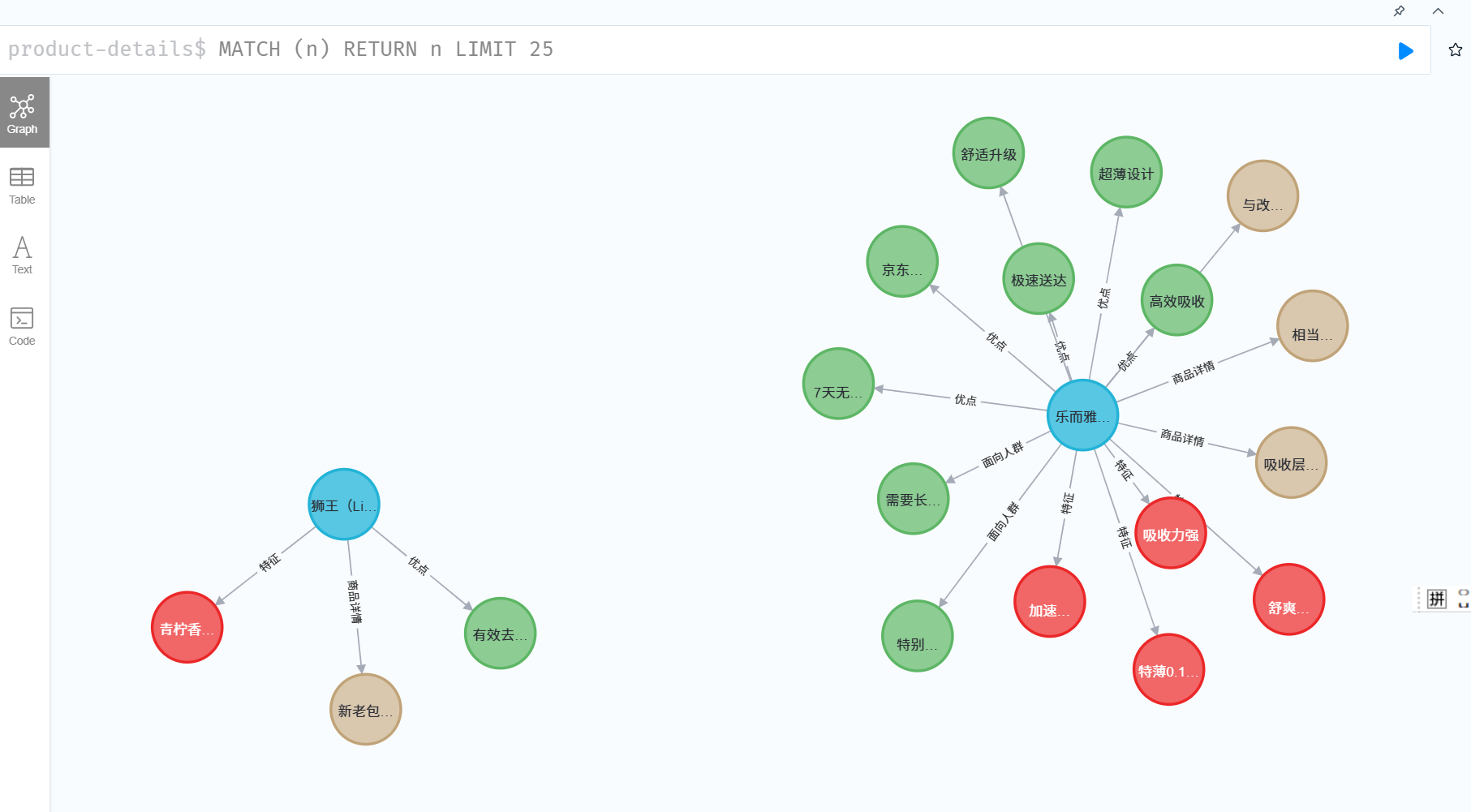
【大模型理解消化的搅碎机】基于6000种商品CSV表格的知识图谱构建
1. graphRAG前菜:
Graph RAG 即图增强检索生成(Graph - Augmented Retrieval Augmented Generation),它是在检索增强生成(RAG)基础上结合图数据库的一种技术。
1.2 检索增强生成(RAG):
RAG 是一种将外部知识源与大语言模型(LLM)相结合的技术。传统的大语言模型依赖于预训练时学到的知识,可能存在知识过时或不完整的问题。RAG 通过在生成回答之前,先从外部知识源(如文档数据库)中检索相关信息,然后将这些信息与用户的问题一起输入到语言模型中,从而生成更准确、更具时效性的回答。
1.3 图增强检索生成(Graph RAG):
Graph RAG 在 RAG 的基础上引入了图数据库。图数据库以图的结构来存储数据,包含节点(代表实体)和边(代表实体之间的关系),能够更自然地表示复杂的关系数据。Graph RAG 利用图数据库的特性,更好地挖掘和利用数据之间的关系,为大语言模型提供更丰富、更具关联性的上下文信息。
2. 工具与所需文档
- neo4j 和 数据库表格文档
3. 代码:
from py2neo import Node, Relationship, Graph, NodeMatcher, RelationshipMatcher
import webbrowser
import csv
def read_csv_line_by_line(file_path):res = []with open(file_path, 'r', newline='', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)for i, row in enumerate(reader):if i != 0:special = ['```json\n', '```']for _ in special:if _ in row[1]:row[1] = row[1].replace(_, "")res.append(eval(row[1]))return resres = read_csv_line_by_line('/www/reconstruction_res.csv')graph = Graph('http://localhost:7474/', user='test', password="****************", name='product-details')
for i, product in enumerate(res):product_name, product_features, product_details, product_strengths, product_fit_person = "", [], [], [], []if '商品名称' in product.keys():product_name = product['商品名称']if '商品特征' in product.keys():product_features = product['商品特征'].split(",")if '商品注意详情' in product.keys():product_details = product['商品注意详情'].split(",")if '商品优势' in product.keys():product_strengths = product['商品优势'].split(",")if '适合人群' in product.keys():product_fit_person = product['适合人群'].split(",")if product_name != "":product = Node('商品名称', name=product_name)graph.create(product)if product_features != []:for _ in product_features:feature = Node('商品特征', name=_)graph.create(feature)relationship = Relationship(product, "特征", feature)graph.create(relationship)if product_details != []:for _ in product_details:details = Node('商品注意详情', name=_)graph.create(details)relationship = Relationship(product, "商品详情", details)graph.create(relationship)if product_strengths != []:for _ in product_strengths:strengths = Node('商品优势', name=_)graph.create(strengths)relationship = Relationship(product, "优点", strengths)graph.create(relationship)if product_fit_person != []:for _ in product_fit_person:fit_person = Node('商品优势', name=_)graph.create(fit_person)relationship = Relationship(product, "面向人群", fit_person)graph.create(relationship)
matcher = NodeMatcher(graph)
match1 = matcher.match("商品名称") # 查询结点
for _ in match1:print(_)
4. 结果展示