视觉语言导航(2)——VLN RNN TRANSFORMER 与ATTENTION 2.2+LSTM(单独一节)
这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
上一节讲了如何处理单幅图像问题,这节讲如何处理连续的图像/视频的问题——递归神经网络RNN
循环神经网络 •长短期记忆(LSTM) •门控循环单元(GRU) •文本生成演示(字符RNN) •变压器 •预训练大型语言模型 •摘要
如何处理序列数据?
科学家们发明了一些聪明的工具:
自动回归模型:根据前几天的温度预测明天温度
循环神经网络(RNN):像人有短期记忆,能记住前文理解后文
Transformer:更先进的模型,能同时关注序列中【所有】重要部分
【递归神经网络的运作流程】
每个数据都是前面数据的迭代,作为输入,输出就是后一个x!



自然变成了线性回归
但是,线性回归的输入是独立的,但序列数据输入是连续且互相关联的
因此不能用线性回归的方法做,而应该使用有feedback的RNN循环神经网络。
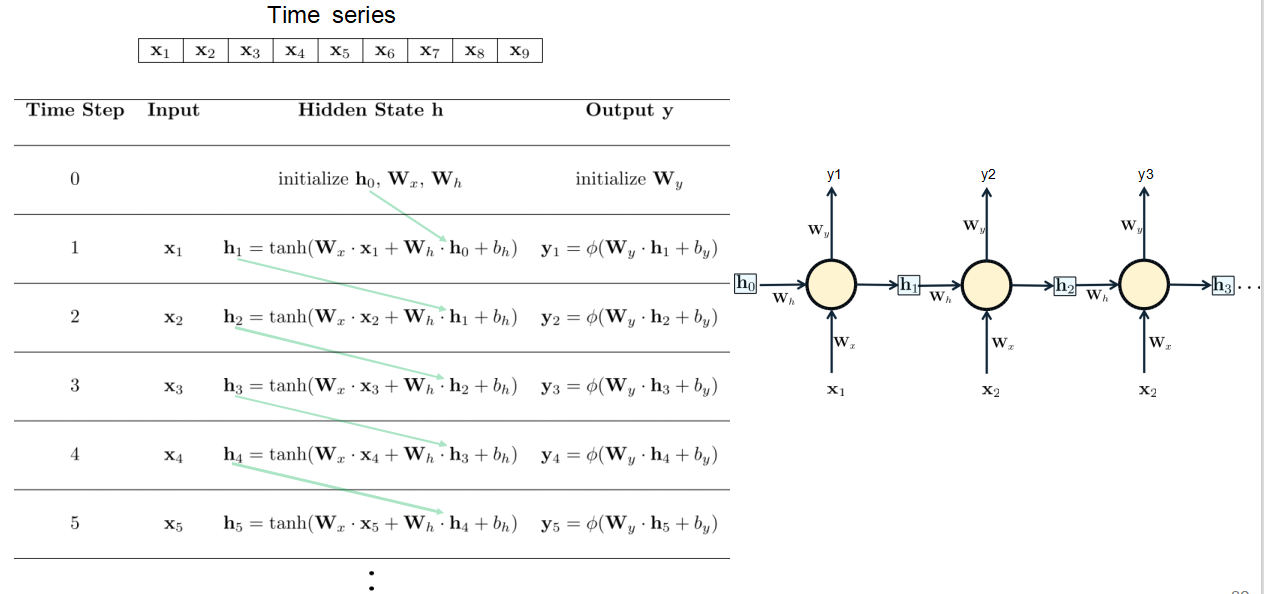
记忆更新公式:
ℎₜ = tanh(𝑊ₓ·𝑥ₜ + 𝑊ₕ·ℎₜ₋₁ + 𝑏ₕ)
把新输入(𝑥ₜ)和上次记忆(ℎₜ₋₁)混合
通过tanh函数压缩到-1到1之间(防止数字过大)
输出公式:
𝑦ₜ = φ(𝑊ᵧ·ℎₜ + 𝑏ᵧ)
根据最新记忆生成输出
φ可能是softmax(分类)或sigmoid等函数
【三种经典变体】
作用:决定RNN如何"记忆"和"遗忘"信息。
基础RNN:简单循环结构,记忆能力有限。
LSTM:通过"门控机制"(输入门、遗忘门、输出门)选择性记忆长期信息。
GRU:简化版LSTM,只有更新门和重置门,计算效率更高。
【三种应用场景设计】
1. 序列→序列(Sequence-to-Sequence)
例子:实时语音转文字
输入:连续语音信号(时间序列)
输出:实时显示的文字流
特点:每个时间步都有对应输出
2. 序列→向量(Sequence-to-Vector)
例子:情感分析
输入:一个完整评论(单词序列)
输出:最终的情感判断(正面/负面)
特点:只看最后输出的总结结果
3. 向量→序列(Vector-to-Sequence)
例子:图片自动描述
输入:一张图片(编码为向量)
输出:描述图片的句子
特点:从静态信息生成动态序列
编码器-解码器架构
工作原理:
编码器:像压缩文件一样把输入序列"打包"成一个浓缩向量(上下文向量)
解码器:用这个浓缩向量"解压"生成输出序列
实际过程比喻:
编码器像学生上课记笔记,把老师讲的内容提炼成关键词
解码器像课后根据关键词复述课堂内容
为什么需要这种设计:
普通RNN的局限:
输入输出长度必须相同
难以处理长距离依赖
Encoder-Decoder的优势:
可以处理不等长的输入输出(如中英文句子长度不同)
通过中间向量保留完整语义
现在最先进的Transformer模型也基于这个思想
就像专业翻译会先完整理解原文意思,再用另一种语言重新表达,而不是逐词翻译。
【RNN训练】
1. 前向传播(展开时间)
时刻1:h₁ = f(x₁, h₀)
时刻2:h₂ = f(x₂, h₁)
...
时刻n:hₙ = f(xₙ, hₙ₋₁)
让网络看到完整时间线,计算最后一帧的输出
2. 损失计算(以Seq2Vec为例)
只关心最后一个输出:Loss = L(yₙ, ŷₙ)
或Loss = ½(y₃ - ŷ)²
其他时刻输出可能被忽略(如图中Y₁-Y₈可能不参与计算)
3.优化更新
优化的权值一个是前一刻对后一刻的影响Wt,一个是这一刻的输入对这一刻的输出的影响Wx
因此每一刻都是共享同一组Wt Wx的
那么计算一个3秒的反向传播
h₁ = tanh(Wₓ·x₁ + Wₕ·h₀)
h₂ = tanh(Wₓ·x₂ + Wₕ·h₁)
h₃ = tanh(Wₓ·x₃ + Wₕ·h₂)
y₃ = Wᵧ·h₃
链式求导
计算对Wₕ的梯度:
∂L/∂Wₕ = ∂L/∂y₃ · ∂y₃/∂h₃ · [∂h₃/∂Wₕ + ∂h₃/∂h₂·∂h₂/∂Wₕ + ∂h₃/∂h₂·∂h₂/∂h₁·∂h₁/∂Wₕ]
梯度来自三个时间步的贡献之和
接着梯度下降去更新就行了。
【梯度消失/梯度爆炸的处理】
早期时刻的梯度指数级衰减/增长(0.9ⁿ→0或1.1ⁿ→∞)
解决方案:
梯度裁剪(设置梯度最大值(如1.0),超过就按比例缩小)
截断BPTT(只回溯部分时间步)
使用LSTM/GRU(缓解消失)
LSTM
核心机制:
三道门控:
遗忘门:决定丢弃哪些记忆("这个信息没用,忘记吧")
输入门:决定存储哪些新信息("这个知识点要记住")
输出门:决定输出哪些记忆("现在该用这个知识回答问题")
GRU——"精简版LSTM"
核心机制:
两道门控:
重置门:决定忽略多少历史信息("之前的内容有多少相关")
更新门:决定新旧信息的混合比例("用多少新信息更新记忆")
LSTM和GRU就像给RNN装上了"记忆流量控制阀",让梯度可以自主选择捷径流动,避免被连续乘法稀释(消失)或放大(爆炸)。
细节可以参考我的CSDN:https://mp.csdn.net/mp_blog/creation/editor/149977581
实际用例
NLP
核心任务三要素
1. 理解语言(Understanding)
分词:把句子拆成有意义的单元
例句:"我爱人工智能" → ["我", "爱", "人工智能"]
词性标注:识别每个词的语法角色
示例:"学习/NN 编程/VB"(NN=名词,VB=动词)
语义分析:理解真实意图
例句:"空调怎么不制冷了?" → 需要维修服务
2. 处理语言(Processing)
情感分析:判断文本情绪
应用:分析商品评论是好评还是差评
实体识别:抓取关键信息
示例:"北京时间明天9点" → {时间: 明天9点, 地点: 北京}
3. 生成语言(Generation)
文本生成:根据输入产生新内容
应用:自动写新闻摘要
机器翻译:跨语言转换
示例:"Hello world" → "你好,世界"
NLP的最基础方法:字符级RNN
第一步:给字母编号(向量化)
'a'=2,'c'=3,'e'=4...
未知字符(如'&')统一标为1
"each" → [4,2,3,5](e=4,a=2,c=3,h=5)
第二步:训练模型(学规律)
电脑通过大量文本学习:
"a"后面经常接"p"(apple)
"q"后面总是"u"(queen)
空格后常跟大写字母
第三步:生成文本(玩游戏)
你输入开头:"art"
电脑:
计算"a"→"r"→"t"后最可能字母是"i"(80%概率)
但随机选择时可能选"i"或"s"(arts/artisan)
输出新字母组合:"arti"
继续这个过程直到生成完整单词
文本生成的"策略选择"
方法 与之前步骤的关系 适用场景
贪心采样 直接使用训练阶段学到的最高概率输出 需要确定性的场景
随机采样 完全依赖模型输出的原始概率分布 创意写作/头脑风暴
Top-k采样 在向量化词汇表基础上筛选可能性 平衡质量与多样性
Top-p采样 动态调整候选词范围 长文本生成
束搜索 考虑多步序列的全局最优 机器翻译/正式文本
技术迭代:
双向RNN:拥有"前后文视野"的升级版RNN
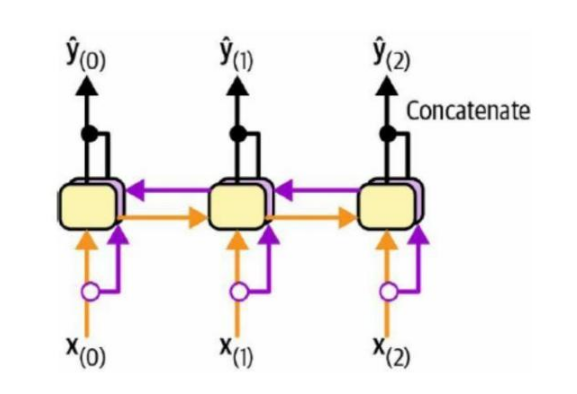
正向处理:"今→天→天→气→真→好"
反向处理:"好←真←气←天←天←今"
最终综合双向信息
正向LSTM:从左到右读取文本(理解上下文)
反向LSTM:从右到左读取文本(捕捉后续影响)
神经机器翻译(NMT):现代翻译官的技术内核
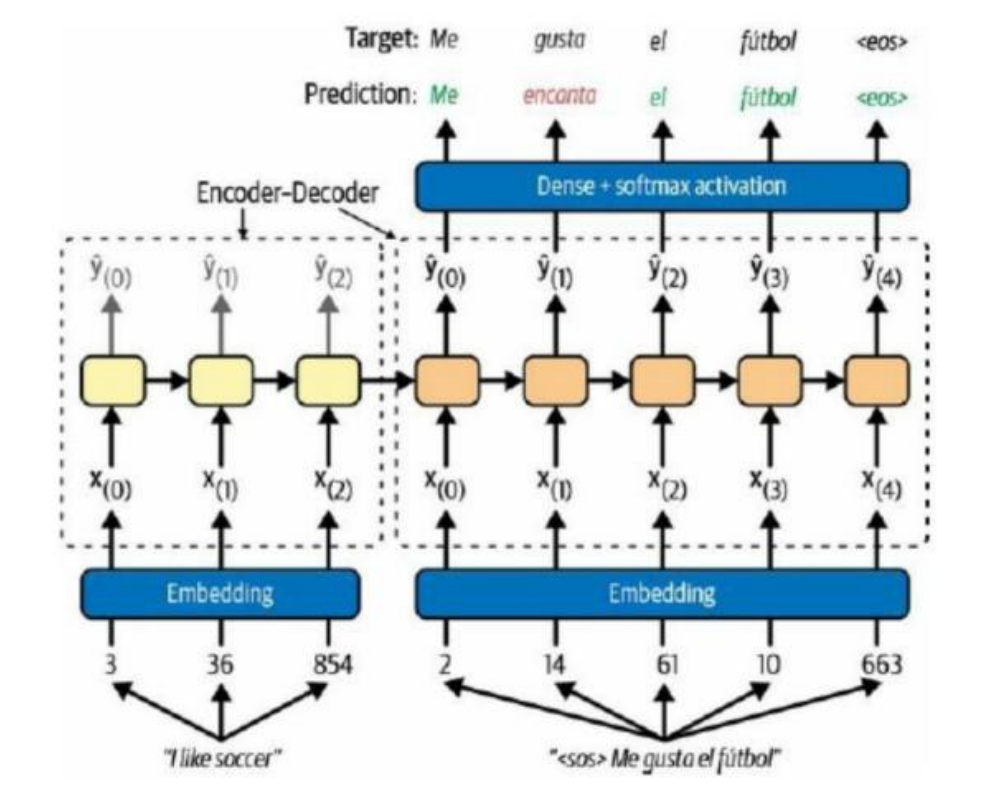
[编码器](双向RNN) → [语义向量] → [解码器](单向RNN)
编码阶段:将源语言(如中文)压缩为"语义密码"
输入:"你好" → 编码为向量[0.2, -1.3, 5.4,...]
解码阶段:将密码解压为目标语言(如英文)
向量 → 逐步生成"Hello"
但是,以上的传统模型还是有很大缺陷:
| 特性 | RNN/LSTM | Transformer |
|---|---|---|
| 处理距离 | 受限于记忆长度 | 任意距离依赖 |
| 训练速度 | 需顺序计算(慢) | 完全并行(快10倍+) |
| 长文本理解 | 容易遗忘早期信息 | 全局注意力机制 |
| 硬件利用率 | 难以充分并行 | 完美利用GPU/TPU |
因此提出了突破性的:
TRANSFORMER
有两种模型——翻译模型 预测模型
注意力机制
QKV机制:
Q:提问对象 K:回应对象 V:具体回应内容
K是用来回应Q的提问/匹配与K的关联紧密程度的,而V则是真正用于更新Q的!
- Key (K) 和 Query (Q) 的作用主要是找到输入数据中与任务最相关的部分。
- Value (V) 则包含了实际需要提取和利用的信息内容
每个词都会在Embedding嵌入时被赋予一个初始向量,通过QKV机制动态适配不同语境(更新向量适配环境)
比如bank=[0.3, -0.1, 0.5],如果在金融领域 we deposit at bank,此时bank作为Q,会找和他相关的K——deposit,读取V:银行是用来存钱的,变为[0.8, 0.2, -0.3](关注“存钱”) ;
如果在地理领域 a dock near a bank,此时bank作为Q,会找和他相关的K——dock,读取V:一个在河边的码头,变为[0.1, 0.6, 0.4](关注“码头”)
二者只是对bank在不同语境做出了不同的更新,并没有改变原来的bank向量。
QKV生成的向量依赖句子中的所有其他词,是临时存储的。而原来的bank则是固定的。
这样也解决了一词多义的问题,让AI理解语境的概念。
翻译任务
编码阶段(理解中文)
输入处理:
"输入句子拆解"
["我", "爱", "人工智能"]
→ 词向量:[[0.3,0.1], [0.5,0.2], [0.8,0.4]] # 2维简化示例
→ 加位置编码:[[0.31,0.12], [0.54,0.23], [0.82,0.43]]自注意力计算(以"爱"为例):
" 生成Q,K,V(假设权重矩阵W_q=[[1,0],[0,1]],单位矩阵简化计算)"
Q_爱 = [0.54,0.23] # "爱"的提问向量
K_我 = [0.31,0.12] # "我"的摘要向量
K_人工 = [0.82,0.43] # "人工智能"的摘要向量" 计算注意力分数"
score_爱→我 = Q_爱·K_我 / √2 = (0.54*0.31 + 0.23*0.12)/1.41 ≈ 0.14
score_爱→人工 = Q_爱·K_人工 / √2 ≈ 0.42
" Softmax归一化"
weights = softmax([0.14, 0.42]) ≈ [0.45, 0.55] # "爱"更关注"人工智能"" 生成新向量"
V_我 = [0.3,0.1] # "我"的完整信息
V_人工 = [0.8,0.4] # "人工智能"的完整信息
new_爱 = 0.45*V_我 + 0.55*V_人工 ≈ [0.57, 0.26] "融合后的新向量"最后这里新的“爱”向量 0.57=0.3*0.45+0.8*0.55 0.26=0.1*0.45+0.4*0.55
是由匹配上K的V构成的!
2. 解码阶段(生成英文)
逐步生成:
输入
<start>,预测第一个词:计算与编码向量的注意力,发现"我"对应"I"概率最高(75%)
已生成"I",预测下一个词:
"爱"的编码向量[0.57,0.26]最接近"love"的嵌入向量
已生成"I love",预测下一个词:
"人工智能"的编码向量[0.82,0.43]匹配"AI"概率70%
预测任务:
目标:续写"我爱人工智能" → "因为它很强大"
1. 编码阶段(分析输入)
自注意力计算(简略版):
"人工"与"智能"的注意力权重=0.9(强绑定)
"爱"的情感分数=+0.8(正面)
2. 生成阶段
第一步:计算<start>与输入的注意力:
最关注句尾"人工智能"(权重0.6),预测连接词"因为"(概率60%)
第二步:已生成"因为",计算下一个词:
注意力聚焦"人工智能" → 选择代词"它"(概率50%)
第三步:已生成"因为它",计算下一个词:
结合正面情感,选择"很"+"强大"(概率40%)
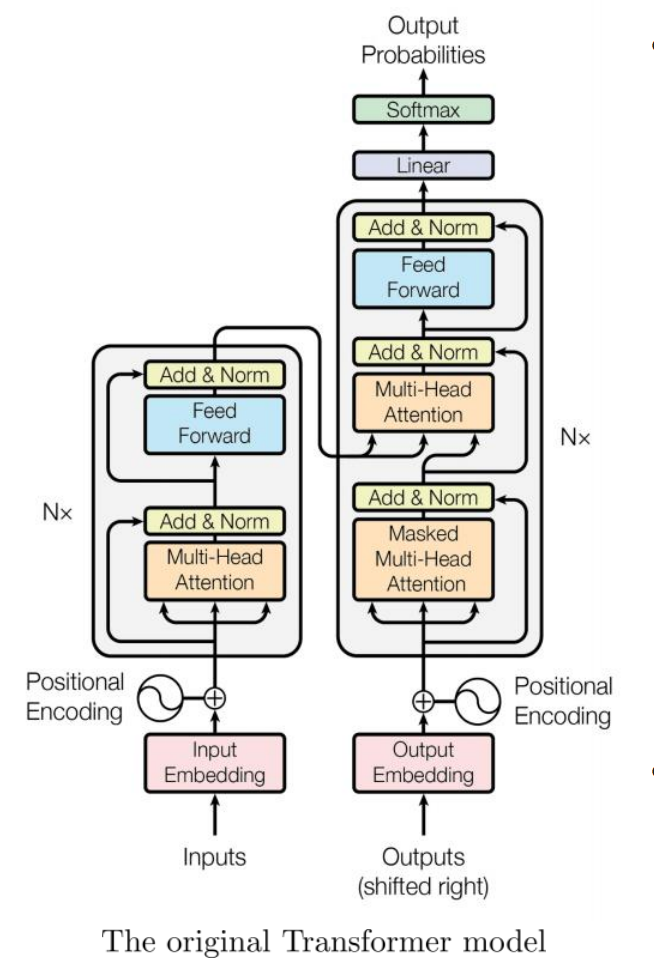
上述过程就是Transformer的流程
核心特点:
✅ 并行处理:像多线程工作,不用等前一个词算完再算下一个(RNN是自回归,必须接受上一个词的输入才能计算,而transormer直接可以对其他所有词进行关注)
✅ 自注意力机制:让每个词都能“关注”句子中的其他词
✅ 无递归结构:避免 RNN 的“遗忘症”(长距离依赖问题)
请先跳过这部分细节讲解,阅读注意力机制部分,再最后跳转回来(这里只是为了逻辑结构严谨把transformer放在技术迭代的最后一项)
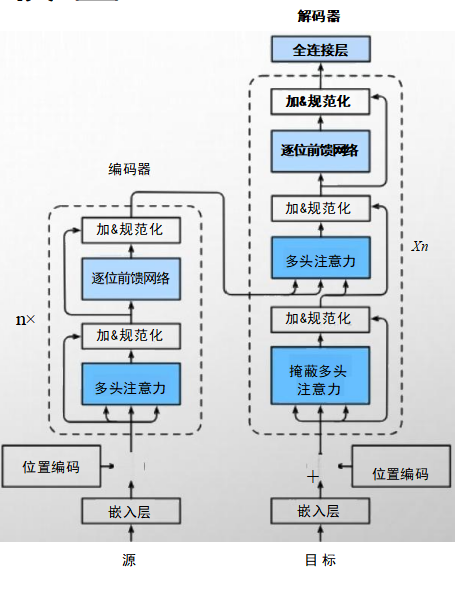
编码器部分
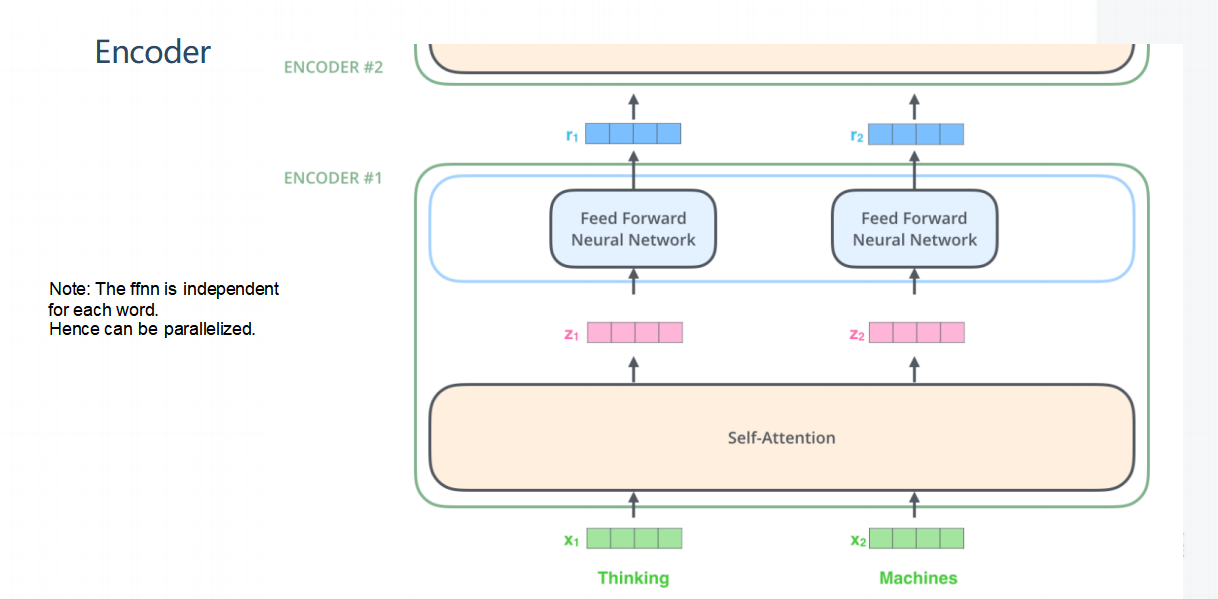
1. 输入序列
- 图中展示了两个输入词“Thinking”和“Machines”,分别表示为向量x1x1和x2x2。这些向量通常是通过嵌入层(Embedding Layer)将原始文本转换成固定长度的数值向量得到的。
2. 自注意力机制(Self-Attention)
自注意力机制是Transformer的核心组件之一,它允许模型在处理每个词时,能够关注到句子中的其他词,从而捕捉到词与词之间的依赖关系。
- 在图中,x1x1和x2x2被送入自注意力层进行处理,输出为新的向量z1z1和z2z2。这些向量包含了输入词自身的信息以及与其他词的相关性信息。
3. 前馈神经网络(FFNN)
经过自注意力机制处理后的向量z1z1和z2z2会被送入前馈神经网络进行进一步的特征变换。
前馈神经网络是一个全连接的两层神经网络,对于每个词的向量独立地进行计算,因此可以并行化处理,提高了计算效率。
在图中,z1z1和z2z2经过FFNN后,分别得到了最终的输出向量r1r1和r2r2。
4. 多层编码器堆叠
图中还展示了多个编码器层(ENCODER #1 和 ENCODER #2)的堆叠。每一层编码器都包含一个自注意力机制和一个前馈神经网络,它们依次对输入进行更深层次的特征提取和变换。
- 多层编码器的设计使得模型能够逐步建立起更复杂的语义表示,从而更好地理解和生成自然语言。
想象你在阅读一篇文章:
- 输入序列 就是你看到的每一个单词。
- 自注意力机制 就是你在读每个单词时,不仅关注这个单词本身,还会考虑它与文章中其他单词的关系,比如上下文、语法结构等。
- 前馈神经网络 就是你对每个单词及其相关性的深入思考和理解,形成更丰富的语义表示。
- 多层编码器堆叠 就是你在阅读过程中,不断加深对文章的理解,从字面意思逐渐过渡到深层含义。
接下来拆解注意力机制: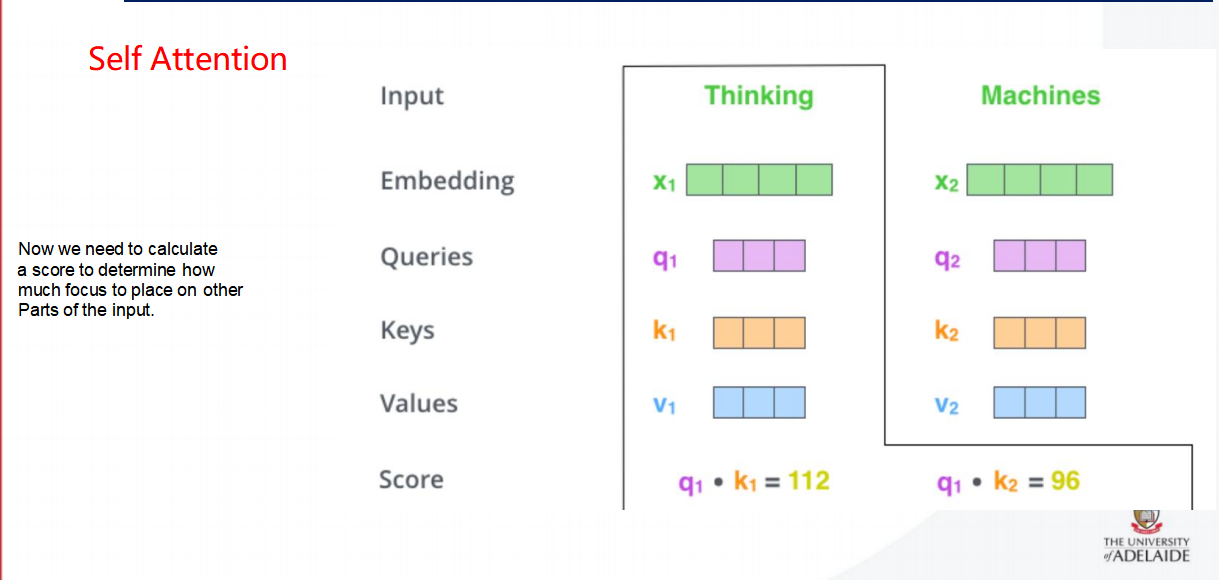
这张图展示了自注意力机制(Self-Attention)中的关键步骤,特别是如何计算注意力分数。让我们详细解析这个过程。
1. 输入与嵌入
输入:假设我们有两个词“Thinking”和“Machines”
嵌入(Embedding):每个词转换成一个嵌入向量。x1x2
2. 查询、键和值
在自注意力机制中,每个词会线性变换成三个不同的向量:查询(Query)、键(Key)和值(Value)。
查询(Queries):查询向量用于表示当前词对其他词的关注程度。例如,“Thinking”的查询向量为q1q1,“Machines”的查询向量为q2q2。
键(Keys):键向量用于表示其他词被关注的程度。例如,“Thinking”的键向量为k1k1,“Machines”的键向量为k2k2。
值(Values):值向量用于表示其他词的实际内容。例如,“Thinking”的值向量为v1v1,“Machines”的值向量为v2v2。
3. 计算注意力分数
注意力分数用于衡量当前词与其他词之间的相关性。具体来说,对于每个词,我们需要计算它与其他所有词的注意力分数。
- 点积计算:注意力分数通过查询向量和键向量的点积来计算。例如,对于词“Thinking”:
- 它与自身(“Thinking”)的注意力分数为q1⋅k1=112q1⋅k1=112。
- 它与另一个词(“Machines”)的注意力分数为q1⋅k2=96q1⋅k2=96。
- 这些分数反映了“Thinking”在多大程度上应该关注自己和其他词。
- 点积计算:注意力分数通过查询向量和键向量的点积来计算。例如,对于词“Thinking”:
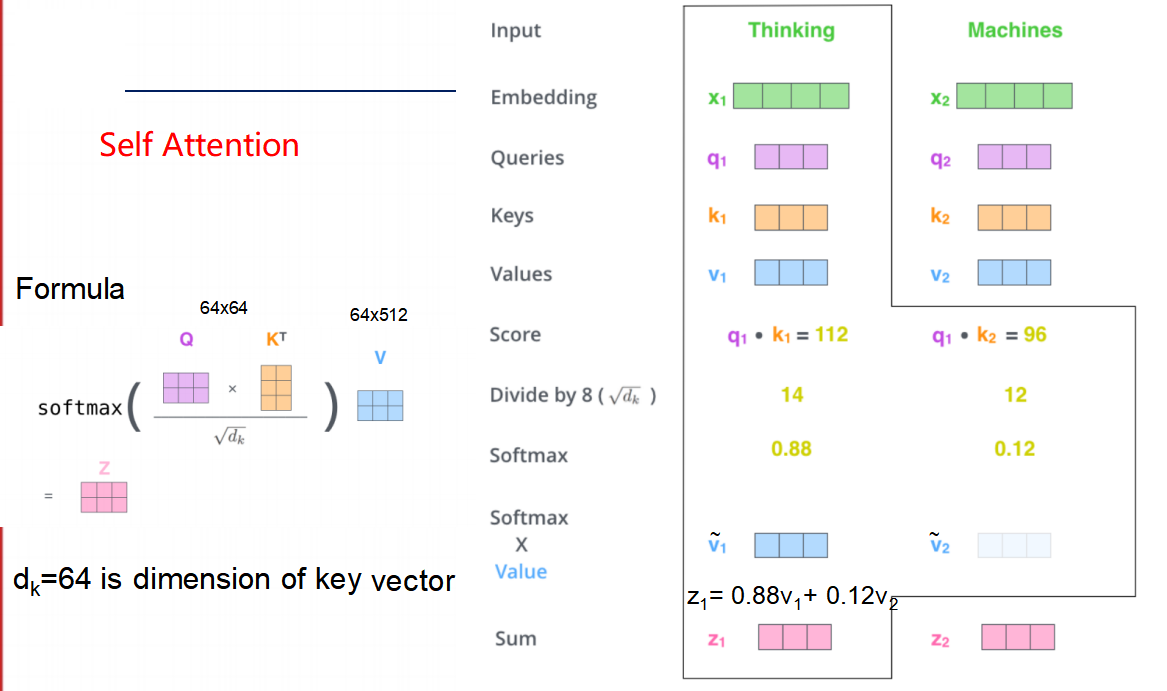
4. 归一化和Softmax
在上一步中,我们得到了每个词与其他词之间的注意力分数。为了将这些分数转换成概率分布,我们需要对它们进行归一化处理。
除以维度平方根:首先,我们将每个注意力分数除以键向量维度的平方根(dk)。在这个例子中,dk=64,因此我们除以8。
- 对于“Thinking”与“Thinking”的注意力分数:112/8=14112/8=14
- 对于“Thinking”与“Machines”的注意力分数:96/8=1296/8=12
Softmax函数:然后,我们使用Softmax函数对这些归一化的分数进行处理,得到一个概率分布。Softmax函数可以确保所有分数加起来等于1,并且较高的分数会被放大,较低的分数会被缩小。
- 对于“Thinking”:
- Softmax(14, 12) = [0.88, 0.12]
- 对于“Thinking”:
5. 加权求和
最后,我们根据Softmax得到的概率分布,对值向量进行加权求和,得到最终的输出向量。
- 对于“Thinking”:
- 输出向量z1=0.88×v1+0.12×v2z1=0.88×v1+0.12×v2
- 对于“Thinking”:
自注意力机制——多头注意力
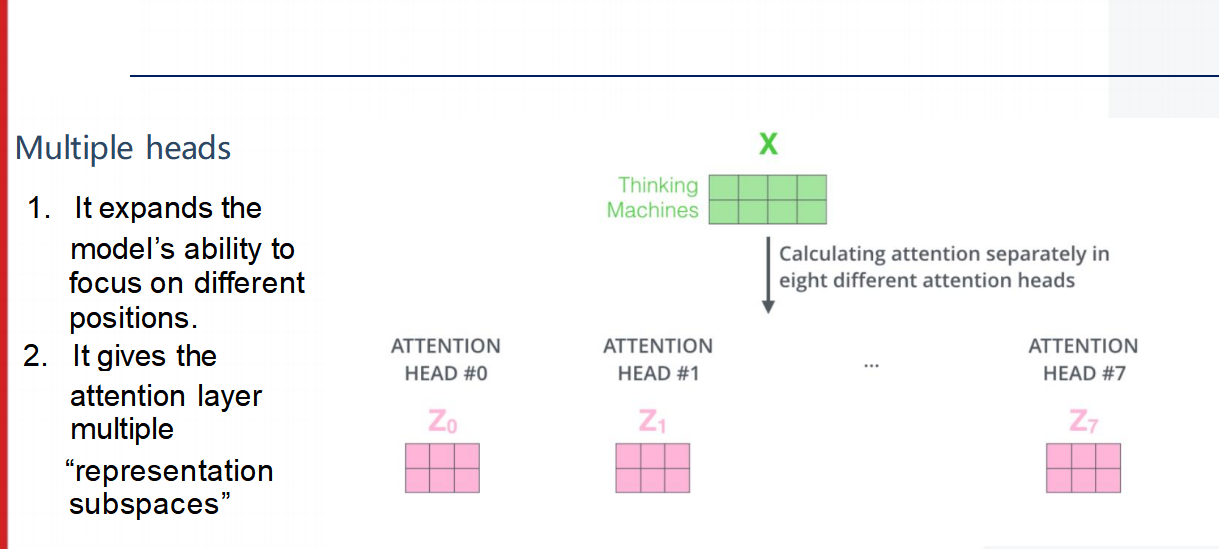
他们会从语法、语义、上下文等多个角度来分析这个单词。
整合多头注意力的输出为一个综合向量

- 归一化和Softmax 就是你在理解每个单词时,根据它与其他单词的相关性,决定你应该在多大程度上关注这个单词。例如,“Thinking”更应该关注自己(0.88),而不是“Machines”(0.12)。
- 加权求和 就是你在综合考虑所有相关信息后,形成对这个单词的最终理解。例如,“Thinking”的最终理解不仅包含它自身的信息,还包含了一部分“Machines”的信息。
- 图中展示了八个不同的注意力头(ATTENTION HEAD #0 到 ATTENTION HEAD #7),它们分别对输入序列“Thinking Machines”进行处理,得到各自的输出向量Z0Z0到Z7Z7。
模型的后续层通常期望一个固定维度的向量作为输入。因此,我们需要将这些向量整合成一个统一的表示。
1. 拼接所有注意力头
- 首先,我们将所有注意力头的输出向量按顺序拼接在一起,形成一个更大的向量。在这个例子中,每个ZiZi是一个2x4的矩阵,因此拼接后的向量是一个2x32的矩阵。
2. 乘以权重矩阵
接下来,我们将拼接后的向量与一个权重矩阵WOWO相乘。这个权重矩阵是在模型训练过程中联合学习得到的,用于将不同注意力头的输出进行线性组合和降维。
- 图中展示了一个24x4的权重矩阵WOWO,它将拼接后的2x32矩阵转换成了一个2x4的矩阵ZZ。
3. 最终输出
- 最终得到的矩阵ZZ包含了来自所有注意力头的信息,并且具有预期的维度。这个矩阵可以被送入前馈神经网络(FFNN)进行进一步的处理。
位置编码(在自注意力机制之前进行)
在自然语言处理任务中,输入序列中的词不仅具有语义信息,还具有顺序信息。例如,在句子“Je suis étudiant”中,“Je”、“suis”和“étudiant”的顺序决定了句子的意义。
然而,Transformer模型中的自注意力机制本身并不具备捕捉顺序信息的能力。为了解决这个问题,Transformer在每个输入嵌入向量上添加了一个位置编码向量。
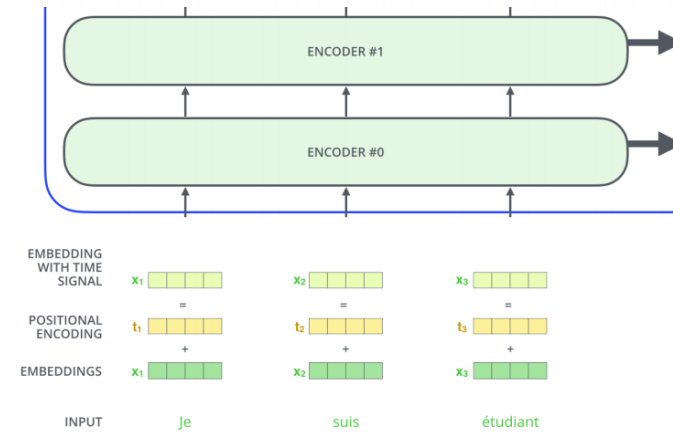
位置编码向量是根据词在序列中的位置计算得到的。常见的计算方法包括正弦和余弦函数。
将位置编码向量与输入嵌入向量相加后,得到新的嵌入向量,这些向量包含了原始的语义信息和额外的位置信息。
由于位置编码向量的存在,即使在没有明确的顺序信息的情况下,模型也能够通过计算嵌入向量之间的距离来捕捉词与词之间的相对位置关系。
Add & Normalize 层的作用(在自注意力机制后,实际中每一个子层后都应有一个归一化层以稳定和加速)
(看不懂先留印象,下一节会细讲)
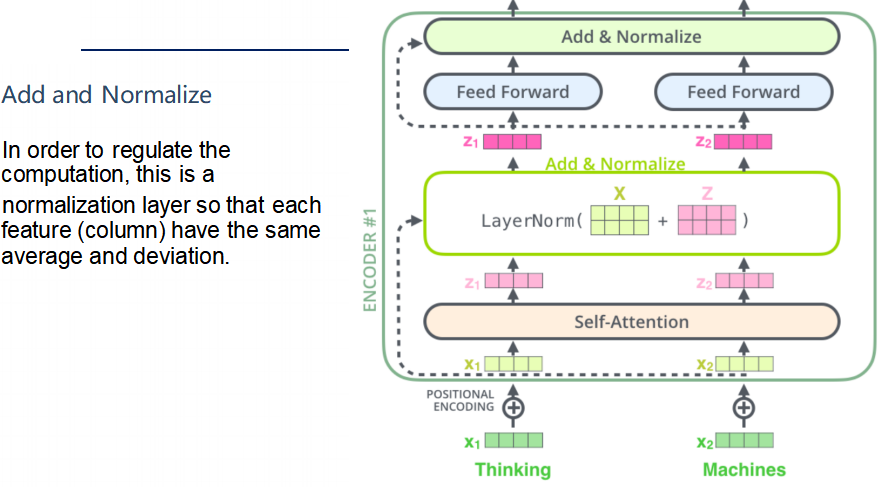
对输入特征进行归一化处理,使得每个特征(列)具有相同的平均值和标准差。这样可以避免在深度神经网络中常见的梯度消失或爆炸问题,并加速模型的训练过程。
自注意力机制:首先,输入向量X1X1和X2X2经过自注意力机制处理后,得到输出向量Z1Z1和Z2Z2。
残差连接:然后,将自注意力机制的输出与原始输入相加,即X+ZX+Z。这种操作称为残差连接(Residual Connection),它可以保留原始输入的信息,并帮助模型学习更复杂的特征表示。
LayerNorm层:最后,将相加后的结果送入LayerNorm层进行归一化处理。LayerNorm层会对每个样本的所有特征进行归一化,使得它们具有相同的平均值和标准差。
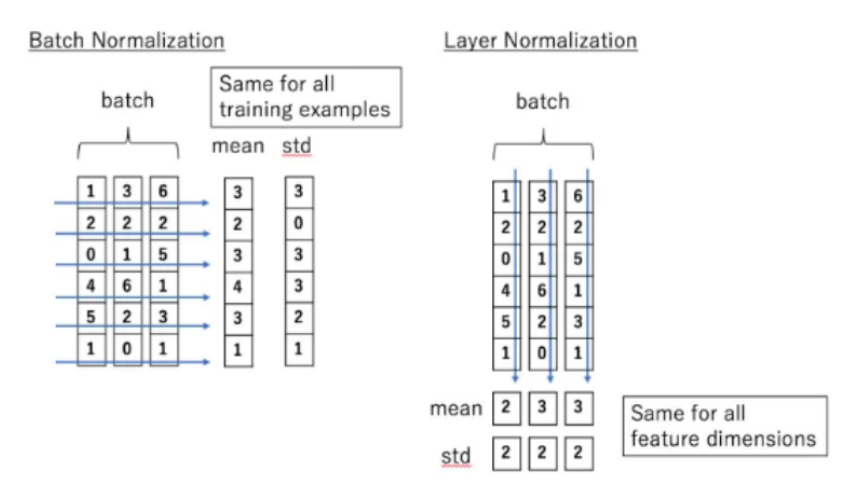
批归一化:归一化处理在批归一化中,对于同一个特征维度,所有训练样本的数值会被一起计算平均值和标准差,并进行。这意味着每个特征维度在整个批次内具有相同的平均值和标准差。
层归一化:在层归一化中,对于同一个样本,所有特征维度的数值会被一起计算平均值和标准差,并进行归一化处理。这意味着每个样本的所有特征维度具有相同的平均值和标准差。
整个TRANSFORMER的结构
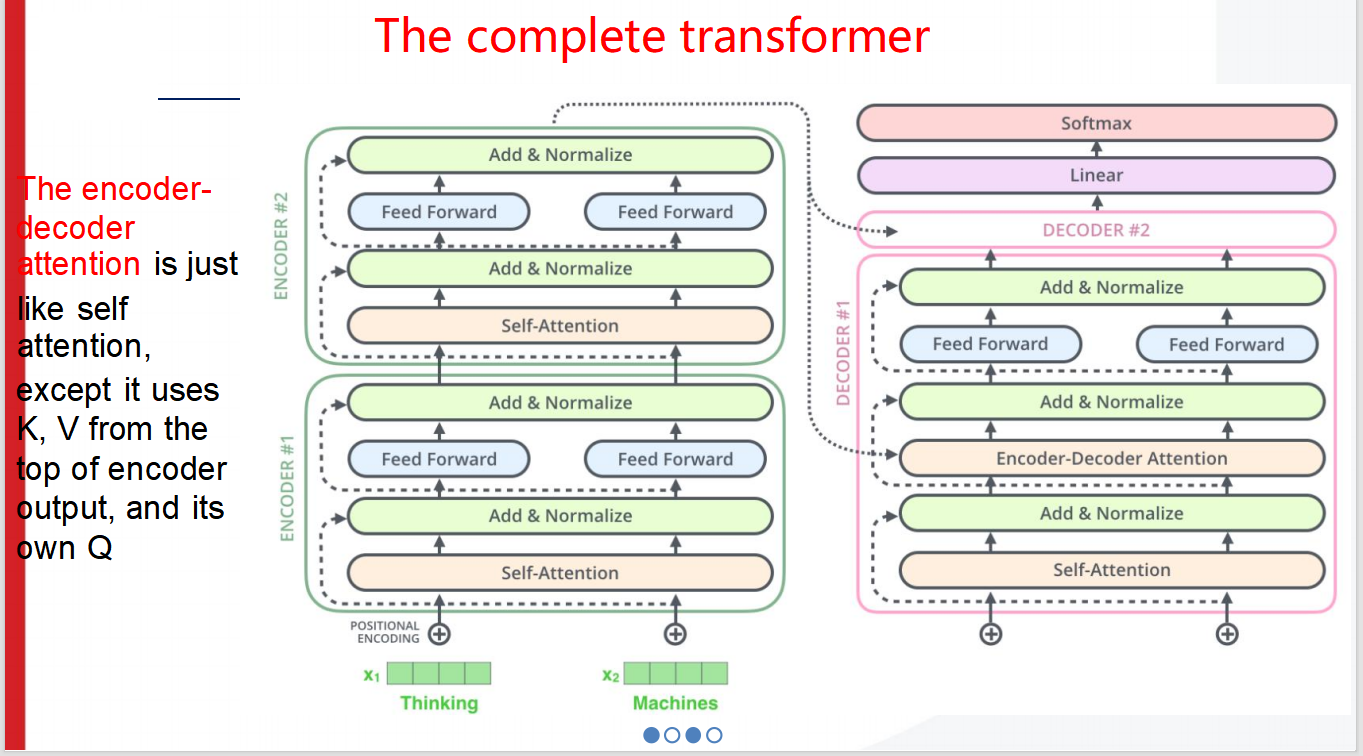
1. 编码器(Encoder)
编码器由多个相同的层堆叠而成,每个层包含两个子层:自注意力机制(Self-Attention)和前馈神经网络(Feed Forward)。
在每个子层之后,都有一个“Add & Normalize”层,用于残差连接和归一化处理,以保持网络的稳定性和收敛性。
输入序列经过嵌入层和位置编码后,被送入编码器的第一个层进行处理。在每个编码器层中,自注意力机制会计算输入序列中各个词之间的依赖关系,并生成新的表示向量;前馈神经网络则对这些表示向量进行非线性变换,以捕捉更复杂的特征。
2. 解码器(Decoder)
解码器同样由多个相同的层堆叠而成,但与编码器不同的是,每个解码器层包含三个子层:自注意力机制、编码器-解码器注意力机制(Encoder-Decoder Attention)和前馈神经网络。
自注意力机制的作用与编码器中的相同,用于计算解码器内部各个词之间的依赖关系。
编码器-解码器注意力机制则是将编码器的输出作为键(K)和值(V),并将解码器自身的查询(Q)与之结合,从而实现编码器和解码器之间的信息交互。
前馈神经网络同样用于对表示向量进行非线性变换,以捕捉更复杂的特征。
3. 编码器-解码器注意力机制
编码器-解码器注意力机制是Transformer模型中非常关键的一部分,它使得解码器能够关注到编码器中与当前解码位置相关的部分。
具体来说,在计算编码器-解码器注意力时,解码器会使用自己的查询(Q)与编码器输出的键(K)和值(V)进行点积操作,得到注意力权重矩阵。然后,通过softmax函数对权重矩阵进行归一化处理,并与值(V)相乘,得到最终的注意力输出。
基于Transformer架构的两种著名预训练语言模型:GPT(Generative Pre-trained Transformer)和BERT(Bidirectional Encoder Representations from Transformers)
Transformer的基本结构 就是你在写作时,不仅要考虑每个句子的意思,还要考虑它们之间的关系,并生成一个整体的文章。(要理解题目,也要写得出文章)
GPT 就是你在写作时,可以根据已有的内容,逐句地生成新的句子,使得文章的内容更加丰富和连贯。(只用写文章)
在GPT中,由于不需要处理输入数据,因此可以去掉Transformer模型中的编码器部分,只保留解码器部分。这样,GPT就可以通过自回归的方式,逐个生成下一个词,从而实现文本生成任务。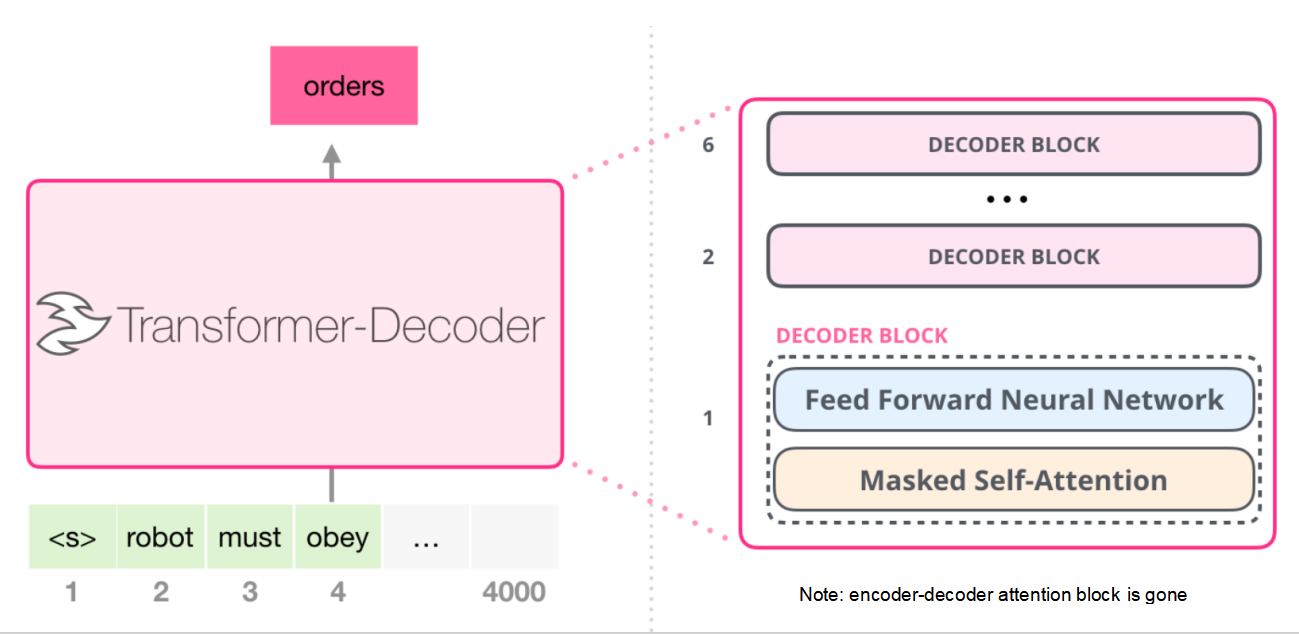
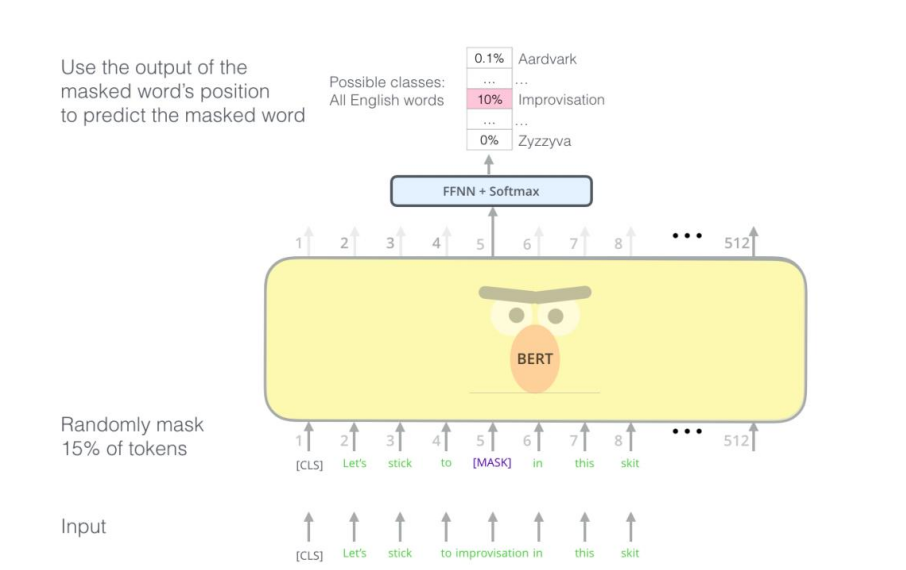
BERT 就是你在写作时,可以从多个角度来理解每个句子的意思,并生成更全面的句子表示,从而更好地表达文章的主题和思想。(只用理解题意)
在BERT中,由于只需要关注输入数据的表示,而不需要生成输出数据,因此可以去掉Transformer模型中的解码器部分,只保留编码器部分。
掩码语言模型(Masked Language Model, MLM 完形填空模型):BERT的一个关键训练任务是预测被随机遮盖掉的单词。在输入文本中,15%的词会被选中并替换为特殊的“[MASK]”标记,模型的任务就是根据上下文来预测这些被遮盖的词是什么。
技术迭代
图像注意力机制(区域分割型)
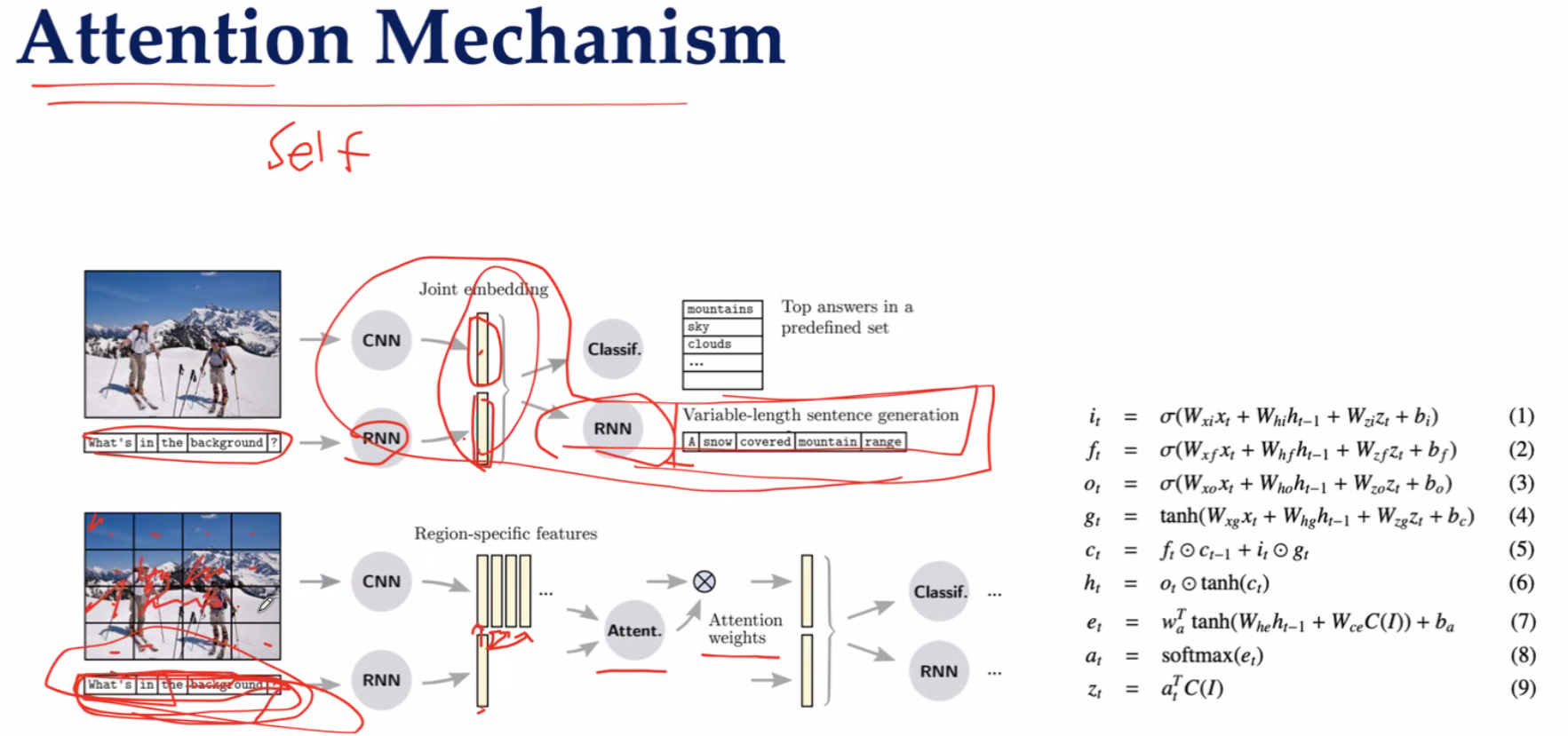
将一张图片分成若干区域,给每个区域赋予一个权值,通过RNN给与提示,问哪个画面最值得注意
堆叠注意力(Stacked Attention)——用前一次的“看到”来指导下一次的“怎么看”!
上下文向量
更新后的Q向量

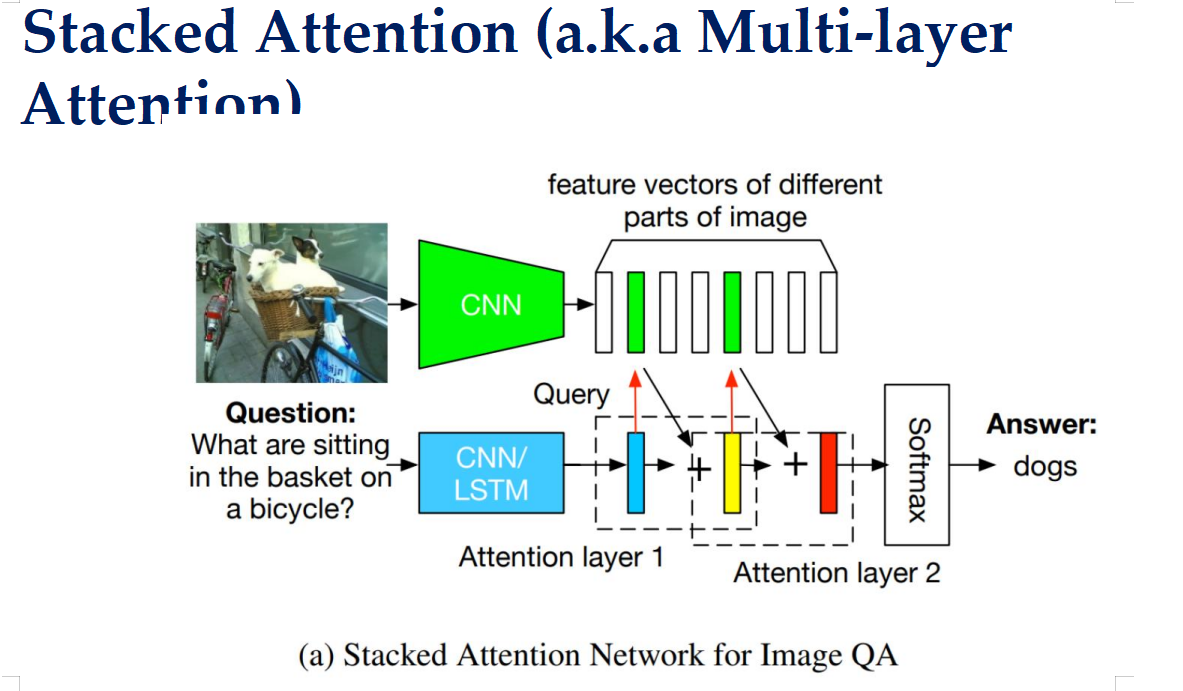
省流:赵构头
第一次搜索:Query = “动物” → 找到中间区域(有狗)
第二次搜索:Query = “中间那个动物” → 再次查数据库,聚焦到狗的头部或身体
如何工作
输入图像和问题:
图像被分割成多个区域,每个区域通过 CNN 提取特征,得到一个特征向量。
(图像注意力机制)
这些特征向量会被分别映射为 Key (K) 和 Value (V) 向量。
K 用于和问题(Query)做相似度计算。
V 才是真正携带视觉信息、用于构建上下文向量的部分。
问题通过另一个CNN或长短期记忆网络(LSTM)进行编码,生成问题的查询向量Q。
第一层注意力(Attention Layer 1):
问题向量Q和图像每个区域K对比,看看哪个区域与问题关联度最大。然后通过 softmax 得到归一化的注意力权重。
这些权重表示:图像的每个区域对回答当前问题的重要程度。
更新携带视觉信息的V向量。

在得到每个部分的重要性评分(即注意力权重 αi)后,通过加权求和的方式将这些重要性评分应用到对应的 V 向量上,最终得到一个综合了所有相关信息且强调了最重要部分的上下文向量C。
第二层注意力(Attention Layer 2):
第一层注意力生成的上下文向量 C1 并不是一个“更新后的图像特征”,而是一个融合了问题和初步关注区域的信息向量,它包含了:
- 原始问题的语义(比如“狗在哪儿?”)
- 第一层注意力“看到”的最相关区域(比如中间那块有动物)
所以,C1C1 可以看作是一个更聚焦的“新问题”或“新查询信号”。
类比:
你问:“图片里有什么?” → 模型看到中间有个动物。
然后你接着问:“中间那个动物是什么?” → 这个“中间那个动物”就是基于第一次回答生成的新查询。
第二层注意力就是用这个“新查询” C1 去重新扫描原始图像,看看能不能找到更精细的答案(比如确认是“狗”而不是“猫”)。
最终输出:
经过两层注意力机制后,得到的最终上下文向量包含了对问题最相关的图像信息。
这个上下文向量被送入Softmax层,生成最终的答案,例如“dogs”。
听不懂?看下面:
第一次搜索:Query = “动物” → 找到中间区域(有狗)
第二次搜索:Query = “中间那个动物” → 再次查数据库,聚焦到狗的头部或身体
共注意力(Co-Attention)机制——接触跨膜态
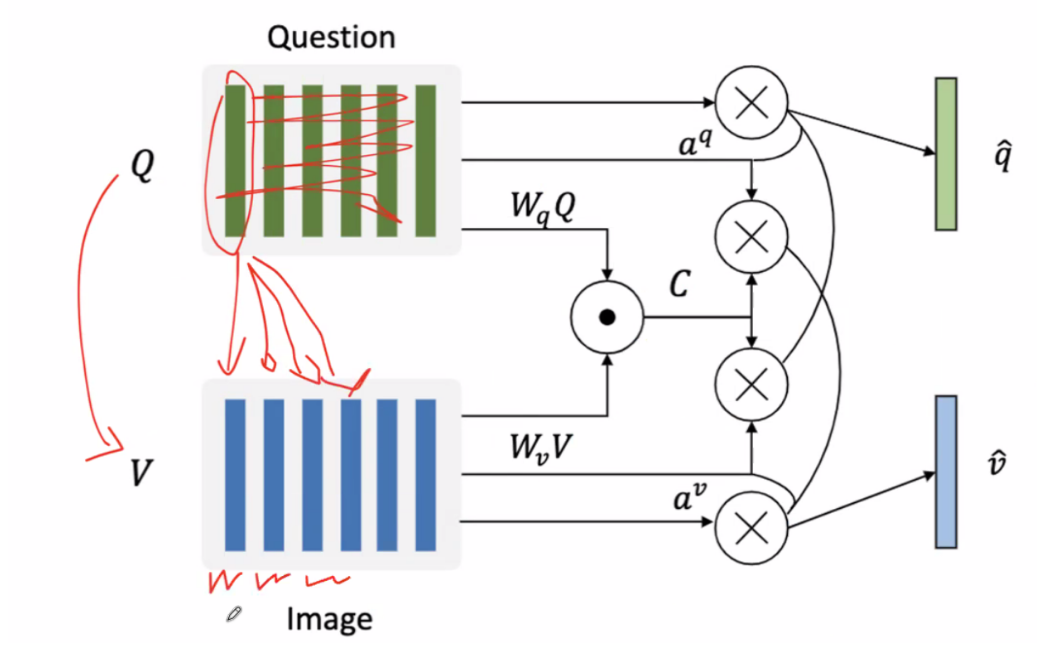
1. 输入部分
- Question (Q):表示问题的特征向量
- Image (V):表示图像的特征向量
2. 权重矩阵
- Wq 和 Wv:这两个权重矩阵分别用于将问题特征 Q 和图像特征 V 映射到一个共同的空间中,使得它们可以在同一个语义中比较和交互。
3. 共注意力计算
- C:表示共注意力矩阵,它是通过将映射后的图像特征 WvV 和问题特征 WqQ 相互点乘得到的。这个矩阵中的每个元素表示图像的一个区域与问题的一个部分之间的相关性。(有点像Seq2Seq,时序一一对应)
4. 注意力权重
- aq 和 av:分别表示问题和图像的注意力权重。表示图像的各个区域和问题的各个部分对于当前任务的重要性。
5. 加权求和
- q^ 和 v^:分别表示加权后的问题特征和图像特征。它们是通过将原始的问题特征 Q 和图像特征 V 分别与对应的注意力权重 aq 和 av 相乘得到的。这一步骤确保了模型更加关注那些对当前任务最重要的信息。
6. 最终输出
- q^ 和 v^ 包含了经过共注意力机制处理后的问题和图像的综合信息。
假设我们有一个问题:“这张图片里有什么颜色的猫?”和一张包含一只橙色猫坐在红色沙发上、背景是绿色植物的图片。
1. 输入处理
- 问题 (Q): 经过编码器处理后得到的问题特征向量,它捕捉了“猫”、“颜色”这些关键词。
- 图像 (V): 经过卷积神经网络(CNN)提取的图像特征向量,它包含了关于图像中不同对象及其属性的信息。
2. 映射到共同空间
使用权重矩阵 WqWq 和 WvWv,将问题特征和图像特征分别映射到一个共同的空间。这样做的目的是为了使问题和图像可以在同一个语义空间内相互作用。
3. 计算共注意力
通过点乘操作得到共注意力矩阵 CC,该矩阵反映了图像的不同区域与问题的相关性。例如,在这个问题中,“猫”的相关性会集中在图像中猫的位置,而忽略沙发和背景植物的部分。
4. 生成注意力权重
对共注意力矩阵进行归一化处理(如使用softmax函数),以生成针对问题和图像的注意力权重。在这个例子中,注意力权重可能会给图像中猫所在位置较高的分数,因为这部分对于回答问题最为关键。
5. 加权求和
根据生成的注意力权重,对原始的问题和图像特征进行加权求和。这意味着模型现在更加关注于那些有助于回答问题的关键信息——即图像中猫的颜色和形态。
6. 生成答案
最后,利用经过共注意力机制处理后的综合信息,模型可以更准确地识别出图中的猫是橙色的,并给出正确答案:“这是一只橙色的猫。”
你说"周末去哪玩?"(文本→图像:关联旅游照片)
对方展示餐厅图片(图像→文本:关联"吃饭"关键词)
顺序共注意力(Sequential Co-Attention)机制
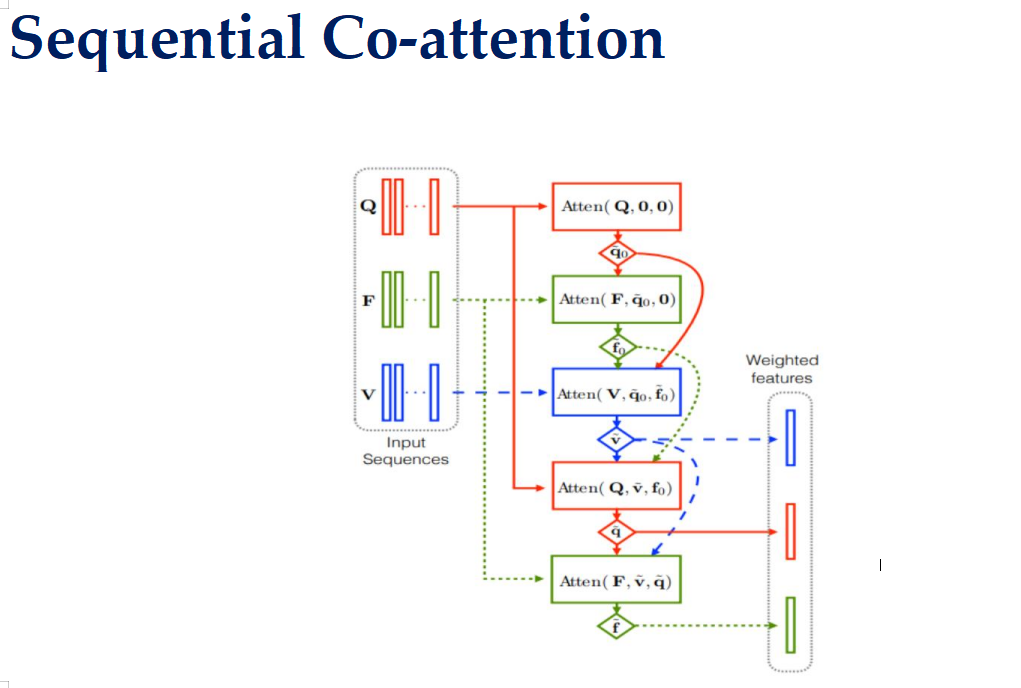
1. 输入序列
- Q: 表示问题的特征向量序列。
- F: 表示其他可能相关的特征向量序列,例如上下文信息或额外的模态数据。
- V: 表示图像的特征向量序列。
2. 初始注意力计算
- Atten(Q, 0, 0): 在第一轮中,使用问题特征 Q 进行注意力计算,此时没有历史信息(初始化为 0),得到加权后的特征 q~0q~0。
3. 交叉注意力计算
接下来的步骤涉及在不同特征序列之间进行交叉注意力计算:
- Atten(F, q~0q~0, 0): 使用上一步得到的加权问题特征 q~0q~0 对 F 特征进行注意力计算,得到加权后的特征 f~0f~0。
- Atten(V, q~0q~0, f~0f~0): 使用 q~0q~0 和 f~0f~0 对 V 特征进行注意力计算,得到加权后的图像特征 v~v~。
4. 反馈与更新
- Atten(Q, v~v~, f~0f~0): 使用上一轮得到的加权图像特征 v~v~ 和 f~0f~0 对问题特征 Q 进行再次注意力计算,得到更新后的加权问题特征 q~q~。
- Atten(F, v~v~, q~q~): 使用 v~v~ 和 q~q~ 对 F 特征进行再次注意力计算,得到更新后的加权特征 f~f~。
5. 最终加权特征
经过多轮迭代和交叉注意力计算后,我们得到了最终的加权特征:
- 加权问题特征 q~q~
- 加权图像特征 v~v~
- 加权其他特征 f~f~
这些加权特征包含了经过多次交互和聚焦后的综合信息,可以用于后续的任务,如生成答案或分类。
🧠 类比帮助理解:
想象你在做一道关于图片的题目,并且需要参考一些额外的信息来回答:
- 问题 (Q) 就是你读到的题目内容。
- 图像 (V) 是你看到的图片。
- 其他信息 (F) 可能是一些背景知识或者上下文信息。
第一轮思考:
- 你先仔细阅读问题,初步理解了需要找什么(比如“猫的颜色”)。
- 然后你开始看图片,根据问题的提示,你的注意力集中在可能有猫的地方。
- 同时,你也会参考一些背景知识,看看有没有相关信息可以帮助你更好地理解问题和图片。
第二轮思考:
- 根据第一轮的观察,你进一步确认了图片中的猫的位置和颜色。
- 你再次回到问题,结合图片中的信息和背景知识,更加明确地理解了问题的要求。
- 最后,你综合所有信息,给出了准确的答案。
除了直接切割,还可以俺对象切割:
BUTD Attention
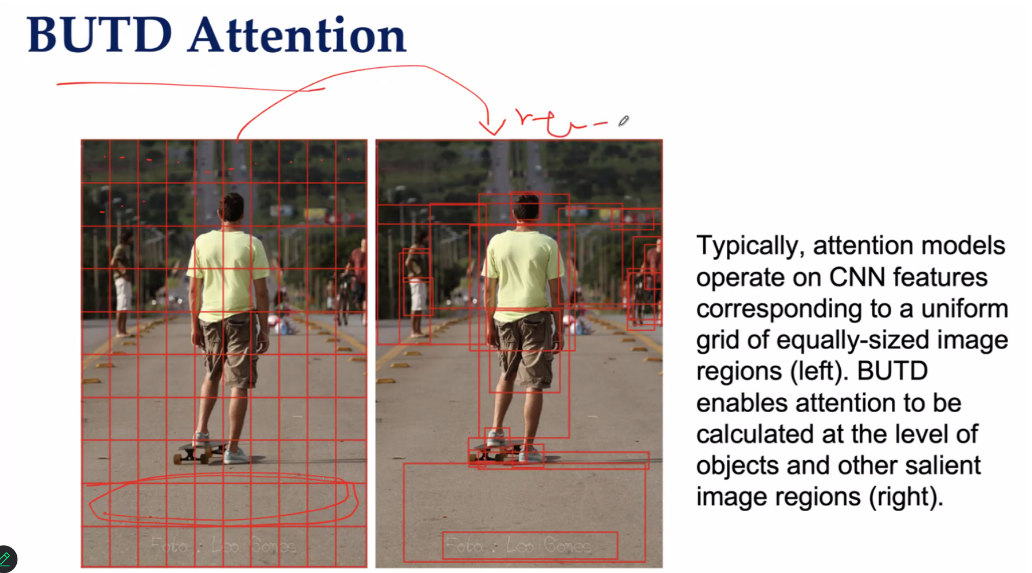
对象级关注:如右图所示,BUTD Attention 能够在对象级别进行注意力计算。这意味着模型可以更准确地聚焦于图像中的关键对象和其他显著区域,而不是简单的网格划分。
- 检测显著区域:通过预先训练的对象检测器(如 Faster R-CNN),BUTD 可以识别出图像中的各个对象及其边界框,并提取这些对象的特征。
- 灵活粒度:不同对象和区域可以根据其重要性分配不同的注意力权重,从而实现更精细的关注。
流程
a. 自下而上(Bottom-Up)信息提取
- 使用预训练的对象检测器(如 Faster R-CNN)对图像进行处理,得到一系列候选对象及其边界框。
- 对每个候选对象提取特征向量,这些特征向量包含了对象的视觉信息。
b. 自上而下(Top-Down)信息引导
- 根据问题或上下文信息生成一个查询向量(Query Vector),这个向量包含了任务相关的先验知识。
- 使用查询向量与对象特征进行交互,计算每个对象的注意力权重。
c. 注意力计算
- 根据计算得到的注意力权重,对对象特征进行加权求和,得到最终的加权特征表示。
- 这些加权特征可以用于后续的任务,如生成答案或分类。
自下而上的步骤会首先帮助你识别出图像中的所有对象,包括猫、狗、背景等;然后,自上而下的步骤会基于问题的需求,重点分析那些被认为是猫的对象,忽略其他不相关的信息。
捕捉特征和信息的两种架构——GCN 和 GAN
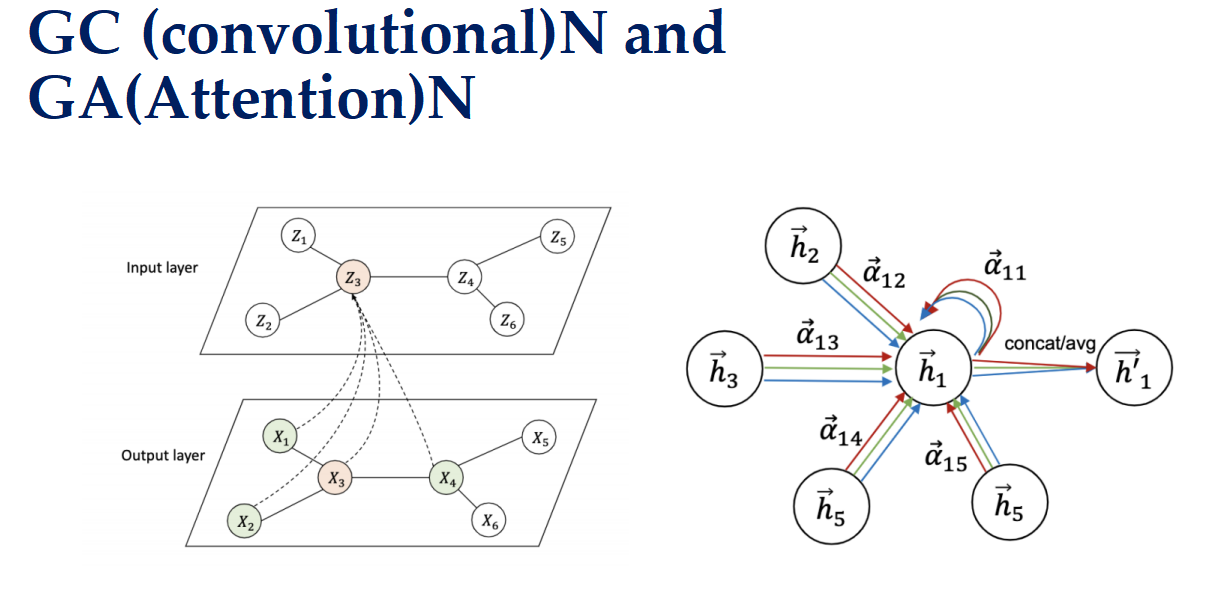
- 卷积神经网络(GC N) 就像是你用放大镜仔细观察图片的每一个小部分,每次只看一小块区域,并且用同样的方式检查所有的区域。这种方法可以帮助你发现局部的细节,但可能需要多次移动放大镜才能覆盖整个图片。
- 注意力机制(GA N) 则更像是你能够同时看到整张图片,并且可以根据需要快速聚焦于不同的部分。你可以根据问题的要求,灵活地调整对不同区域的关注程度,从而更高效地找到答案。
图注意力机制(对象关注型)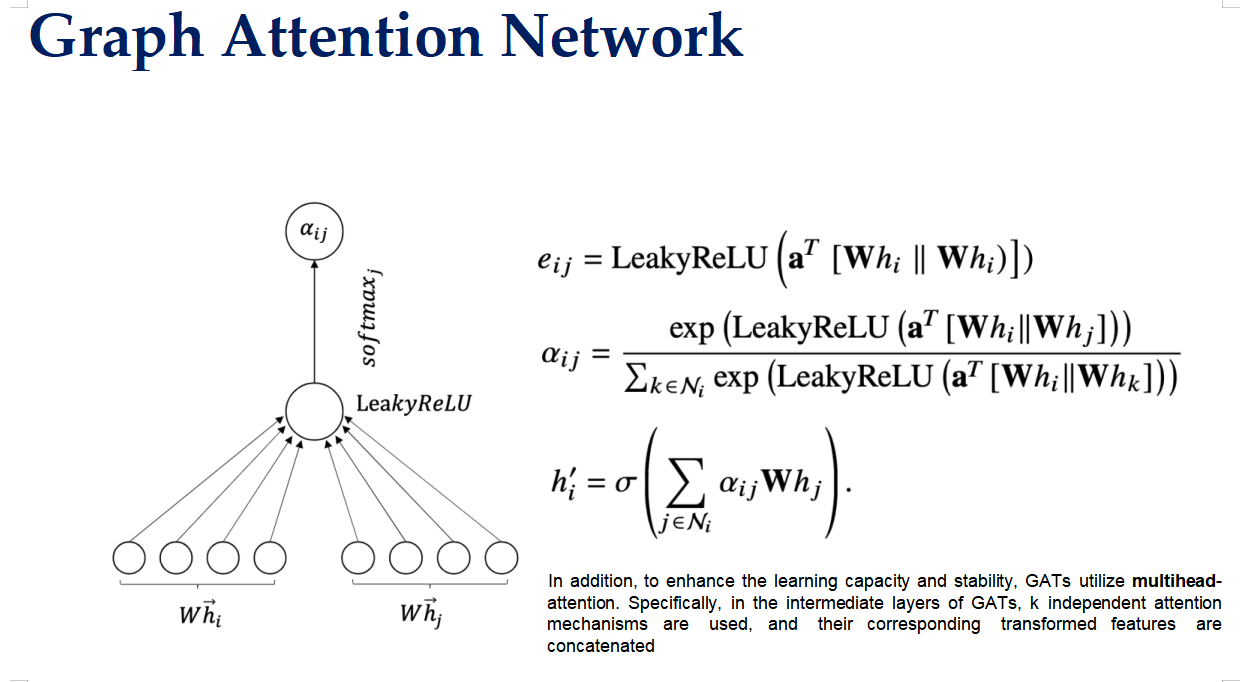
想象你正在组织一场学校班级活动,你需要决定每个同学在活动中扮演的角色。你的目标是根据每个同学的特点来分配任务,使得整个活动能够顺利进行。
1. 了解每个同学(节点特征)
- 每个同学就像是图中的一个节点。他们都有自己的特点,比如有的擅长表演,有的擅长组织,有的擅长后勤等。
- 这些特点可以看作是每个同学的特征向量。
2. 确定谁和谁一起合作(邻居节点)
- 在活动中,某些同学会自然地被安排在一起合作。例如,负责表演的同学可能会与负责音响的同学紧密合作。
- 这种合作关系就像图中的边,连接了不同的节点(同学),形成了一个网络。
3. 注意力系数计算
- 接下来,你需要决定每个同学在团队中应该承担多少责任。为了做到这一点,你会考虑每个同学的特点以及他们与其他同学的合作关系。
- 在GAT中,这一步通过计算注意力系数来实现。具体来说:
- 你首先会为每一对合作的同学(节点)计算一个初步的“合作评分”(未归一化的注意力系数)。
- 然后,你会对这些评分进行标准化处理,确保每个同学的合作评分总和为1。这样你就得到了最终的注意力系数,表示每个同学在团队中的重要性或贡献度。
4. 加权求和(更新节点特征)
- 根据计算出的注意力系数,你可以调整每个同学的任务分配。例如,如果某个同学的注意力系数较高,说明他在团队中的作用更大,那么你可能会给他分配更多重要的任务。
- 在GAT中,这个过程通过加权求和来实现。也就是说,每个同学的新角色(特征向量)是根据他们的原始角色以及与他们合作的同学的特征来重新计算的。
5. 多头注意力机制
- 有时候,你可能需要从多个角度来评估每个同学的作用。例如,不仅考虑他们在表演方面的能力,还要考虑他们在组织和后勤方面的能力。
- 在GAT中,这种多角度的评估被称为多头注意力机制。它允许模型从多个维度来捕捉每个节点之间的复杂关系,从而得到更加丰富的信息。
- 单头注意力就是KQV机制。
- 并行处理:所有这些注意力头会同时工作,每个头独立地计算自己的注意力权重,并基于这些权重对输入数据进行加权求和。
- 整合信息:一旦所有头完成了它们的工作,结果会被合并起来,形成一个综合的输出。这样,模型就能从多个维度理解输入数据,而不是局限于单一的视角。
在图注意力机制下提出了:使用生成对抗网络(GAN)来解决视觉问答(VQA)任务
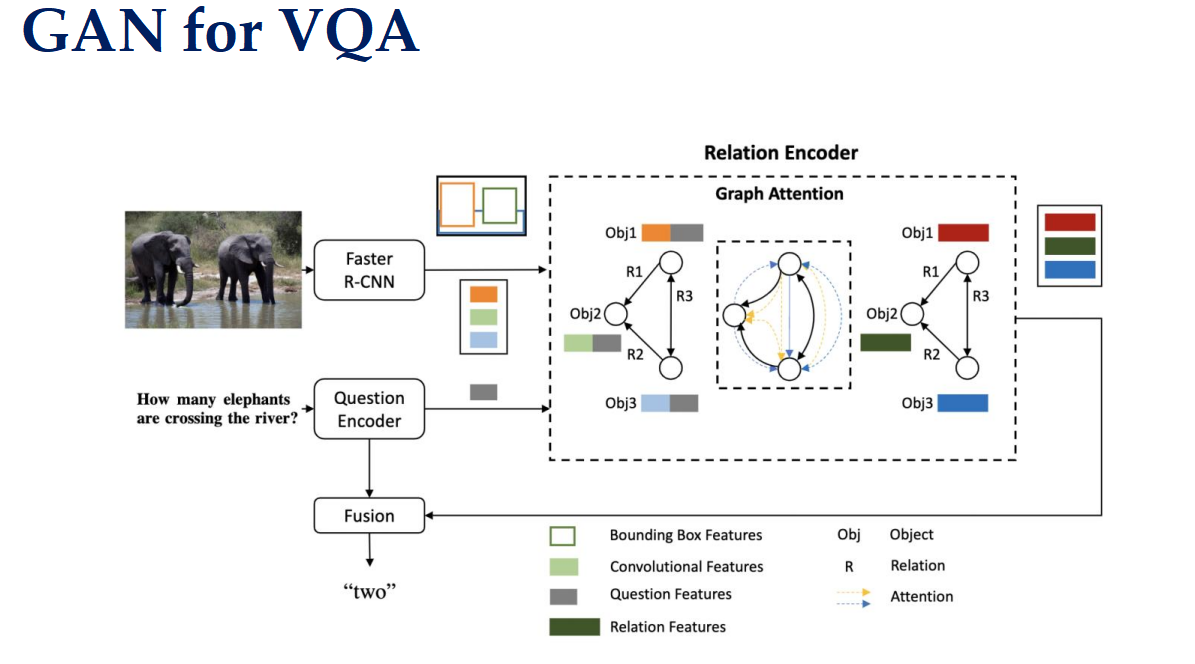
1. 输入图像处理
Faster R-CNN:首先,输入图像被送入 Faster R-CNN 模型中进行目标检测和特征提取。Faster R-CNN 能够识别图像中的不同对象,并为每个对象生成边界框和对应的特征向量。
- 在示例图像中,Faster R-CNN 检测到了两个大象,并为它们分别生成了特征向量。
2. 问题编码
Question Encoder:同时,输入的问题也被送入一个编码器中进行处理。这个编码器通常是一个循环神经网络(RNN),如 LSTM 或 GRU,它可以将自然语言的问题转换成一个固定长度的向量表示。
- 对于问题“有多少只大象正在过河?”,编码器会生成一个与之对应的特征向量。
3. 关系编码器
Graph Attention:接下来,模型进入关系编码器部分,这里使用了图注意力机制来捕捉对象之间的关系。
构建图结构:每个对象(Obj1、Obj2、Obj3)及其之间的关系(R1、R2、R3)被表示成一个图。例如,Obj1 和 Obj2 之间可能有某种关系 R1。
注意力机制:在图中,注意力机制用于计算每个节点(对象)与其他节点之间的相关性。这有助于模型理解对象之间的相互作用和依赖关系。
更新特征:通过注意力机制,每个对象的特征会被更新,以包含其邻居节点的信息。这样可以更全面地表示每个对象在场景中的角色和位置。
4. 特征融合
Fusion:最后,来自图像的对象特征和问题特征被融合在一起。这个过程通常涉及一些复杂的操作,如点积、拼接或加权求和,目的是将视觉信息和文本信息结合起来,形成一个综合的表示。
总结
CNN-RNN
注意力
堆叠式注意力(多层)
共注意力(自注意力与交叉注意力)
顺序共注意力(从Q、V到K、Q、V)
BUTD(图像分割>对象分割)
图
GCN(对象结构)
GAN(多头)