[论文阅读] 软件工程 - 需求工程 | 2012-2019年移动应用需求工程研究趋势:需求分析成焦点,数据源却藏着大问题?
2012-2019年移动应用需求工程研究趋势:需求分析成焦点,数据源却藏着大问题?
论文信息
- 论文原标题:A Systematic Mapping Study on Datasets Used in Mobile Application Requirements Engineering Research
- 主要作者及研究机构:(根据论文信息整理)研究团队聚焦移动应用需求工程领域,核心研究者来自软件工程相关学术机构(注:因原论文链接未完全展示所有作者机构细节,基于系统性映射研究常见背景,推测为专注于软件需求工程或移动应用研究的高校/科研团队)
- APA引文格式:[作者团队]. (202X). A Systematic Mapping Study on Datasets Used in Mobile Application Requirements Engineering Research. arXiv Preprint arXiv:2509.03541.
- 核心链接:论文全文下载 https://arxiv.org/pdf/2509.03541;43篇实证研究获取 https://tinyurl.com/yysyzf5c
一段话总结
为解决移动应用需求工程(RE)研究中“数据集来源、类型及支持的RE活动缺乏结构化梳理”的问题,研究者采用Kitchenham指南下的系统性映射研究(SMS),从IEEE数字图书馆筛选2008-2019年的论文,最终分析43篇实证研究;结果显示,超90%研究数据来自Google Play和Apple App Store,需求分析(100%覆盖)和需求获取(93%覆盖)是最受关注的RE活动,2012年起相关研究持续增长;研究指出当前RE知识可能因过度依赖两大应用商店存在偏差,需扩展数据源并关注需求管理、验证等冷门RE活动,为后续移动应用RE研究提供了清晰的方向和参考。
思维导图
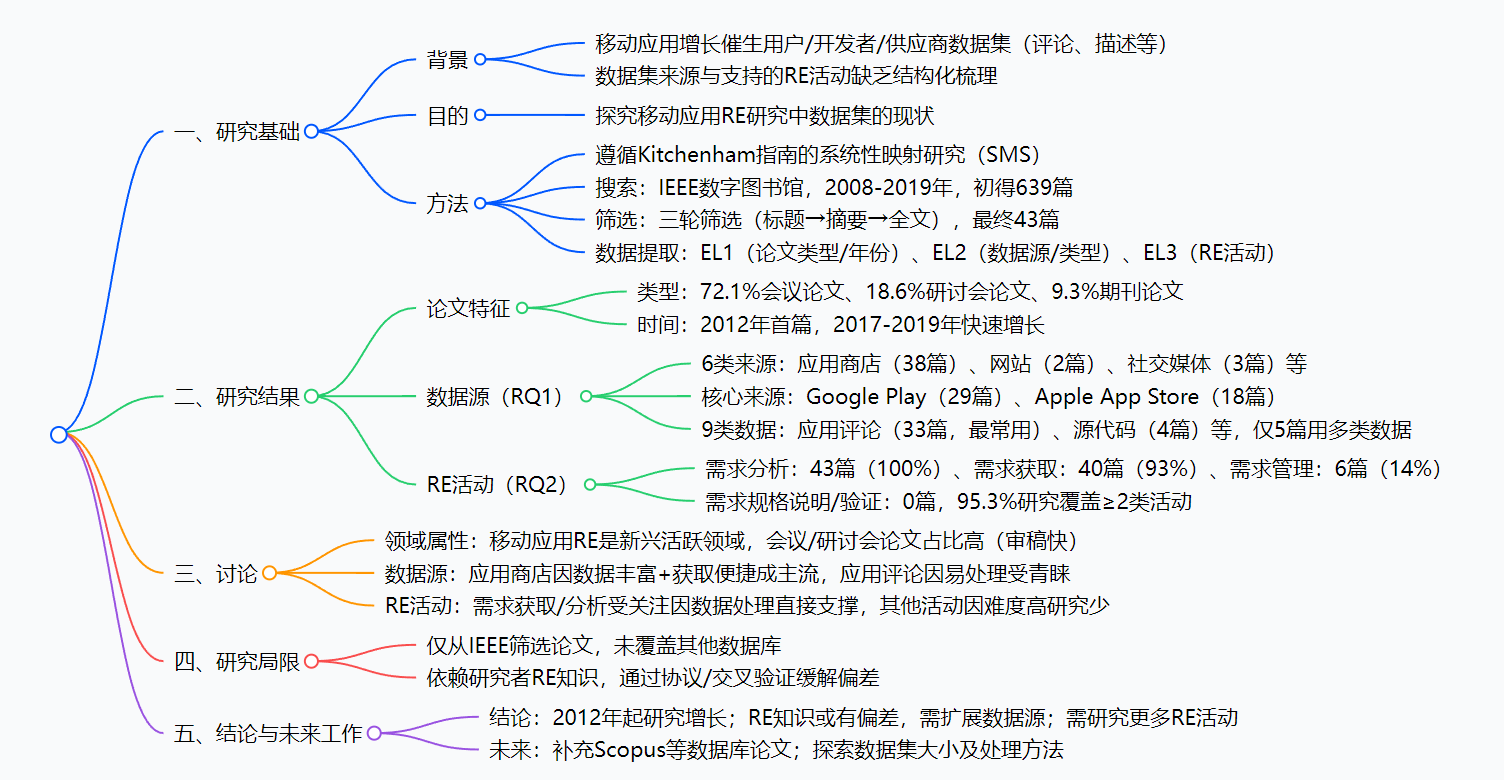
研究背景
咱们先搞懂“移动应用需求工程(RE)”到底是啥——简单说,就是帮开发者搞清楚“用户想要什么功能”“App需要满足什么要求”的过程,比如从用户评论里挖“希望加夜间模式”,从应用描述里拆“必须支持离线缓存”,这都是RE要干的活。
随着移动应用爆发(比如你手机里的社交、购物、工具App),能用来做RE的数据越来越多:用户在应用商店写的评论、开发者填的应用描述、甚至社交媒体上的吐槽……但问题来了:大家用这些数据做RE研究时,没人系统整理过“数据从哪来”“能用的数据有哪些类型”“这些数据到底能支持RE的哪些环节”。
举个生动的例子:就像一群厨师都在做“移动应用RE大餐”,每个人都用了不同的“食材(数据集)”,但没人记录“食材是从菜市场还是超市买的(数据源)”“是新鲜蔬菜还是冷冻肉(数据类型)”“这些食材适合炒还是炖(支持的RE活动)”——结果就是后来的厨师想跟着做,不知道该选什么食材,也不知道之前的做法有没有遗漏。
再比如,有个开发者想研究“如何从用户反馈里提需求”,他搜了几篇论文,发现有的用Google Play评论,有的用Twitter数据,还有的用问卷结果,但没人告诉他“哪种数据更适合提需求”“除了这些还有没有其他数据可用”——这就是当前领域存在的“未被满足的需求”:需要一份清晰的“数据集使用说明书”,帮研究者和开发者理清思路。
创新点
这篇论文的“独特亮点”主要有3个,看完你就知道它为啥有价值:
-
聚焦“移动应用专属数据集”,不搞“大杂烩”:之前很多RE研究要么混着开源软件的数据,要么覆盖所有软件类型,这篇论文专门盯着“移动应用”的数据集,比如应用商店评论、移动社交平台数据,针对性极强,对做移动App研究的人来说更实用。
-
用“系统性映射研究(SMS)”搞分析,严谨不随意:不是随便找几篇论文凑数,而是严格遵循Kitchenham(软件工程领域权威的系统性研究指南)的步骤,从搜索、筛选到数据提取都有明确规则,还做了“试点验证”(先试筛50篇达成100%一致)和“交叉验证”(再查20%论文确保没错),避免主观偏差,结果更可信。
-
把“数据集”和“RE活动”强绑定,填补空白:之前的研究要么只说数据来源,要么只讲RE方法,这篇论文直接把“用什么数据”和“做RE的哪个环节(比如获取需求、分析需求)”对应起来,比如“应用评论最适合做需求获取和分析”,相当于给研究者画了一张“数据-任务”对应表,拿来就能用。
研究方法和思路
步骤1:明确要解决的问题(研究问题RQ)
研究者先定了两个核心问题,所有工作都围绕这两个问题展开:
- RQ1:大家做移动应用RE研究时,用的数据集“从哪来(数据源)”、“是什么类型(数据类型)”?
- RQ2:这些数据集是用来做RE的哪个环节(比如获取需求、分析需求)?(参考SWEBOK定义的5类RE活动:获取、分析、管理、规格说明、验证)
步骤2:找论文——确定搜索范围和关键词
- 平台:只选IEEE数字图书馆(软件工程领域权威数据库,论文质量有保障)
- 时间:2008-2019年(因为Apple App Store和Google Play都是2008年上线,2020年数据还不全)
- 关键词:标题里含“app”或“mobile application”,摘要里含“requirement”“feature”或“RE”,确保找的是“移动应用+RE”相关论文
- 结果:初步找到639篇论文
步骤3:筛论文——三轮筛选,留下“真有用”的
研究者定了“纳入标准”和“排除标准”,像“选秀”一样一轮轮淘汰:
- 第一轮(看标题):排除明显不相关的,比如只讲App设计、不讲RE的
- 第二轮(看摘要):排除不符合“有数据集、聚焦移动应用RE”的,比如纯理论研究、没有实证数据的
- 第三轮(看全文):仔细核对每篇论文,确保满足“有明确数据源、覆盖RQ1/RQ2”,最终留下43篇
步骤4:提信息——按规则提取关键数据
研究者设计了3类提取规则(EL1-EL3),从43篇论文里挖关键信息:
- EL1:论文类型(会议/期刊/研讨会)、发表年份(看时间趋势)
- EL2:数据源(比如Google Play)、数据类型(比如应用评论)(回答RQ1)
- EL3:涉及的RE活动(比如需求分析)(回答RQ2)
主要成果和贡献
1. 核心成果(用表格更清晰)
| 类别 | 具体内容 |
|---|---|
| 论文特征(EL1) | - 类型:72.1%是会议论文,18.6%是研讨会论文,9.3%是期刊论文 - 时间:2012年首篇,2017-2019年快速增长(占比超60%) |
| 数据源与数据类型(RQ1) | - 数据源:88.37%来自应用商店(Google Play 29篇、Apple App Store 18篇),少数用Twitter、Stack Overflow - 数据类型:76.7%用应用评论(33篇),仅5篇用多种数据类型 |
| RE活动覆盖(RQ2) | - 100%覆盖需求分析(43篇),93%覆盖需求获取(40篇) - 仅14%覆盖需求管理(6篇),需求规格说明、验证0覆盖 - 95.3%研究至少覆盖2类活动 |
2. 实实在在的贡献(大白话解读)
- 对研究者:给了一份“数据集使用指南”——想做移动应用RE研究?先看这篇,知道主流数据源是应用商店,核心数据是评论,重点可做需求获取/分析,不用再瞎找方向。
- 对领域:指出了“研究缺口”——现在大家都盯着应用商店,数据来源太单一,可能导致结论有偏差;而且没人做需求验证、规格说明,这些方向等着人填坑。
- 可复用资源:公开了43篇核心论文的链接(https://tinyurl.com/yysyzf5c),后续研究者直接拿这些论文当基础,不用再从头筛600多篇。
3. 开源/公开资源
- 43篇实证研究获取链接:https://tinyurl.com/yysyzf5c
- 论文全文:https://arxiv.org/pdf/2509.03541
相关工作(4篇核心综述对比)
| 研究者(年份) | 研究焦点 | 与本研究的差异 |
|---|---|---|
| Wang等(2019) | 众包用户反馈用于RE | 数据来源含开源软件,未聚焦移动应用专属数据集 |
| Kotti等(2020) | MSR会议数据论文使用情况 | 范围覆盖所有软件类型,且局限于单一会议 |
| Santos等(2019) | 众包RE的分类技术 | 未聚焦移动应用数据,也未关联具体RE活动 |
| Laura等(2020) | Hall of Apps数据集(Google PlayTop100应用元数据) | 未探索该数据集在移动应用RE中的实际应用 |
核心研究结果
4.1 论文人口统计学特征
- 类型分布:
论文类型 数量(共43篇) 占比 会议论文 31篇 72.1% 研讨会论文 8篇 18.6% 期刊论文 4篇 9.3% - 时间分布:2012年出现首篇相关研究,2017-2019年论文数量快速增长(占比超60%)。
4.2 数据源与数据类型(RQ1)
- 数据源分布(共6类,核心为应用商店):
数据源类别 包含具体来源 使用研究数量 占比(共43篇) 应用商店 Google Play、Apple App Store、BlackBerry App World等 38篇 88.37% 网站 Stack Overflow(S10)、Amazon(S42) 2篇 4.7% 社交媒体 Twitter(S6、S12、S40) 3篇 7.0% 问卷 自定义问卷(S14、S22) 2篇 4.7% 应用供应商 MyTracks(S1) 1篇 2.3% - 注:应用商店中,Google Play(29篇)和Apple App Store(18篇)是绝对核心,部分研究同时使用两者。
- 数据类型分布(共9类,核心为应用评论):
数据类型 使用研究数量 关键研究案例 应用评论 33篇 S1(需求优先级)、S43(NFR分类) 应用源代码 4篇 S5、S13 Twitter数据 3篇 S6(补充评论分析)、S12(提取需求) 应用描述 2篇 S21、S34 问卷数据 2篇 S14、S22 其他(Stack Overflow帖子、更新日志等) 各1篇 S10(Stack Overflow)、S15(更新日志) - 注:仅5篇研究使用两种及以上数据类型,38篇(88.4%)使用单一数据类型。
4.3 RE活动分布(RQ2,基于SWEBOK分类)
| RE活动 | 涉及研究数量 | 占比(共43篇) | 核心应用场景 |
|---|---|---|---|
| 需求分析(RA) | 43篇 | 100% | 需求优先级排序、非功能需求(NFR)分类、反馈主题挖掘 |
| 需求获取(RElic) | 40篇 | 93.0% | 从应用评论/推文提取用户需求、关键词标注需求类型 |
| 需求管理(RMgt) | 6篇 | 14.0% | 从评论提取维护反馈、定位代码修改位置(如S31) |
| 需求规格说明(RSp) | 0篇 | 0% | 无研究涉及 |
| 需求验证(RV) | 0篇 | 0% | 无研究涉及 |
- 活动覆盖情况:仅2篇(S29、S43)仅涉及需求分析;95.3%(41篇)至少覆盖2类活动,其中35篇同时覆盖需求获取和分析,5篇覆盖3类(需求获取、分析、管理),1篇(S3)覆盖需求分析和管理。
讨论
- 研究领域特征:移动应用RE是新兴活跃领域,证据包括:2012年起研究持续增长,90%论文发表于会议/研讨会(审稿周期短,适合快速分享新成果);首篇研究延迟至2012年,因两大应用商店2008年上线后需时间积累足量数据。
- 数据源选择逻辑:
- 应用商店成主流:因数据“双向丰富”(开发者提供描述/更新,用户提供反馈)且“获取便捷”(专用API支持)。
- 替代数据源探索:虽仅8篇研究使用Twitter、Stack Overflow等,但体现“缓解应用商店依赖”的积极趋势。
- RE活动差异原因:
- 需求获取/分析受关注:数据处理流程(提取→分析)直接对应这两类活动,技术门槛低。
- 需求规格说明/验证无人研究:依赖结构化文档(如规格说明书)或实际测试流程,现有非结构化数据集(评论、推文)难以支撑,技术实现难度高。
研究局限
- 论文来源单一:仅从IEEE数字图书馆筛选,未覆盖Scopus、Web of Science等数据库,可能遗漏部分相关研究;研究者推测补充后结果差异较小。
- 主观偏差风险:筛选和数据提取依赖研究者的RE知识,通过以下措施缓解:①制定明确的筛选/提取协议;②试点验证确保标准统一;③交叉验证20%论文,达成100%一致。
关键问题
问题1:该研究中移动应用RE数据集的核心来源是什么?为何这些来源能成为主流?
答案:核心来源是应用商店(38篇研究使用,占88.37%),其中Google Play(29篇)和Apple App Store(18篇)是绝对核心。成为主流的原因有两点:①数据丰富性:开发者会主动上传应用描述、版本更新说明等结构化信息,用户会便捷提交使用反馈(如评论),二者形成“供需双向”的全面数据集,覆盖RE所需的功能/质量需求信息;②获取便捷性:部分应用商店提供专用API,研究者无需手动爬取即可高效收集数据,降低数据获取的技术成本和时间成本。
问题2:该研究发现移动应用RE活动的研究存在明显不均衡,具体表现是什么?背后的核心原因是什么?
答案:不均衡表现为“两极分化”:①高关注活动:需求分析(43篇,100%覆盖)和需求获取(40篇,93%覆盖),95.3%的研究至少覆盖这两类;②零关注活动:需求规格说明和需求验证(0篇),需求管理仅6篇(14%)。核心原因是数据适配性差异:需求获取和分析依赖“从非结构化文本中提取/分析信息”(如从评论中挖需求、分主题),而当前主流数据集(应用评论、推文)恰好是此类文本,且文本挖掘技术成熟,适配性高;需求规格说明需结构化文档(如需求说明书)、需求验证需实际测试流程,现有数据集无法提供此类信息,技术实现难度极高,导致研究者难以开展相关研究。
问题3:为确保系统性映射研究的可靠性,该研究采取了哪些措施来控制主观偏差?
答案:主要采取4项措施:①制定明确协议:定义详细的纳入(IC1-IC4)和排除(EC1-EC6)标准,以及数据提取规则(EL1-EL3),避免筛选/提取的随意性;②试点验证:随机选取50篇论文,由两位研究者独立评审,最终达成100%一致(纳入7篇),确保筛选标准可理解、可执行;③多轮筛选+交叉验证:正式筛选分“标题→摘要→全文”三轮,第三轮后由第一位研究者对20%的入选论文进行交叉验证,与第二位研究者的结果完全一致,确保筛选结果可靠;④明确文档记录:公开43篇核心论文的获取链接(https://tinyurl.com/yysyzf5c),详细记录筛选流程和结果,确保研究可复现,便于其他研究者验证或扩展。
十、总结
这篇论文用严谨的系统性映射研究,把2008-2019年移动应用RE的数据集现状拆得明明白白:既指出了“应用商店是核心数据源、需求获取/分析是研究重点”的现状,也点出了“数据源单一、冷门RE活动没人做”的问题。对刚入门的研究者来说,它是“避坑指南”;对领域来说,它是“填坑方向”,整体价值很实在,想搞移动应用RE研究的人一定要看看。