Abstract
本文提出了一种新颖的视图合成和3D场景表示方法,用于为计算机断层扫描(CT)生成新的投影视图。
方法采用了Gaussian Splatting 框架,基于有限的2D图像投影集,无需运动结构(SfM)方法,在CT中实现新颖视图合成。因此,我们减少了总扫描持续时间和患者在扫描期间接受的辐射剂量。
我们调整了损失函数来适应我们的任务,即通过使用两个稀疏性促进正则化项来鼓励更强的背景和前景区分(beta loss 和 TV loss)。最后,我们使用均匀的先验分布来初始化3D空间中的高斯位置,这个先验分布表示大脑的位置在视野内可能的位置。模型性能评估使用了脑部CT数据集,并证明了渲染的新视图和模拟扫描的原始投影视图密切匹配,并且比其他隐式3D场景表示方法表现更好。此外,和基于神经网络的稀疏视图CT图像重建相比,实验观察到训练时间减少了。最后,和等效的体素网格图像表示相比,高斯splatting的表示所需的内存减少了17%。
Contributions
- 引入了GaSpCT,一种隐式(译者注:是不是说错了,3DGS是显式表达)3D场景表示和新颖的视图合成模型,允许从有限的投影数据集渲染新颖的CT大脑投影,该模型占用的内存较小,而且渲染新视图的计算成本较低。
- 在CT成像中,预计未被患者占据的像素将具有空或背景强度值。为了提高合成视图的平滑性和稀疏性,我们增强了3DGS中使用的基线损失函数,添加了总变分损失(TV loss)和Beta分布负对数似然损失。
- 引入了一个脚本将CT相机参数近似为针孔相机的参数,从重建图像 医学数字成像和通信元数据中提取CT相机参数。因此消除了运动结构(SfM)的必要性,由于缺乏明显的边缘,SfM在CT照片上表现不佳。此外,我们的方法还初始化了代表预期患者脑容量的椭球3D点云。
- 我们对脑部CT投影图像上的隐式3D场景表示进行了首次验证,冰箱医学生成社区提供所有使用的数据集。
方法
GaSpCT
模型基于Gaussian Splatting,针对CT脑扫描调整了该模型,在损失函数中添加了两个促进稀疏性的正则化器,并将点云初始化为椭球体(类似于大脑结构)。
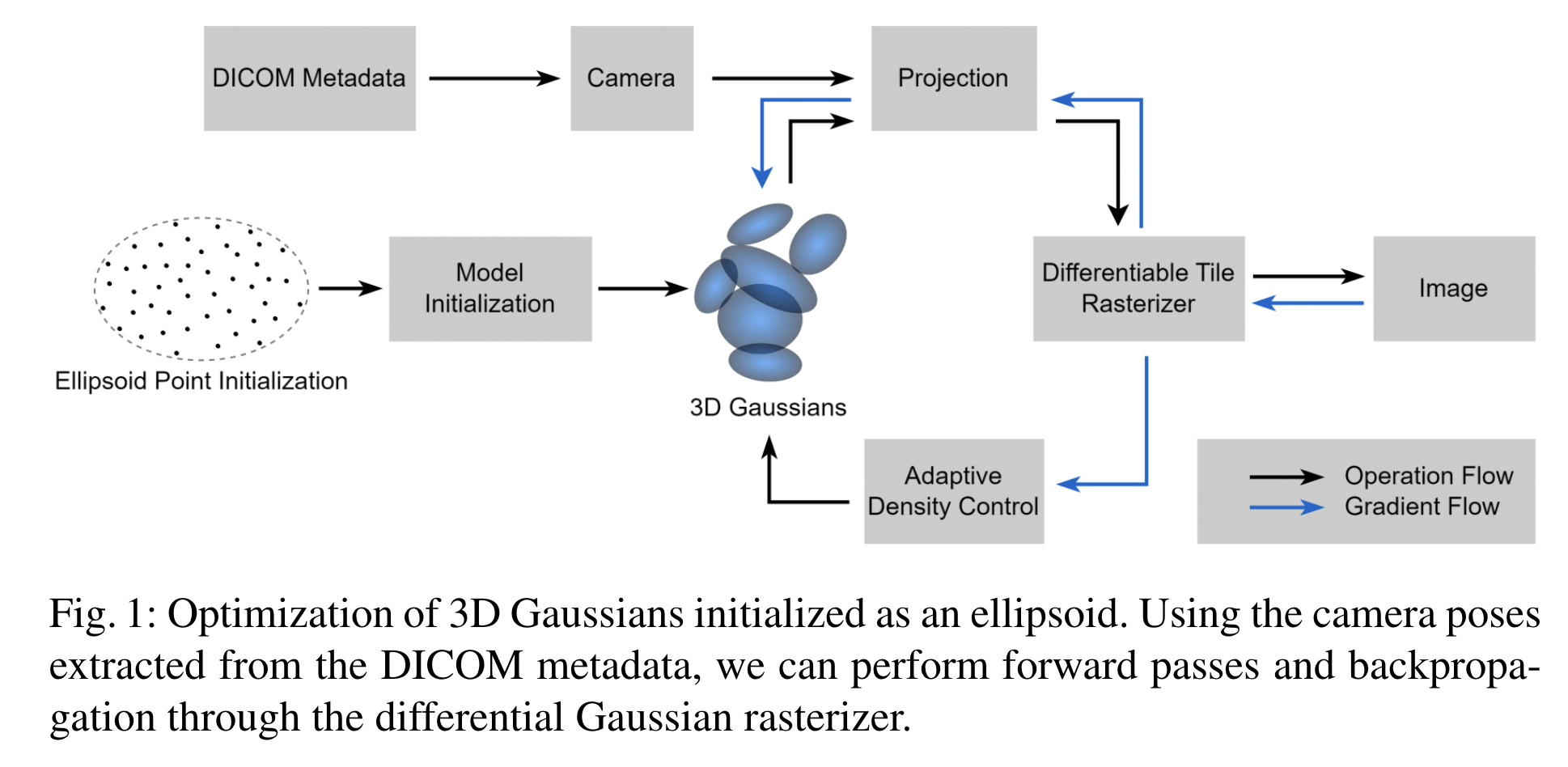
Gaussian Splatting
原始的Gaussian Splatting模型中三维场景被编码为3D高斯。每个Guassian由38个参数组成,包括位置、协方差、颜色和不透明度。在优化期间,从训练集分布中采样2D图像和相机姿态。通过使用可微高斯光栅化器,可以从给定姿势的点云渲染等效图像。计算渲染图像和真实图像之间的损失,并使用Adam优化器对损失函数的梯度执行反向传播。原始的损失函数是:
L o r i g i n a l = ( 1 − λ ) L 1 + λ L D _ S S I M L_{original}=(1-\lambda)L_1+\lambda L_{D\_SSIM} Loriginal=(1−λ)L1+λLD_SSIM
Total Variation Regularization: 我们加入了总变分损失。 TV惩罚了相邻像素之间的较大变化,增强图像的平滑度同时减少噪声伪影的影响。
L T V = λ T V ∑ i , j N , M ∣ p i + 1 , j − p i , j ∣ + ∣ p i , j + 1 − p i , j ∣ L_{TV}=\lambda_{TV}\sum_{i,j}^{N,M}|p_{i+1,j}-p_{i,j}|+|p_{i,j+1}-p_{i,j}| LTV=λTVi,j∑N,M∣pi+1,j−pi,j∣+∣pi,j+1−pi,j∣
其中p表示坐标i,j处的像素值。N、M分别是图像的高度和宽度。
Beta 分布正则化器 :我们采用Beta分布的负对数似然。这种损失通过将背景值推至0并增强前景的像素强度来促进稀疏性。
L b e t a = 1 / P ∑ p [ l o g ( I α ( p ) ) + l o g ( 1 − I α ( p ) ) ] L_{beta}=1/P\sum_p[log(I_{\alpha}(p))+log(1-I_{\alpha}(p))] Lbeta=1/Pp∑[log(Iα(p))+log(1−Iα(p))]
P是总像素数量, I α I_{\alpha} Iα是图像不透明度。
总损失函数:
L f i n a l = λ 1 L 1 + λ D _ S S I M L D _ S S I M + λ T V L T V + λ b e t a L b e t a L_{final}=\lambda_1L_1+\lambda_{D\_SSIM}L_{D\_SSIM}+\lambda_{TV}L_{TV}+\lambda_{beta}L_{beta} Lfinal=λ1L1+λD_SSIMLD_SSIM+λTVLTV+λbetaLbeta
实验
数字重建放射图像: 通过输入从DICOM元数据检索的视野、患者和扫描仪参数,使用3D DICOM图像作为输入体模来模拟CT扫描。DRR的输出是一组新的投影图像。我们生成角度分辨率为1度的360°投影视图。图像大小128*128。该程序用于为不同患者的20次CT脑部扫描生成DRR,以捕获不同人之间的解剖变异性。
Structure from Motion 在 CT图像上的挑战: Gaussian Splatting需要SfM软件的输出作为训练脚本的输入。包括相机内外参和表示3D场景中已识别特征的点云。然而将SfM应用与CT图像尤其具有挑战性。这是放射密度在重建的投影图像上逐渐变化的结果。因此,明显缺乏精致的边缘和良好的细节,这将影响准确和鲁邦的特征提取。
CT图像的相机外参和内参:
我们使用DICOM元数据提供的有关CT扫描参数的先验知识,以数学方式生成相机内参和外参。我们检索的变量是成像空间的视场FOV,探测器阵列的尺寸以及源到探测器和患者的距离。这些变量用于计算每个相机位姿的笛卡尔坐标(x,y,z)。姿态之间的polar angle增量与CT数据集的角分辨率相同,而方位角(azimuth angle)保持固定为0(假设我们将世界坐标的原点设置在CT FOV的中心)。
设置
在单个 NVIDIA RTX A4000上运行。
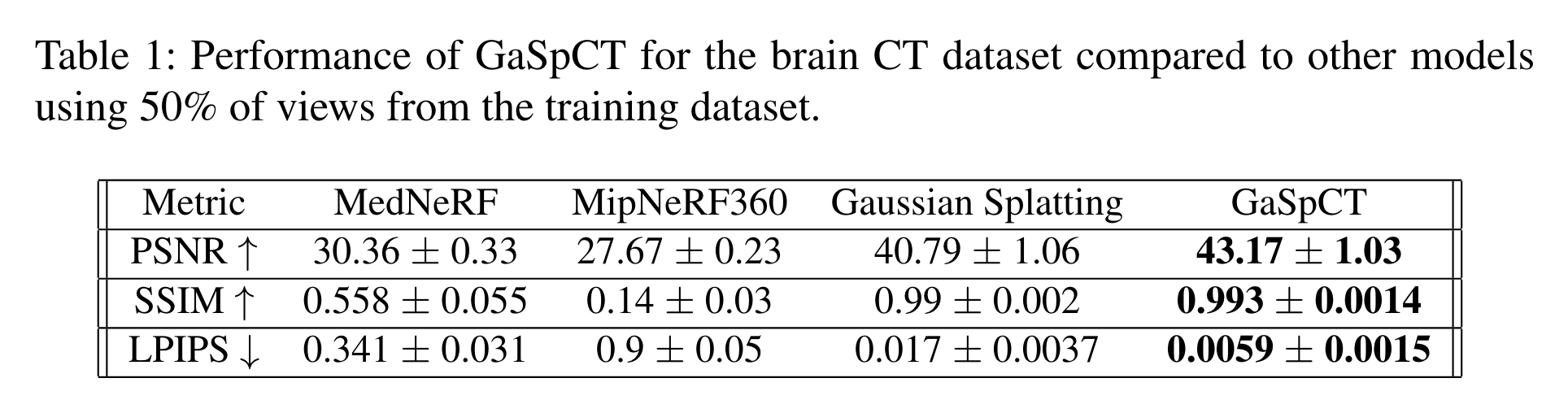
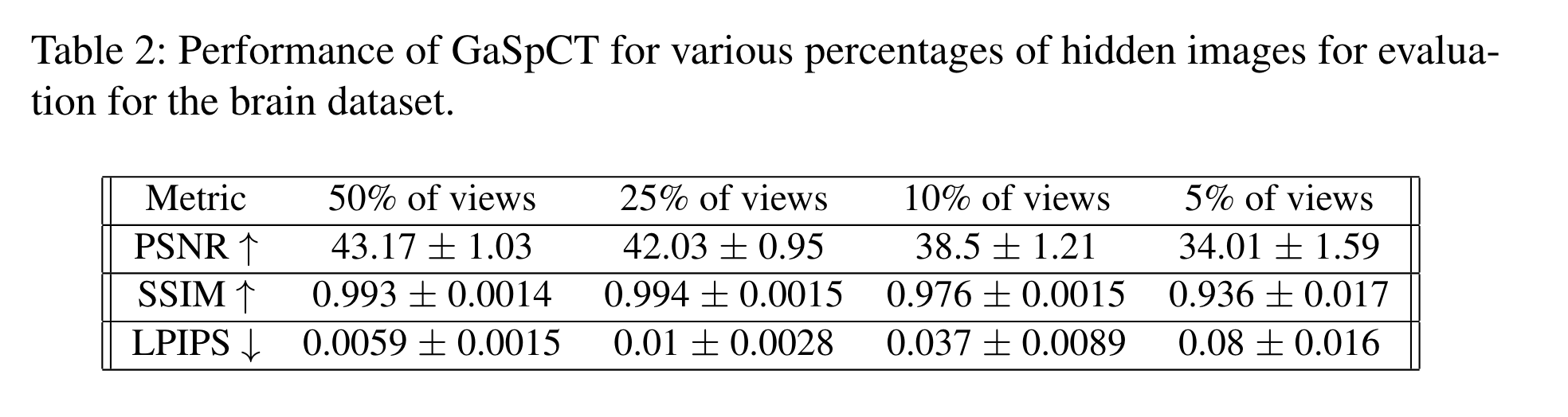
结果
评价指标:
- PSNR
- SSIM
- LPIPS(Learned Perceptual Image Patch Similarity)
每次扫描的优化过程需要5-10分钟。
Future work
- 下一步的重要工作是编写一种新型相机,和基于弯曲正交平面的CT成像中的探测器阵列紧密匹配。这种近似比我们当前的针孔相机近似要准确地多;
- 此外,值得研究和调整SfM方法中的边缘检测和特征提取,以准确定义初始点云;
- 研究使用高斯泼溅表示来表示多种医学扫描的潜力。








![[牛客网]——C语言刷题day3](https://img-blog.csdnimg.cn/direct/9c77aa01fd304b11a0e1020f76cdc9b2.png)