# 构建词汇表:自然语言处理中的关键步骤
构建词汇表:自然语言处理中的关键步骤
在自然语言处理(NLP)任务中,词汇表(Vocabulary)是文本数据预处理的核心组件之一。它将文本中的单词或字符映射为数值索引,从而让计算机能够理解和处理语言数据。本文将详细介绍如何使用 Python 构建一个基于字符的词汇表,并通过一个具体的例子展示其过程。
1. 词汇表的作用
在 NLP 中,文本数据通常是通过词汇表进行编码的。词汇表的作用是将文本中的每个单词或字符转换为一个唯一的数值索引,这样计算机就可以处理这些数据。例如,假设我们有一个词汇表:
{'今': 0, '天': 1, '气': 2, '真': 3, '好': 4, '<UNK>': 5, '<PAD>': 6}
那么,文本 “今天天气真好” 可以被编码为 [0, 1, 2, 3, 4]。如果文本中出现词汇表中不存在的字符,如 “明”,则可以用 <UNK>(未知字符)来代替,即索引 5。
2. 构建词汇表的步骤
2.1 准备数据
假设我们有一个 CSV 文件 simplifyweibo_4_moods.csv,其中包含了一些文本数据。文件的格式可能如下:
id,text
1,今天天气真好
2,我咁要去打球
3,明天会下雨
我们的目标是从这些文本中提取字符,统计它们的频率,并构建一个词汇表。
2.2 编写代码
以下是构建词汇表的完整代码:
from tqdm import tqdm
import pickle as pkl# 定义全局变量
MAX_VOCAB_SIZE = 4760 # 词表长度限制
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号def build_vocab(file_path, max_size, min_freq):"""构建词汇表函数:param file_path: 输入文件路径:param max_size: 词汇表的最大大小:param min_freq: 单词的最小出现频率:return: 构建好的词汇表(字典形式)"""# 定义分词器,将输入字符串逐字分割为字符列表tokenizer = lambda x: [y for y in x]# 初始化词汇表字典vocab_dic = {}# 打开文件并逐行读取with open(file_path, 'r', encoding='UTF-8') as f:i = 0 # 初始化计数器,用于跳过文件的第一行for line in tqdm(f): # 使用tqdm显示进度条if i == 0: # 跳过文件的第一行(通常是表头)i += 1continuelin = line[2:].strip() # 去掉每行的前两个字符,并去掉行首行尾的多余空格if not lin: # 如果处理后的行为空,则跳过continue# 对当前行进行分字处理,并统计每个字符的出现频率for word in tokenizer(lin):vocab_dic[word] = vocab_dic.get(word, 0) + 1# 按照字符的出现频率从高到低排序,并过滤掉出现频率小于min_freq的字符# 只保留前max_size个字符vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq], key=lambda x: x[1], reverse=True)[:max_size]# 重新构建词汇表字典,将字符映射为索引值vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}# 将特殊符号UNK和PAD添加到词汇表中,并分配索引值vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})# 打印构建好的词汇表(可选,用于调试)print(vocab_dic)# 将词汇表保存为一个.pkl文件,方便后续使用pkl.dump(vocab_dic, open('simplifyweibo_4_moods.pkl', 'wb'))# 打印词汇表的大小print(f"Vocab size: {len(vocab_dic)}")return vocab_dic # 返回构建好的词汇表if __name__ == "__main__":# 调用build_vocab函数,构建词汇表vocab = build_vocab('simplifyweibo_4_moods.csv', MAX_VOCAB_SIZE, 3)# 打印字符串'vocab',确认函数运行完成print('vocab')
2.3 代码解析
- 分词器:
tokenizer是一个简单的函数,将输入字符串逐字分割为字符列表。 - 统计频率:逐行读取文件内容,统计每个字符的出现频率。
- 过滤和排序:过滤掉出现频率小于
min_freq的字符,并按频率从高到低排序,只保留前max_size个字符。 - 构建词汇表:将字符映射为索引值,并添加特殊符号
<UNK>和<PAD>。 - 保存词汇表:将词汇表保存为
.pkl文件,方便后续加载和使用。
2.4 运行结果
输入文件 simplifyweibo_4_moods.csv 的内容如下:
运行代码后,输出如下:
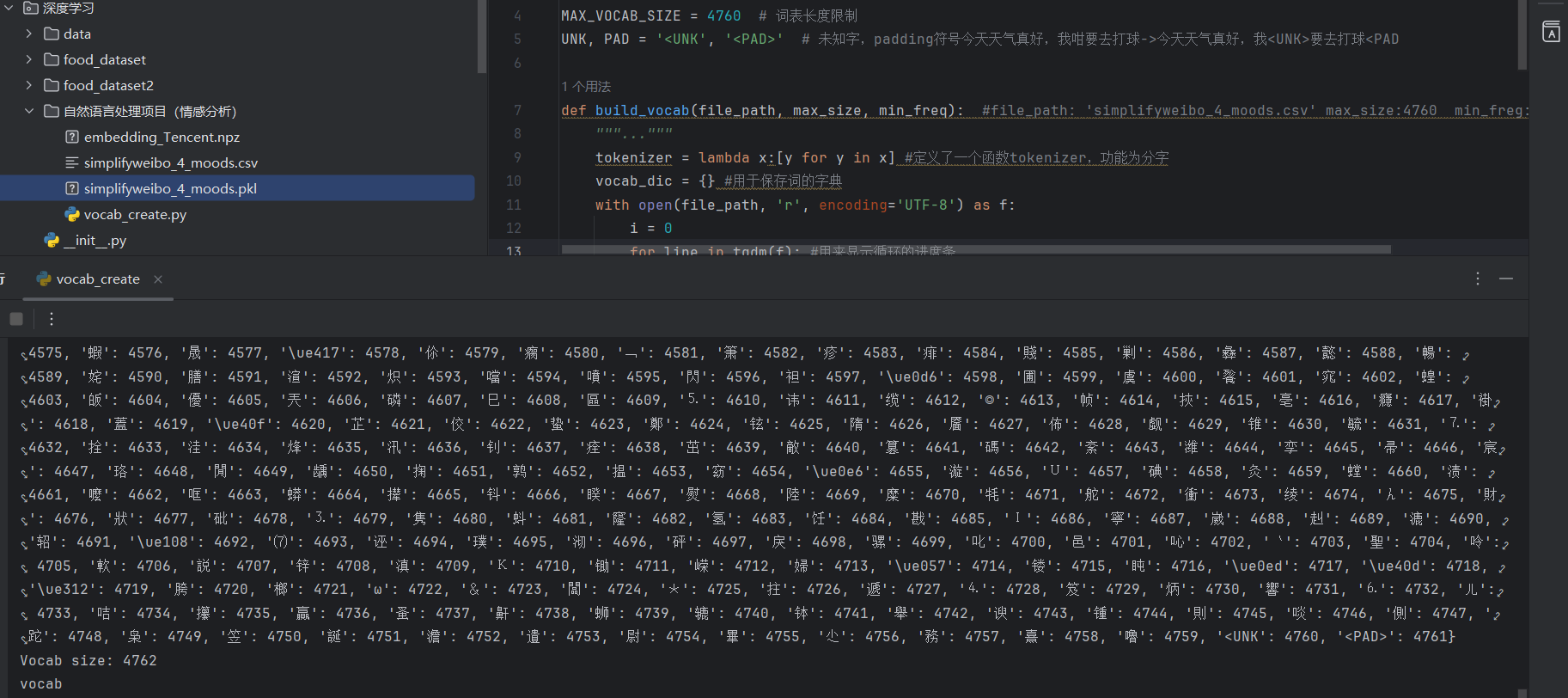
同时,词汇表会被保存为 simplifyweibo_4_moods.pkl 文件。
3. 词汇表的应用
构建好的词汇表可以用于多种 NLP 任务,例如:
- 文本分类:将文本编码为数值序列,输入到分类模型中。
- 情感分析:分析文本的情感倾向。
- 机器翻译:将源语言文本编码为数值序列,翻译为目标语言。
4. 总结
构建词汇表是 NLP 中的一个重要步骤。通过统计字符频率、过滤低频字符并映射为索引值,我们可以高效地处理文本数据。本文通过一个具体的例子展示了如何使用 Python 构建词汇表,并保存为 .pkl 文件以便后续使用。希望这篇文章对你有所帮助!