spring-ai整合PGVector实现RAG
背景
最近公司的产品和业务线,要求往ai方向靠拢,在研发各种智能体,整理下最近学习的过程,将一部分内容整理出来,分享给需要的同学。
这篇文章将会提供详细的例子以及踩坑说明。主要内容是整合spring-ai,同时本地借助ollama平台部署本地模型,并基于PostgreSQL实现向量的存储,实现最基本的RAG能力。
准备工作
安装ollama部署本地大模型
首先,我们进入ollama官网Ollama,下载ollama安装包,具体不赘述。
本地安装完之后,打开命令行工具:
输入命令:ollama -h获取相关的提示
C:\Users\Administrator>ollama -h
Large language model runnerUsage:ollama [flags]ollama [command]Available Commands:serve Start ollamacreate Create a model from a Modelfileshow Show information for a modelrun Run a modelstop Stop a running modelpull Pull a model from a registrypush Push a model to a registrylist List modelsps List running modelscp Copy a modelrm Remove a modelhelp Help about any commandFlags:-h, --help help for ollama-v, --version Show version informationUse "ollama [command] --help" for more information about a command.然后基于ollama pull命令下载大模型到本地(具体哪些模型,可以去ollama官网搜索):
C:\Users\Administrator>ollama list
NAME ID SIZE MODIFIED
shaw/dmeta-embedding-zh:latest 41783961c26d 408 MB 13 hours ago
llama3:latest 365c0bd3c000 4.7 GB 37 hours agoC:\Users\Administrator>示例中,我们下载了2个模型:
shaw/dmeta-embedding-zh:是嵌入式模型(Embedding model),仅用于内容将文本转化为向量,无法用于内容生成,如对话等。我们后面的示例中会使用这个嵌入模型做向量化处理。
llama3:生成式模型,可以用于文本内容生成,如对话等
ollama run 命令详解
1. 作用与功能
-
核心功能:启动交互式对话会话
-
工作流程:
-
检查模型是否在本地
-
若不存在则自动下载 (
ollama pull) -
加载模型到内存
-
启动 REPL(读取-求值-打印循环)环境
-
等待用户输入并生成响应
-
2. 使用限制
-
仅支持对话模型:如 Llama 3、Mistral 等生成式模型
-
不支持嵌入模型:如
dmeta-embedding-zh等向量模型
安装PostgreSQL及Vector扩展
PostgreSQL主要用于向量数据的存储,因为其天生的特性优势,以及自带的扩展插件等,可以用于向量数据的存储。
首先在官网PostgreSQL: The world's most advanced open source database下载安装包,选择自己合适的版本。
我们选择16.9版本,下载并安装。安装过程不再赘述。安装完成后,基于PG-admin4管理工具可以看到安装好的PostgreSQL.
接下来安装vector插件:https://github.com/pgvector/pgvector/tags
网上没找到预编译的版本,要基于源码自己编译打包才行:
源码下载到本地解压:
安装visual studio 2022版本,利用VS的编译工具。
打开命令行工具,执行命令:
call "C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvars64.bat"
cd D:\software\pgvector-0.7.3
set "PGROOT=D:\software\postgre16"
nmake /F Makefile.win
nmake /F Makefile.win install如果执行时,报错nmake命令找不到,则说明是visual studio安装的不对缺少必要插件。解决方式如下:
步骤 1:安装缺失的 C++ 组件
-
打开 Visual Studio Installer
-
找到已安装的 Visual Studio Community 2022
-
点击 "修改"
-
在 "工作负载" 选项卡中:
-
勾选 "使用 C++ 的桌面开发"
-
在右侧 "安装详细信息" 中确保选中:
-
MSVC v143 - VS 2022 C++ x64/x86 生成工具
-
Windows 10 SDK(或 Windows 11 SDK)
-
C++ CMake 工具
-
-
-
点击 "修改" 按钮开始安装
步骤 2:验证安装
安装完成后,检查以下路径:
# 默认路径
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvars64.bat# 备选路径
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvarsamd64_x86.bat
C:\Program Files\Microsoft Visual Studio\2022\Community\Common7\Tools\VsDevCmd.bat然后重新执行前面的编译工作即可,此时就会把vector扩展安装到postgre本地的安装目录下。
插件安装完之后,进入PGAdmin4工具,创建扩展及表结构:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS hstore;
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE IF NOT EXISTS vector_store (id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,content text,metadata json,embedding vector(1536) // 1536 is the default embedding dimension
);搭建工程
引入依赖
废话不多说,直接提供maven依赖的配置信息:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.5.4</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.zxm</groupId><artifactId>spring-ai-agent</artifactId><version>0.0.1-SNAPSHOT</version><name>spring-ai-agent</name><description>Demo project for Spring Boot</description><url/><licenses><license/></licenses><developers><developer/></developers><scm><connection/><developerConnection/><tag/><url/></scm><properties><java.version>17</java.version><spring-ai.version>1.0.1</spring-ai.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-advisors-vector-store</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-client-webflux</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-server-webflux</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-ollama</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-pgvector</artifactId></dependency><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>io.projectreactor</groupId><artifactId>reactor-test</artifactId><scope>test</scope></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><annotationProcessorPaths><path><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></path></annotationProcessorPaths></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
application.yaml配置
server:port: 8090
spring:application:name: spring-ai-agentai:ollama:base-url: http://localhost:11434embedding:options:#model: llama3:latestmodel: shaw/dmeta-embedding-zh:latestmodel:embedding: ollamadatasource:url: jdbc:postgresql://localhost:5432/ai-vectorusername: rootpassword: rootdriver-class-name: org.postgresql.Driverhikari:connection-timeout: 30000maximum-pool-size: 5编写逻辑
首先定义PGVectorStore的配置类:
package com.zxm.spring.ai.agent.config;import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;import javax.sql.DataSource;import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgDistanceType.COSINE_DISTANCE;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgIndexType.HNSW;@Configuration
public class PgVectorVectorStoreConfig {@Beanpublic VectorStore pgVectorVectorStore(@Qualifier("vectorJdbcTemplate") JdbcTemplate jdbcTemplate,EmbeddingModel embeddingModel) {return PgVectorStore.builder(jdbcTemplate, embeddingModel).dimensions(768) // 与嵌入模型维度对齐.distanceType(COSINE_DISTANCE) // 余弦相似度计算.indexType(HNSW) // 高效近似最近邻搜索.initializeSchema(false) // 自动初始化表结构.build();}@Bean("vectorJdbcTemplate")public JdbcTemplate jdbcTemplate(DataSource dataSource) {return new JdbcTemplate(dataSource);}
}这里有个插曲,最开始选择的模型是llama3,当时参考的示例中配置的向量的默认维度的1536,后来运行程序时报错:
org.postgresql.util.PSQLException: 错误: expected 1536 dimensions, not 4096经过排查后发现,llama3的维度是4096,嵌入模型的维度与vector存储的dimensions必须保持一致,使用hnsw索引,在修改表的维度时,报错: column cannot have more than 2000 dimensions for hnsw index,因此需要更换嵌入模型,使用:
shaw/dmeta-embedding-zh
编写一个Controller,实现向量转换以及存储的逻辑:
package com.zxm.spring.ai.agent.controller;import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.*;import java.util.Arrays;
import java.util.List;/*** @Author* @Description* @Date Create in 下午 2:30 2018/12/21 0021*/
@RestController
@RequestMapping("/embeding")
public class EmbeddingController {@Resourceprivate EmbeddingModel embeddingModel;// 加载指定的资源文件@Value("classpath:document/医院.txt")private org.springframework.core.io.Resource resource;@Resourceprivate VectorStore vectorStore;@GetMapping("/embed")public Object embed() {// 返回响应对象EmbeddingResponse embeddingResponse = embeddingModel.embedForResponse(List.of("今天天气不错"));// Map<String, EmbeddingResponse> embedding = Map.of("embedding", embeddingResponse);System.out.println(Arrays.toString(embeddingResponse.getResult().getOutput()));// 直接返回向量化后的数据float[] embed = embeddingModel.embed("挺风和日丽的");System.out.println(Arrays.toString(embed));return embed;}@GetMapping("/embed2")public String embed2() {// 读取文本文件TextReader textReader = new TextReader(this.resource);// 元数据中增加文件名textReader.getCustomMetadata().put("filename", "医院.txt");// 获取Document对象List<Document> docList = textReader.read();// 向量化处理float[] embed = embeddingModel.embed(docList.get(0));// 打印向量化后的数据System.out.println(Arrays.toString(embed));// 打印Document中的原始文本数据System.out.println(docList.get(0).getText());return "success";}@GetMapping("/embed3")public String embed3() {// 读取文本文件TextReader textReader = new TextReader(this.resource);// 元数据中增加文件名textReader.getCustomMetadata().put("filename", "医院.txt");// 获取Document对象List<Document> docList = textReader.read();// 文档分割TokenTextSplitter splitter = new TokenTextSplitter();List<Document> splitDocuments = splitter.apply(docList);// 向量化处理float[] embed = embeddingModel.embed(splitDocuments.get(0));// 打印向量化后的数据System.out.println(Arrays.toString(embed));// 打印Document中的原始文本数据System.out.println(splitDocuments.get(0).getText());vectorStore.add(splitDocuments);return "success";}
}本地预先准备文件用于生成向量:
大连市第三人民医院
大医二院
中心医院
大连市第七人民医院
大医一院
铁路医院
小区门口的社区医院
甘井子社区医院测试结果
浏览器执行:http://localhost:8090/embeding/embed3
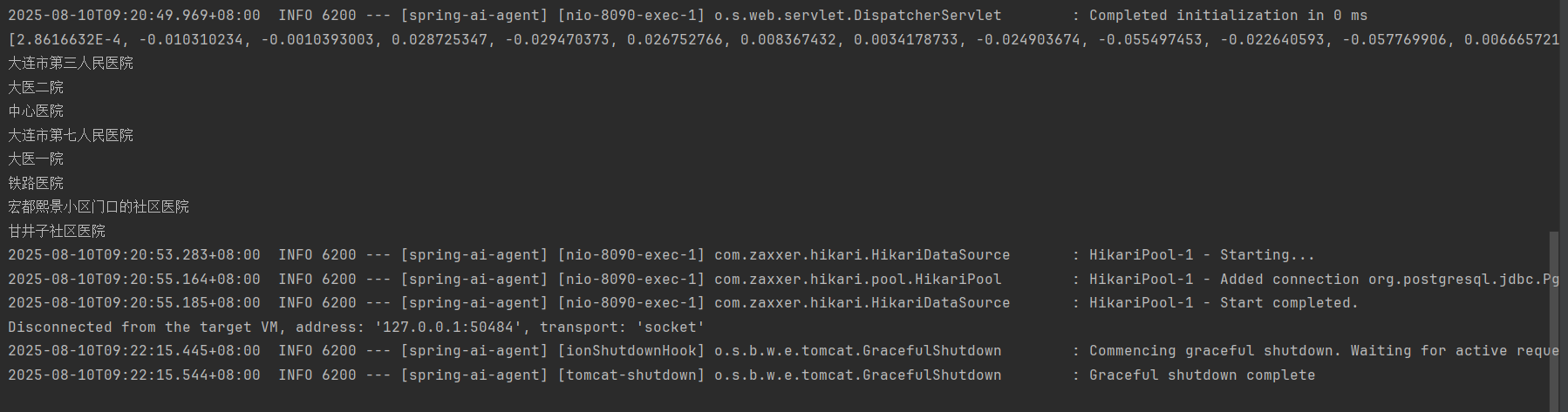
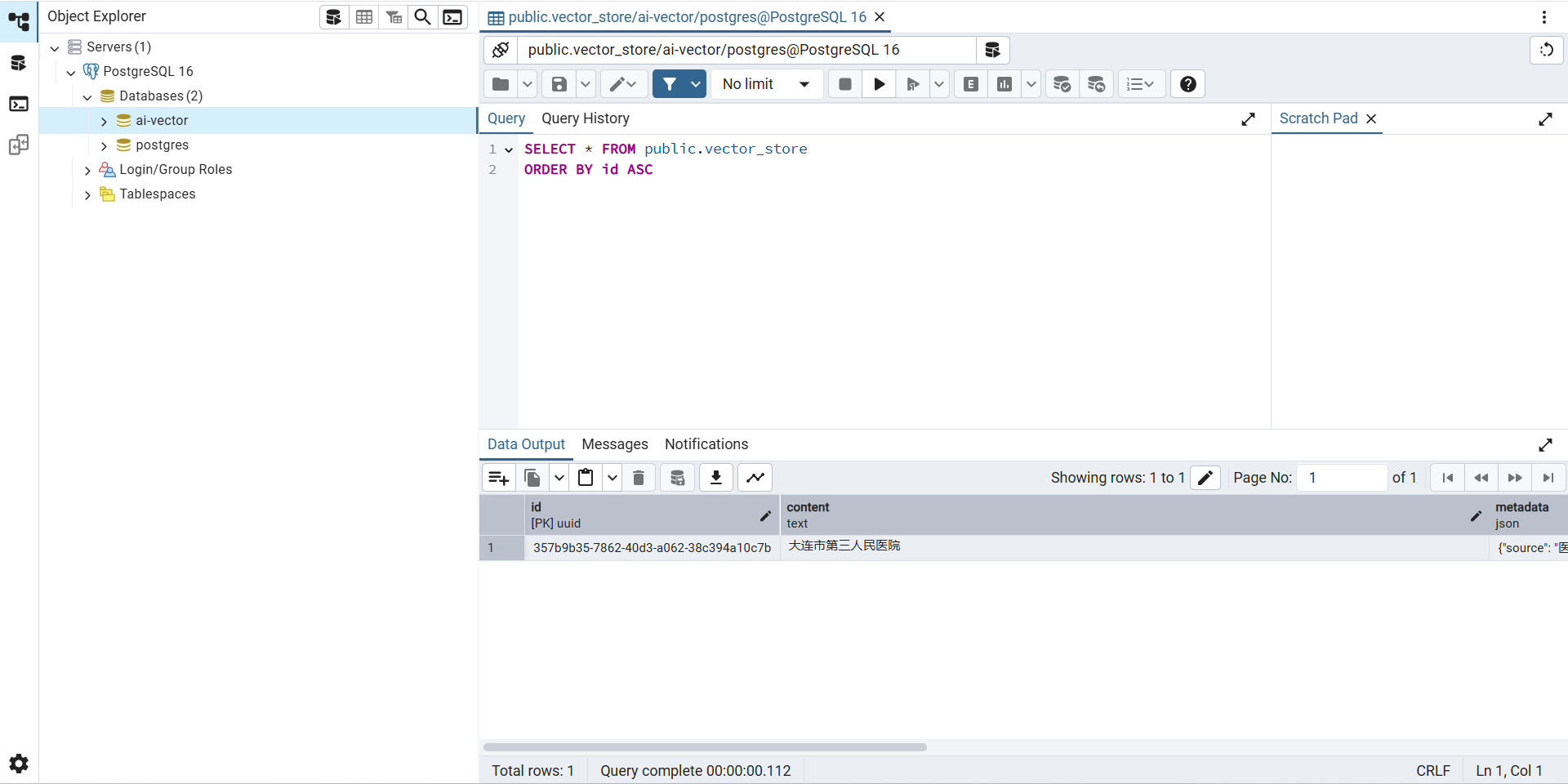
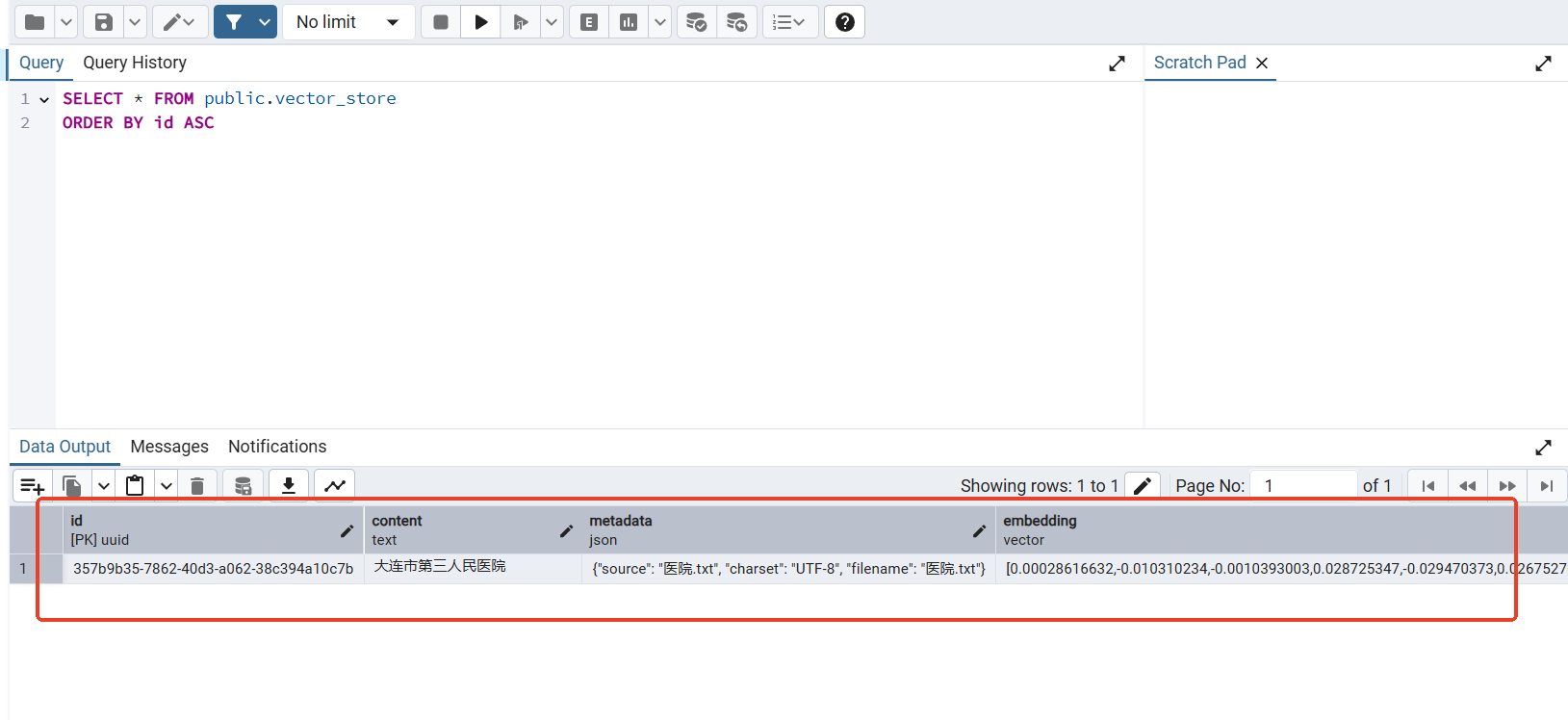
数据已经向量化,且存储到PostgreSQL中:
执行查询:http://localhost:8090/search?query=医院
返回结果:
[{"id": "357b9b35-7862-40d3-a062-38c394a10c7b","text": "大连市第三人民医院\r\n大医二院\r\n中心医院\r\n大连市第七人民医院\r\n大医一院\r\n铁路医院\r\n宏都熙景小区门口的社区医院\r\n甘井子社区医院","media": null,"metadata": {"charset": "UTF-8","source": "医院.txt","filename": "医院.txt","distance": 0.40404886},"score": 0.5959511399269104
}]实现简单的RAG能力
我们的目标是根据输入的提示,先转换成向量,然后在向量数据库中检索,然后转化成提示词的上下文信息,输入给大模型,大模型基于提示词的增强,给出准确的反馈。
编写实现的逻辑,先配置WebClient:
@Configuration
public class WebClientConfig {@Beanpublic WebClient ollamaWebClient() {return WebClient.builder().baseUrl("http://localhost:11434") // Ollama 服务地址.defaultHeader("Content-Type", "application/json").build();}
}编写核心实现逻辑:
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Mono;import java.util.HashMap;
import java.util.List;
import java.util.Map;@RestController
public class RAGController {@Autowiredprivate VectorStore vectorStore;@Autowiredprivate WebClient ollamaClient;@GetMapping("/ask")public Mono<String> askQuestion(@RequestParam String question) {// 步骤1: 向量检索相关文档List<Document> contextDocs = retrieveRelevantDocuments(question);// 步骤2: 构建LLM提示String prompt = buildPrompt(question, contextDocs);// 步骤3: 调用Llama3生成答案return generateAnswer(prompt);}// 检索相关文档private List<Document> retrieveRelevantDocuments(String query) {SearchRequest request = SearchRequest.builder().query(query).topK(3) // 获取最相关的3个文档.build();return vectorStore.similaritySearch(request);}// 构建提示模板private String buildPrompt(String question, List<Document> contextDocs) {StringBuilder contextBuilder = new StringBuilder();contextBuilder.append("请基于以下上下文回答问题:\n\n");// 添加上下文文档for (int i = 0; i < contextDocs.size(); i++) {contextBuilder.append("【上下文片段 ").append(i + 1).append("】:\n").append(contextDocs.get(i).getText()).append("\n\n");}// 添加问题contextBuilder.append("问题:").append(question).append("\n\n");contextBuilder.append("答案:");return contextBuilder.toString();}// 调用Llama3生成答案private Mono<String> generateAnswer(String prompt) {Map<String, Object> requestBody = new HashMap<>();requestBody.put("model", "llama3");requestBody.put("prompt", prompt);requestBody.put("stream", false);return ollamaClient.post().uri("/api/generate").bodyValue(requestBody).retrieve().bodyToMono(OllamaResponse.class).map(OllamaResponse::getResponse);}private static class OllamaResponse {private String response;public String getResponse() {return response;}public void setResponse(String response) {this.response = response;}}
}然后,启动ollama的生成式大模型:
浏览器调用请求:http://localhost:8090/ask?question=在宏都熙景附近去哪里看病方便?
响应结果:
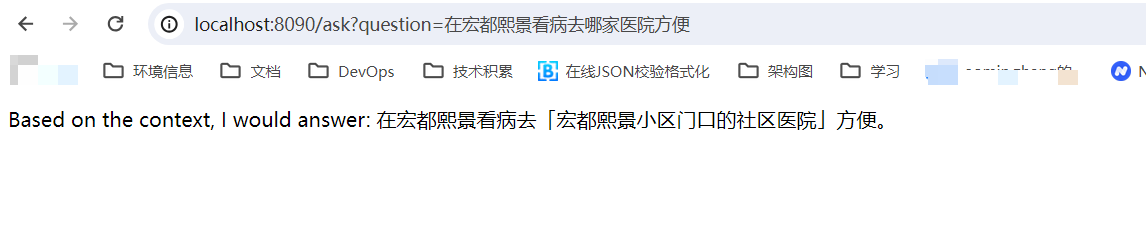
至此一个最简单的检索增强生成的案例实现完成。
总结
今天的示例先分享到这里,学习的道路是漫长曲折的,后面有机会再分享更多的内容。希望大家一起多交流,互相成长。