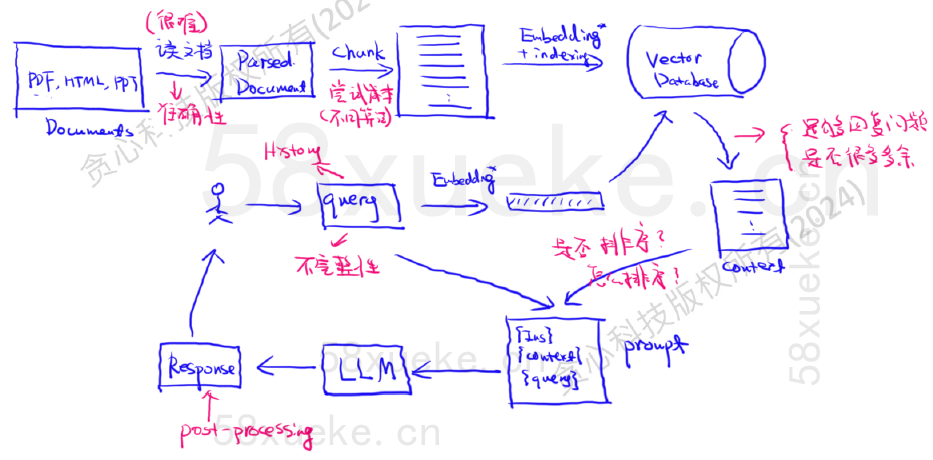
RAG所存在的问题和解决方案
经典RAG流程
https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
问题:文档解析准确性
很重要的工作。要获得高质量数据,确保解析的文档是正确的,解析率很高。
问题:chunk的方式
chunk很多要考虑的点。多尝试chunk的方法,确保每个chunk表达的都是同一个主题或者是完整的主题。很难评价哪个方法更好。
问题:query
query清洗。可能存在不完整、不准确、很复杂的问题。
案例1(Self-querying)
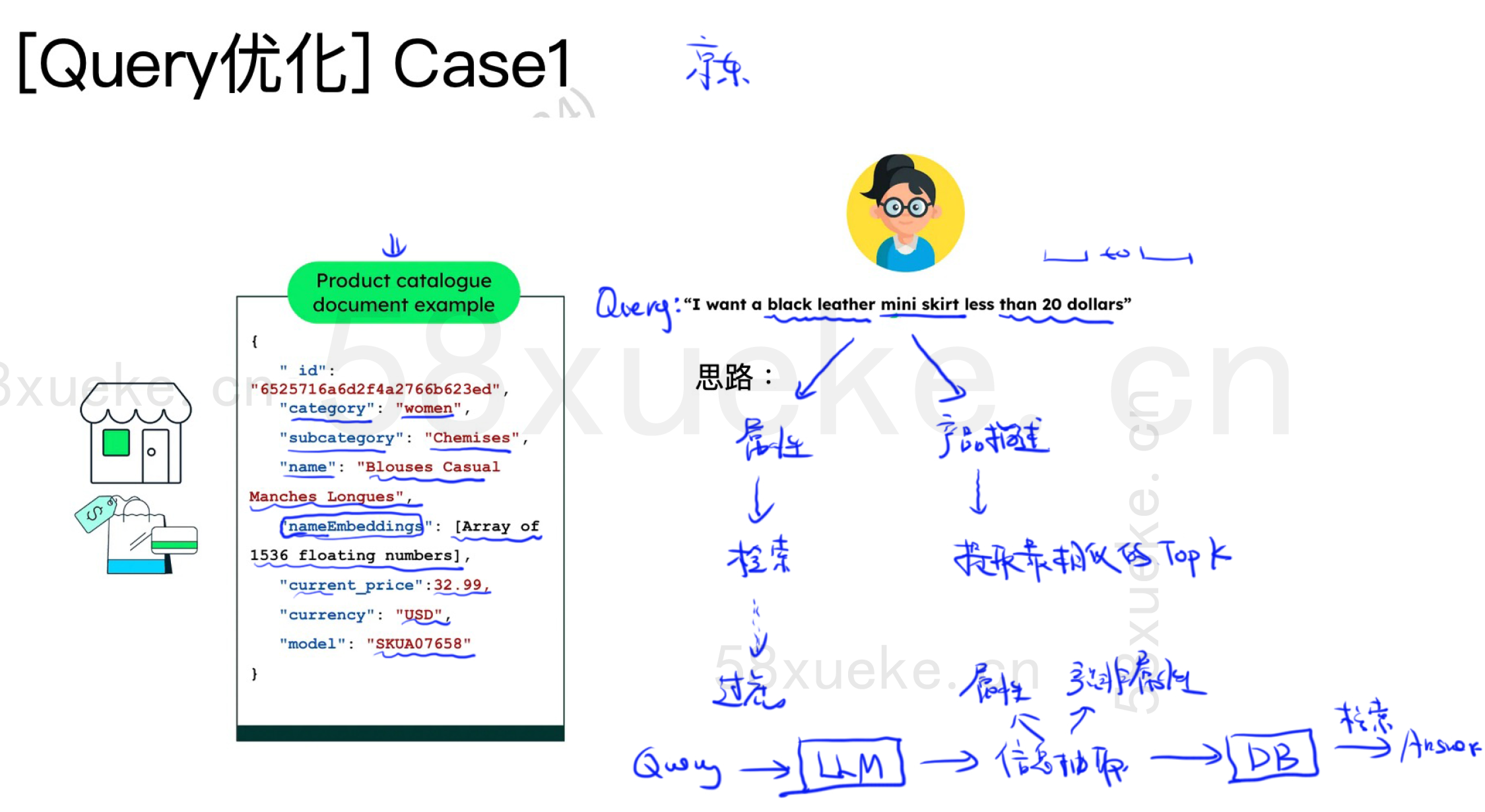
不能直接把query做embedding,不然效果比较差。
可以从query中用大模型抽取出属性和产品描述(非属性)。属性可以在检索系统中进行过滤。产品描述可以提取最相似的top k个。
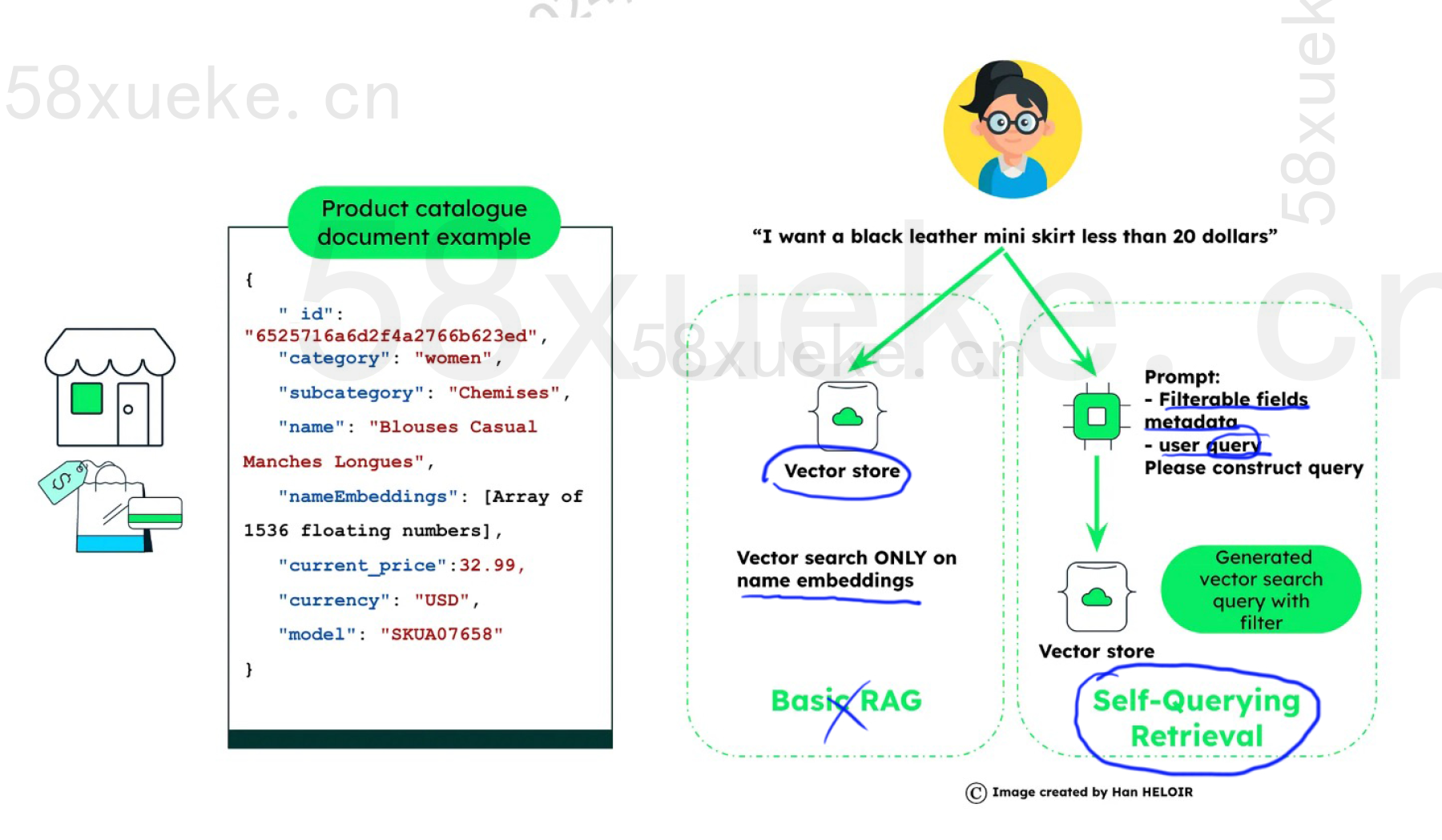
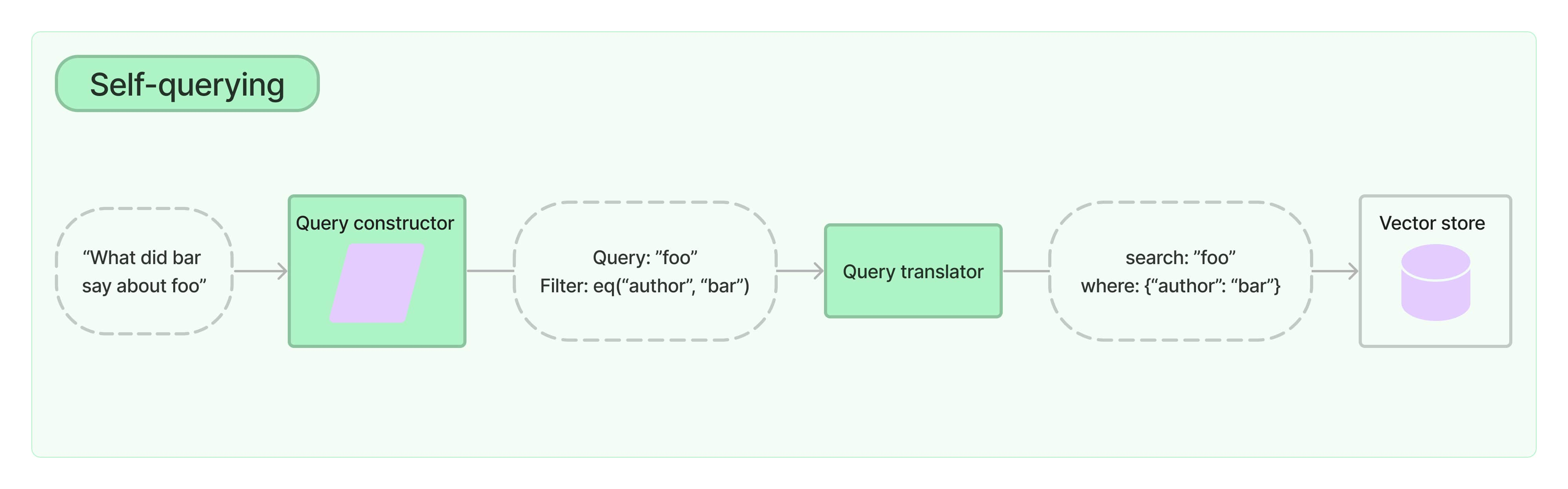
How to do "self-querying" retrieval | 🦜️🔗 LangChain
案例2(MultiQueryRetriever)
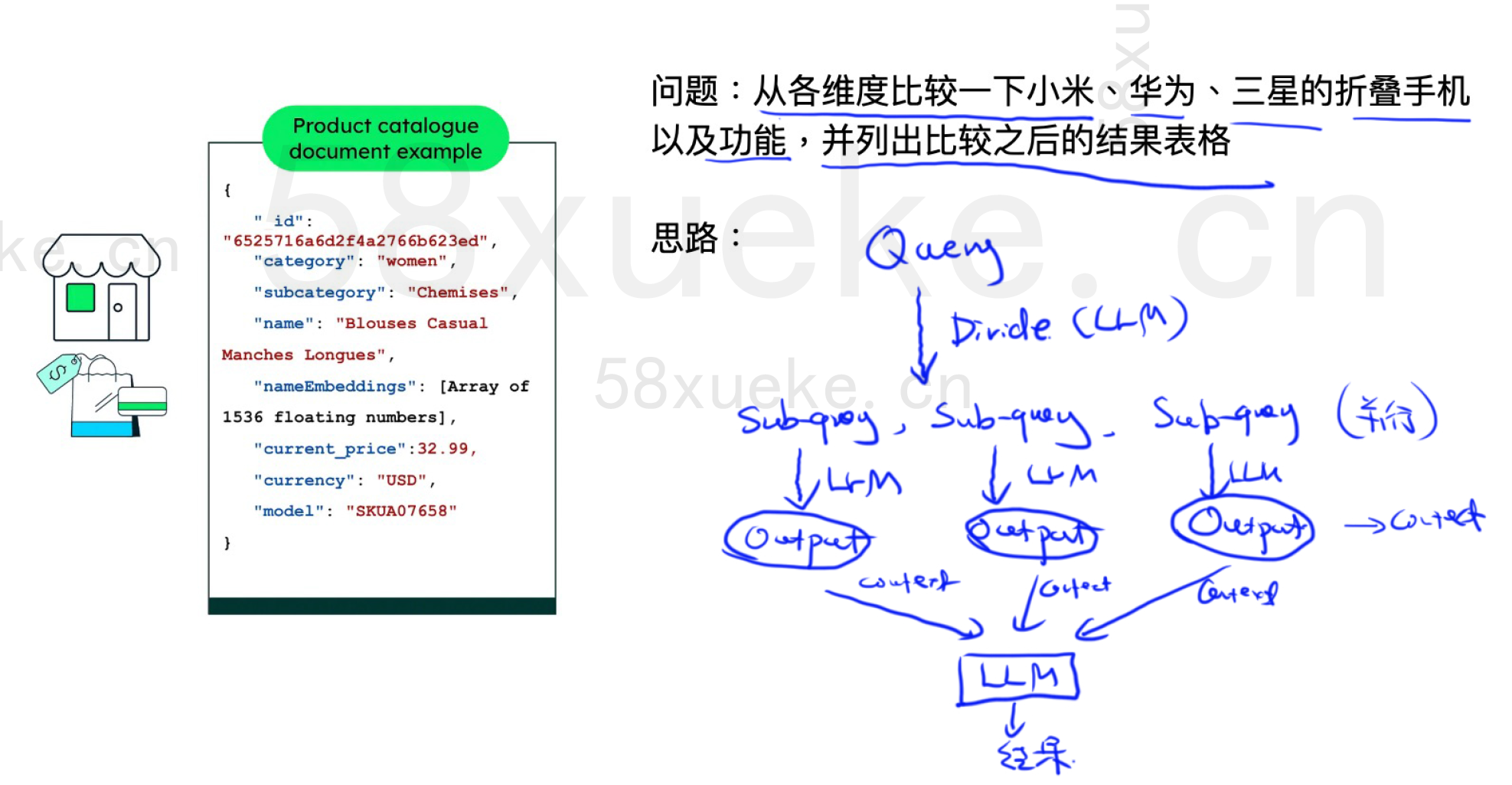
直接embedding可能会丧失品牌信息。从query中分为几个产品,分别得到不同产品的信息,然后将output输入到大模型中进行比较从而得到最终的结果。

How to use the MultiQueryRetriever | 🦜️🔗 LangChain
案例3(Step-Back Prompting)

我们询问对一个变量的计算结果,可能输出错误。遇到具体的问题时,先退一步,想一个更宽泛的问题,把这个问题解决之后,再来看当前的问题。

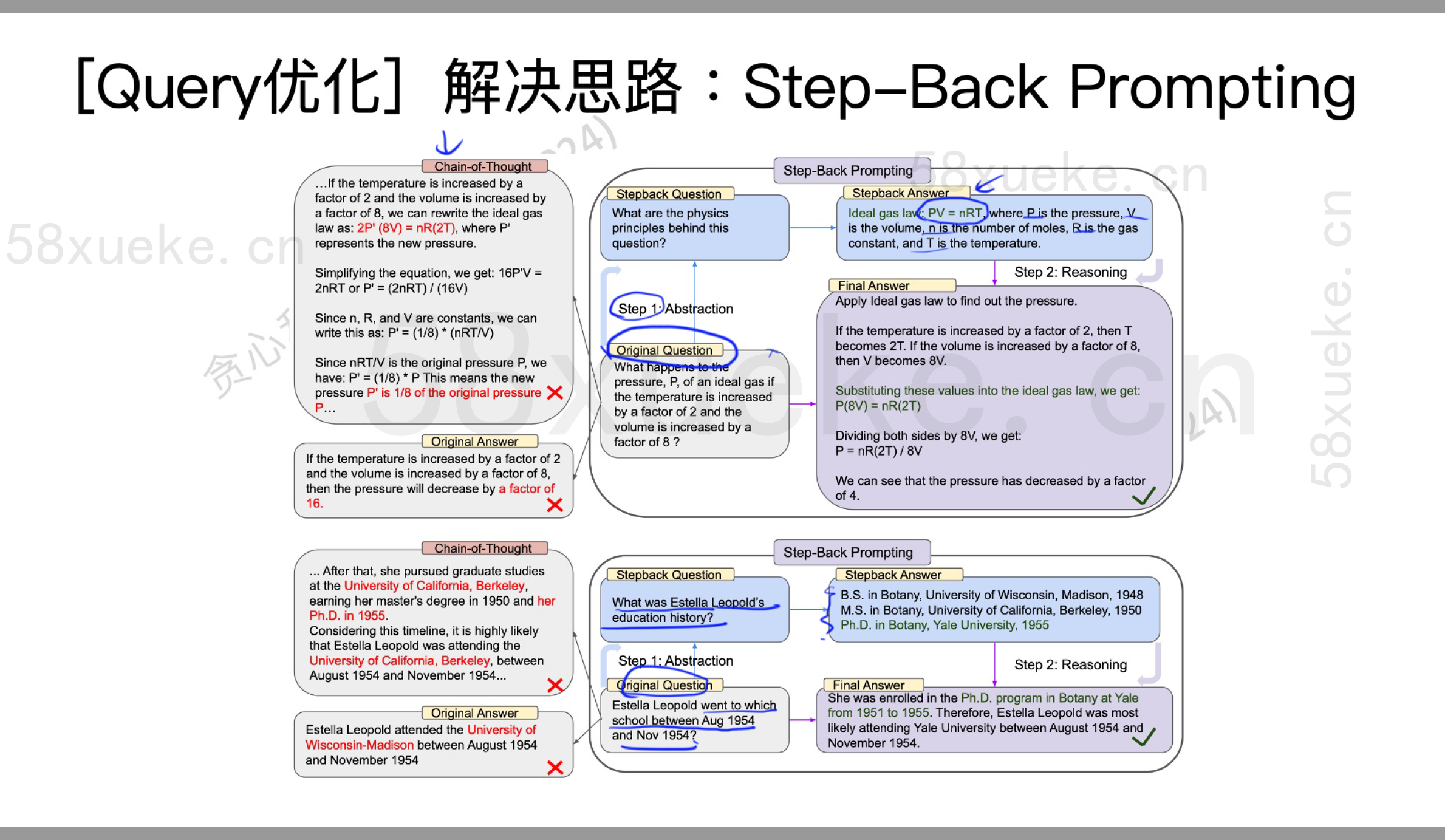
[2310.06117] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
把stopback answer和original question拼在一起丢。
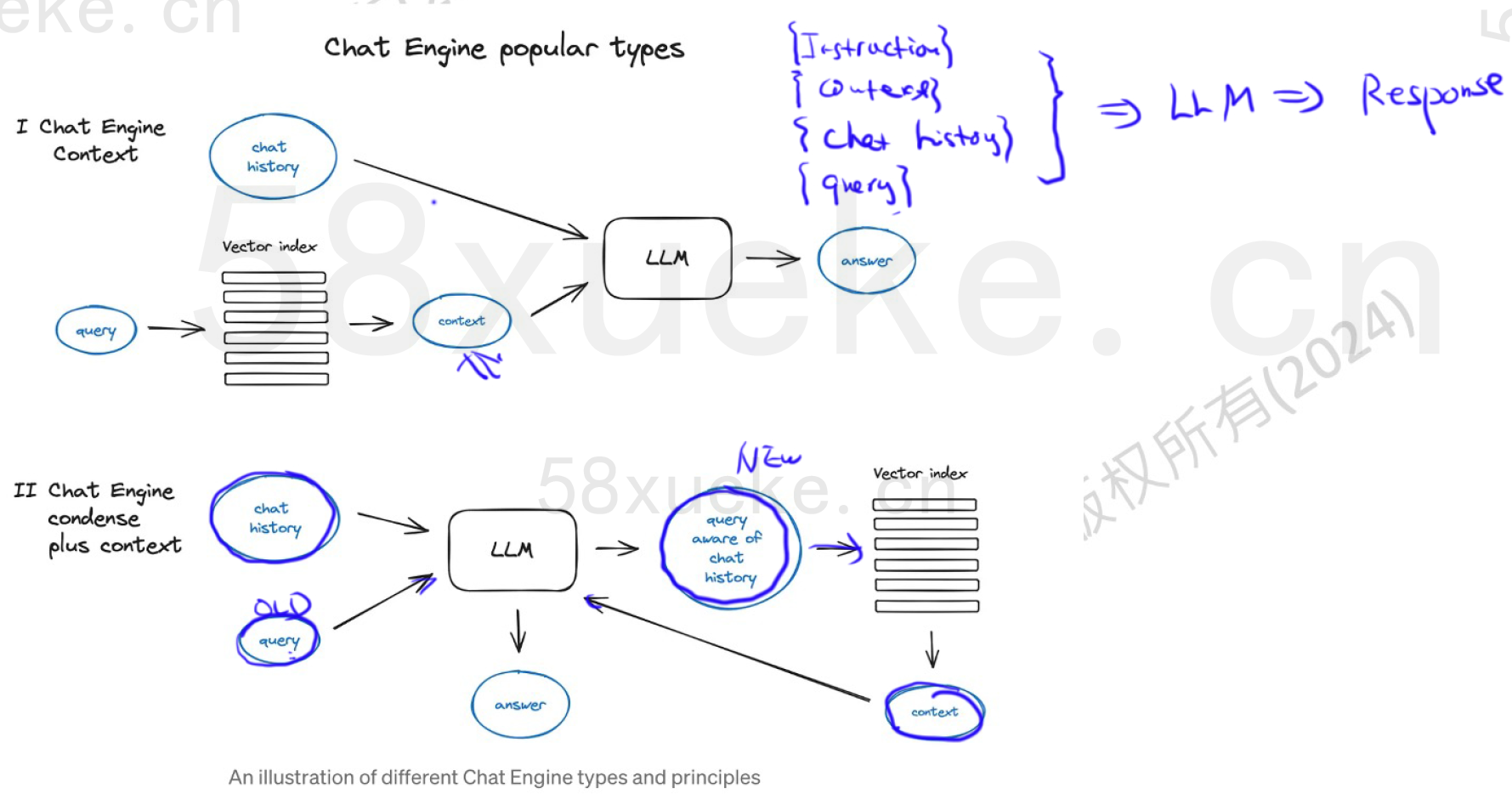
案例4(基于历史对话生成query)
问题:如何更好地处理多轮对话?如何处理conversation history?
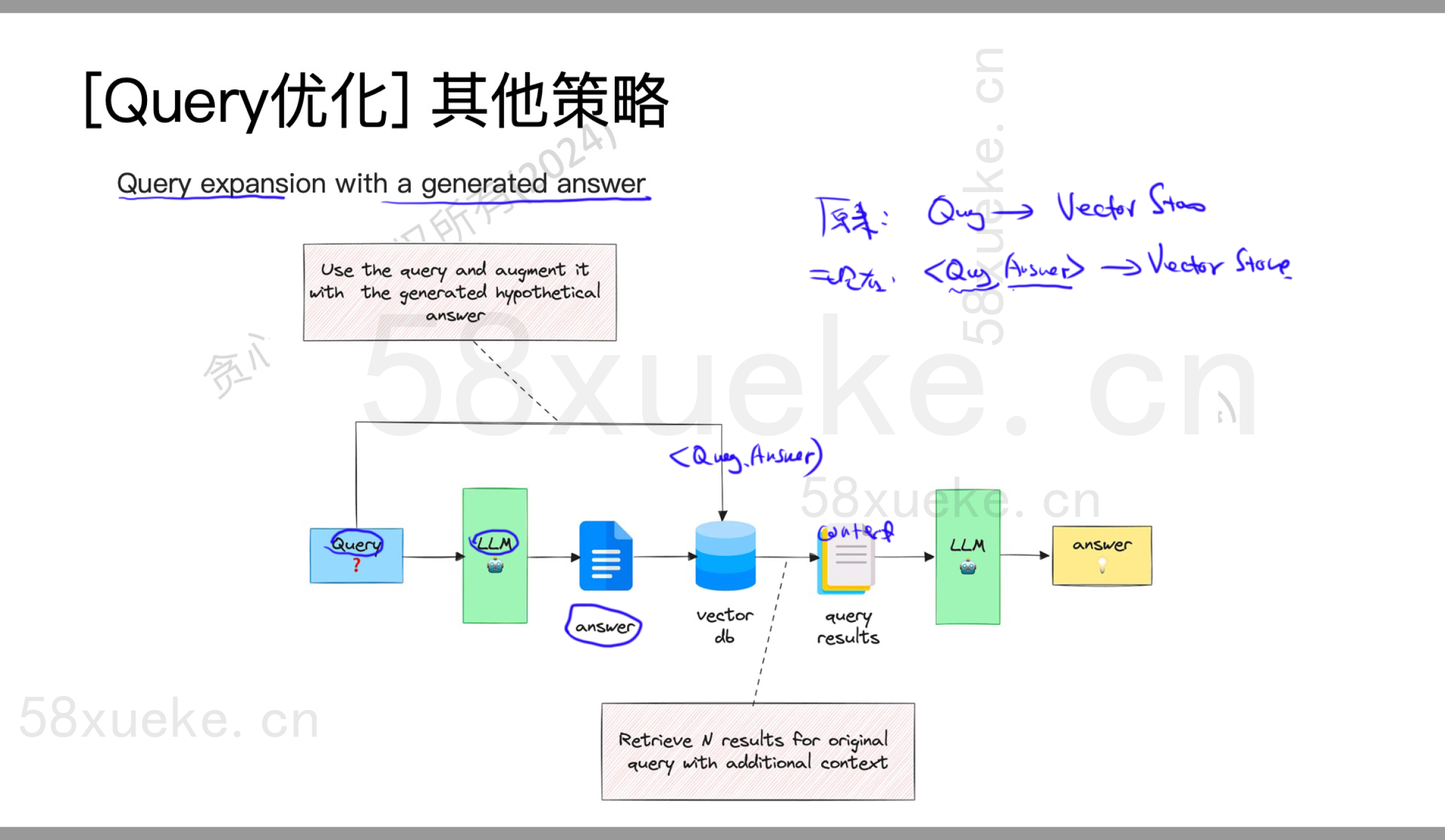
其他策略
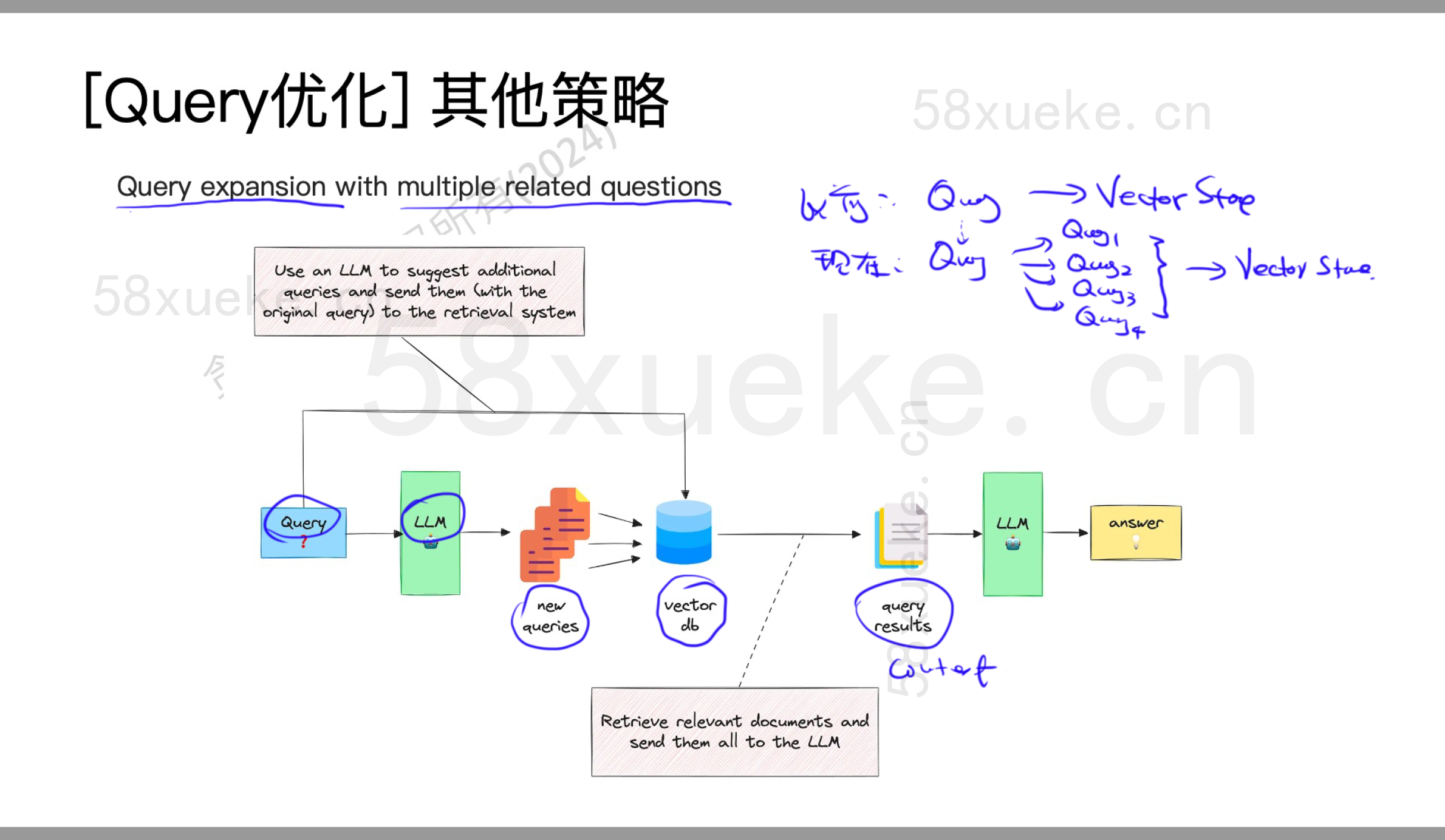
问题:检索问题(Retriever)
是否足够回答问题?是否有很多是多余的?主要问题如下:
1.检索出来的Context并没有包含想要的信息(Context缺失回答问题有帮助的信息)
2.检索结果不准确,最终返回的是跟问题不太相关的结果
3.仅靠Embedding检索的结果缺失我们想要的context
Sentence Window Retrieval
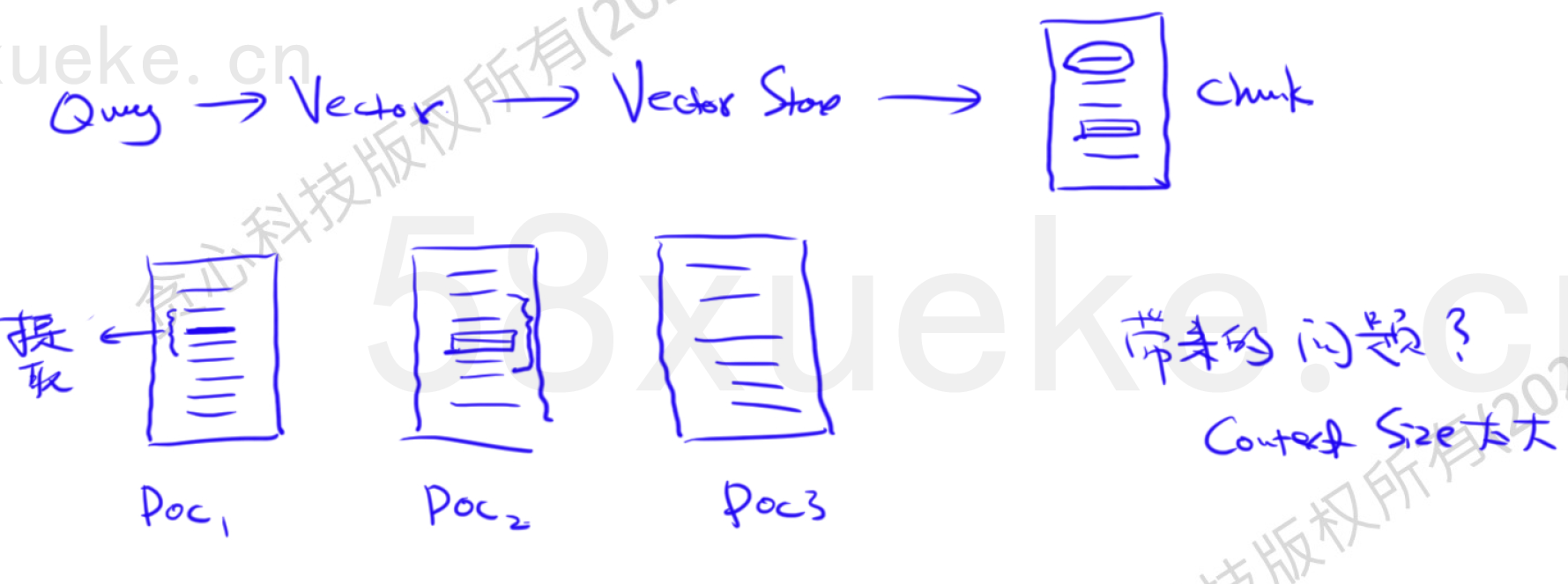
以句子为粒度做向量检索(更精细),在命中的句子周围取一个窗口的上下文(保证语义完整)。

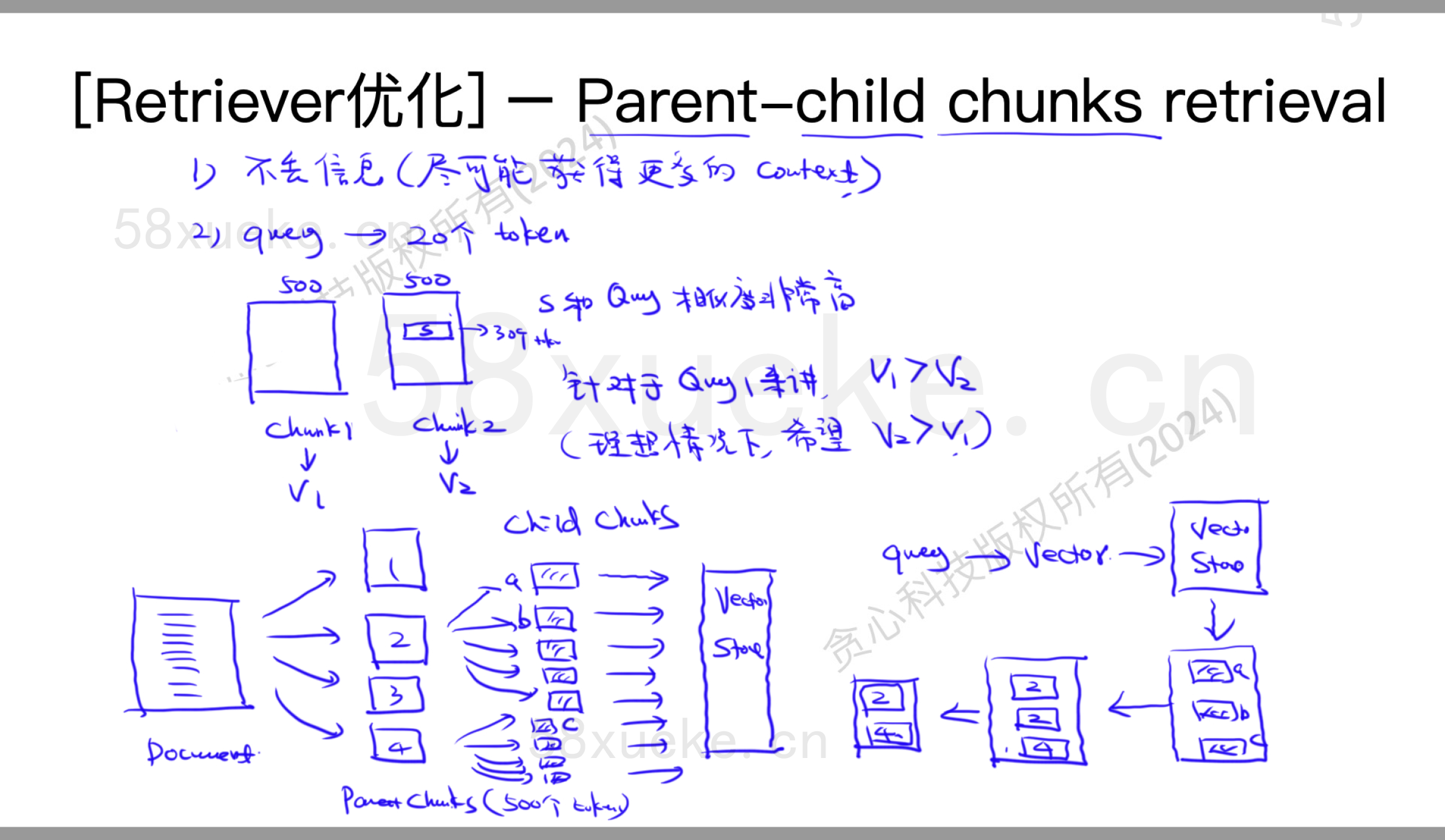
Parent-child chunks retrieval
How to use the Parent Document Retriever | 🦜️🔗 LangChain
解决问题:①不丢失信息;②向量数据库中其中一段话s跟query相似度非常高,但是整句话综合后s相似度下降,没有其他的高。
矛盾:query不能设计地过小;query尽可能小的时候,准确率可能更高。
解决:Parent-child chunks retrieval
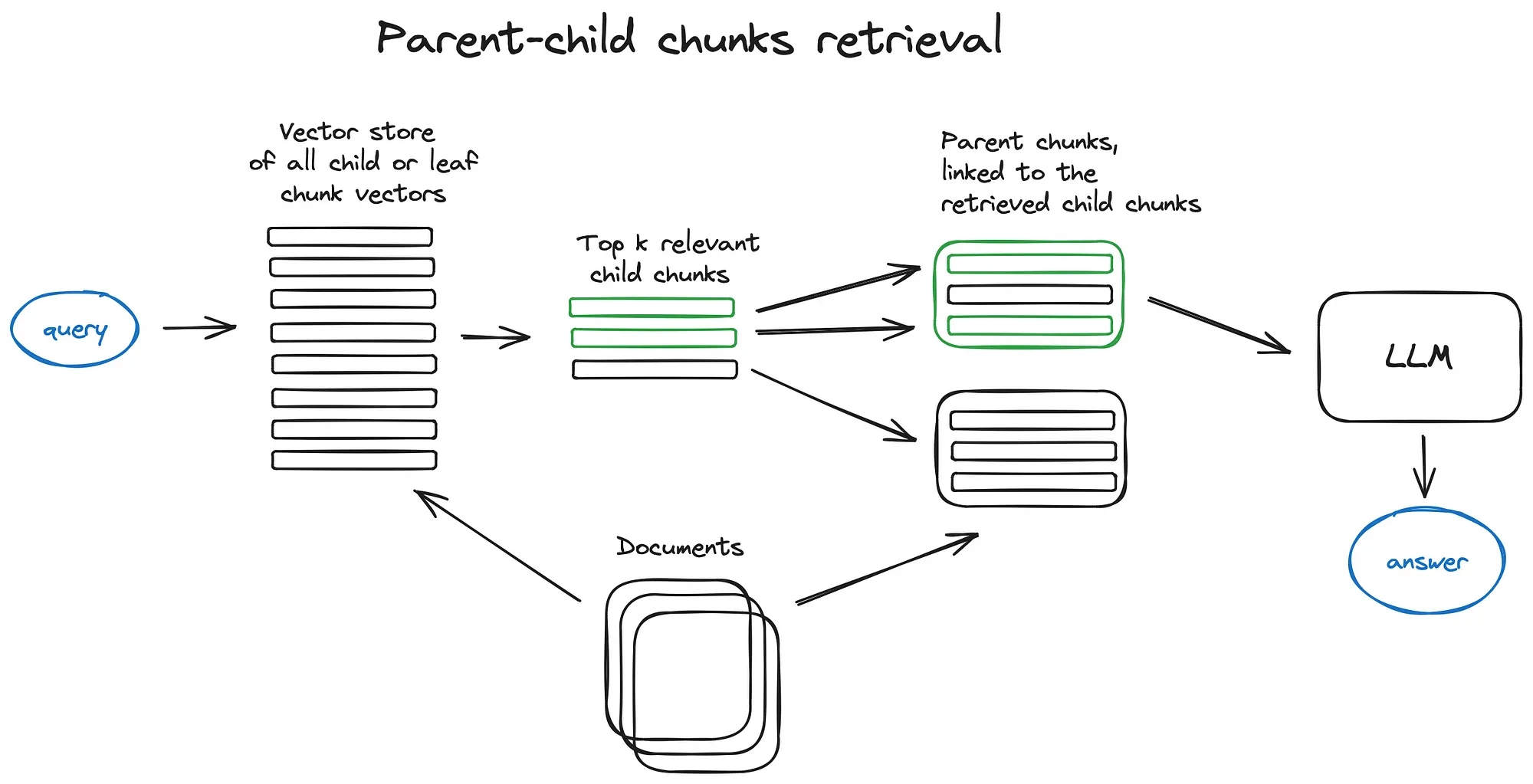
步骤:文档分为一些trunks,然后把每个parent trunk再分为几个child chunks。然后将,child chunks存在向量数据库中。搜索时是在child chunks上搜索/计算,返回是返回这些child chunks属于哪个parent chunks。
问题:可能parent chunks可能非常大。建议做rag。
Fusion Retrieval
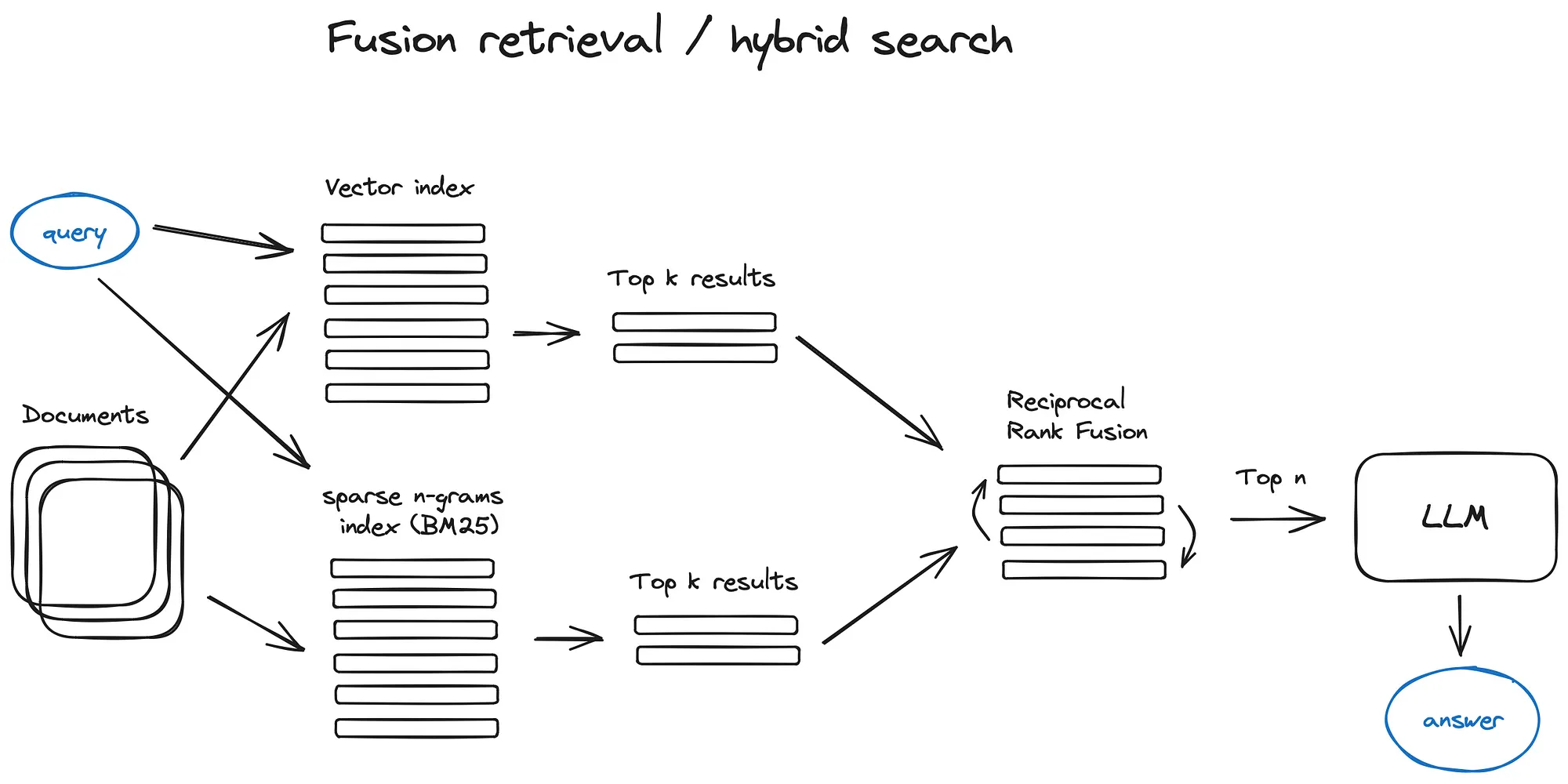
将不同检索系统下地结果合在一起。
问题:当我们要融合结果时该怎么排序?比如不同结果来自不同地排序结果?
问题:搜索结果排序(ranking)
上下文窗口大小不满足把所有的搜索结果都塞进去,所以我们需要做排序。排序怎么样?是否需要排序?怎么排序?
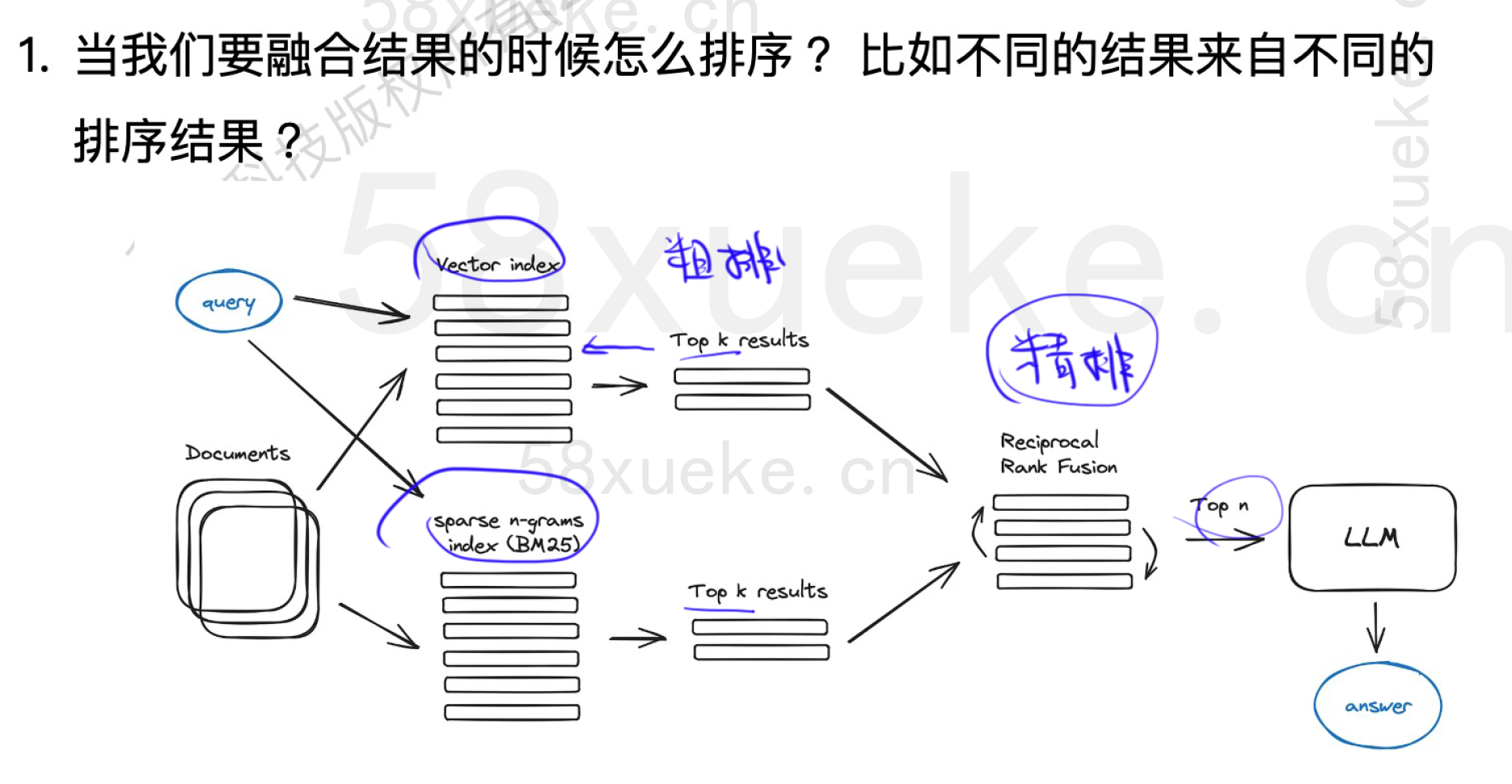
Ensemble Retriever
langchain提供一个模块Ensemble Retriever,集成了一些简单的排序算法。有些排序算法或场景可能不是我们需要的,但这时候我们又需要精排的话,这需要我们自己手搓。Ensemble Retriever是为上述流程(排序)设计的。
How to combine results from multiple retrievers | 🦜️🔗 LangChain

步骤:同时用多个检索器搜索,把结果融合(加权、排序、去重)。
Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods
问题:response
response是否有问题?有可能需要做一些post-processing。
RAG的评估(RAGS)
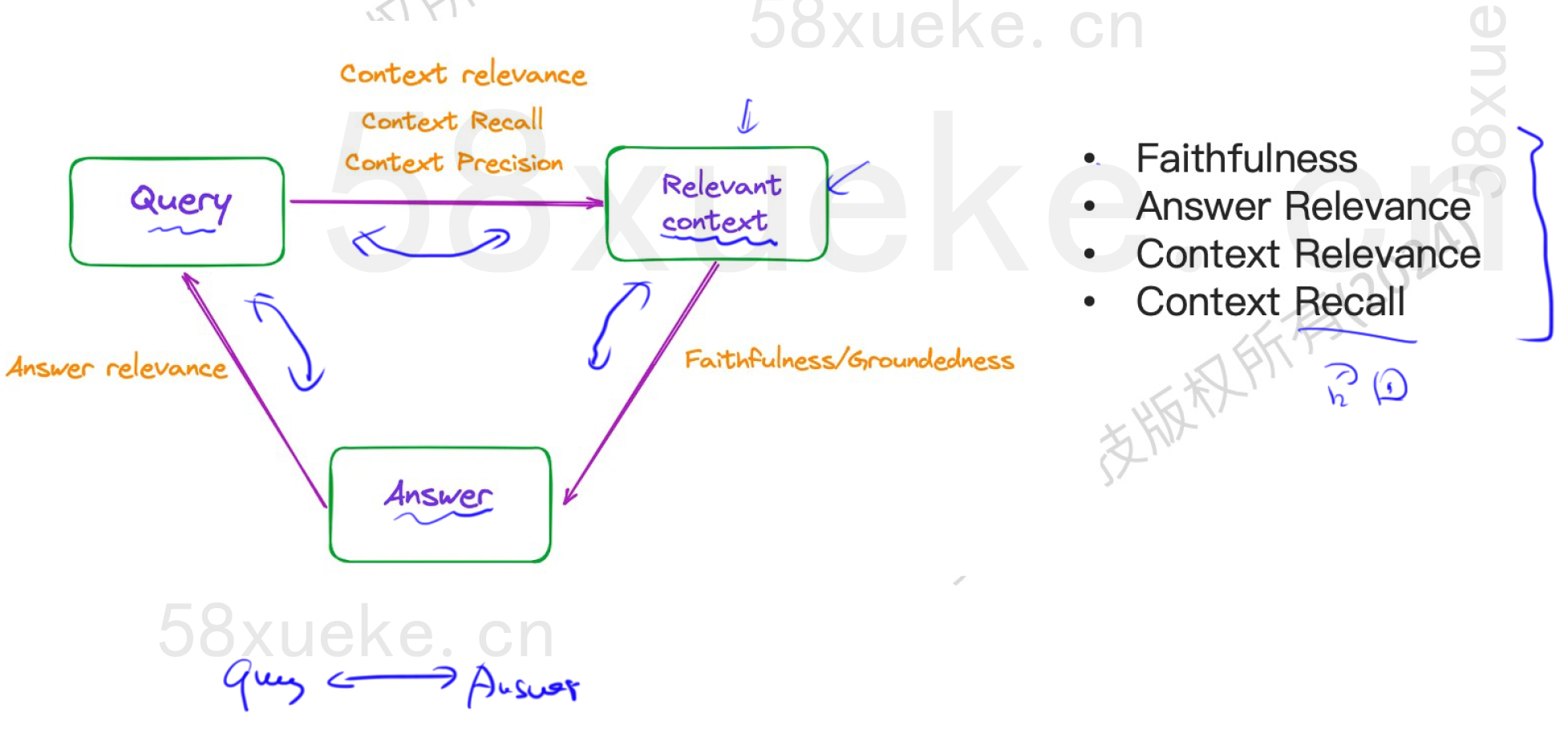
Faithfulness

关心回答是否正确。answer可以拆解成很多statements(用LLM),关心它们是否在context中提到过。

计算逻辑:answer有很多statement,我们再通过大模型判断statement是否是正确的。

Answer Relevance
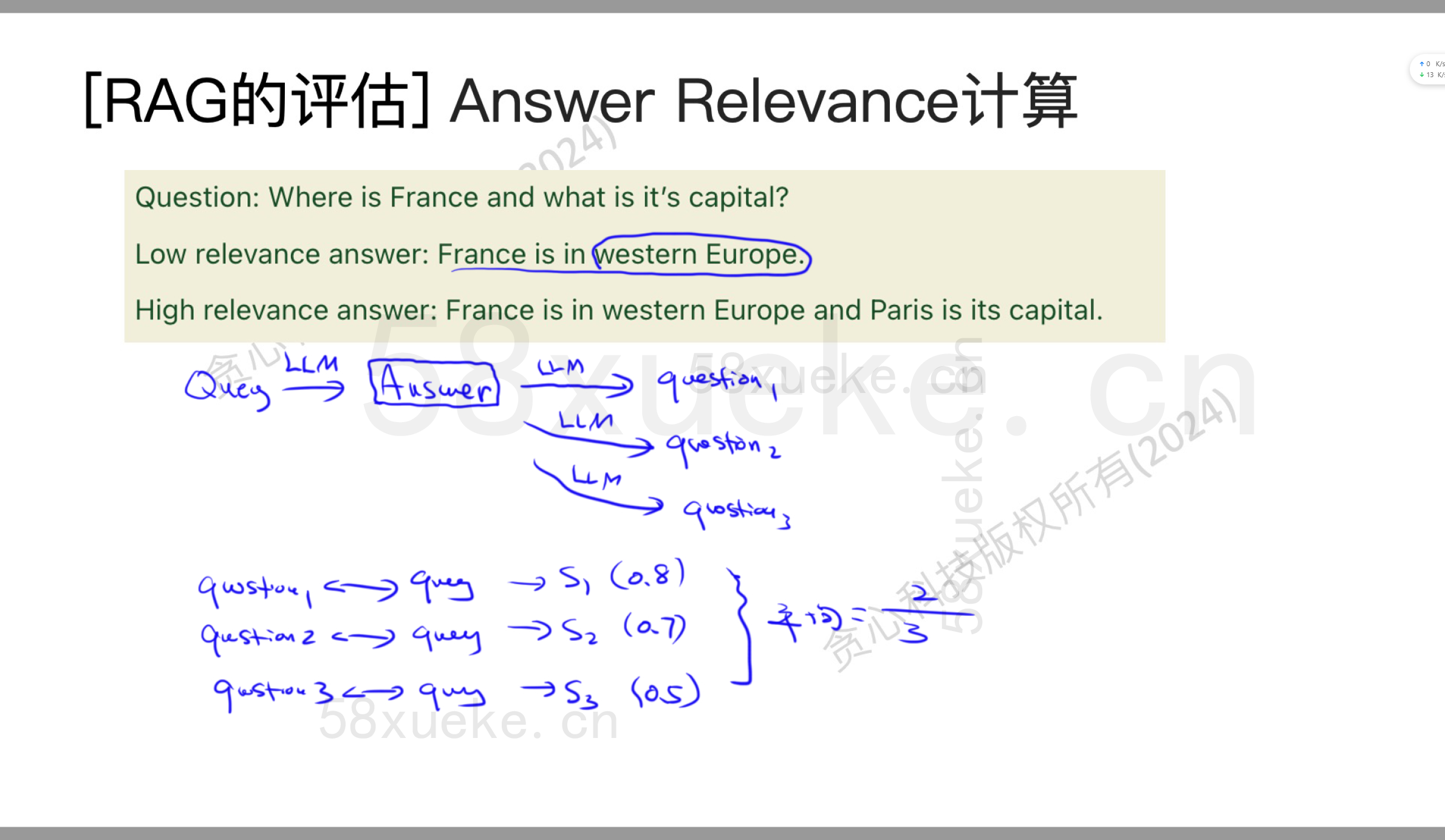
一个query得到answer。基于这个answer,我们反向生成很多questions,接下来我们判断生成的问题跟query之间的相似度,算出平均相似度。


Context Relevance

其他Metric
- Context Recall
- Context Precision
- Answer semantic similarity
📚 Core Concepts - Ragas