基于论文的大模型应用:基于SmartETL的arXiv论文数据接入与预处理(四)
上一篇介绍了基于SmartETL框架实现arxiv采集处理的基本流程,通过少量的组件定制开发,配合yaml流程配置,实现了复杂的arxiv采集处理。
由于其业务流程复杂,在实际应用中还存在一些不足需要优化。
5. 基于Kafka的任务解耦设计
5.1.存在问题
由于arXiv论文数量庞大、解析处理流程复杂,实际应用中可能会遇到不少问题。主要包括:
- 持续采集问题。数据集需要定期下载更新,每篇新论文需要进行完整处理。
- 采集处理性能问题。数据量大,以及下载、解析、向量化、入库等过程都会比较耗时,需要尽可能提升处理性能。
- 异常中断问题。过程中出现问题,如程序BUG,可能导致全部数据都要重新处理,应该尽量避免影响已处理的部分。
应对这些问题的一个比较好的办法就是引入消息中间件技术,基于生产者-消费者模式,将不同处理环节进行解耦,既可以避免相互影响,而且可以针对不同处理环节的计算复杂度进行独立设计以提高整体吞吐。
5.2.Kafka队列设计
引入kafka消息中间件,设计多个消息队列,将不同环节作为独立的生产者/消费者,实现流程解耦。如下图所示:
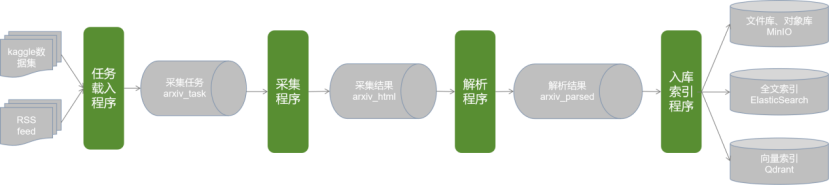
设计消息队列包括:
- 采集任务队列(
arxiv_task):arxiv采集处理任务队列,即kaggle数据集排序后的论文元数据。 - 采集结果队列(
arxiv_html):待处理的html解析任务。 - 解析结果队列(
arxiv_parsed):解析后待入库的论文信息。
5.3.子流程设计
流程解耦后的每个环节作为一个子流程,与Kafka进行读取或写入。具体包括包括:
- 任务载入子流程:将下载或订阅的最新论文元数据写入
arxiv_task队列。 - 采集子流程:基于提供的arxiv论文元数据,进行HTML(或/和PDF文件)采集。HTML/PDF保存在本地或MinIO系统。完成后,在
arxiv_html队列中插入一条数据,可以是输入的论文元数据,也可以附加html文件路径信息。 - 解析子流程:对提供的html文件信息进行解析,解析结果写入
arxiv_parsed队列中。 - 入库索引子流程:对解析结果写入ES或Qdrant数据库中。(可能还需要考虑到与已有数据的融合或消歧,本文暂不考虑)
上述每个子流程都运行为一个SmartETL实例。根据速度要求,对部分子流程可以启动多个SmartETL实例。
6.新流程设计
如前所述,基于kafka解耦的流程将分成4个子流程,通过kafka消息队列数据进行驱动。
6.1.任务载入子流程
此子流程较为简单,读取kaggle数据集文件(JSON格式),写入Kafka即可。按需运行。
name: json数据写入kafka
consts:kafka_config:kafka_ip: 10.60.1.148:9092kafka_topic: arxiv_taskloader: JsonLine('data/sorted_arxiv.json')
nodes:writer: database.kafka.KafkaWriter(**kafka_config, buffer_size=50)processor: writer
6.2.采集子流程
基于前文流程进行简单改造即可。
name: arxiv论文下载consts:consumer:kafka_ip: 10.60.1.148:9092kafka_topic: arxiv_taskgroup_id: arxiv_crawlerproducer:kafka_ip: 10.60.1.148:9092kafka_topic: arxiv_htmlloader: database.kafka_v2.KafkaConsumer(**consumer)
nodes:#拼接html下载urlmk_url: Map('gestata.arxiv.url4html', key='id', target_key='url_html')#下载html内容download: Map('util.http.content', key='url_html', target_key='content', most_times=3, ignore_error=True)#保存html文件save: WriteFiles('data/arxiv_html', name_key='id', suffix='.html')#元数据集写入kafkawrite: database.kafka.KafkaWriter(**producer, buffer_size=1)processor: Chain(Print("id"), mk_url, download, save, write)
6.3.解析子流程
name: arxiv论文解析consts:consumer:kafka_ip: 10.60.1.148:9092kafka_topic: arxiv_htmlgroup_id: arxiv_htmlproducer:kafka_ip: 10.60.1.148:9092kafka_topic: arxiv_parseloader: database.kafka_v2.KafkaConsumer(**consumer)
nodes:#论文解析parse: Map('gestata.arxiv.extract')#元数据集写入kafkawrite: database.kafka.KafkaWriter(**producer, buffer_size=1)processor: Chain(parse, write)
6.4.入库索引子流程
name: arxiv论文入库ES和Qdrantconsts:bge_large: http://10.208.63.29:8001/embedqd_config:host: '10.60.1.145'es_config:host: '10.208.61.117'port: 9200index: doc_arxivbuffer_size: 3consumer:kafka_ip: 10.60.1.148:9092kafka_topic: arxiv_parsegroup_id: arxiv_parseloader: database.kafka_v2.KafkaConsumer(**consumer)
nodes:# 入库处理write: gestata.arxiv.ArxivProcess(bge_large, qd_config, es_config)processor: write
这里出于效率考虑,将论文正文chunk拆分、向量化、入向量库的工作集中在一个组件中实现。核心代码如下:
abstract = paper.get('abstract')
self.embed_and_write2(index=1, _id=_id, content=abstract, collection='chunk_arxiv_abstract2505')
sections = paper.get('sections')
for index, section in enumerate(sections,start=1):figures = section.get('figures')if figures:self.image_embed_and_write(_id=_id, index=index, figures=figures)title = section['title'].lower()content = section['content']collection = 'chunk_arxiv_discusss2505'if 'introduction' in title:collection = 'chunk_arxiv_introduction2505'elif 'method' in title:collection = 'chunk_arxiv_method2505'elif 'experiment' in title:collection = 'chunk_arxiv_experiment2505'self.embed_and_write2(index=index, _id=_id, content=content, collection=collection)self.ESWriter.index_name = self.es_indexself.ESWriter.write_batch(rows=[paper])
7.总结
本系列文章讨论了arXiv论文数据采集和预处理的相关技术,实现了对arXiv论文内容抽取以及建立向量化索引,通过Kafka消息中间件实现了各处理环节的解耦,更加方便实际业务中使用。整个流程基于SmartETL框架进行开发,同时也对SmartETL框架进行了完善。
相关代码已经全部推送到 SmartETL项目,具体流程定义在 这里,欢迎下载体验