心
本文使用的聆思CSK6大模型开发板开箱联网就可以使用大模型语音交互,按照以上步骤就可以接入自建知识库,详细功能参考:套件简介 | 聆思文档中心