CVPR 2025 | 机器人操控 | RoboGround:用“掩码”中介表示,让机器人跨场景泛化更聪明
点击关注gongzhonghao【计算机sci论文精选】
1.导读
1.1
论文基本信息
论文标题:ROBOGROUND: Robotic Manipulation with Grounded Vision-Language Priors
作者:Haifeng Huang, Xinyi Chen, Hao Li, Xiaoshen Han, Yilun Chen, Tai Wang, Zehan Wang, Jiangmiao Pang,Zhou Zhao
作者单位:浙江大学、上海人工智能实验室
发表会议:CVPR(计算机视觉与模式识别会议)
论文链接:https://arxiv.org/abs/2504.21530
图灵学术论文辅导
2.论文概述
2.1
核心问题与背景
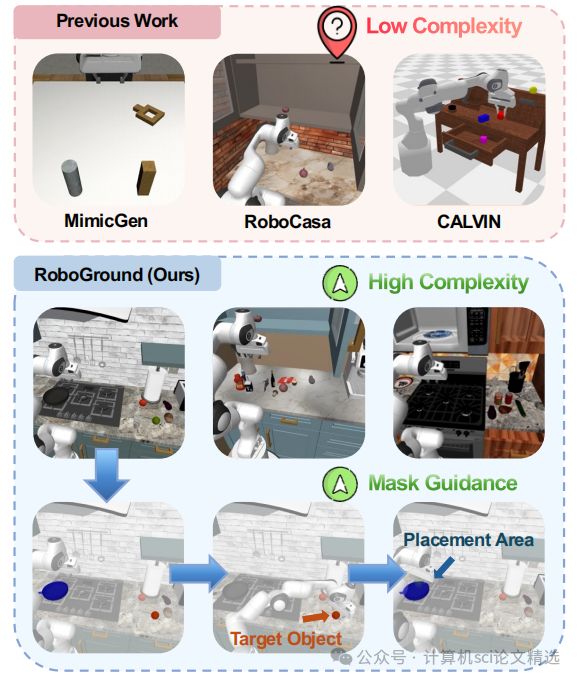
现有的模仿学习方法通常局限于特定场景,而大型视觉-语言-动作模型虽有进步,但在没有大量特定数据和微调的情况下,仍难以泛化。
研究背景表明,通过引入中间表示可以为策略网络提供指导。然而,现有的中间表示存在局限性:语言指令过于粗糙,缺乏空间精度;而目标图像等细粒度表示则需要大量数据和计算资源。基于此,该论文通过引入一种兼具精细空间指导和强大泛化潜力的“接地掩码”作为中间表示,来弥补现有方法的不足,从而构建一种更具鲁棒性和泛化能力的机器人操纵策略。
2.2
主要贡献
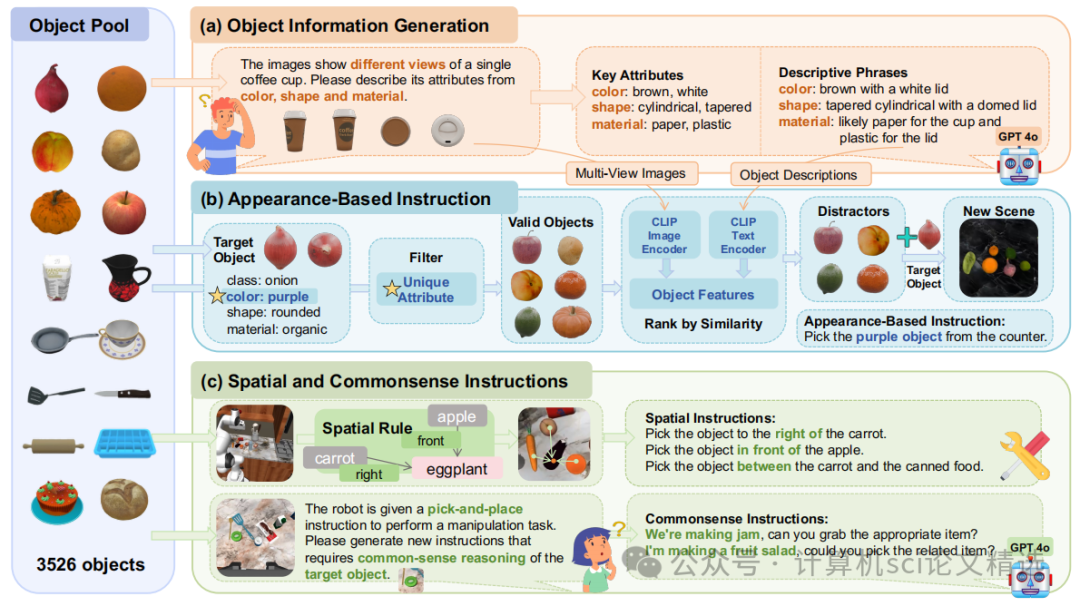
文章首先提出ROBOGROUND策略:一种新颖的、基于接地掩码的机器人操纵策略,显著提升了机器人的泛化能力 ;其次,团队创建了大规模多样化数据集:提出了一种自动化数据生成流水线,生成包含24K个演示和112K个多样化指令的复杂数据集,涵盖物体外观、空间关系和常识知识。此外,团队还通过广泛的实验证明了接地掩码作为中间指导的有效性,验证了该方法在泛化到新颖设置时的优越性能 。
2.3
关键技术与创新点
ROBOGROUND创造性地引入了“接地掩码”作为中间表示,它兼具两者优势。掩码能够提供精确的像素级空间信息,同时通过与预训练视觉-语言模型的结合,具备强大的泛化潜力。
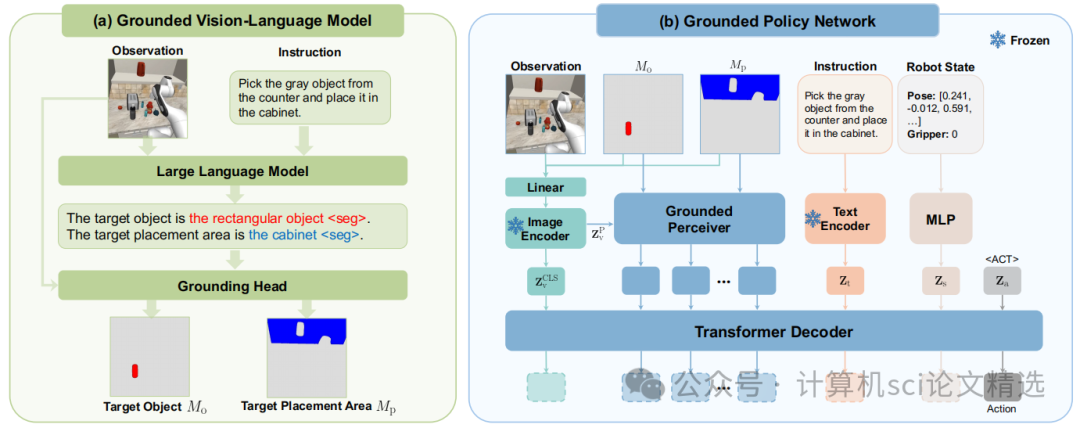
接地视觉-语言模型:该模型基于GLaMM架构,能够根据图像和语言指令,为后续的策略网络提供了高精度的空间指导。
接地感知器:为了高效利用掩码信息,论文设计了接地感知器。它通过在注意力机制中引入掩码引导,确保模型将注意力集中在关键的物体和区域上,显著提升了策略网络的性能。
指令多样性:利用GPT-4等大型语言模型,生成了需要进行外观、空间关系和常识推理的多种复杂指令,有效提高模型的学习能力。
3.研究背景及相关工作
3.1
现有机器人策略的泛化局限性
早期的机器人操纵策略主要依赖于从收集的演示中进行模仿学习,专注于在预定义场景中学习特定技能,因此泛化能力有限。近期VLA模型虽然通过大规模训练数据和预训练VLM来提升泛化能力,但它们仍然难以在没有大量数据集和额外微调的情况下泛化到新颖环境中,而这些都成本高昂 。
3.2
中间表示的研究现状
为了解决泛化问题,研究者们提出了使用中间表示来为策略网络提供结构化指导。这些方法通常分为两类:
易于获取但粒度粗糙的表示:例如语言指令,虽然易于生成,但往往缺乏精细物体操纵所需的空间精度 。
粒度精细但资源密集型表示:例如目标图像或点流,虽然提供了详细的空间指导,但需要大量的训练数据和计算资源,限制了其可扩展性。
3.3
相关工作对比
与本文方法密切相关的现有工作主要集中在两个方面:中间表示和大型视觉-语言模型。
中间表示方法:许多方法探索了不同的中间表示,如语言指令、2D轨迹、点流、目标图像等。与本文方法最接近的是MOO,它使用预训练的VLM生成粗糙的边界框。本文方法与之不同之处在于,它专注于获取精细的物体掩码,并引入了高效的Grounded Perceiver来更好地利用基于掩码的中间指导,从而提高操纵性能 。
大型视觉-语言模型:本文,利用GLaMM模型生成目标物体和放置区域的接地掩码,为低级策略网络提供结构化指导。
4.实验设计和方法
4.1
总体架构设计
论文提出的ROBOGROUND框架旨在通过将接地掩码作为中间表示来增强机器人操纵策略的泛化能力。
接地视觉-语言模型:
基础模型:模型以图像和文本指令作为输入,使用CLIP视觉编码器获取视觉特征,并通过MLP投影到LLM的嵌入空间。LLM结合视觉特征和文本指令生成文本输出 。
像素级接地:团队使用一个微调过的SAM编码器和一个类似SAM的解码器。一个特殊的标记被引入LLM的词汇表中,用于提取与接地相关的特征。
接地策略网络:
基础模型:网络遵循GR-1模型架构,处理历史图像观察、机器人状态和语言指令序列来预测未来的机器人动作 。
掩码整合机制:对于每个输入图像,其对应的掩码Mo和Mp通过通道拼接的方式整合进来。拼接后的图像输入通过一个线性层投影回3个通道,然后输入到预训练的ViTMAE编码器中。
接地感知器:感知器接收来自视觉编码器的补丁特征,并引入两组额外的查询token,分别对应目标物体和放置区域,它们在注意力层与补丁特征交互时,通过掩码进行引导 。
5. 实验结果分析
5.1
仿真环境与基线模型
实验在RoboCasa仿真环境中进行,该环境提供了自动化的场景生成流水线。研究团队将原始RoboCasa数据集归类为“简单”任务,并生成了包含“外观”、“空间”和“常识”三类指令的复杂拾取-放置任务,以及开/关门、按按钮等基本操纵技能任务。
5.2
主要结果与分析
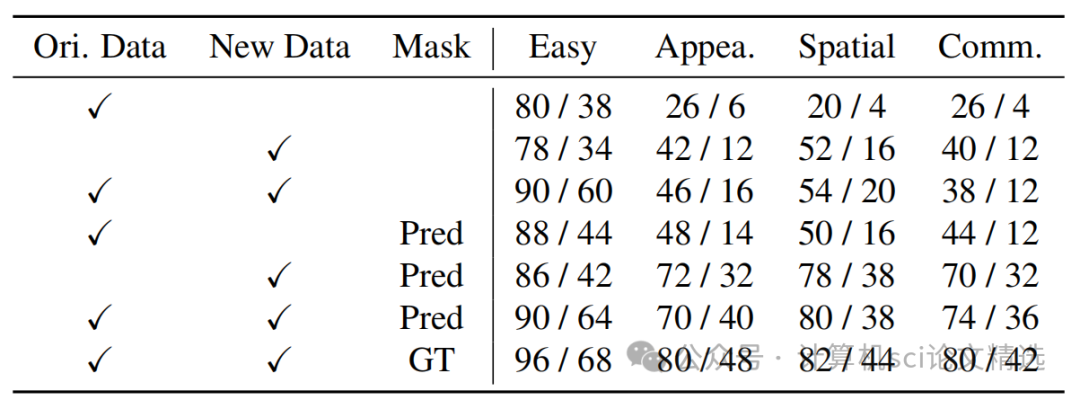
在所有任务中,ROBOGROUND方法均显著优于所有基线模型 。
在复杂任务上的表现:ROBOGROUND在“外观”、“空间”和“常识”任务上的成功率均有大幅提升,这表明接地掩码的引入对于处理语义丰富的指令至关重要 。
接触率与成功率的差距:实验观察到,接触率显著高于成功率,这表明模型的抓取能力仍有待提升。
5.3
零样本泛化评估
团队为了评估模型的泛化能力,实验设计了两种零样本设置:
未见实例:在训练数据中已存在的类别中的新物体上进行评估。
未见类别:在训练数据中未出现过的全新类别中的物体上进行评估 。

6.论文总结展望
6.1
论文总结
这篇论文成功地提出了ROBOGROUND这一新颖的机器人操纵策略,通过将“接地掩码”作为中间表示,显著增强了机器人策略的泛化能力。作者认为,接地掩码能够有效地平衡空间指导的精度和泛化潜力,为机器人策略网络提供了关键的结构化信息。为了验证这一方法的有效性,研究团队设计了一套自动化数据生成流水线,构建了一个包含大规模、高复杂度和多样化指令的仿真数据集。通过在这一挑战性数据集上与多个基线模型进行广泛对比实验,以及在零样本设置和消融研究中的深入分析,论文有力地证明了该方法在处理复杂、新颖场景和指令时的优越性。
6.2
论文展望
团队认为,尽管ROBOGROUND取得了显著成果,但论文也指出了未来的研究方向:
提升抓取精度:实验结果显示接触率与成功率之间存在差距,这表明模型的抓取能力仍有提升空间。
探索更复杂的任务:当前的研究主要集中在拾取和放置任务以及一些基本技能上。未来的工作可以扩展到更复杂的、需要多步骤规划和更精细操纵的机器人任务。
真实世界部署:当前工作主要在仿真环境中进行。将该方法泛化并部署到真实世界机器人上,将是未来的一个重要研究方向,需要解决仿真与现实之间的差距问题。
更高效的接地模型:未来可以探索更轻量级或更高效的接地模型,以加快推理速度并降低计算资源需求。
本文选自gongzhonghao【计算机sci论文精选】