HuggingFace Trainer(回调可视化)
HuggingFace Trainer(回调&可视化)
- 0、教程
- 1、Trainer参数
- 1.官方说明
- 2.参数说明
- 3.评估指标
- 2、TrainingArguments
- 3.1、Callbacks回调
- 1. 官方教程
- 2.✅回调参数(kwargs可获取对象)
- 3.✅解包参数(有两种)
- 4. ✅Trainer log tensorboard某一参数
- 3.2、✅Callbacks 的logs
- 1. `logs` 是什么
- 2. “only accessible in the event `on_log`” 的含义
- 3. 结合页面上下文的调用流程
- 4. 实际应用场景
- 4、logging 日志(可视化)
- 1. 教程
- 2. Trainer log设置
- 5、TensorBoardCallback(用不上)
- 6、✅报错
- 1\. 修改自定义回调类 🚀
- 2\. 修改 Trainer 实例化 🛠️
- 7、完整示例
- 1\. 完整代码
- 2\. 运行说明
- 8.1、✅完整示例(两种实现方式)
- 方法一:kwargs解包
- 方法二:参数中声明
- 8.2、用self._trainer保存模型(不推荐)
- 为什么推荐使用 `control.should_save`?
- 示例代码回顾
- 总结
- 为什么选择直接用 `self._trainer` 保存?
- 使用 `self._trainer` 保存模型的完整示例
- 1\. 修改 `TrainingArguments`
- 2\. 修改自定义回调
- 3\. 完整代码(带有新回调)
- 9、提问
- 10. TensorBoard转csv
- 1.方法一(✅推荐)
- 2.方法一:(去重)
- 3.方法二
- 4.方法二:(去重)
0、教程
官方:
https://hugging-face.cn/docs/transformers/trainer
https://huggingface.co/docs/transformers/main_classes/trainer
https://huggingface.co/docs/transformers/zh/internal/trainer_utils
https://blog.csdn.net/qq_45779334/article/details/134465640
-
Trainer:
https://huggingface.co/docs/transformers/main_classes/trainer
https://huggingface.co/docs/transformers/v4.53.3/zh/main_classes/trainer -
TrainingArguments:
https://huggingface.co/docs/transformers/v4.53.3/en/main_classes/trainer#transformers.TrainingArguments -
日志:https://huggingface.co/docs/transformers/main_classes/logging
-
Callbacks:
https://huggingface.co/docs/transformers/main_classes/callback
https://huggingface.co/docs/transformers/v4.53.3/en/main_classes/callback#transformers.TrainerCallback
评估指标:compute_metrics()
其他:
https://blog.csdn.net/u013172930/article/details/146155963
https://deepinout.com/pytorch/pytorch-questions/62_pytorch_huggingface_trainer_logging_train_data.html
https://zhuanlan.zhihu.com/p/690000700
1、Trainer参数
1.官方说明
https://huggingface.co/docs/transformers/main_classes/trainer
https://huggingface.co/docs/transformers/v4.53.3/zh/main_classes/trainer
在实例化你的 Trainer 之前,创建一个 TrainingArguments,以便在训练期间访问所有定制点。
如果你想要使用自回归技术在文本数据集上微调像 Llama-2 或 Mistral 这样的语言模型,
考虑使用 trl 的 SFTTrainer。SFTTrainer 封装了 Trainer,专门针对这个特定任务进行了优化,
并支持序列打包、LoRA、量化和 DeepSpeed,以有效扩展到任何模型大小。
另一方面,Trainer 是一个更通用的选项,适用于更广泛的任务。
Trainer 与 TrainingArguments 类齐头并进,该类提供了广泛的选项来自定义模型的训练方式。
这两个类共同提供了一个完整的训练 API。
Seq2SeqTrainer 和 Seq2SeqTrainingArguments 继承自 Trainer 和 TrainingArguments 类,
它们适用于训练序列到序列任务(例如摘要或翻译)的模型。Trainer 类被优化用于 🤗 Transformers 模型,
并在你在其他模型上使用时可能会有一些令人惊讶的结果。
当在你自己的模型上使用时,请确保:你的模型始终返回元组或 ModelOutput 的子类。
如果提供了 labels 参数,你的模型可以计算损失,
并且损失作为元组的第一个元素返回(如果你的模型返回元组)。你的模型可以接受多个标签参数(在 TrainingArguments 中
使用 label_names 将它们的名称指示给 Trainer),
但它们中没有一个应该被命名为 "label"。
args ( TrainingArguments , 可选 )—— 用于训练的参数。默认为 TrainingArguments 的基本实例,其 如果未提供,则将 output_dir 设置为当前目录中名为 tmp_trainer 的目录。
data_collator ( DataCollator , 可选 ) — 用于从 train_dataset 或 eval_dataset 元素列表中生成批次的函数。如果未提供 processing_class ,则默认使用 default_data_collator() 。 如果 processing_class 是特征提取器或标记器,则为 DataCollatorWithPadding 。
processing_class ( PreTrainedTokenizerBase 、 BaseImageProcessor 、 FeatureExtractionMixin 或 ProcessorMixin , 可选 )— 用于处理数据的处理类。如果提供,将用于自动处理模型的输入,并将其与模型一起保存,以便更轻松地重新运行中断的训练或重用已微调的模型。这将取代 tokenizer 参数,后者现已弃用。
train_dataset (Union[ torch.utils.data.Dataset , torch.utils.data.IterableDataset , datasets.Dataset ], 可选 ) — 用于训练的数据集。如果是 Dataset ,则不接受的列 model.forward() 方法将被自动删除。
compute_loss_func ( Callable , 可选 )— 一个函数,接受原始模型输出、标签以及整个累积批次 (batch_size * Gradient_accumulation_steps) 中的项目数,并返回损失。例如,请参阅 Trainer 使用的默认损失函数 。
compute_metrics ( Callable[[EvalPrediction], Dict] , 可选 ) — 用于在评估时计算指标的函数。必须接受 EvalPrediction 参数并返回指标值的字典字符串。 注意: 在传递 TrainingArgs 时,将 batch_eval_metrics 设置为 True ,则 compute_metrics 函数必须接受布尔值 compute_result 参数。该参数将在最后一个 eval 批次之后触发,以指示该函数需要计算并返回全局汇总统计信息,而不是累积批次级别的统计信息。
回调 ( TrainerCallback 列表, 可选 ) — 用于自定义训练循环的回调列表。这些回调将添加到此处详述的默认回调列表中。
优化器 ( tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR] , 可选 ,默认为 (None, None) ) — 包含要使用的优化器和调度器的元组。默认为模型上的 AdamW 实例,以及由 get_linear_schedule_with_warmup() 提供的调度器,该调度器由 args 控制。
2.参数说明
好的 👍
我来帮你系统梳理一下 Hugging Face Trainer 的主要参数(包含常用和进阶参数),这样你在用 Trainer 训练时能清楚每个参数的作用。
📌 Hugging Face Trainer 参数说明
1️⃣ 初始化参数(Trainer 构造函数)
from transformers import Trainertrainer = Trainer(model=model, # 模型(必须是 PreTrainedModel 或 torch.nn.Module)args=training_args, # TrainingArguments 配置train_dataset=train_dataset, # 训练集 (datasets.Dataset 或 torch.utils.data.Dataset)eval_dataset=eval_dataset, # 验证集tokenizer=tokenizer, # 分词器(可选,用于保存/评估时自动处理)data_collator=data_collator, # batch 拼接函数,默认自动推断compute_metrics=compute_metrics, # 计算指标函数,eval 时用callbacks=[CustomCallback], # 回调函数列表
)
2️⃣ TrainingArguments(训练配置参数)
from transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir="./results", # 模型保存路径overwrite_output_dir=True, # 覆盖已有输出目录evaluation_strategy="epoch", # 评估策略: "no", "steps", "epoch"save_strategy="epoch", # 模型保存策略save_total_limit=2, # 最多保存多少个 checkpointper_device_train_batch_size=16, # 训练 batch 大小per_device_eval_batch_size=16, # 验证 batch 大小gradient_accumulation_steps=1, # 梯度累计(等效于大 batch)learning_rate=5e-5, # 学习率weight_decay=0.01, # 权重衰减num_train_epochs=3, # 训练轮数max_steps=-1, # 最大训练步数(优先于 epoch)warmup_steps=500, # 预热步数logging_dir="./logs", # TensorBoard 日志路径logging_steps=50, # 日志记录间隔report_to="tensorboard", # 日志报告方式(tensorboard, wandb, all)save_steps=500, # 保存模型间隔(当 save_strategy="steps" 时生效)eval_steps=500, # 评估间隔load_best_model_at_end=True, # 是否在训练结束后加载最优模型metric_for_best_model="accuracy", # 用于挑选最佳模型的指标greater_is_better=True, # 指标是否越大越好fp16=True, # 混合精度训练(需 GPU 支持)dataloader_num_workers=4, # DataLoader 的 worker 数seed=42, # 随机种子
)
3️⃣ 常用参数详解
| 参数 | 说明 |
|---|---|
| model | 训练的模型(通常来自 AutoModelFor...) |
| train_dataset | 训练集,需实现 __len__ 和 __getitem__ |
| eval_dataset | 验证集,Trainer 会在指定策略下评估 |
| tokenizer | 用于保存模型时自动保存分词器 |
| data_collator | 批数据处理函数,默认会 pad 对齐 |
| compute_metrics | 用于验证时计算指标(如准确率、F1) |
| callbacks | 自定义回调,比如早停 EarlyStoppingCallback |
4️⃣ 训练/评估策略参数
-
evaluation_strategy
"no":不评估"steps":每隔eval_steps评估"epoch":每个 epoch 结束后评估
-
save_strategy
"no":不保存"steps":每隔save_steps保存"epoch":每个 epoch 保存
-
logging_strategy
- 同理,可以设置
"steps"或"epoch"
- 同理,可以设置
5️⃣ 高级参数
| 参数 | 说明 |
|---|---|
| gradient_checkpointing | 节省显存(牺牲速度) |
| lr_scheduler_type | 学习率调度器(linear, cosine, constant, 等) |
| optim | 优化器选择(adamw_torch, adamw_hf, sgd) |
| group_by_length | 数据按长度分组,提高效率(主要用于 NLP) |
| resume_from_checkpoint | 从 checkpoint 恢复训练 |
| dataloader_pin_memory | DataLoader 是否固定内存 |
| remove_unused_columns | 是否移除没用到的数据列 |
✅ 总结:
- Trainer = (模型 + 数据 + 训练配置 + 指标/回调)
- 核心调参点:batch_size、learning_rate、scheduler、gradient_accumulation、fp16、evaluation_strategy
- 通过
TrainingArguments控制训练流程,TensorBoard 可实时监控
要不要我帮你整理一个 Trainer 参数速查表(CheatSheet),像一张对照表那样,随时查?
好的 👍 我帮你把 Hugging Face Trainer 里最常用的参数做一个系统说明(中文+用途),这样你能快速理解它们在训练中起的作用。
🏗️ TrainingArguments 常用参数说明
from transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir="./results", # 模型输出目录(保存权重、日志)overwrite_output_dir=True, # 是否覆盖旧的output_dirnum_train_epochs=3, # 训练总epoch数per_device_train_batch_size=16, # 每个GPU/CPU上的训练batch大小per_device_eval_batch_size=16, # 每个GPU/CPU上的验证batch大小gradient_accumulation_steps=1, # 梯度累积步数(用于大batch)learning_rate=5e-5, # 学习率weight_decay=0.01, # 权重衰减(L2正则)warmup_steps=500, # 学习率warmup步数lr_scheduler_type="linear", # 学习率调度器 (linear, cosine等)optim="adamw_torch", # 优化器 (adamw_torch / adamw_hf / sgd 等)logging_dir="./logs", # TensorBoard 日志目录logging_strategy="steps", # logging方式: "steps" 或 "epoch"logging_steps=10, # 每多少步记录一次日志report_to="tensorboard", # 记录到哪里 (["tensorboard", "wandb", "none"])evaluation_strategy="steps", # 评估方式: "no" / "steps" / "epoch"eval_steps=50, # 每多少步进行一次evalsave_strategy="steps", # 保存模型方式: "no" / "steps" / "epoch"save_steps=50, # 每多少步保存一次模型save_total_limit=3, # 最多保存多少个checkpoint(旧的会删掉)load_best_model_at_end=True, # 训练结束后加载最佳模型metric_for_best_model="eval_loss", # 判定最优模型的metricgreater_is_better=False, # metric越大越好还是越小越好(loss是False)seed=42, # 随机种子,保证可复现fp16=True, # 是否使用混合精度训练 (GPU上)dataloader_num_workers=4, # DataLoader的线程数
)
📌 关键点分类理解
🔹 训练控制
-
num_train_epochs:总训练轮数
-
per_device_train_batch_size:每个设备的 batch size
-
gradient_accumulation_steps:控制等效 batch 大小
- 例:batch=16, grad_accum=2 → 等效 batch=32
🔹 优化器 & 学习率
- learning_rate:基础学习率
- weight_decay:L2正则
- warmup_steps:学习率热身步数
- lr_scheduler_type:调度器类型(
linear,cosine,polynomial, …)
🔹 日志 & 可视化
-
logging_strategy:
"steps"→ 每隔logging_steps记录"epoch"→ 每个 epoch 记录
-
report_to: 控制日志输出到哪里(tensorboard, wandb, none)
🔹 评估 & 保存
-
evaluation_strategy:
"no"→ 不评估"steps"→ 每隔eval_steps评估"epoch"→ 每个 epoch 评估
-
save_strategy: 保存模型的方式(steps/epoch)
-
save_total_limit: 限制 checkpoint 数量
🔹 最优模型
- load_best_model_at_end:最后加载最优checkpoint
- metric_for_best_model:评估指标(如
eval_loss、eval_accuracy) - greater_is_better:指标是否越大越好
📊 典型配置:股票预测(回归任务)
training_args = TrainingArguments(output_dir="./results",num_train_epochs=20,per_device_train_batch_size=32,per_device_eval_batch_size=32,learning_rate=1e-4,weight_decay=0.01,logging_strategy="steps",logging_steps=10,evaluation_strategy="steps",eval_steps=50,save_strategy="steps",save_steps=50,save_total_limit=3,report_to="tensorboard",load_best_model_at_end=True,metric_for_best_model="eval_mse",greater_is_better=False,
)
要不要我帮你整理一张 参数作用表格 (参数 - 默认值 - 推荐值 - 用途)?这样你随时查就像 Trainer速查表 一样用起来很方便。
3.评估指标
训练时的评估和测试时的评估用不同评估指标
在 Hugging Face 的 Trainer 框架中,训练过程中的评估(evaluation during training) 和 最终测试时的评估(evaluation on test set) 是分开的,两者完全可以使用 不同的评估指标。
- 默认情况
Trainer在训练过程中(trainer.train()时)会周期性调用compute_metrics来计算评估指标。trainer.evaluate(eval_dataset=...)会在验证集上计算同样的指标。trainer.predict(test_dataset=...)也会默认调用compute_metrics来返回指标。
因此,默认情况下,训练中评估 / 验证集评估 / 测试集评估 都用同一个 compute_metrics。
- 如果想在训练和测试阶段使用不同指标
可以通过 自定义两个不同的指标函数,然后在需要时分别传给 Trainer.evaluate 和 Trainer.predict。
方式一:在 Trainer 内部只定义训练用的 compute_metrics
def compute_metrics_train(eval_pred):predictions, labels = eval_pred# 比如训练时只看 MSEmse = ((predictions - labels) ** 2).mean()return {"mse": mse}trainer = Trainer(model=model,args=training_args,train_dataset=train_ds,eval_dataset=valid_ds,compute_metrics=compute_metrics_train
)
这样在训练时和验证集上评估时,都会只用 mse。
方式二:测试时单独传入另一个 compute_metrics
def compute_metrics_test(eval_pred):predictions, labels = eval_pred# 比如测试时用 MAE 和 R²mae = abs(predictions - labels).mean()ss_res = ((labels - predictions) ** 2).sum()ss_tot = ((labels - labels.mean()) ** 2).sum()r2 = 1 - ss_res/ss_totreturn {"mae": mae, "r2": r2}# 测试时覆盖默认 compute_metrics
results = trainer.predict(test_ds, metric_key_prefix="test", compute_metrics=compute_metrics_test)
print(results.metrics)
这样就可以实现:
- 训练/验证时: 用
mse - 测试时: 用
mae、r2
- 更灵活的做法:动态选择指标
如果你想在同一个 compute_metrics 里根据 阶段 返回不同指标,可以加一个全局变量或 Trainer 参数区分:
EVAL_MODE = "train" # 或 "test"def compute_metrics(eval_pred):predictions, labels = eval_predif EVAL_MODE == "train":return {"mse": ((predictions - labels) ** 2).mean()}elif EVAL_MODE == "test":mae = abs(predictions - labels).mean()return {"mae": mae}
在调用 trainer.predict 前,把 EVAL_MODE 改成 "test" 即可。
✅ 总结:
-
Trainer默认使用一个compute_metrics,训练、验证、测试都会调用它。 -
想要不同指标,可以:
- 在测试时调用
predict(test_ds, compute_metrics=...)来覆盖指标函数。 - 或者在一个函数里根据阶段切换返回的指标。
- 在测试时调用
要不要我给你写一个 股票预测的完整例子,其中训练时用 MSE,测试时用 MAE 和 R²,这样更贴近你的场景?
compute_metrics()中eval_pred的 logits, labels对应关系:
def compute_metrics(eval_pred):print("进入 compute_metrics")predictions, labels = eval_predlogits = eval_pred.predictionslabels = eval_pred.label_ids
在这里插入代码片
在 Hugging Face 的 Trainer 框架里,compute_metrics(eval_pred) 里的
-
eval_pred.predictions(也就是 logits)
就是模型forward()返回的输出中的"logits"部分。
👉 也就是说你在CustomInformer.forward里return {"logits": preds},那这里logits = preds。 -
eval_pred.label_ids(也就是 labels)
就是模型forward()返回的输出中的"labels"参数。
是Dataset.__getitem__()返回的dict中,键名为"labels"的张量。
👉 所以如果你在Dataset里返回的是{"past_values": ...,"past_time_features": ...,"past_observed_mask": ...,"labels": y[idx], # 注意必须叫 labels }那么
eval_pred.label_ids = y[idx]。
Trainer 的工作机制是这样的:
-
Dataset 提供
labels→Trainer会自动把它传进model.forward(labels=...)。 -
Model.forward 返回一个
dict,其中"logits"会被当成预测结果保存。 -
评估时,
compute_metrics(eval_pred)里的:eval_pred.predictions = logitseval_pred.label_ids = labels
2、TrainingArguments
TrainingArguments:
https://huggingface.co/docs/transformers/v4.53.3/en/main_classes/trainer#transformers.TrainingArguments
do_train ( 可选 ,默认为)— 是否运行训练。此参数不直接由 Trainer 使用,而是供训练/评估脚本使用。更多详情请参阅示例脚本 bool False
logging_strategy 单位(或 IntervalStrategy , 可选 ,默认为 )— 训练期间采用的日志记录策略。可能的值包括: str “steps”
“no”: No logging is done during training.
“no” :训练期间不进行任何记录。
“epoch”: Logging is done at the end of each epoch.
“epoch” :记录在每个时期结束时完成。
“steps”: Logging is done every .logging_steps
“steps” :每隔 进行一次日志记录 logging_steps
logging_steps (或, 可选 ,默认为 500)— 两个日志之间的更新步数。应为整数或浮点数(范围为)。如果小于 1,则将被解释为总训练步数的比率。int int float logging_strategy=“steps” [0,1)
run_name(可选,默认为)— 运行的描述符。通常用于 wandb 、 mlflow 、 comet 和 swanlab 日志 output_dir 。 如果未指定 , 则与 相同。str str output_dir
remove_unused_columns (, 可选 ,默认为) — 是否自动删除模型转发方法未使用的列 bool True
label_names (, 可选 ) — 输入字典中与标签对应的键列表。list list[str]
load_best_model_at_end ( 可选 ,默认为)— 是否在训练结束时加载训练过程中找到的最佳模型。启用此选项后,最佳检查点将始终保存。更多信息请 save_total_limit bool False
metric_for_best_model(可选)— 与 一起使用 str 指定用于比较两个不同模型的指标。必须是评估返回的指标名称,带或不带前缀。str load_best_model_at_end “eval_”。如果未指定,则默认为或(使用评估损失)。 “loss” load_best_model_at_end == True lr_scheduler_type == SchedulerType.REDUCE_ON_PLATEAU
abel_smoothing_factor ( 可选 ,默认为 0.0) — 使用的标签平滑因子。零表示不使用标签平滑,否则底层独热编码标签将分别从 0 和 1 更改为 和 。float float 1 - label_smoothing_factor + label_smoothing_factor/num_labels
optim (或, 可选 ,默认为)— 要使用的优化器,例如“adamw_torch”、“adamw_torch_fused”、“adamw_apex_fused”、“adamw_anyprecision”和“adafactor”。有关优化器的完整列表,请参阅 training_args.py。str training_args.OptimizerNames str “adamw_torch” OptimizerNames
optim_args (, 可选 ) — 提供给优化器(例如 AnyPrecisionAdamW、AdEMAMix 和 GaLore)的可选参数 str
report_to (或, 可选 ,默认为)— 用于报告结果和日志的集成列表。支持的平台包括、、、、、、、、、、、和。用于报告给所有已安装的集成,不报告任何集成。str list[str] str “all” “azure_ml” “clearml” “codecarbon” “comet_ml” “dagshub” “dvclive” “flyte” “mlflow” “neptune” “swanlab” “tensorboard” “wandb” “all” “none”
push_to_hub ( 可选 ,默认为)— 每次保存模型时是否将模型推送到 Hub。如果启用,将创建一个与仓库同步的 git 目录(由 确定),并且每次触发保存时都会推送内容(取决于您的 )。调用 save_model() 也会触发推送 False bool output_dir hub_model_id save_strategy
hub_model_id ( 可选 )— 与本地 output_dir 保持同步的存储库名称。它可以是一个简单的模型 ID,在这种情况下,模型将被推送到您的命名空间。否则,它应该是完整的存储库名称,例如,这样您就可以将数据推送到您所属的组织。默认为 output_dir_name ,其名称为 。str str “user_name/model” “organization_name/model” user_name/output_dir_name output_dir

3.1、Callbacks回调
https://huggingface.co/docs/transformers/v4.53.3/zh/main_classes/callback
https://huggingface.co/docs/transformers/main_classes/callback
https://hugging-face.cn/docs/transformers/trainer#callbacks
https://hugging-face.cn/docs/setfit/how_to/callbacks#using-callbacks
中文:https://hugging-face.cn/docs/transformers/main_classes/callback#transformers.TrainerCallback
源码:https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_callback.py
1. 官方教程
Callbacks可以用来自定义PyTorch [Trainer]中训练循环行为的对象(此功能尚未在TensorFlow中实现),该对象可以检查训练循环状态(用于进度报告、在TensorBoard或其他ML平台上记录日志等),并做出决策(例如提前停止)。
Callbacks是“只读”的代码片段,除了它们返回的[TrainerControl]对象外,它们不能更改训练循环中的任何内容。对于需要更改训练循环的自定义,您应该继承[Trainer]并重载您需要的方法(有关示例,请参见trainer)。
默认情况下,TrainingArguments.report_to 设置为”all”,然后[Trainer]将使用以下callbacks。
TrainerCallback一个对象类,用于检查某些事件中训练循环的状态并做出某些决策。在每个事件中,以下参数可用:
- 参数
args 、 state 和 control 是所有事件的位置参数,其余参数则分组到 kwargs 中。您可以使用它们在事件签名中解压所需的参数。例如,请参阅简单的 PrinterCallback 代码。
- args ( TrainingArguments ) — 用于实例化 Trainer 训练参数。
- 状态 ( TrainerState ) — Trainer 的当前状态。
- 控制 ( TrainerControl )——返回给 Trainer 并可用于做出一些决策的对象。control 对象是唯一可以通过回调改变的对象,在这种情况下,改变它的事件应该返回修改后的版本。
注意:(更新)
在本类中,一步被理解为一次更新步。当使用梯度累积时,一次更新步可能需要多次正向和反向传播:如果您使用 gradient_accumulation_steps=n,那么一次更新步需要经过 n 个批次。
n all this class, one step is to be understood as one update step. When using gradient accumulation, one update step may require several forward and backward passes: if you use gradient_accumulation_steps=n, then one update step requires going through n batches.
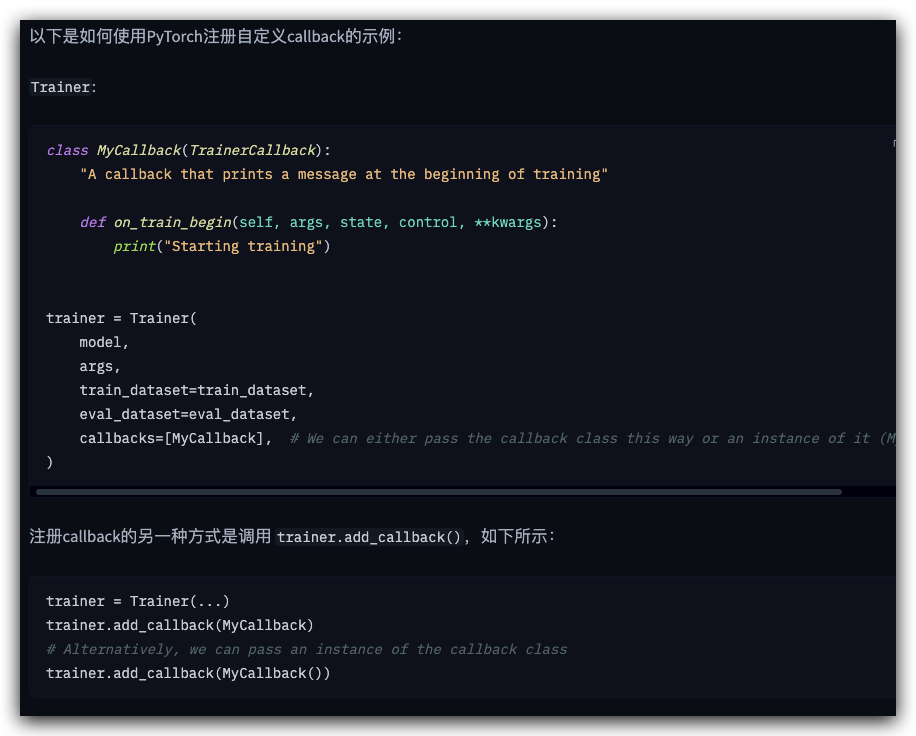
class MyCallback(TrainerCallback):"A callback that prints a message at the beginning of training"def on_train_begin(self, args, state, control, **kwargs):print("Starting training")trainer = Trainer(model,args,train_dataset=train_dataset,eval_dataset=eval_dataset,callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
)
from transformers import TrainerCallback, Trainerclass EarlyStoppingCallback(TrainerCallback):def __init__(self, num_steps=10):self.num_steps = num_stepsdef on_step_end(self, args, state, control, **kwargs):if state.global_step >= self.num_steps:return {"should_training_stop": True}else:return {}trainer = Trainer(model=model,args=training_args,train_dataset=dataset["train"],eval_dataset=dataset["test"],processing_class=tokenizer,data_collator=data_collator,compute_metrics=compute_metrics,callbacks=[EarlyStoppingCallback()],
)
class PrinterCallback(TrainerCallback):def on_log(self, args, state, control, logs=None, **kwargs):_ = logs.pop("total_flos", None)if state.is_local_process_zero:print(logs)
2.✅回调参数(kwargs可获取对象)
参考源码:https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_callback.py
class TrainerCallback:# no-format"""A class for objects that will inspect the state of the training loop at some events and take some decisions. Ateach of those events the following arguments are available:Args:args ([`TrainingArguments`]):The training arguments used to instantiate the [`Trainer`].state ([`TrainerState`]):The current state of the [`Trainer`].control ([`TrainerControl`]):The object that is returned to the [`Trainer`] and can be used to make some decisions.model ([`PreTrainedModel`] or `torch.nn.Module`):The model being trained.tokenizer ([`PreTrainedTokenizer`]):The tokenizer used for encoding the data. This is deprecated in favour of `processing_class`.processing_class ([`PreTrainedTokenizer` or `BaseImageProcessor` or `ProcessorMixin` or `FeatureExtractionMixin`]):The processing class used for encoding the data. Can be a tokenizer, a processor, an image processor or a feature extractor.optimizer (`torch.optim.Optimizer`):The optimizer used for the training steps.lr_scheduler (`torch.optim.lr_scheduler.LambdaLR`):The scheduler used for setting the learning rate.train_dataloader (`torch.utils.data.DataLoader`, *optional*):The current dataloader used for training.eval_dataloader (`torch.utils.data.DataLoader`, *optional*):The current dataloader used for evaluation.metrics (`dict[str, float]`):The metrics computed by the last evaluation phase.Those are only accessible in the event `on_evaluate`.logs (`dict[str, float]`):The values to log.Those are only accessible in the event `on_log`.The `control` object is the only one that can be changed by the callback, in which case the event that changes itshould return the modified version.The argument `args`, `state` and `control` are positionals for all events, all the others are grouped in `kwargs`.You can unpack the ones you need in the signature of the event using them. As an example, see the code of thesimple [`~transformers.PrinterCallback`].Example:```pythonclass PrinterCallback(TrainerCallback):def on_log(self, args, state, control, logs=None, **kwargs):_ = logs.pop("total_flos", None)if state.is_local_process_zero:print(logs)```"""
中文翻译:
参数 args、state 和 control 是所有事件的位置参数,其他所有参数都被分组到 kwargs 中。 您可以在事件方法的签名中使用它们来解包您需要的参数。作为示例,请参阅简单的 [~transformers.PrinterCallback] 代码。
示例:(用到logs,把他写到参数,解包)
class PrinterCallback(TrainerCallback):def on_log(self, args, state, control, logs=None, **kwargs):_ = logs.pop("total_flos", None)if state.is_local_process_zero:print(logs)
翻译说明:
位置参数:指的是必须按顺序传递的参数(args, state, control)
kwargs:关键字参数,包含所有其他参数
解包:指在方法签名中使用 **kwargs 来接收额外的参数
示例代码:展示了一个简单的日志回调实现,它会:
从日志中移除 total_flos 键(如果存在)
只在主进程中打印日志信息

3.✅解包参数(有两种)
解包:指在方法签名中使用 **kwargs 来接收额外的参数
方式1:kwargs获取
方式2:在参数重声明该参数
def on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):metrics = kwargs.get('metrics', {})eval_mse = metrics.get('eval_mse')threshold = 5.0print(f"回调获取 MSE: {metrics}, 阈值: {threshold}")
def on_evaluate(self, args, state, control, metrics=None, **kwargs):if metrics is None:return controlprint(f"[Eval]: {metrics}")
4. ✅Trainer log tensorboard某一参数
实现:要想记录到tensorboard,必须把Trainer对象通过参数传入callback,然后调用trainer进行记录
Trainer log tensorboard某一参数
明白 ✅ 你想让 HuggingFace Trainer 在 TensorBoard 上 log 某一个参数。
这里分几种情况说明:
1️⃣ 直接 log 到 TensorBoard
Trainer 内部使用 self.log() 来写 log,所有 log 都会被送到你在 TrainingArguments(report_to=...) 指定的后端(如 TensorBoard)。
注意:kwargs["trainer"]获取不到trainer,要在初始化手动传入
比如在 回调里:
from transformers import TrainerCallbackclass CustomLogCallback(TrainerCallback):# 纠正def __init__(self, trainer):# 修复:在初始化时保存 trainer 实例self._trainer = trainerdef on_step_end(self, args, state, control, **kwargs):# 假设你要记录学习率optimizer = kwargs.get("optimizer")if optimizer is not None:lr = optimizer.param_groups[0]["lr"]kwargs["trainer"].log({"learning_rate": lr})# 假设你要记录梯度范数model = kwargs.get("model")if model is not None:total_norm = 0for p in model.parameters():if p.grad is not None:total_norm += p.grad.data.norm(2).item() ** 2grad_norm = total_norm ** 0.5#kwargs["trainer"].log({"grad_norm": grad_norm}) # 错误❌
传入 Trainer:
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,callbacks=[CustomLogCallback]
)
纠正:# 实例化 Trainertrainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=compute_metrics,callbacks=[], # 先不添加,后面再加)# 实例化回调并添加到 Trainer 中,确保回调能获取到 trainer 实例trainer.add_callback(CustomSavingAndLoggingCallback(trainer))
然后你就可以在 TensorBoard 看到 learning_rate 和 grad_norm 两条曲线。
2️⃣ 使用 compute_metrics 记录评估参数
如果你只想在 eval/test 阶段 log 参数:
def compute_metrics(eval_pred):predictions, labels = eval_predmse = ((predictions - labels) ** 2).mean()mae = abs(predictions - labels).mean()return {"eval_mse": mse, "eval_mae": mae}
这样 eval_mse、eval_mae 会出现在 TensorBoard 的 scalars。
3️⃣ 控制 log 策略
在 TrainingArguments 里配置:
training_args = TrainingArguments(output_dir="./results",logging_dir="./logs",logging_strategy="steps", # "epoch" 也行logging_steps=50,report_to=["tensorboard"], # 确保写入 TensorBoard
)
4️⃣ 直接用 SummaryWriter(完全手动)
有时候你想和 Trainer log 分开写,可以自己建一个 TensorBoard writer:
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("./logs")# 在训练循环里
writer.add_scalar("custom_param", value, step)
👉 总结:
- 如果要让参数出现在 TensorBoard,最简单的是:在 回调里用
trainer.log()。 - 如果只在评估时需要,放到
compute_metrics里即可。 - 如果你想要完全独立的曲线,可以直接用
SummaryWriter。
要不要我帮你写一个 最小完整示例(比如记录 loss、lr、grad_norm 三个参数到 TensorBoard),这样你可以跑一下直接看到效果?
你是想在 HuggingFace 的 Trainer 里,把某一个自定义参数/指标(比如学习率、loss 之外的东西)记录到 TensorBoard 吗?
在 Trainer 里记录到 TensorBoard 的常用方法有两种:
- 用
TrainerCallback自定义记录 (❌不生效)
from transformers import TrainerCallbackclass CustomTensorboardCallback(TrainerCallback):def on_log(self, args, state, control, logs=None, **kwargs):# logs 是 trainer 内部默认的字典,可以往里加自己的参数if logs is not None:logs["my_param"] = 0.1234 # 你想记录的参数return control
然后在 Trainer 初始化时传入:
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,callbacks=[CustomTensorboardCallback]
)
这样 TensorBoard 就会多出一个 my_param 曲线。
- 直接用
trainer.log()
在训练循环或自定义逻辑里,可以随时调用:
trainer.log({"my_param": 0.5678})
这样也会被写入到 TensorBoard。
- 如果用 TensorBoardWriter
Trainer 内部已经有 self.log_metrics() 机制,会把字典里的所有键值写到 TensorBoard,所以只要确保你的参数出现在 logs 里,它就会被写进去。
例如在 on_step_end 或 on_epoch_end 回调里:
def on_step_end(self, args, state, control, **kwargs):logs = {"custom_lr": optimizer.param_groups[0]["lr"]}kwargs["trainer"].log(logs)return control
要更具体的话,我得问一下:
👉 你想 log 的是模型内部的参数值(比如某一层权重/梯度),还是**训练过程中的一些数值(比如学习率、奖励、某个loss子项)**呢?
3.2、✅Callbacks 的logs
https://huggingface.co/docs/transformers/v4.56.1/en/main_classes/callback#transformers.TrainerCallback
官方说明:
logs (dict[str, float]) — The values to log.
Those are only accessible in the event on_log.
这句话出自 Hugging Face Transformers 文档中 TrainerCallback 的参数说明,结合周围页面的上下文,它的意思可以这样理解:
1. logs 是什么
- 类型:
dict[str, float]- 键(
str):指标或日志项的名字,例如"loss"、"learning_rate"、"eval_accuracy"。 - 值(
float):对应的数值。
- 键(
- 来源:这些值是 Trainer 在训练或评估过程中收集到的即时日志数据,比如当前 step 的损失、评估指标、学习率等。
2. “only accessible in the event on_log” 的含义
TrainerCallback有很多事件方法(on_train_begin、on_step_end、on_evaluate、on_log等)。logs这个参数只会在on_log事件中传入,也就是说:- 你不能在
on_step_end、on_evaluate等其他事件里直接访问logs。 - 如果你想获取并处理这些日志值(比如打印、保存到文件、发送到监控平台),必须在
on_log回调里做。
- 你不能在
3. 结合页面上下文的调用流程
文档里提到:
on_log事件会在 Trainer 完成一次日志记录后触发。- 触发时会把
logs字典传给回调,让你有机会读取这些值。 - 例如官方的
PrinterCallback就是在on_log里打印logs内容:class PrinterCallback(TrainerCallback):def on_log(self, args, state, control, logs=None, **kwargs):_ = logs.pop("total_flos", None) # 去掉不需要的项if state.is_local_process_zero:print(logs)
4. 实际应用场景
- 自定义日志输出:在
on_log中把logs写入 CSV、数据库或第三方监控(如 WandB、MLflow)。 - 条件触发:根据
logs中的指标值(如eval_loss)决定是否保存模型或提前停止。 - 可视化:将
logs中的值推送到 TensorBoard、Matplotlib 实时绘图等。
✅ 总结
logs 是 Trainer 在某个时间点收集到的一批指标数据,它只会在 on_log 事件中传入回调函数,供你读取和处理。这是 Hugging Face 设计的一个“只读快照”,方便你在日志记录时做自定义操作,而不会影响训练主流程。
如果你愿意,我可以帮你画一个 Trainer 回调事件触发顺序图,标出 logs 出现的位置,这样你就能直观看到它为什么只能在 on_log 里访问。这样会让你在写自定义回调时更精准地放置逻辑。你要我画吗?
4、logging 日志(可视化)
1. 教程
日志:https://huggingface.co/docs/transformers/main_classes/logging
https://huggingface.co/docs/transformers/v4.53.3/zh/main_classes/logging
TrainingArguments设置:
log_level (,可选,默认为 ) — 要在主进程上使用的记录器日志级别。可能的选择是字符串形式的日志级别:“debug”, ‘info’、‘warning’、‘error’ 和 ‘critical’,加上一个 ‘passive’ 级别,它不设置任何内容并保留 Transformers 库的当前日志级别(默认情况下)。strpassive"warning"参考:https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level
2. Trainer log设置
你问的 Trainer log 设置 主要涉及到 Hugging Face Trainer 是怎么把训练过程中的指标(loss、learning rate、自定义指标等)记录到 console / file / TensorBoard / wandb 等地方。下面我给你梳理一下:
🔧 1. 控制 log 频率
在 TrainingArguments 里设置:
from transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir="./results",logging_dir="./logs", # TensorBoard 日志保存路径logging_strategy="steps", # 记录策略: "steps" 或 "epoch"logging_steps=50, # 每隔多少 step 打一次 logevaluation_strategy="steps", # 评估策略: "no", "steps", "epoch"eval_steps=200, # 每隔多少 step 做一次 evalsave_strategy="steps", # 保存策略save_steps=200,save_total_limit=3, # 最多保存多少个 checkpoint
)
logging_strategy="steps"→ 每logging_steps次迭代 log 一次logging_strategy="epoch"→ 每个 epoch 结束 log 一次logging_first_step=True→ 一开始也 log
🔧 2. 设置 log 输出方式
通过 report_to 参数控制:
training_args = TrainingArguments(output_dir="./results",logging_dir="./logs",report_to=["tensorboard"], # 支持 "tensorboard", "wandb", "comet_ml", "none"
)
"tensorboard"→ 写入logging_dir"wandb"→ 自动推送到 Weights & Biases"none"→ 不写 log(只在 console 打印)
🔧 3. 自定义 log 的内容
Trainer 默认 log 的有:
loss(训练时的平均 loss)learning_rateepocheval_loss(评估 loss)compute_metrics返回的指标(如eval_mse,eval_accuracy)
如果你要加自己的 log →
- 评估时:写在
compute_metrics - 训练时:写
TrainerCallback.on_log
🔧 4. TensorBoard 可视化
启动方式:
tensorboard --logdir ./logs
然后打开浏览器 http://localhost:6006 就能看到曲线。
✅ 总结:
- 日志频率 →
logging_strategy+logging_steps - 日志位置 →
logging_dir - 日志工具 →
report_to=["tensorboard"] - 日志内容 → 默认 loss/metrics,也可以
compute_metrics+TrainerCallback自定义
要不要我帮你写一个 股票预测 Trainer 的配置模板,直接能 log train_loss、eval_mse、eval_mae 到 TensorBoard?
5、TensorBoardCallback(用不上)
也是官方自定义的回调
https://huggingface.co/docs/transformers/v4.56.1/en/main_classes/callback#transformers.integrations.TensorBoardCallback
https://github.com/huggingface/transformers/blob/v4.56.1/src/transformers/integrations/integration_utils.py#L671
6、✅报错
问题:callback中不存在trainer对象?要想记录到tensorboard,必须把Trainer对象通过参数传入callback,然后调用trainer进行记录
class CustomSavingAndLoggingCallback(TrainerCallback):"""自定义回调,用于在 MSE 达到阈值时保存模型,并在 TensorBoard 中记录额外指标。"""def __init__(self, trainer):# 修复:在初始化时保存 trainer 实例self._trainer = trainer
trainer = kwargs["trainer"] # ✅ 从 kwargs 里取 trainer
KeyError: 'trainer'
self.trainer.log({key: value}) # ✅ 这里的 self.trainer 由 Trainer 自动注入
AttributeError: 'EvalSaveCallback' object has no attribute 'trainer'
print(self._trainer.tb_writer)
AttributeError: 'Trainer' object has no attribute 'tb_writer'
你遇到了一个常见的 TrainerCallback 问题,即在回调中需要访问 Trainer 实例但 kwargs 里没有这个对象。
根本原因:on_evaluate 方法的 kwargs 参数是由 Trainer 自动填充的,它通常只包含评估相关的对象(如 model、metrics 等),不包括 Trainer 实例本身。
解决方案:你可以通过在 __init__ 方法中保存 trainer 实例来解决这个问题。Trainer 在实例化时会将自身传递给回调。
1. 修改自定义回调类 🚀
将 CustomSavingAndLoggingCallback 类修改为在初始化时接收 trainer 实例。
class CustomSavingAndLoggingCallback(TrainerCallback):def __init__(self, trainer):self._trainer = trainer # 在初始化时保存 trainer 实例def on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):metrics = kwargs.get('metrics', {})eval_mse = metrics.get('eval_mse')threshold = 5.0# 保存达到阈值的模型if eval_mse is not None and eval_mse <= threshold:print(f"MSE {eval_mse} 达到或低于阈值 {threshold},准备保存模型。")control.should_save = True# 使用保存的 _trainer 实例来记录自定义值if state.is_world_process_zero and "tensorboard" in args.report_to:performance_score = 100 / (1 + eval_mse) if eval_mse is not None else 0self._trainer.log({"custom/performance_score": performance_score,"step": state.global_step})
2. 修改 Trainer 实例化 🛠️
在实例化 Trainer 后,将 trainer 实例传递给你的回调。
# ... (其他代码保持不变) ...# 实例化 Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=compute_metrics,# callbacks=[] 先留空
)# 在这里实例化回调,并将 trainer 传递给它
trainer.add_callback(CustomSavingAndLoggingCallback(trainer))# 开始训练
print("开始训练...")
trainer.train()
这种方法可以确保你的回调始终拥有对 Trainer 实例的引用,从而能够调用 trainer.log() 方法或其他你需要的方法。这是处理需要在回调中访问 Trainer 实例时的最佳实践。
7、完整示例
好的,这是整合了所有功能,并修复了前面所有问题的完整代码。你可以直接复制、粘贴和运行。
这个版本包含了:
- 自定义 MLP 模型和配置:用于股票预测任务。
- 虚拟数据集和评估函数:方便测试,使用 MSE 作为评估指标。
- 修复后的自定义回调:它能正确地访问
Trainer实例,在 MSE 达到阈值时保存模型,并向 TensorBoard 记录自定义的性能分数。 - 正确的
TrainingArguments:evaluation_strategy和save_strategy保持一致,以支持load_best_model_at_end。 - 设备兼容性修复:确保输入数据与模型在同一设备(CPU/MPS/CUDA)。
1. 完整代码
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset
from sklearn.metrics import mean_squared_error
from transformers import (PreTrainedModel,PretrainedConfig,TrainingArguments,Trainer,TrainerCallback,TrainerState,TrainerControl
)# --------------------------------- 自定义 MLP 模型和配置 ---------------------------------
class MLPConfig(PretrainedConfig):"""用于股票预测的 MLP 模型配置类。"""model_type = "mlp_for_stock_prediction"def __init__(self, input_size=10, num_labels=1, **kwargs):super().__init__(**kwargs)self.input_size = input_sizeself.num_labels = num_labelsclass SimpleMLPForStockPrediction(PreTrainedModel):"""一个简单的 MLP 模型,用于股票预测任务。"""config_class = MLPConfigbase_model_prefix = "mlp"def __init__(self, config):super().__init__(config)self.mlp = nn.Sequential(nn.Linear(config.input_size, 256),nn.ReLU(),nn.Dropout(0.1),nn.Linear(256, 128),nn.ReLU(),nn.Dropout(0.1),nn.Linear(128, config.num_labels))self.post_init()def forward(self, input_features=None, labels=None):if not isinstance(input_features, torch.Tensor):raise TypeError("input_features must be a torch.Tensor.")logits = self.mlp(input_features.float())loss = Noneif labels is not None:loss_fct = nn.MSELoss()loss = loss_fct(logits.view(-1), labels.view(-1).float())from transformers.modeling_outputs import SequenceClassifierOutputreturn SequenceClassifierOutput(loss=loss, logits=logits)# --------------------------------- 数据集和评估函数 ---------------------------------
class StockDataset(Dataset):"""用于 Trainer 的自定义股票数据集。"""def __init__(self, features, labels):self.features = featuresself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):return {'input_features': torch.tensor(self.features[idx], dtype=torch.float32),'labels': torch.tensor(self.labels[idx], dtype=torch.float32)}def create_dummy_data(num_samples, input_size):"""生成虚拟的股票数据。"""features = np.random.rand(num_samples, input_size) * 100labels = features[:, 0] * 0.5 + features[:, 1] * 0.2 + np.random.randn(num_samples)return features, labelsdef compute_metrics(eval_pred):"""计算评估指标,这里是均方误差 (MSE)。"""logits, labels = eval_predpredictions = logits.flatten()mse = mean_squared_error(labels, predictions)return {"eval_mse": mse}# --------------------------------- 自定义回调 ---------------------------------
class CustomSavingAndLoggingCallback(TrainerCallback):"""自定义回调,用于在 MSE 达到阈值时保存模型,并在 TensorBoard 中记录额外指标。"""def __init__(self, trainer):# 修复:在初始化时保存 trainer 实例self._trainer = trainerdef on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):metrics = kwargs.get('metrics', {})eval_mse = metrics.get('eval_mse')threshold = 5.0# 保存达到阈值的模型if eval_mse is not None and eval_mse <= threshold:print(f"MSE {eval_mse} 达到或低于阈值 {threshold},准备保存模型。")control.should_save = True# 使用保存的 _trainer 实例来记录自定义值if state.is_world_process_zero and "tensorboard" in args.report_to:performance_score = 100 / (1 + eval_mse) if eval_mse is not None else 0self._trainer.log({"custom/performance_score": performance_score,"step": state.global_step})# --------------------------------- 训练脚本 ---------------------------------
if __name__ == "__main__":# 配置、数据和模型准备config = MLPConfig(input_size=10, num_labels=1)model = SimpleMLPForStockPrediction(config)num_samples = 2000features, labels = create_dummy_data(num_samples, config.input_size)train_features, train_labels = features[:1500], labels[:1500]eval_features, eval_labels = features[1500:], labels[1500:]train_dataset = StockDataset(train_features, train_labels)eval_dataset = StockDataset(eval_features, eval_labels)# 定义训练参数training_args = TrainingArguments(output_dir="./stock_prediction_results",num_train_epochs=10,per_device_train_batch_size=32,per_device_eval_batch_size=32,evaluation_strategy="epoch", # 修复:与保存策略保持一致save_strategy="epoch", # 修复:与评估策略保持一致logging_dir="./stock_prediction_logs",report_to="tensorboard",load_best_model_at_end=True,metric_for_best_model="eval_mse",greater_is_better=False,save_total_limit=3,disable_tqdm=False,)# 实例化 Trainertrainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=compute_metrics,callbacks=[], # 先不添加,后面再加)# 实例化回调并添加到 Trainer 中,确保回调能获取到 trainer 实例trainer.add_callback(CustomSavingAndLoggingCallback(trainer))# 开始训练print("开始训练...")trainer.train()print("训练结束。")# 使用训练好的最佳模型进行预测device = trainer.model.devicenew_data = np.random.rand(1, config.input_size) * 100with torch.no_grad():# 修复:将输入数据移动到正确的设备input_tensor = torch.tensor(new_data, dtype=torch.float32).to(device)prediction = trainer.model(input_features=input_tensor).logitsprint(f"新数据的预测结果: {prediction.item()}")2. 运行说明
-
安装依赖:确保你已安装所有必需的库:
pip install torch transformers scikit-learn tensorboard -
运行代码:将代码保存为
.py文件,并在终端中运行。python your_script_name.py -
检查结果:
- 控制台:观察训练过程中的打印信息,特别是当 MSE 达到阈值时,会有相应的提示。
- 本地文件:在
stock_prediction_results目录下,你会看到保存的最佳模型检查点。 - TensorBoard 可视化:运行以下命令启动 TensorBoard 服务,然后在浏览器中打开提供的地址。
在 TensorBoard 中,你可以看到tensorboard --logdir ./stock_prediction_logseval_mse和自定义的custom/performance_score的变化曲线。
如果你对代码中的任何部分还有疑问,随时可以提问。
8.1、✅完整示例(两种实现方式)
提问:
HuggingFace Trainer 回调&可视化:自定义回调,获取评估返回的值,并记录在Trainer的tensorboard中可视化,保存最好和达到阈值的模型,自定义mlp模型,实现简单的mlp股票预测
参考:
https://huggingface.co/docs/transformers/v4.56.1/zh/main_classes/callback#transformers.TrainerCallback
https://hugging-face.cn/docs/transformers/custom_models
方法一:kwargs解包
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset
from sklearn.metrics import mean_squared_error
from transformers import (PreTrainedModel,PretrainedConfig,TrainingArguments,Trainer,TrainerCallback,TrainerState,TrainerControl
)# --------------------------------- 自定义 MLP 模型和配置 ---------------------------------
class MLPConfig(PretrainedConfig):"""用于股票预测的 MLP 模型配置类。"""model_type = "mlp_for_stock_prediction"def __init__(self, input_size=10, num_labels=1, **kwargs):super().__init__(**kwargs)self.input_size = input_sizeself.num_labels = num_labelsclass SimpleMLPForStockPrediction(PreTrainedModel):"""一个简单的 MLP 模型,用于股票预测任务。"""config_class = MLPConfigbase_model_prefix = "mlp"def __init__(self, config):super().__init__(config)self.mlp = nn.Sequential(nn.Linear(config.input_size, 256),nn.ReLU(),nn.Dropout(0.1),nn.Linear(256, 128),nn.ReLU(),nn.Dropout(0.1),nn.Linear(128, config.num_labels))self.post_init()def forward(self, input_features=None, labels=None):if not isinstance(input_features, torch.Tensor):raise TypeError("input_features must be a torch.Tensor.")logits = self.mlp(input_features.float())loss = Noneif labels is not None:loss_fct = nn.MSELoss()loss = loss_fct(logits.view(-1), labels.view(-1).float())from transformers.modeling_outputs import SequenceClassifierOutputreturn SequenceClassifierOutput(loss=loss, logits=logits)# --------------------------------- 数据集和评估函数 ---------------------------------
class StockDataset(Dataset):"""用于 Trainer 的自定义股票数据集。"""def __init__(self, features, labels):self.features = featuresself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):return {'input_features': torch.tensor(self.features[idx], dtype=torch.float32),'labels': torch.tensor(self.labels[idx], dtype=torch.float32)}def create_dummy_data(num_samples, input_size):"""生成虚拟的股票数据。"""features = np.random.rand(num_samples, input_size) * 100labels = features[:, 0] * 0.5 + features[:, 1] * 0.2 + np.random.randn(num_samples)return features, labelsdef compute_metrics(eval_pred):"""计算评估指标,这里是均方误差 (MSE)。"""logits, labels = eval_predpredictions = logits.flatten()mse = mean_squared_error(labels, predictions)return {"eval_mse": mse}# --------------------------------- 自定义回调 ---------------------------------
class CustomSavingAndLoggingCallback(TrainerCallback):"""自定义回调,用于在 MSE 达到阈值时保存模型,并在 TensorBoard 中记录额外指标。"""def __init__(self, trainer):# 修复:在初始化时保存 trainer 实例self._trainer = trainerdef on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):metrics = kwargs.get('metrics', {})eval_mse = metrics.get('eval_mse')threshold = 200print(self._trainer.log)# print(self._trainer.tb_writer)# print(self.log)callbacks = kwargs.get('callbacks', {})print(callbacks)# 保存达到阈值的模型if eval_mse is not None and eval_mse <= threshold:print(f"MSE {eval_mse} 达到或低于阈值 {threshold},准备保存模型。")control.should_save = True# 使用保存的 _trainer 实例来记录自定义值if state.is_world_process_zero and "tensorboard" in args.report_to:performance_score = 100 / (1 + eval_mse) if eval_mse is not None else 0self._trainer.log({"custom/performance_score": performance_score,"custom/step": state.global_step,"custom/eval_mse": eval_mse+100})# self._trainer.log_metrics('train',{"custom/eval_mse": eval_mse+100})# --------------------------------- 训练脚本 ---------------------------------
if __name__ == "__main__":# 配置、数据和模型准备config = MLPConfig(input_size=10, num_labels=1)model = SimpleMLPForStockPrediction(config)num_samples = 2000features, labels = create_dummy_data(num_samples, config.input_size)train_features, train_labels = features[:1500], labels[:1500]eval_features, eval_labels = features[1500:], labels[1500:]train_dataset = StockDataset(train_features, train_labels)eval_dataset = StockDataset(eval_features, eval_labels)# 定义训练参数training_args = TrainingArguments(output_dir="./logs3/stock_prediction_results",num_train_epochs=10,per_device_train_batch_size=32,per_device_eval_batch_size=32,eval_strategy="epoch", # 修复:与保存策略保持一致# save_strategy="epoch", # 修复:与评估策略保持一致save_strategy="no", # 修复:与评估策略保持一致logging_dir="./logs3/stock_prediction_logs",# report_to="tensorboard",report_to="all",# load_best_model_at_end=True,metric_for_best_model="eval_mse",greater_is_better=False,# save_total_limit=3,disable_tqdm=False,)# 实例化 Trainertrainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=compute_metrics,callbacks=[], # 先不添加,后面再加)# 实例化回调并添加到 Trainer 中,确保回调能获取到 trainer 实例trainer.add_callback(CustomSavingAndLoggingCallback(trainer))# 开始训练print("开始训练...")trainer.train()print("训练结束。")# 使用训练好的最佳模型进行预测device = trainer.model.devicenew_data = np.random.rand(1, config.input_size) * 100with torch.no_grad():# 修复:将输入数据移动到正确的设备input_tensor = torch.tensor(new_data, dtype=torch.float32).to(device)prediction = trainer.model(input_features=input_tensor).logitsprint(f"新数据的预测结果: {prediction.item()}")方法二:参数中声明
import torch
import torch.nn as nn
from transformers import PreTrainedModel, PretrainedConfigclass MLPConfig(PretrainedConfig):model_type = "mlp"def __init__(self, input_dim=10, hidden_dim=64, num_labels=2, **kwargs):super().__init__(**kwargs)self.input_dim = input_dimself.hidden_dim = hidden_dimself.num_labels = num_labelsclass MLPForStockPrediction(PreTrainedModel):config_class = MLPConfigdef __init__(self, config):super().__init__(config)self.fc1 = nn.Linear(config.input_dim, config.hidden_dim)self.fc2 = nn.Linear(config.hidden_dim, config.num_labels)def forward(self, input_ids=None, labels=None):# input_ids: [batch, features]x = torch.relu(self.fc1(input_ids.float()))logits = self.fc2(x)loss = Noneif labels is not None:loss_fn = nn.CrossEntropyLoss()loss = loss_fn(logits, labels)return {"loss": loss, "logits": logits}from transformers import TrainerCallback
import numpy as np
import osclass EvalSaveCallback(TrainerCallback):def __init__(self, monitor="eval/accuracy", mode="max", threshold=None, output_dir="./results",trainer=None):self.monitor = monitorself.mode = modeself.threshold = thresholdself.output_dir = output_dirself.best_value = -np.inf if mode == "max" else np.inf# 修复:在初始化时保存 trainer 实例self.trainer = trainerdef on_evaluate(self, args, state, control, metrics=None, **kwargs):if metrics is None:return controlprint(f"[Eval]: {metrics}")# self.trainer = kwargs["trainer"] # ❌ 从 kwargs 里取 trainer# 1. 写 tensorboardfor key, value in metrics.items():if isinstance(value, (int, float, np.number)):self.trainer.log({f'my_{key}': value})# 2. 判断是否刷新 bestif self.monitor in metrics:current = metrics[self.monitor]improved = (current > self.best_value) if self.mode == "max" else (current < self.best_value)if improved:self.best_value = currentbest_dir = os.path.join(self.output_dir, "best_model")self.trainer.save_model(best_dir)if trainer.is_world_process_zero():print(f"✨ New best {self.monitor}: {current:.4f}, model saved to {best_dir}")# 3. 达到阈值保存if self.threshold is not None:condition = (current >= self.threshold) if self.mode == "max" else (current <= self.threshold)if condition:thresh_dir = os.path.join(self.output_dir, f"checkpoint-{state.global_step}-thresh")trainer.save_model(thresh_dir)if trainer.is_world_process_zero():print(f"🚀 Threshold reached ({self.monitor}={current:.4f}), model saved to {thresh_dir}")return controldef on_log(self, args, state, control, logs=None, **kwargs):if logs:print(f"[Log] step {state.global_step}: {logs}")return controlfrom transformers import Trainer, TrainingArguments
from datasets import Dataset
import numpy as np# === 构造假股票数据 ===
n_samples = 200
n_features = 10
X = np.random.randn(n_samples, n_features).astype(np.float32)
y = np.random.randint(0, 2, size=n_samples) # 0=跌, 1=涨dataset = Dataset.from_dict({"input_ids": X,"labels": y
})
dataset = dataset.train_test_split(test_size=0.2)# === 配置模型 ===
config = MLPConfig(input_dim=n_features, hidden_dim=64, num_labels=2)
model = MLPForStockPrediction(config)# === 训练参数 ===
args = TrainingArguments(output_dir="./logs2/results",eval_strategy="steps",eval_steps=10,logging_dir="./logs2",logging_strategy="steps",logging_steps=10,report_to=["tensorboard"],num_train_epochs=5,per_device_train_batch_size=16,per_device_eval_batch_size=16,save_strategy="no", # 我们自己保存
)# === 评估函数 ===
from sklearn.metrics import accuracy_scoredef compute_metrics(eval_pred):logits, labels = eval_predpreds = np.argmax(logits, axis=-1)return {"accuracy": accuracy_score(labels, preds)}# === Trainer ===
trainer = Trainer(model=model,args=args,train_dataset=dataset["train"],eval_dataset=dataset["test"],compute_metrics=compute_metrics,# callbacks=[# EvalSaveCallback(monitor="eval/accuracy", mode="max", threshold=0.75, output_dir="./logs2/results")# ]
)# 实例化回调并添加到 Trainer 中,确保回调能获取到 trainer 实例
trainer.add_callback(EvalSaveCallback(monitor="eval/accuracy", mode="max", threshold=0.1, output_dir="./logs2/results", trainer=trainer))trainer.train()8.2、用self._trainer保存模型(不推荐)
模型该用 self._trainer 保存吗?
这是一个很好的问题。当你在自定义 TrainerCallback 中需要保存模型时,确实可以利用 self._trainer 这个实例。不过,Hugging Face 官方推荐的方法是使用 control.should_save = True 来告诉 Trainer 应该在当前步保存,而不是在回调中直接调用保存方法。
为什么推荐使用 control.should_save?
当你设置 control.should_save = True 时,你是在与 Trainer 的主训练循环协同工作。Trainer 会在每个 on_evaluate 或 on_step_end 事件结束后,检查 control 的状态。如果 should_save 被设置为 True,Trainer 会调用它自己的内部保存逻辑 (_save_checkpoint)。
这样做有几个关键优势:
- 保证一致性:
Trainer的保存逻辑处理了许多细节,例如:- 在分布式训练中的同步。
- 根据
save_total_limit删除旧的检查点。 - 正确地保存模型、优化器、学习率调度器和训练状态。
- 避免代码重复:你无需在回调中重新实现所有这些复杂的保存逻辑。
- 遵循最佳实践:这是 Hugging Face 设计
TrainerCallback的初衷,目的是让回调能够影响训练流程,而不是完全接管它。
示例代码回顾
在之前的代码中,我们正是这么做的。我们通过 control.should_save = True 来触发保存,而不是直接调用 self._trainer.save_model() 或 self._trainer._save_checkpoint()。
class CustomSavingAndLoggingCallback(TrainerCallback):def __init__(self, trainer):self._trainer = trainerdef on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):metrics = kwargs.get('metrics', {})eval_mse = metrics.get('eval_mse')threshold = 5.0if eval_mse is not None and eval_mse <= threshold:print(f"MSE {eval_mse} 达到或低于阈值 {threshold},准备保存模型。")# 告诉 Trainer 在当前步保存模型,而不是我们自己保存control.should_save = True
总结
尽管技术上你可以在回调中通过 self._trainer 来调用 save_model(),但这通常不是最佳做法。最佳实践是使用 control.should_save = True 来与 Trainer 的内置保存机制协同工作,确保训练流程的稳定性和一致性。
好的,如果你坚持要在自定义回调中直接使用 self._trainer 来保存模型,这是可能的,并且在某些特殊情况下可能很有用。
尽管官方推荐使用 control.should_save = True,但直接调用 trainer.save_model() 给了你更精细的控制权,比如你可以自定义保存路径或保存特定的模型子模块。
为什么选择直接用 self._trainer 保存?
- 完全控制路径和文件名:你可以根据评估结果或时间戳动态地创建保存目录,而不仅仅是依赖 Trainer 的默认命名规则。
- 只保存模型:如果你只想保存模型,而不保存优化器状态、学习率调度器等其他训练状态,直接调用
trainer.save_model()可以做到这一点。 - 不触发
Trainer的默认保存:当你设置save_strategy="no"时,control.should_save无法触发保存。在这种情况下,直接调用trainer.save_model()是实现自定义保存的唯一方法。
使用 self._trainer 保存模型的完整示例
下面是修改后的 CustomSavingAndLoggingCallback 和 TrainingArguments,它展示了如何在评估结果达到阈值时,使用 self._trainer 来直接保存模型。
1. 修改 TrainingArguments
首先,我们需要确保 Trainer 不会使用其默认的保存逻辑。这样我们才能完全控制保存过程。
training_args = TrainingArguments(output_dir="./stock_prediction_results",num_train_epochs=10,per_device_train_batch_size=32,per_device_eval_batch_size=32,evaluation_strategy="epoch",logging_dir="./stock_prediction_logs",report_to="tensorboard",load_best_model_at_end=True,metric_for_best_model="eval_mse",greater_is_better=False,# 关键修改:关闭 Trainer 的默认保存策略save_strategy="no", save_steps=1000000, disable_tqdm=False,
)
2. 修改自定义回调
在这个版本中,我们不再设置 control.should_save = True。相反,我们直接调用 self._trainer.save_model()。
import os
import datetimeclass CustomSavingAndLoggingCallback(TrainerCallback):def __init__(self, trainer):self._trainer = trainerdef on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):metrics = kwargs.get('metrics', {})eval_mse = metrics.get('eval_mse')threshold = 5.0if eval_mse is not None and eval_mse <= threshold:# 获取当前时间戳作为文件名的一部分,确保唯一性timestamp = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")# 自定义保存路径save_path = os.path.join(args.output_dir, f"checkpoint-threshold-{state.global_step}-{timestamp}")print(f"MSE {eval_mse} 达到或低于阈值 {threshold},正在保存模型到:{save_path}")# 关键修改:直接调用 trainer.save_model()self._trainer.save_model(output_dir=save_path)# 由于我们自己保存了,我们可以取消 Trainer 的默认保存行为control.should_save = Falseif state.is_world_process_zero and "tensorboard" in args.report_to:performance_score = 100 / (1 + eval_mse) if eval_mse is not None else 0self._trainer.log({"custom/performance_score": performance_score,"step": state.global_step})
3. 完整代码(带有新回调)
下面是完整的可运行代码,它包含了所有前面的功能,并用直接保存模型的自定义回调替换了旧版本。
import torch
import torch.nn as nn
import numpy as np
import os
import datetime
from torch.utils.data import Dataset
from sklearn.metrics import mean_squared_error
from transformers import (PreTrainedModel,PretrainedConfig,TrainingArguments,Trainer,TrainerCallback,TrainerState,TrainerControl
)# --------------------------------- 自定义 MLP 模型和配置 ---------------------------------
class MLPConfig(PretrainedConfig):model_type = "mlp_for_stock_prediction"def __init__(self, input_size=10, num_labels=1, **kwargs):super().__init__(**kwargs)self.input_size = input_sizeself.num_labels = num_labelsclass SimpleMLPForStockPrediction(PreTrainedModel):config_class = MLPConfigbase_model_prefix = "mlp"def __init__(self, config):super().__init__(config)self.mlp = nn.Sequential(nn.Linear(config.input_size, 256), nn.ReLU(), nn.Dropout(0.1),nn.Linear(256, 128), nn.ReLU(), nn.Dropout(0.1),nn.Linear(128, config.num_labels))self.post_init()def forward(self, input_features=None, labels=None):if not isinstance(input_features, torch.Tensor):raise TypeError("input_features must be a torch.Tensor.")logits = self.mlp(input_features.float())loss = Noneif labels is not None:loss_fct = nn.MSELoss()loss = loss_fct(logits.view(-1), labels.view(-1).float())from transformers.modeling_outputs import SequenceClassifierOutputreturn SequenceClassifierOutput(loss=loss, logits=logits)# --------------------------------- 数据集和评估函数 ---------------------------------
class StockDataset(Dataset):def __init__(self, features, labels):self.features = featuresself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):return {'input_features': torch.tensor(self.features[idx], dtype=torch.float32),'labels': torch.tensor(self.labels[idx], dtype=torch.float32)}def create_dummy_data(num_samples, input_size):features = np.random.rand(num_samples, input_size) * 100labels = features[:, 0] * 0.5 + features[:, 1] * 0.2 + np.random.randn(num_samples)return features, labelsdef compute_metrics(eval_pred):logits, labels = eval_predpredictions = logits.flatten()mse = mean_squared_error(labels, predictions)return {"eval_mse": mse}# --------------------------------- 自定义回调 ---------------------------------
class CustomSavingAndLoggingCallback(TrainerCallback):def __init__(self, trainer):self._trainer = trainerdef on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):metrics = kwargs.get('metrics', {})eval_mse = metrics.get('eval_mse')threshold = 5.0if eval_mse is not None and eval_mse <= threshold:timestamp = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")save_path = os.path.join(args.output_dir, f"checkpoint-threshold-{state.global_step}-{timestamp}")print(f"MSE {eval_mse} 达到或低于阈值 {threshold},正在保存模型到:{save_path}")self._trainer.save_model(output_dir=save_path)control.should_save = Falseif state.is_world_process_zero and "tensorboard" in args.report_to:performance_score = 100 / (1 + eval_mse) if eval_mse is not None else 0self._trainer.log({"custom/performance_score": performance_score, "step": state.global_step})# --------------------------------- 训练脚本 ---------------------------------
if __name__ == "__main__":config = MLPConfig(input_size=10, num_labels=1)model = SimpleMLPForStockPrediction(config)num_samples = 2000features, labels = create_dummy_data(num_samples, config.input_size)train_features, train_labels = features[:1500], labels[:1500]eval_features, eval_labels = features[1500:], labels[1500:]train_dataset = StockDataset(train_features, train_labels)eval_dataset = StockDataset(eval_features, eval_labels)training_args = TrainingArguments(output_dir="./stock_prediction_results",num_train_epochs=10,per_device_train_batch_size=32,per_device_eval_batch_size=32,evaluation_strategy="epoch",logging_dir="./stock_prediction_logs",report_to="tensorboard",load_best_model_at_end=True,metric_for_best_model="eval_mse",greater_is_better=False,save_strategy="no", # 关键:关闭默认保存save_steps=1000000, disable_tqdm=False,)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=compute_metrics,callbacks=[],)trainer.add_callback(CustomSavingAndLoggingCallback(trainer))print("开始训练...")trainer.train()print("训练结束。")device = trainer.model.devicenew_data = np.random.rand(1, config.input_size) * 100with torch.no_grad():input_tensor = torch.tensor(new_data, dtype=torch.float32).to(device)prediction = trainer.model(input_features=input_tensor).logitsprint(f"新数据的预测结果: {prediction.item()}")9、提问
提问:
1.
HuggingFace Trainer 回调&可视化:自定义回调,获取评估返回的值,并记录在Trainer的tensorboard中可视化
参考:
https://huggingface.co/docs/transformers/v4.56.1/zh/main_classes/callback#transformers.TrainerCallback
https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_callback.py
HuggingFace Trainer 回调&可视化:自定义回调,获取评估返回的值,并记录在Trainer的tensorboard中可视化,保存最好和达到阈值的模型
参考:
https://huggingface.co/docs/transformers/v4.56.1/zh/main_classes/callback#transformers.TrainerCallback
https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_callback.py
HuggingFace Trainer 回调&可视化:自定义回调,获取评估返回的值,并记录在Trainer的tensorboard中可视化,保存最好和达到阈值的模型,自定义mlp模型,实现简单的mlp股票预测
参考:
https://huggingface.co/docs/transformers/v4.56.1/zh/main_classes/callback#transformers.TrainerCallback
https://hugging-face.cn/docs/transformers/custom_models
10. TensorBoard转csv
提问:
简单:将TensorBoard每个文件到出到每个csv
文件名类似如下:
logs2/events.out.tfevents.1757138113.Mac.53327.0
1.方法一(✅推荐)
import os
import pandas as pd
from tensorboard.backend.event_processing.event_accumulator import EventAccumulatordef export_to_csv(log_dir, output_dir="csv_exports"):"""将 TensorBoard 事件文件中的所有标量数据导出为 CSV。"""if not os.path.exists(output_dir):os.makedirs(output_dir)# 遍历日志目录中的所有文件for root, dirs, files in os.walk(log_dir):for file in files:# 找到事件文件if "tfevents" in file:file_path = os.path.join(root, file)# 创建 EventAccumulator 实例event_acc = EventAccumulator(file_path)event_acc.Reload()# 获取所有可用的标量标签tags = event_acc.Tags()['scalars']if not tags:print(f"在文件 {file} 中没有找到标量数据。")continueprint(f"正在处理文件: {file}")# 为每个标签创建一个 DataFramedata = {}for tag in tags:events = event_acc.Scalars(tag)# 提取 step, wall_time 和 valuesteps = [event.step for event in events]values = [event.value for event in events]data[tag] = pd.DataFrame({'step': steps,'value': values,})# 将所有数据合并到一个 DataFrame# 这里只合并了 step 和 value,可以根据需要调整merged_df = pd.DataFrame()for tag, df in data.items():df = df.rename(columns={'value': tag})if merged_df.empty:merged_df = dfelse:merged_df = pd.merge(merged_df, df, on='step', how='outer')# 创建输出文件名output_filename = os.path.join(output_dir, f"{file}.csv")# 导出到 CSVmerged_df.to_csv(output_filename, index=False)print(f"数据已成功导出到 {output_filename}")if __name__ == "__main__":# 指定你的 TensorBoard 日志目录log_directory = "logs2"# export_to_csv(log_directory,"./logs2/csv_logs2")export_to_csv("./logs3/stock_prediction_logs", "./logs3/csv_logs2") #./logs/2025-09-06_00-40-59 # export_to_csv("./logs/2025-09-06_00-40-59", "./logs/csv_logs2") # 2.方法一:(去重)
import os
import pandas as pd
from tensorboard.backend.event_processing.event_accumulator import EventAccumulatordef export_to_csv_unique(log_dir, output_dir="csv_exports_unique"):"""将 TensorBoard 事件文件中的标量数据导出为无重复行的 CSV。"""if not os.path.exists(output_dir):os.makedirs(output_dir)for root, dirs, files in os.walk(log_dir):for file in files:if "tfevents" in file:file_path = os.path.join(root, file)event_acc = EventAccumulator(file_path)event_acc.Reload()tags = event_acc.Tags().get('scalars', [])if not tags:print(f"在文件 {file} 中没有找到标量数据。")continueprint(f"正在处理文件: {file}")data = {}for tag in tags:events = event_acc.Scalars(tag)steps = [event.step for event in events]values = [event.value for event in events]data[tag] = pd.DataFrame({'step': steps,'value': values,})# 合并所有数据到一个 DataFramemerged_df = pd.DataFrame()for tag, df in data.items():df = df.rename(columns={'value': tag})if merged_df.empty:merged_df = dfelse:merged_df = pd.merge(merged_df, df, on='step', how='outer')# --- 新增步骤:对 DataFrame 进行去重 ---# 根据 'step' 列去除重复行,并保留第一次出现的记录merged_df = merged_df.drop_duplicates(subset=['step'], keep='first')# 创建输出文件名output_filename = os.path.join(output_dir, f"{file}.csv")# 导出到 CSVmerged_df.to_csv(output_filename, index=False)print(f"数据已成功导出到 {output_filename}")if __name__ == "__main__":# 指定你的 TensorBoard 日志目录log_directory = "logs2"# export_to_csv_unique(log_directory)export_to_csv_unique("./logs3/stock_prediction_logs", "./logs3/csv_logs2") #./logs/2025-09-06_00-40-59 3.方法二
import os
import glob
import pandas as pd
from tensorboard.backend.event_processing import event_accumulatordef export_events_to_csv(logdir, outdir="./csv_logs"):os.makedirs(outdir, exist_ok=True)event_files = glob.glob(os.path.join(logdir, "events.out.tfevents.*"))for f in event_files:ea = event_accumulator.EventAccumulator(f)ea.Reload()# 每个 tag 单独存 DataFramedfs = []for tag in ea.Tags()["scalars"]:events = ea.Scalars(tag)df = pd.DataFrame({"step": [e.step for e in events],tag: [e.value for e in events]})dfs.append(df)if not dfs:continue # 空文件跳过# 按 step 合并df_all = dfs[0]for df in dfs[1:]:df_all = pd.merge(df_all, df, on="step", how="outer")# 保存base_name = f.split("events.out.tfevents.")[-1] + ".csv"out_path = os.path.join(outdir, base_name)df_all.to_csv(out_path, index=False)print(f"✅ 导出: {out_path}")# 使用示例
# export_events_to_csv("./logs2", "./logs2/csv_logs") #logs3/stock_prediction_logs
export_events_to_csv("./logs3/stock_prediction_logs", "./logs3/csv_logs") #logs3/stock_prediction_logs
# export_events_to_csv("./logs/2025-09-06_00-40-59", "./logs/csv_logs") #logs3/stock_prediction_logs4.方法二:(去重)
import os
import glob
import pandas as pd
from tensorboard.backend.event_processing import event_accumulatordef export_events_to_csv(logdir, outdir="./csv_logs"):os.makedirs(outdir, exist_ok=True)event_files = glob.glob(os.path.join(logdir, "events.out.tfevents.*"))for f in event_files:ea = event_accumulator.EventAccumulator(f)ea.Reload()dfs = []for tag in ea.Tags()["scalars"]:events = ea.Scalars(tag)df = pd.DataFrame({"Step": [e.step for e in events],tag: [e.value for e in events]})# 🔑 删除相同 step 的重复值df = df.drop_duplicates("Step", keep="last")dfs.append(df)if not dfs:continue# 按 Step 合并df_all = dfs[0]for df in dfs[1:]:df_all = pd.merge(df_all, df, on="Step", how="outer")df_all = df_all.sort_values("Step") # 排序一下base_name = f.split("events.out.tfevents.")[-1] + ".csv"out_path = os.path.join(outdir, base_name)df_all.to_csv(out_path, index=False)print(f"✅ 导出: {out_path}")# 使用
# export_events_to_csv("./logs2", "./logs2/csv_logs")
export_events_to_csv("./logs3/stock_prediction_logs", "./logs3/csv_logs") #./logs/2025-09-06_00-40-59