扩张尺度张量填充方式
需求
比如我有一个高分辨率特征张量size为[5,5],低分辨率特征张量size为[3,3],如果我想把低分辨率*2然后和高分辨率特征叠加,那就需要把[5,5]和[6,6]的张量加起来,但是维度不一致,怎么把[5,5]的张量通过填充的方式扩展到[6,6]?下面就给出两种填充方式。
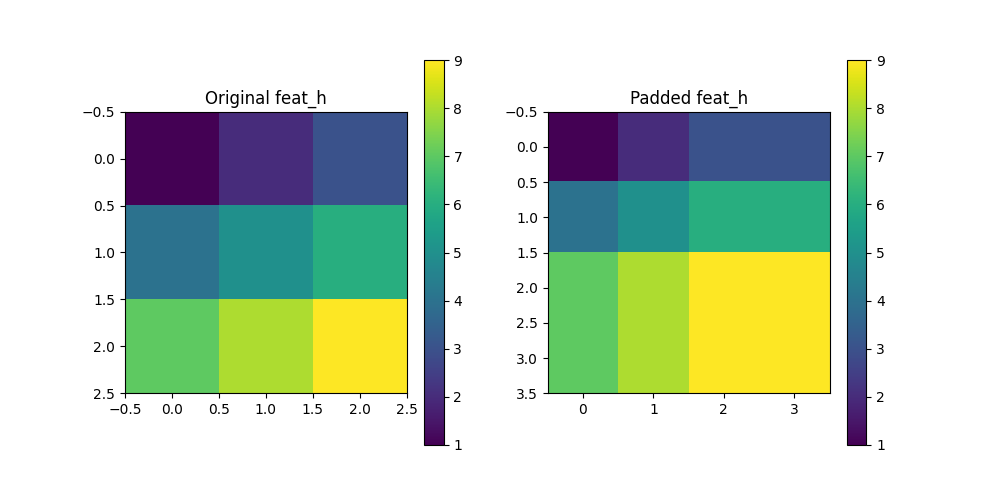
一、零填充
1.代码
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 用 0 填充的函数
def pad_feat_h(feat_h, feat_aggregate):# 获取 feat_aggregate 的长和宽h_agg, w_agg = feat_aggregate.shape[-2:]# 获取 feat_h 的长和宽h_h, w_h = feat_h.shape[-2:]# 计算 feat_aggregate 长和宽乘 2 的结果new_h = h_agg * 2new_w = w_agg * 2# 判断是否需要进行 paddingif new_h > h_h or new_w > w_h:# 计算需要填充的数量pad_h = new_h - h_hpad_w = new_w - w_h# 计算左右上下需要填充的数量pad_left = pad_w // 2pad_right = pad_w - pad_leftpad_top = pad_h // 2pad_bottom = pad_h - pad_top# 进行 padding 操作feat_h = F.pad(feat_h, (pad_left, pad_right, pad_top, pad_bottom), mode='constant', value=0)return feat_h2.测试用例
# 创建一个简单的测试特征图 feat_h
feat_h = torch.tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]
], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 添加批次和通道维度# 创建一个目标特征图 feat_aggregate
feat_aggregate = torch.tensor([[0, 0],[0, 0]
], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 添加批次和通道维度# 调用填充函数
padded_feat_h = pad_feat_h(feat_h, feat_aggregate)# 可视化
plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)
plt.title("Original feat_h")
plt.imshow(feat_h.squeeze().numpy(), cmap='viridis')
plt.colorbar()plt.subplot(1, 2, 2)
plt.title("Padded feat_h")
plt.imshow(padded_feat_h.squeeze().numpy(), cmap='viridis')
plt.colorbar()plt.show()3.可视化
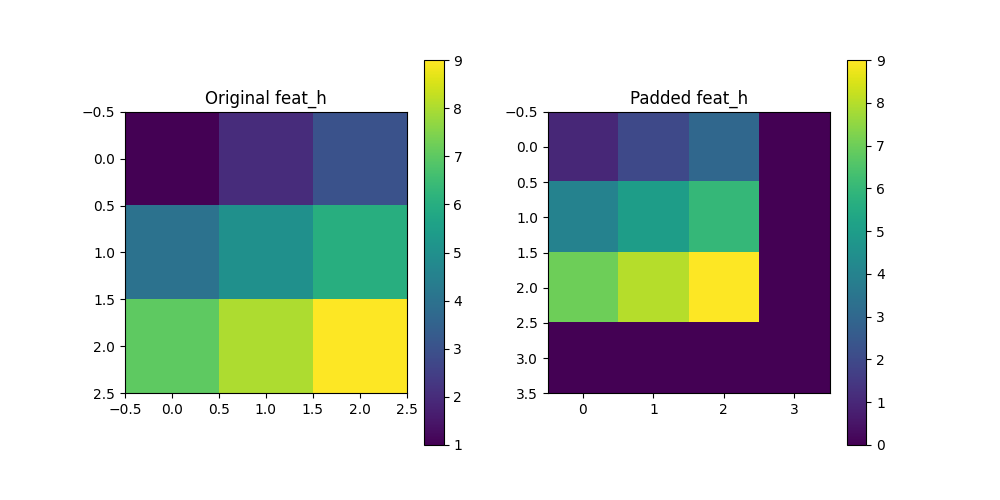
二、边缘填充
用张量的最外层像素去补齐缺失的元素
1.代码
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as npdef pad_feat_h_with_edge(feat_h, feat_aggregate):# 获取 feat_aggregate 的长和宽h_agg, w_agg = feat_aggregate.shape[-2:]# 获取 feat_h 的长和宽h_h, w_h = feat_h.shape[-2:]# 计算 feat_aggregate 长和宽乘 2 的结果new_h = h_agg * 2new_w = w_agg * 2# 判断是否需要进行 paddingif new_h > h_h or new_w > w_h:# 计算需要填充的数量pad_h = new_h - h_hpad_w = new_w - w_h# 计算左右上下需要填充的数量pad_left = pad_w // 2pad_right = pad_w - pad_leftpad_top = pad_h // 2pad_bottom = pad_h - pad_top# 进行 padding 操作,修改 mode 为'replicate'feat_h = F.pad(feat_h, (pad_left, pad_right, pad_top, pad_bottom), mode='replicate')return feat_h2.测试用例
# 创建一个简单的测试特征图 feat_h
feat_h = torch.tensor([[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]
], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 添加批次和通道维度# 创建一个目标特征图 feat_aggregate
feat_aggregate = torch.tensor([[0, 0, 0],[0, 0, 0],[0, 0, 0]
], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 添加批次和通道维度# 调用填充函数
padded_feat_h = pad_feat_h_with_edge(feat_h, feat_aggregate)# 可视化
plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)
plt.title("Original feat_h")
plt.imshow(feat_h.squeeze().numpy(), cmap='viridis')
plt.colorbar()3.可视化
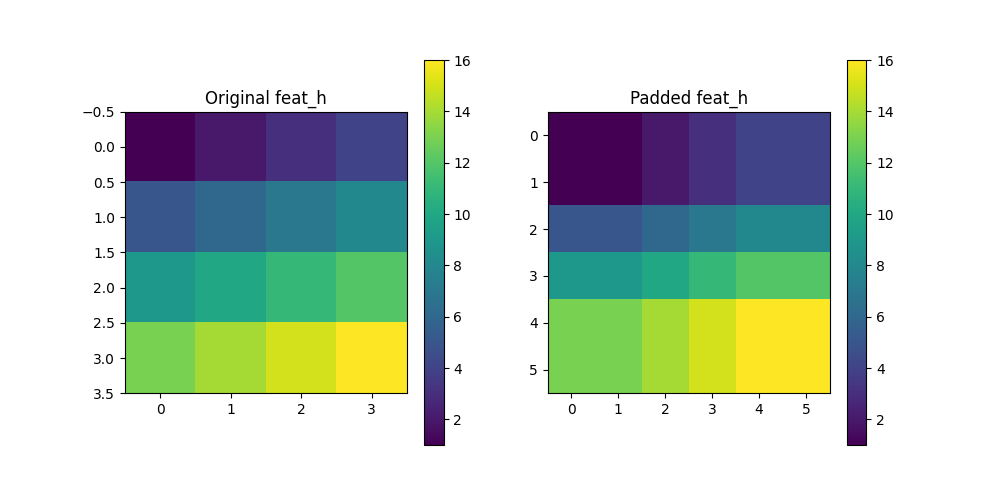
注:该代码也适合original_feat_h不恰好处于Padded_feat_h的情况
如下图所示: